基于阿里云官网文档-大数据开发治理平台 DataWorks研读+数据质量扩展+相应的大数据组件知识扩展
网址:阿里DataWorkers网址:数据集成概述 - 大数据开发治理平台 DataWorks - 阿里云
目录
网址:阿里DataWorkers网址:数据集成概述 - 大数据开发治理平台 DataWorks - 阿里云
一、DataWorks 工作流程
1、数据集成
(1)数据同步过程中几个必要的东西
2、数据开发
(1)写sql,但又不止写sql
(2)调度配置
3、运维工作
(1)大体如下
(2)周期任务 实例DAG图(有向无环图)
(3)任务状态
(4)补数据
4、数据治理
(1)数据访问控制
(2)数据质量 单独拿出来说
5、数据地图
二、数据质量(重要)
1、情景:
2、主要的数据质量校验规则
(1)主键重复检测
(2)表数据量检测
(3)某些重要计算列检测
三、思考整理
1、ELASTICSearch
(1)是什么?
(2)适用场景
(3)特点
2、kudu
(1)是什么?
(2)架构
3、impala
(1)是什么?
(2)优缺点
4、kylin
(1)是什么?
(2)特点
(3)应用场景
5、Presto
(1)是什么?
(2)优缺点
一、DataWorks 工作流程
1、数据集成
也就是数据的同步,包括抽数、导数
在离线数仓中也叫 离线同步
(1)数据同步过程中几个必要的东西
1)数据源
包括从哪来到哪去,可以是数据库,也可以是别的,比如FTP、ES等
2)表
来源表 目标表
3)字段映射关系
4)同步方式/同步逻辑
mysql -》hive
全删全查--先清空hive表的某些分区,再插入
直接插入
hive--》mysql
全删全查
直接插入
主键冲突 update
hive --》 mysql 一般称为 回流
同步方法:1、直接对mysql业务库进行操作。优缺点:操作简单;但是风险较大
2、写到kafka,让java后端去消费
kafka,消息中间 件 hive ->kafka ->mysql
中间多了一层,离线数仓称为生产者,java后端称为消费者
特点:较为安全,但是开发比较麻烦
3、api接口
产生统一的api接口,供java同事去调用,dataworkers有相应的功能,
api接口一般是一行数据,一个JSON
4、还是将数据写到mysql,但是是接口端的mysql
hive ---》 mysql(接口库) --》接口 --》mysql业务库
5)同步时间,多久同步一次
linux crontab
2、数据开发
(1)写sql,但又不止写sql
(2)调度配置
时间配置:什么时候运行?多久运行一次?
生效时间范围:比如 2022-4-9 ~ 2022-4-10
SLA:设置任务的超时时间,比如设置一小时,也可以设置具体的时间,时效性
依赖设置:哪些任务跑完了,我才可以跑
重跑设置:是否出错,自动重跑?重跑几次?是否可以手动重跑?
其它:代码提醒,比如写一个表 dwd_order_ ,可以提醒补全(主要依靠元数据)
血缘关系,一大段sql,平台可以将其中所有表的依赖解析出来
版本,谁编辑过,编辑了几次,为什么编辑,可以回滚?
代码搜索:
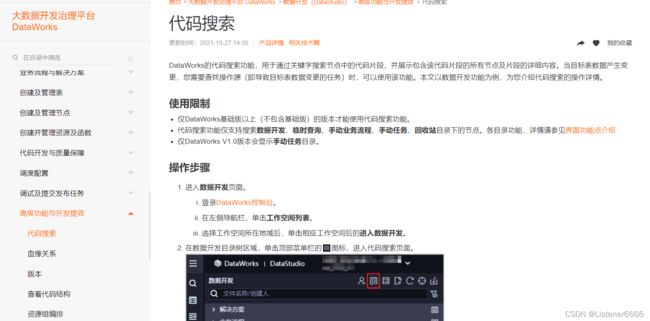
3、运维工作
(1)大体如下
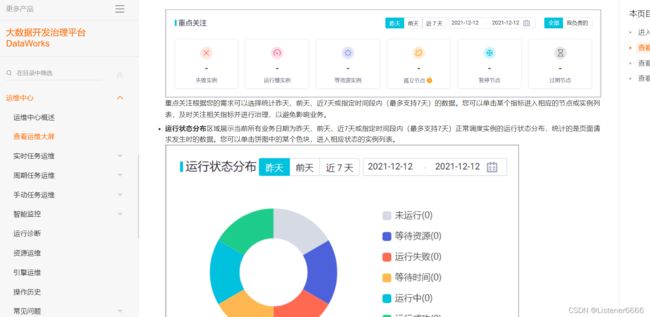
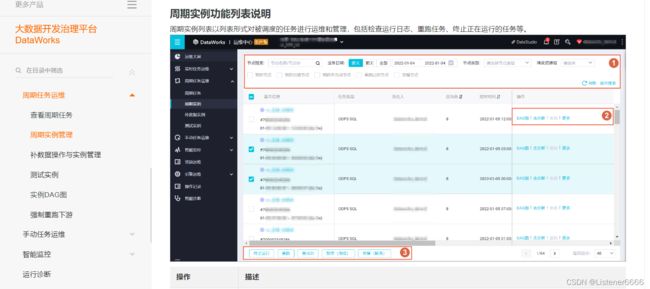
(2)周期任务 实例DAG图(有向无环图)

(3)任务状态
启动 、停止 、暂停(冻结)、 解冻
(4)补数据
作用 1:例如hive加了个字段,那我可能要基于业务去重跑某个时间段的数据
2:做测试用,重跑某一天的某个分区的数据
3:调度任务失败后,重跑
4、数据治理
(1)数据访问控制
例如分析师想要看某个做好的ADS表,他申请,你审批
(2)数据质量 单独拿出来说
5、数据地图
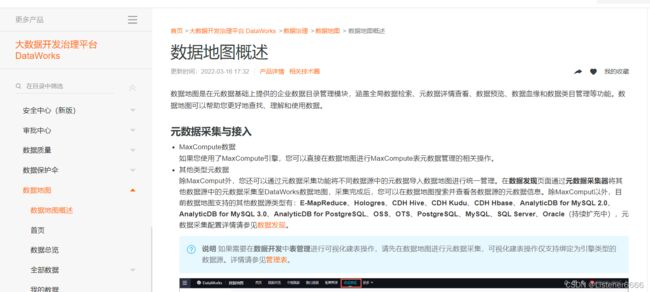
包含了表,字段,分区,数据量,上下游依赖等等信息(从元数据搞来)
二、数据质量(重要)
1、情景:
比如有些任务我们跑成功了,但是数据不对,下游分析师或者业务发现,告知我们。
例如,有一个app弹窗,里面放的是优惠券的链接,里面的数据是自己做的,原本按照业务要求只需要发一万张,但是却发了十万人,这就会造成资损。
2、主要的数据质量校验规则
(1)主键重复检测
having count(distinct id) > 1
(2)表数据量检测
数据量多也不行,少也不行,没有更不行
没有数据:是否为空? count(1) 是否大于 0 ?
多也不行,少也不行:表数据量波动阈值,假如每天的数据量大约是1万条左右,我们设置阈值为50%,当突然有一天数据量达到 2万条,就会警告等。
N天平均值波动,方差波动,周期波动
(3)某些重要计算列检测
比如一个存放百分比的列,里面值都为小于1大于0的小数,我们可以置该列最大值为1,出现大于1 的报错
三、思考整理
1、ELASTICSearch
(1)是什么?
Elasticsearch,基于Lucene,隐藏复杂性,提供简单易用的RestfulAPI接口、JavaAPI接口(还有其他语言的API接口)。
Elasticsearch是一个实时分布式搜索和分析引擎。它用于全文搜索、结构化搜索、分析。
(2)适用场景
1)维基百科,类似百度百科,牙膏,牙膏的维基百科,全文检索,高亮,搜索推荐。
2)The Guardian(国外新闻网站),类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+ 社交网络数据(对某某新闻的相关看法),数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)。
3)Stack Overflow(国外的程序异常讨论论坛),IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案。
4)GitHub(开源代码管理),搜索上千亿行代码。
5)国内:站内搜索(电商,招聘,门户,等等),IT系统搜索(OA,CRM,ERP,等等),数据分析(ES热门的一个使用场景)。
(3)特点
1)可以作为一个大型分布式集群(数百台服务器)技术,处理PB级数据,服务大公司;也可以运行在单机上,服务小公司
2)Elasticsearch不是什么新技术,主要是将全文检索、数据分析以及分布式技术,合并在了一起,才形成了独一无二的ES;lucene(全文检索),商用的数据分析软件(也是有的),分布式数据库(mycat)
3)对用户而言,是开箱即用的,非常简单,作为中小型的应用,直接3分钟部署一下ES,就可以作为生产环境的系统来使用了,数据量不大,操作不是太复杂
4)数据库的功能面对很多领域是不够用的(事务,还有各种联机事务型的操作);特殊的功能,比如全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理;Elasticsearch作为传统数据库的一个补充,提供了数据库所不能提供的很多功能
2、kudu
(1)是什么?
Kudu 是一个针对 Apache Hadoop 平台而开发的列式存储管理器。
(2)架构
Kudu也采用了Master-Slave形式的中心节点架构,管理节点被称作Kudu Master,数据节点被称作Tablet Server(可对比理解HBase中的RegionServer角色)。一个表的数据,被分割成1个或多个Tablet,Tablet被部署在Tablet Server来提供数据读写服务。
Kudu Master在Kudu集群中,发挥如下的一些作用:
1. 用来存放一些表的Schema信息,且负责处理建表等请求。
2. 跟踪管理集群中的所有的Tablet Server,并且在Tablet Server异常之后协调数据的重部署。
3. 存放Tablet到Tablet Server的部署信息。
Tablet与HBase中的Region大致相似,但存在如下一些明显的区别点:
Tablet包含两种分区策略,一种是基于Hash Partition方式,在这种分区方式下用户数据可较均匀的分布在各个Tablet中,但原来的数据排序特点已被打乱。另外一种是基于Range Partition方式,数据将按照用户数据指定的有序的Primary Key Columns的组合String的顺序进行分区。而HBase中仅仅提供了一种按用户数据RowKey的Range Partition方式。
3、impala
(1)是什么?
Cloudera公司推出,提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。
基于Hive,使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点。
是CDH平台首选的PB级大数据实时查询分析引擎。

(2)优缺点
优点:
1.基于内存运算,不需要把中间结果写入磁盘,省掉了大量的I/O开销。
2.无需转换为Mapreduce,直接访问存储在HDFS,HBase中的数据进行作业调度,速度快。
3.使用了支持Data locality的I/O调度机制,尽可能地将数据和计算分配在
同一台机器上进行,减少了网络开销。
4.支持各种文件格式,如TEXTFILE 、SEQUENCEFILE 、RCFile、Parquet。
5.可以访问hive的metastore,对hive数据直接做数据分析。
缺点:
1.对内存的依赖大,且完全依赖于hive。
2.实践中,分区超过1万,性能严重下降。
3.只能读取文本文件,而不能直接读取自定义二进制文件。
4.每当新的记录/文件被添加到HDFS中的数据目录时,该表需要被刷新。
4、kylin
(1)是什么?
Apache Kylin 是一个开源的分布式存储引擎,最初由 eBay 开发贡献至开源 社区。它提供 Hadoop 之上的 SQL 查询接口及多维分析(OLAP)能力以支持大规 模数据,能够处理 TB 乃至 PB 级别的分析任务,能够在亚秒级查询巨大的 Hive 表,并支持高并发。
(2)特点
- 数据源和模型:主要支持Hive、Kafka
- 构建引擎:早期支持MapReduce计算引擎,新版本支持Spark、Flink计算引擎。除了全量构建外,基于时间的分区特性,支持增量构建。
- 存储引擎:构建好的Cube以Key-Value形式存储在HBase中,通过优化Rowkey加速查询。每一种维度的排列组合计算结果被保存为一个物化视图,叫做Cuboid.
- 优化算法:Cube本身是空间换时间,也会根据算法,剪枝优化掉一些多余的Cuboid,需求平衡。
- 访问接口:支持标准SQL接口,可以对接Zeppelin、Tableau等BI工具。SQL通过查询引擎,可以被路由到对应的Cuboid上。
(3)应用场景
- 特点:Kylin在亚秒级内返回海量数据的查询结果。
- 巨大的数据量,单个数据源表千亿行数据级别,且单个数据源达到百TB级别。
- 巨大的查询压力(查询的高并发)
- 查询的快速响应
- 下游较灵活的查询方式,需支持带有复杂条件的SQL查询。
- Kylin的核心思想是预计算,将数据按照指定的维度和指标,预先计算出所有可能的查询结果,利用空间换时间来加速查询速度。
5、Presto
(1)是什么?
Presto是一款Facebook开源的MPP架构的OLAP查询引擎,可针对不同数据源执行大容量数据集的一款分布式SQL执行引擎。
比如说,你想对存储在不同数据源中的数据,如HDFS、Mysql、HBase等通过一个SQL做查询分析,那么只需要把每一个数据源当成是Presto的Connector,对应实现Presto SPI暴露出的Connector API就可以了。
(2)优缺点
优点:
基于内存运算,减少了硬盘IO,计算更快
能够连接多个数据源,跨数据源连表查,比如从Hive查询大量网站访问记录,然后从Mysql中匹配出设备信息。
缺点:
Presto能处理PB级别的海量数据分析,但Presto并不是把PB即数据都放在内存中计算。而是根据场景,如Count,AVG等聚合运算,是边堵数据边计算,再清理内存,再读数据再计算,这种内存耗的并不高。但是连表查,就可能产生大量的临时数据,因此速度会变慢。