DLink 流批一体技术架构及优势 | 滴普科技FastData系列解读

一、引言
在上期的两篇连载文章中,我们分析了Lambda 和 Kappa 架构固有的一些问题,同时也引出了流批一体架构的优势,本文就 FastData流批一体大数据平台DLink ,如何基于 Flink + Iceberg 流批一体技术及其实践进行初步探讨。
二、需求背景
传统的基于离线(比如 Hive)数仓有很高的成熟度和稳定性,但在一些时延要求比较高的场景,则需要借助实时数仓 Flink 的帮助,将延时降低到秒级(或分钟级),但两套并存的数仓架构,势必带来双倍的资源消耗和开发维护工作量。那么,是否存在可以将离线和实时任务、批处理和流式任务,统一放在一套架构中调度和运行的架构呢?答案自然是肯定的。这就是 Dlink 的统一技术栈。
三、DLink 流批一体技术架构
(1)统一技术栈
DLink整体技术方案的核心理念就是“统一”。从底层Data Stack 的角度看,包括5 个部分:
- 数据存储:首先是数据存储格式的统一。利用 Iceberg 基于快照的读写分离和回溯(backfill)、流批统一的写入和读取、不强绑定计算存储引擎、ACID 语义及数据多版本、表schema和 partition evolution 等能力。
- Catalog Manager:统一Data Catalog,兼容 Hive Meta Store 接口,可实现 Flink、Trino、Hive 等常用大数据分析、计算引擎的无缝接入和良好的互操作性。
- 计算引擎:Unified DataStream,Flink 引擎在 DataStream 和 Table API 中均支持 batch 和 streaming 两种执行模式。
- 调度引擎:流批一体调度器,同时支持流批调度模式。在调度器内部通过 DAG 的合并和拆解、资源的细粒度配置等规则,对物理执行计划进行自适应调优。
- SQL引擎:统一了流式计算 SQL 与分析、点查等 Serving 类SQL 语义(兼容 ANSI SQL 标准)。所有的 SQL 类操作使用统一的 SQL 引擎。

图一 DLink 统一技术栈
关于 DLink的技术特点,在第四节会重点介绍一下。
实时数仓建设最重要的环节就是 ETL 任务,接下来我们结合实际场景和需求,看一下 Dlink 实时数仓是如何解决传统 Lambda架构在 ETL 场景中遇到的各种问题。
(2)实时数仓 ETL 场景
下图是DLink 流批一体数据平台在实时数仓场景(典型的 ETL 场景)的一个数据流图:
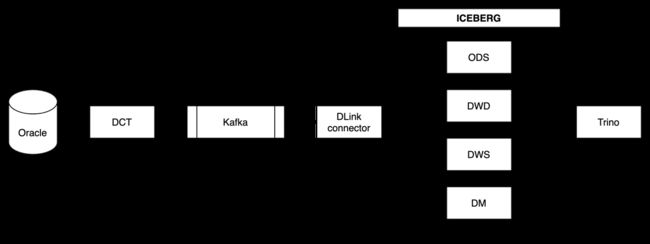
图二:DLink 数据流图
2.1 客户需求
客户之前完全使用 Oracle 搭建他们的数仓系统,在数据量达到一定规模之后,ETL 和数据分析的效率越来越低,亟需进行架构升级。对此,客户提出以下需求:一,实时抽取和写入:实时将 Oracle 的增量数据抽取并写入 Iceberg 中,业务数据的并发量在3000 行 / 秒,端到端时延要求在1至5分钟内;二,OLAP 统计分析:支持 DM 层数据的查询分析。
总之,对数据处理的实时性和数据的分析提出了要求。
2.2 实时数仓数据流程
结合客户的具体需求和 Dlink 的产品特性,我们设计了图二的流批一体实时数仓架构,从数据生命周期的角度,数据流程可以分为以下三个部分:
数据采集消费(Extract & Transform)
FastData DCT组件(类似 Debezium)负责 Oracle binlog 的抓取并转换成 dct-json 格式存储在 Kafka,实现增量数据入到 Iceberg 实时数仓。
数据统一存储(Unified Storage)
统一采用 iceberg 表格式存储全量数据,包括数仓的 ODS、DWD、DWS 和 DM 层数据,并实现各层之间增量数据的流转和处理。
数据实时处理(Transform & Load)
Flink 实际上在实时数仓 ETL 的以下阶段发挥了作用:
- 实时数据入湖:使用 Flink Kafka Source Connector 从 Kafka 拉取数据,并使用 Iceberg sink connector 将数据写入到 ODS 层;
- 增量数据读取: 当 ODS 层有新增数据时,触发 iceberg source connector 的增量读取事件,经过 Flink 计算将增量数据通过 Iceberg sink connector写入下面的 DWD 层,实现历史数据的更新;
- 更新下游数据:针对上游 ODS 明细数据的偶尔变更,触发DLink计算任务对小批量数据进行准实时的重新计算,更新下游统计数据,并将变更继续向下游传播。
接下来,我们从数据的采集、转换、存储和分析的角度继续来看:FastData DLink 流批一体大数据平台集成了从数据采集到最终的数据计算、分析能力。结合图二来看,具体涉及的流程如下:
数据采集
采集流程中使用了FastData DCT 以及 Kafka 组件,实现了Oracle增量数据的实时采集。
数据转换
转换环节主要涉及数仓离线链路的处理。类似往期文章中提到的 Lambda 架构,我们实际上可以通过 Flink 批处理读取某个 Iceberg 表的快照做全局分析,得到的结果可供不同场景(如Ad Hoc查询、数据科学、机器学习)下的用户读取和分析。
数据存储
Iceberg 作为通用的表格式存储,很好地分离了计算引擎(Flink、Spark、Hive、Presto等) 和底下的存储层,这样就可以很好地兼容多种计算引擎和文件格式(Parquet、ORC、Avro 等),正在成为数据湖上Table Format 层的事实标准。
Iceberg manifest和snapshot的设计,有效地隔离了不同transaction的变更,非常方便批处理和增量计算。
同时,Apache Iceberg 的社区资源也非常丰富,Netflix、Apple、LinkedIn、Adobe等公司都有PB级别的生产数据,运行在Apache Iceberg之上。
数据分析
由于底层 Iceberg 存储格式的打通,Trino 可实时读取 Flink 写入的 Iceberg 快照,从而实现了端到端近实时(1 分钟之内)的分析。
四、DLink技术亮点
那么,为了支撑以上产品特性,DLink 平台中又引入了哪些创新的技术呢?
在构建 DLink 流批一体大数据平台的过程中,基于 Iceberg、Flink 和 Trino 技术栈,结合客户的实际场景和需求,我们在元数据管理、数据存储格式和数据分析性能上做了一些工作,总结如下:
(1)统一元数据存储(Catalog Manager)
基于 DLink 统一的 Catalog Manager (简称 CM)和 统一元数据模型,实现了 Flink 和 Trino 引擎在catalog、database、表、视图(包括物化视图)和数据类型的统一和 良好的互操作性,彻底解决大数据引擎元数据格式不同造成的各种问题,用户无需代码开发,真正实现 Define Once,Query Anywhere!
同时,DLink CM可对外提供标准的 Hive Meta Store 接口。通过 HMS 接口,我们也计划将 DLink 的内部托管数据源暴露给外部第三方数据引擎(Hive、Spark 等),实现 DLink与大数据生态的打通。
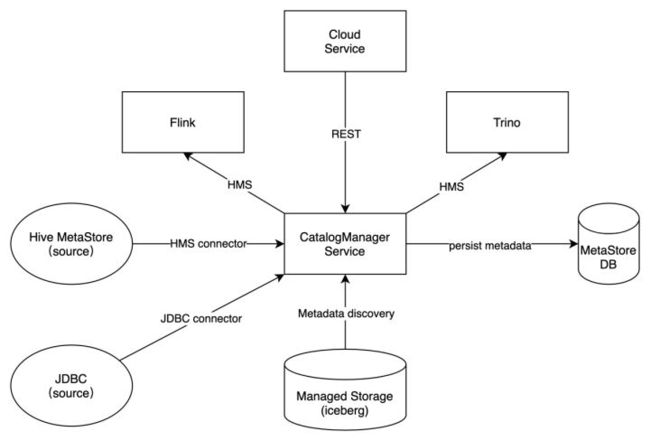
图三 统一元数据存储
对于数据源和 Catalog 的管理,有三种情况:
- 结构化元数据:可对接开源 Hive Meta Store;
- 半结构化元数据:对于以 CSV、JSON等格式存储在对象存储和分布式文件系统上的元数据信息,可通过 Crawler 任务自动探索和解析,从而自动生成元数据信息;
- JDBC:支持MySQL、PostgreSQL、Oracle 等数据源的接入。
(2)统一数据存储(Iceberg)
Apache Iceberg 作为一个开放的数据湖表格存储,接口定义清晰,支持Flink、Spark等各种大数据引擎,兼容性比较好。虽然有不少优点,社区也比较活跃,但目前还存在点查、更新性能差的问题,DLink 目前联合Iceberg社区在索引和维表等技术之上做了增强和优化:
Clustering 技术
通过z-order实现多维数据重新聚合排序,提升多维聚合性能,大幅提升查询性能。
二级索引
增加了 Bloom Filter 索引,文件级别的过滤性能大大提升,从而加速点查性能。
MOR(Merge On Read)优化
通过后台自动调度的 Job,合并delete file 和 data file。避免在读取时,查询完data file后,还需要临时合并 delete file 的结果,从而提升了读性能。
小文件合并
类似 MOR Job 的后台任务。基于 Iceberg 的快照隔离和读写分离的优秀特性,我们开发了小文件自动合并功能。后台 Job 自动合并小文件,持续优化读取性能。基于多版本的快照隔离能力,文件合并操作不阻塞用户正常读写。
Lookup Table
维度表在流式计算的应用很广,通过 SQL 的 join 操作实现数据的补全。比如, source stream 是MySQL Binlog 日志中的订单信息,但日志中仅记录了商品的 ID,这样当订单信息入仓,我们进行日志流 Join 的时候,就可以通过查询维表的方式,补全商品名称的信息。
DLink Lookup Table 将热数据高效缓存在本地,冷数据存储在 Iceberg,同时基于数据局部性原理和统计分析,我们加入了自研的缓存替换算法,缓存命中率较高。同时,查询维表时,通过 Projection 与 Filter push down 极大降低缓存的数据量,进一步提高了缓存的命中率。我们初步测试 Streaming Join 维表性能较 Flink 原生 Lookup Table 性能提升2倍以上。
(3)统一 SQL引擎
在统一元数据之后,为了进一步提升易用性,我们在 Trino 和 Flink 之上构建了统一的 ANSI SQL 层,提供了一致的使用体验。数据入湖,DML、DDL等 SQL 操作均由一套 SQL 实现。在统一的 SQL 引擎及其优化器之上,我们做了如下优化:
Dynamic Filtering技术
Dynamic Filtering 技术早在 2005 年就在 Oracle中实现。借鉴数据库的思路,我们基于 Trino 引擎在Iceberg connector 上实现了 Dynamic Filtering 技术,大大减少了 tableScan 算子扫描的数据量。对于Dynamic filtering 技术感兴趣的同学可以参考:Dynamic filtering 。
五、未来展望
在FastData DLink统一元数据与存储的架构之上,FastData DLink将继续优化流式计算和数据入湖的性能,优化端到端时延,秉承简单、高效、易用的理念,构建流批一体、湖仓一体的实时大数据平台。
2022 年,DLink 将在 Flink、Iceberg、Trino 等开源组件上的优化和新特性逐步回馈开源社区,与国内外同行共建良好的大数据生态。
由于本文篇幅的限制,对于DLink大数据流批一体处理、流式计算、多维分析和湖仓一体等,大家关心的下一代大数据平台核心技术,后续我们会持续和大家分享,敬请期待!