K8S学习心得:Scheduler原理与源码分析
1. Scheduler概念
资源调度器。kube-apiserver收到新建Pod的请求,识别其合法并存入etcd,然后kube-scheduler去watch kube-apiserver知道此需求,根据预定的调度策略评估出一个最合适Node节点来运行Pod,如果没有最合适,那就随机,最后会把调度的结果记录在etcd中。
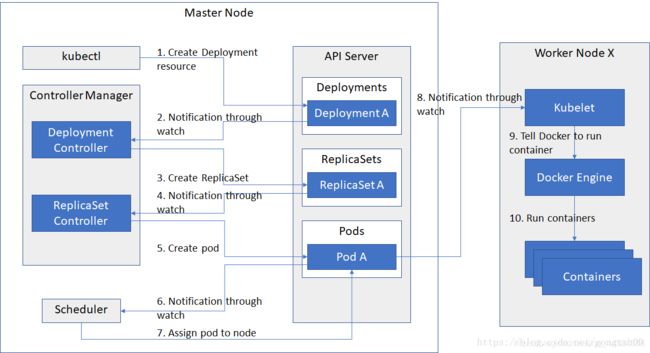 通过上边的流程图我们也能大概看出:Scheduler在整个系统中起"承上启下"作用,承上:负责接收Controller Manager创建的新的Pod,为其选择一个合适的Node;启下:Node上的kubelet接管Pod的生命周期。
通过上边的流程图我们也能大概看出:Scheduler在整个系统中起"承上启下"作用,承上:负责接收Controller Manager创建的新的Pod,为其选择一个合适的Node;启下:Node上的kubelet接管Pod的生命周期。
2. 调度流程
Scheduler是怎么通过调度算法,为待调度Pod列表的每个Pod从Node列表中选择一个最适合的Node的呢?我们来简单看一下它的调度流程。
1、预选调度过程
即遍历所有目标Node,筛选出符合要求的候选节点,kubernetes内置了多种预选策略(xxx Predicates)供用户选择
2、确定最优节点
在第一步的基础上采用优选策略(xxx Priority)计算出每个候选节点的积分,取最高积分。
调度流程通过插件式加载的“调度算法提供者”(AlgorithmProvider)具体实现,一个调度算法提供者就是包括一组预选策略与一组优选策略的结构体。
3. 预选策略
说明:返回true表示该节点满足该Pod的调度条件;返回false表示该节点不满足该Pod的调度条件。
3.1. NoDiskConflict
判断备选Pod的数据卷是否与该Node上已存在Pod挂载的数据卷冲突,如果是则返回false,否则返回true。
3.2. PodFitsResources
判断备选节点的资源是否满足备选Pod的需求,即节点的剩余资源满不满足该Pod的资源使用。
计算备选Pod和节点中已用资源(该节点所有Pod的使用资源)的总和。
获取备选节点的状态信息,包括节点资源信息。
如果(备选Pod+节点已用资源>该节点总资源)则返回false,即剩余资源不满足该Pod使用;否则返回true。
3.3. PodSelectorMatches
判断节点是否包含备选Pod的标签选择器指定的标签,即通过标签来选择Node。
- 如果Pod中没有指定spec.nodeSelector,则返回true。
- 否则获得备选节点的标签信息,判断该节点的标签信息中是否包含该Pod的spec.nodeSelector中指定的标签,如果包含返回true,否则返回false。
3.4. PodFitsHost
判断备选Pod的spec.nodeName所指定的节点名称与备选节点名称是否一致,如果一致返回true,否则返回false。
3.5. CheckNodeLabelPresence
检查备选节点中是否有Scheduler配置的标签,如果有返回true,否则返回false。
3.6. CheckServiceAffinity
判断备选节点是否包含Scheduler配置的标签,如果有返回true,否则返回false。
3.7. PodFitsPorts
判断备选Pod所用的端口列表中的端口是否在备选节点中已被占用,如果被占用返回false,否则返回true。
4. 优选策略
4.1. LeastRequestedPriority
优先从备选节点列表中选择资源消耗最小的节点(CPU+内存)。
4.2. CalculateNodeLabelPriority
优先选择含有指定Label的节点。
4.3. BalancedResourceAllocation
优先从备选节点列表中选择各项资源使用率最均衡的节点。
5. 部分源码分析
scheduler的pkg代码目录结构如下:
scheduler
├── algorithm # 主要包含调度的算法
│ ├── predicates # 预选的策略
│ ├── priorities # 优选的策略
│ ├── scheduler_interface.go # ScheduleAlgorithm、SchedulerExtender接口定义
│ ├── types.go # 使用到的type的定义
├── algorithmprovider
│ ├── defaults
│ │ ├── defaults.go # 默认算法的初始化操作,包括预选和优选策略
├── cache # scheduler调度使用到的cache
│ ├── cache.go # schedulerCache
│ ├── interface.go
│ ├── node_info.go
│ ├── node_tree.go
├── core # 调度逻辑的核心代码
│ ├── equivalence
│ │ ├── eqivalence.go # 存储相同pod的调度结果缓存,主要给预选策略使用
│ ├── extender.go
│ ├── generic_scheduler.go # genericScheduler,主要包含默认调度器的调度逻辑
│ ├── scheduling_queue.go # 调度使用到的队列,主要用来存储需要被调度的pod
├── factory
│ ├── factory.go # 主要包括NewConfigFactory、NewPodInformer,监听pod事件来更新调度队列
├── metrics
│ └── metrics.go # 主要给prometheus使用
├── scheduler.go # pkg部分的Run入口(核心代码),主要包含Run、scheduleOne、schedule、preempt等函数
└── volumebinder
└── volume_binder.go # volume bind
作者才疏学浅,这里仅列出scheduleOne部分的源码,供大家一起学习。scheduleOne主要为单个pod选择一个适合的节点,为调度逻辑的核心函数。
(此部分代码位于pkg/scheduler/scheduler.go)
对单个pod进行调度的基本流程如下:
- 通过podQueue的待调度队列中弹出需要调度的pod。
- 通过具体的调度算法为该pod选出合适的节点,其中调度算法就包括预选和优选两步策略。
- 如果上述调度失败,则会尝试抢占机制,将优先级低的pod剔除,让优先级高的pod调度成功。
- 将该pod和选定的节点进行假性绑定,存入scheduler cache中,方便具体绑定操作可以异步进行。
- 实际执行绑定操作,将node的名字添加到pod的节点相关属性中。
核心代码如下:
// scheduleOne does the entire scheduling workflow for a single pod. It is serialized on the scheduling algorithm's host fitting.
func (sched *Scheduler) scheduleOne() {
pod := sched.config.NextPod()
if pod.DeletionTimestamp != nil {
sched.config.Recorder.Eventf(pod, v1.EventTypeWarning, "FailedScheduling", "skip schedule deleting pod: %v/%v", pod.Namespace, pod.Name)
glog.V(3).Infof("Skip schedule deleting pod: %v/%v", pod.Namespace, pod.Name)
return
}
glog.V(3).Infof("Attempting to schedule pod: %v/%v", pod.Namespace, pod.Name)
// Synchronously attempt to find a fit for the pod.
start := time.Now()
suggestedHost, err := sched.schedule(pod)
if err != nil {
// schedule() may have failed because the pod would not fit on any host, so we try to
// preempt, with the expectation that the next time the pod is tried for scheduling it
// will fit due to the preemption. It is also possible that a different pod will schedule
// into the resources that were preempted, but this is harmless.
if fitError, ok := err.(*core.FitError); ok {
preemptionStartTime := time.Now()
sched.preempt(pod, fitError)
metrics.PreemptionAttempts.Inc()
metrics.SchedulingAlgorithmPremptionEvaluationDuration.Observe(metrics.SinceInMicroseconds(preemptionStartTime))
metrics.SchedulingLatency.WithLabelValues(metrics.PreemptionEvaluation).Observe(metrics.SinceInSeconds(preemptionStartTime))
}
return
}
metrics.SchedulingAlgorithmLatency.Observe(metrics.SinceInMicroseconds(start))
// Tell the cache to assume that a pod now is running on a given node, even though it hasn't been bound yet.
// This allows us to keep scheduling without waiting on binding to occur.
assumedPod := pod.DeepCopy()
// Assume volumes first before assuming the pod.
//
// If all volumes are completely bound, then allBound is true and binding will be skipped.
//
// Otherwise, binding of volumes is started after the pod is assumed, but before pod binding.
//
// This function modifies 'assumedPod' if volume binding is required.
allBound, err := sched.assumeVolumes(assumedPod, suggestedHost)
if err != nil {
return
}
// assume modifies `assumedPod` by setting NodeName=suggestedHost
err = sched.assume(assumedPod, suggestedHost)
if err != nil {
return
}
// bind the pod to its host asynchronously (we can do this b/c of the assumption step above).
go func() {
// Bind volumes first before Pod
if !allBound {
err = sched.bindVolumes(assumedPod)
if err != nil {
return
}
}
err := sched.bind(assumedPod, &v1.Binding{
ObjectMeta: metav1.ObjectMeta{Namespace: assumedPod.Namespace, Name: assumedPod.Name, UID: assumedPod.UID},
Target: v1.ObjectReference{
Kind: "Node",
Name: suggestedHost,
},
})
metrics.E2eSchedulingLatency.Observe(metrics.SinceInMicroseconds(start))
if err != nil {
glog.Errorf("Internal error binding pod: (%v)", err)
}
}()
}