CUDA教程: 1.GPU的硬件架构
前言
什么样的朋友适合来学习CUDA
- 有志于从事CUDA/GPU系统开发的开发者
- 使用CUDA/GPU并行计算, AI, HPC系统的科研工作者
- 计算机,电子,自动化,生医等相关专业的硕士研究生或高年级本科生
学习完这个系列的教程您可以收获什么?
- 了解和掌握GPU/CUDA并行计算系统的分析,设计,开发,调试和优化方法
- GPU并行计算系统的分析能力,编程能力
- 能够通过看API手册之类的,自行进步以从事GPU开发职业
基础知识
- 计算机体系结构基础
- C语言程序设计
- 计算机算法基础
- 线性代数
1.CUDA教程—GPU的硬件架构
What is CUDA?
-
CUDA
Compute Unified Device Architecture
-
CUDA C/C++
- 基于C/C++的编程方法
- 支持异构编程的扩展方法
- 简单明了的APIs,能够轻松的管理存储系统
-
CUDA支持的编程语言:
C/C++/Python/Fortran/Java/…….
CUDA是我们跟GPU硬件沟通的桥梁, 它介于应用和驱动之间, 让我们可以不必直接调用驱动程序, 以一种更加简单的方式调用GPU的计算能力.
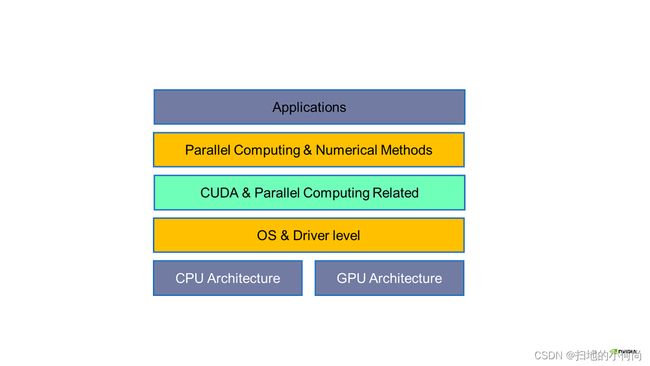
如果你想学好CUDA, 那么了解GPU硬件是必须的!
接下来我们思考一个问题: 我们为什么要使用计算机?

当然是为了解决计算问题, 我们希望计算频率无穷大, 希望有取之不尽的内存, 希望有更加智能化的接口. 目前我们正在一步步的想着目标走去, 甚至现在的智能手机的计算能力比以前很多一屋子电脑的计算能力都强.
而当我们扒开一块CPU的芯片的时候, 我们会发现:

其实那些昂贵的芯片面积很多都被用于复杂的逻辑处理, 以及存储单元.
这也使得我们在很长的一段时间内能够非常轻松的升级我们的芯片.

对, 你没猜错, 大名鼎鼎的摩尔定律.我们只需要无限升级芯片的制作工艺, 让单位面积内容纳更多的晶体管, 那么我们就可以轻松地升级芯片的计算能力.
当我们满心的以为我们找到了一条康庄大道的时候, 可惜时间有太多的无奈.
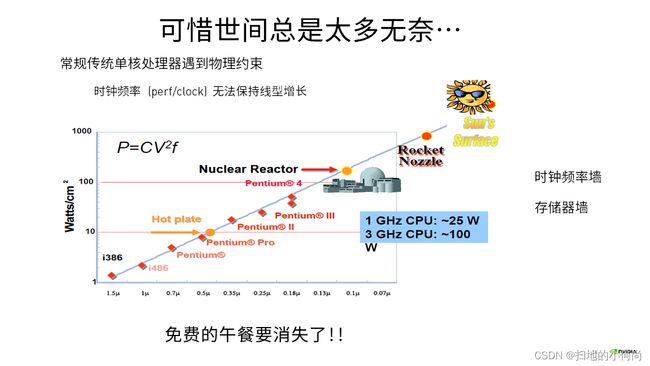
当我们继续升级芯片制程的时候, 我们撞上了两堵墙.
- 一堵墙叫做时钟频率, 当单位面积内晶体管越来越多的时候, 发热也会越来越大, 能量密度就越来越高, 我们很难控制.更高的时钟频率, 将会突破我们能承受的极限
- 另外一堵墙叫做存储器, 当计算能力继续提升的时候, 很难保证存储单元能够跟上芯片的节奏.
于是乎, 免费的午餐就要消失了.
而这时, 平地一声雷, GPU应运而生.

GPU本名图形处理单元, 小明显卡, 外号核弹.
它的诞生让我们看到了突破前面两堵墙的可能
那么, 为什么GPU就能做到呢? 我们同样从硬件结构出发, 也就是Core.
下面的途中展示的是一个CPU计算核心的示意结构图:
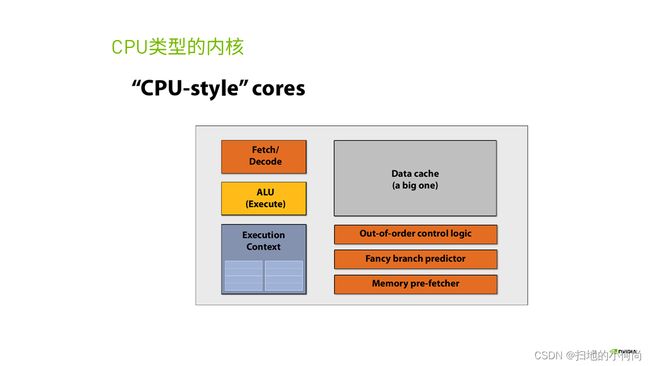
经过长时间的打磨, 它已经有非常稳定的结构. 各种单元之间的配合也非常流畅.
而在CPU中有很多单元是来优化计算流水线的, 帮助我们解决在计算遇到分支, 等待等情况下该如何处理.比如上图中的乱序执行, 分支预测和存储预获取等单元.
而我们去除掉这些单元之后, 实际上这个核心还是可以计算的. 只不过在产生分支之后, 可能会变得慢.
但是, 我们可以利用它们节省的面积多放置一些计算核心. 于是乎就产生了下面的样式的核心:
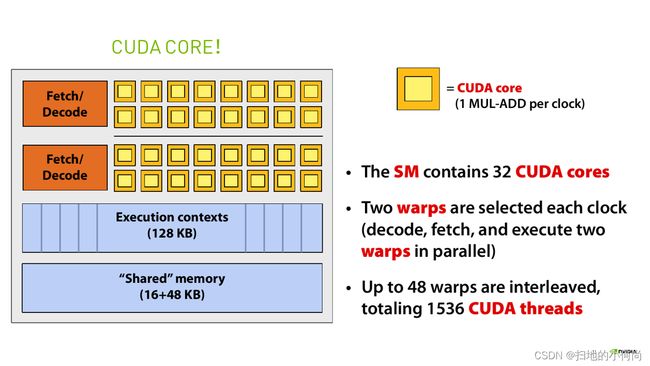
这也就是我们GPU中CUDA core最早的雏形.
而我们把上面的结构叫做一个SM, 它有32个核心, 有一个共享的存储单元让这些核心可以共同协作, 他有一个执行上下文池, 能够让这些核心在任务开始之前就知道它要干嘛.

对比CPU的计算核心来看, 我们很明显的能够感觉到, GPU多了更多的计算Core, 少了一些控制单元和存储单元.
所以, 这也就造成了GPU更适合计算.

而到我写这篇文章的时候, 最先进的GPU A100中已经包含了上万的core.
而你要问我上图中那些格子都是干嘛的, 我来解释:
- L1缓存是让所有的计算核心共享的存储单元
- Warp 调度器是来调度Warp执行命令的
- Dispatch单元是来分配核心的
- 剩下的绿色部分就是来计算用的各种core(多种精度和类型)
正因为这样的结构, 导致GPU编程的方式和CPU有本质上的不同.

CPU处理问题是one by one 顺序执行的, 而GPU处理问题的时候是并行的, 同时完成多个任务.
CUDA并行计算模式
一句话:并行计算是同时应用多个计算资源解决一个计算问题
- 涉及多个计算资源或处理器
- 问题被分解为多个离散的部分,可以同时处理(并行)
- 每个部分可以由一系列指令完成
- 最好是计算密集的任务
- 通信和计算开销比例合适
- 不要受制于访存带宽
未完待续, 下章我们来探讨具体的编程问题!