Linux网络编程 - 多进程服务器端(1)
一 进程概念及应用
利用之前学习到的内容,我们可以构建按序向第一个客户端到第一百个客户端提供服务的服务器端。当然,第一个客户端不会抱怨服务器端,但如果每一个客户端的平均服务时间为 0.5秒,则第100个客户端会对服务器端产生相当大的不满情绪。
1.1 两种类型的服务器端
如果真正为客户端着想,应提高客户端满意度的平均标准。如果有下面这种类型的服务器端,各位客户端应该感到满意了吧?
“第一个连接请求的受理时间为0秒,第50个连接请求的受理时间为50秒,第100个连接请求的受理时间为100秒!但只要受理,服务只需1秒钟。”
如果排在前面的连接请求数能用一只手数清,客户端当然会对服务器端感到满意。但只要超过这个数,客户端就会开始抱怨。还不如用下面这种方式提供服务。
“所有连接请求的受理时间不超过1秒,但平均服务时间为2~3秒。”
显然,第二种服务器端更加合理一些,能够让绝大部分的客户端感到满意。
1.2 并发服务器的实现方法
即使有可能延长服务时间,也有必要改进服务器端,使其能同时向所有发起连接请求的客户端提供服务,以提高平均满意度。而且,网络程序中数据通信时间比CPU运算时间占比更大,因此,向多个客户端提供服务是一种有效利用CPU的方式。接下来讨论同时向多个客户端提供服务的并发服务器端。下面列出的是具有代表性的并发服务器端实现模型和方法。
- 多进程服务器:通过创建多个进程提供服务。
- 多路复用服务器:通过捆绑并统一管理多个I/O对象提供服务。
- 多线程服务器:通过生成与客户端等量的线程提供服务。
我们本篇博文讲解的是第一种方法:多进程服务器。
1.3 理解进程
进程的概念定义,简单地说,进程就是占用内存空间的正在运行的程序。
假如各位从网上下载了LBreakout游戏并安装到硬盘。此时的游戏并非进程,而是程序。因为游戏并未进入运行状态。下面开始运行程序。此时游戏被加载到计算机内存中并进入运行状态,这时才可称为进程。如果同时运行多个LBreakout程序,则会生成相应数量的进程,也会占用相应进程数的内存空间。
再举一个例子。假设各位需要进行文档相关操作,这时应打开文档编辑软件。如果工作的同时还想听音乐,应打开音乐播放器软件。另外,为了与朋友聊天,再打开即时聊天软件。此时共创建3个进程。从操作系统的角度看,进程是程序流的基本单位,若创建多个进程,则操作系统将同时运行这多个进程。有时一个程序运行过程中也会产生多个进程。接下来要创建的多进程服务器端就是其中的代表。编写服务器端前,先了解一下通过程序创建进程的方法。
《提示》CPU核的个数与进程数
拥有2个运算单元的CPU称作双核(Dual)CPU,拥有4个运算单元的CPU称作四核(Quad)CPU。也就是说,1个CPU中可能包含多个运算单元(核)。核的个数与可同时运行的进程数相同。相反,若进程数超过核数,进程将分时使用CPU资源。但因为 CPU 运转速度极快(纳秒级别),我们用户会感到所有进程好像是同时在运行。当然,核数越多,这种感觉越明显。
【Linux进程知识相关链接】
Linux 进程
Linux进程概念(精讲)
Linux进程控制(精讲)
1.4 进程ID
进程ID是用来标识一个进程的身份证号。无论进程是如何被创建的,所有进程都会从操作系统分配到一个ID。此ID称为“进程ID”,其值为大于2的整数。1 要分配给操作系统启动后的(用于协助操作系统)首个进程,因此用户进程无法得到ID值1。
在Linux系统中, 可以使用 ps 命令查看正在运行的进程。
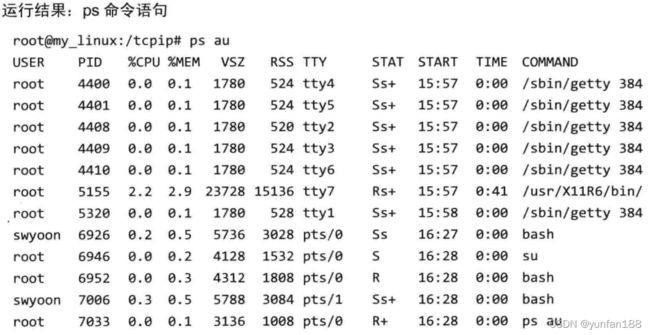 图1-1 ps命令查看正在运行的进程
图1-1 ps命令查看正在运行的进程
可以看出,通过 ps 命令可以查看当前正在运行的所有进程。特别需要注意的是,该命令同时列出了PID(进程ID)。另外,上述示例通过指定 a 和 u 参数列出了所有进程详细信息。
1.5 通过调用 fork() 函数创建子进程
创建进程的方法有很多,此处只介绍用于创建多进程服务器端的fork函数。
- fork() — 创建一个子进程。
#include
pid_t fork(void);
//返回值: 成功时返回子进程ID,失败时返回-1。 fork() 函数将创建调用该函数的进程副本。也就是说,并非根据完全不同的程序创建进程,而是复制正在运行的、调用fork()函数的进程。另外,两个进程都将执行fork()函数调用后的语句(准确地说是在fork函数返回后)。但因为通过同一个进程、复制相同的内存空间,之后的程序流要根据fork函数的返回值加以区分。即利用fork函数的如下特点区分程序执行流程。
- 父进程:fork函数返回子进程ID。
- 子进程:fork函数返回0。
《说明》我们需要理解的是,调用一次fork函数,该函数会返回两次。一次是在调用该函数的进程(也就是派生出子进程的父进程)中返回一次,返回值是新派生的进程的进程ID;另一次是在子进程中返回,返回值是0,代表当前进程为子进程。如果返回值为-1的话,则表示在创建子进程的过程中出错。
此处“父进程(Parent Process)” 指原进程,即调用fork函数的主体,而“子进程(Child Process)” 是通过父进程调用fork函数复制出的进程。接下来讲解调用fork函数后的程序运行流程,如下图所示。
 图1-2 fork函数的调用
图1-2 fork函数的调用
从图1-2中可以看出,父进程调用fork函数的同时复制出子进程,并分别得到fork函数的返回值。但复制前,父进程将全局变量gval 到11,将局部变量lval 的值增加到25,因此在这种状态下完成进程复制工作。复制完成后根据fork函数的返回值区分父子进程。父进程将lval 的值加1,但这不会影响子进程的lval 的值。同样,子进程将gval 的值加1,也不会影响到父进程的gval。因为fork函数调用后分成了完全不同的进程,父子进程各自拥有独立的进程空间,只是二者共享同一段代码而已。
编程实例:接下来我们编写示例程序来验证前面的内容。
- fork.c
#include
#include
int gval = 10;
int main(int argc, char *argv[])
{
pid_t pid;
int lval = 20;
gval++, lval+=5;
pid = fork(); //创建子进程
if(pid == 0) //子进程
gval+=2, lval+=2;
else if(pid != -1) //父进程
gval-=2, lval-=2;
if(pid == 0)
printf("Child Proc: [%d, %d]\n", gval, lval);
else if(pid != -1)
printf("Parent Proc: [%d, %d]\n", gval, lval);
return 0;
} 编译程序:gcc fork.c -o fork
运行程序:./fork
Child Proc: [13, 27]
Parent Proc: [9, 23]
<结果分析> 从运行结果可以看出,调用fork函数后,父子进程拥有完全独立的内存地址空间。
二 进程和僵尸进程
文件操作中,关闭文件和打开文件同等重要。同样,进程销毁也和进程创建同等重要。如果未未认真对待进程销毁,它们可能将变成僵尸进程。
2.1 僵尸(Zombie)进程
进程完成工作后(执行完main函数中的程序后)应被销毁,但有时这些进程将变成僵尸进程,占用系统中的重要资源,给系统运行带来负担。
僵尸进程:一个进程使用fork()函数创建子进程,如果子进程退出,而父进程并没有调用wait()或waitpid()函数获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中,这种进程称之为僵尸进程。对于僵尸进程,我们应当尽快消灭这种进程。
僵尸状态:进程已经结束运行但未释放进程控制块(PCB),Linux 使用 TASK_ZOMBIE 宏表示此状态。
【参考链接】孤儿进程与僵尸进程[总结]
2.2 僵尸进程产生的原因
为了防止僵尸进程的产生,先解释僵尸进程产生的原因。利用如下两个示例展示调用fork函数产生子进程的终止方式。
- 传递参数并调用 exit 函数。
- main 函数中执行 return 语句并返回值。
向 exit 函数传递的参数值和 main 函数的 return 语句返回的值都会传递给操作系统。而操作系统不会销毁子进程,直到把这些值传递给产生该子进程的父进程。处在这种状态(僵尸状态)下的进程就是僵尸进程。也就是说,将子进程变成僵尸状态的正是操作系统。既然如此,此僵尸进程何时被销毁呢?
“应该向创建子进程的父进程传递子进程的 exit 参数值或 return 语句的返回值。”
如何向父进程传递这些值呢?操作系统不会主动把这些值传递给父进程。只有父进程主动发起请求(函数调用)时,操作系统才会传递该值。换言之,如果父进程未主动要求获取子进程的结束状态值,操作系统将一直保存,并让子进程长时间处于僵尸状态。也就是说,父进程要负责回收自己派生出的子进程。
编程实例:创建一个僵尸进程。zombie.c
#include
#include
int main(int argc, char *argv[])
{
pid_t pid = fork();
if(pid == 0) //子进程
{
puts("Hi, I am a child process");
}
else //父进程
{
prinf("Child process ID: %d\n", pid);
sleep(30);
}
if(pid == 0)
puts("End child process");
else
puts("End parent process");
return 0;
} 编译程序:gcc zombie.c -o zombie
运行程序:./zombie
Child process ID: 130217
Hi, I am a child process
End child process
End parent process
程序开始运行后,将在如上所示状态暂停。跳出这种状态前(30秒内),可以验证一下子进程是否为僵尸进程。该验证可以在其他控制台窗口进行。验证结果如下图所示:

可以看出,PID为 130217 的进程状态为僵尸状态([zombie])。另外,经过30秒的等待时间后,PID为 130216 的父进程和之前的僵尸子进程同时销毁。
《提示》后台处理(Background Processing)
后台处理是指将控制台(终端)窗口中的指令放到后台运行的方式。如果以如下方式运行上述示例,则程序将在后台运行(& 将出发后台处理)。
./zombie &
如果采用这种方式运行,即可在同一控制台(终端)窗口输入下列命令,无需另外再打开新的控制台。如下图所示。
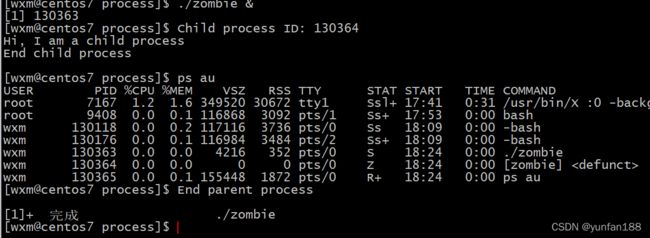
2.3 销毁僵尸进程方法1:利用 wait 函数
为了销毁子进程,父进程应主动请求获取子进程的返回值。接下来讨论父进程发起请求的具体方法,共有2种,其中之一就是调用 wait 函数。
- wait() — 等待一个子进程结束运行或终止运行。
#include
pid_t wait(int *stat_loc);
//参数说明
//stat_loc: 指向保存子进程结束时传递的返回值所在的内存空间地址
//返回值: 成功时返回终止的子进程ID,失败时返回-1 调用 wait 函数时如果已有子进程终止,那么子进程终止时传递的返回值(exit 函数的参数值、main 函数的return 返回值)将保存到该函数的参数 stat_loc指针所指向的内存空间。但函数参数指向的单元中还包含其他信息,因此需要通过下列宏进行分离。
- 以下几个宏是用于判断进程退出时的状态的,可分为三组:
(1)WIFEXITED(status) :若计算结果为“真”(true),则表示子进程正常终止。
WEXITSTATUS(status):如果 WIFEXITED(stat_val) 为真,则使用此宏 —> 获取子进程的退出返回值。
(2)WIFSIGNALED(status):若计算结果为“真”(true),则表示子进程异常终止。
WTERMSIG(status):如果 WIFSIGNALED(stat_val) 的结果为真,则使用此宏 —> 获取导致子进程终止的那个信号的编号。
(3)WIFSTOPPED(status):若计算结果为“真”(true),则表示子进程处于暂停状态。
WSTOPSIG(status):如果 WIFSTOPPED(stat_val) 的计算结果为真,则使用此宏 —> 获取使子进程暂停运行的那个信号的编号。
WIFCONTINUED(status):若计算结果为“真”(true),则表示进程暂停后已经继续运行。
《说明》C语言的条件表达式中,是用“非零值”来表示真,用“零值”来表示假,而不像Java语言那样使用 true 或 false 关键字来表示真或假。
【参考链接】进程控制之wait函数
也就是说,向 wait 函数传递变量 status 的地址时,调用 wait 函数后应编写如下代码。
if(WIFEXITED(status)) //是正常终止吗
{
puts("Normal termination!");
printf("Child Pass num: %d\n", WEXITSTATUS(status)); //那么返回值是多少?
}编程实例:根据上述内容编写示例程序,此示例中不会再让子进程变成僵尸进程。
- wait.c
#include
#include
#include
#include
int main(int argc, char *argv[])
{
int status;
pid_t pid = fork();
if(pid == 0) //子进程执行体
{
return 3; //子进程return语句的返回值
}
else //父进程执行体
{
printf("Child PID: %d\n", pid);
pid = fork(); //继续创建子进程
if(pid == 0)
{
return 7;
}
else
{
printf("Child PID: %d\n", pid);
wait(&status);
if(WIFEXITED(status)) //判断子进程是否正常终止
printf("Child send one: %d\n", WEXITSTATUS(status)); //输出子进程的返回值
wait(&status);
if(WIFEXITED(status))
printf("Child send two: %d\n", WEXITSTATUS(status));
sleep(30); //父进程休眠30秒
}
}
puts("Parent process exit.");
return 0;
} 编译程序:gcc wait.c -o wait
运行程序:./wait
Child PID: 65452
Child PID: 65453
Child send one: 3
Child send two: 7
Parent process exit.
在父进程处于sleep状态时,我们使用 ps 命令查看此时正在运行的进程,并没有发现运行结果中的PID对应的进程,如下图所示。

这是因为在父进程中我们调用了 wait 函数,完全销毁了该进程。另外两个子进程正常终止时的返回值3和7传递到了父进程中,通过宏 WEXITSTATUS(status) 获取得到的。
以上就是通过 wait 函数消灭僵尸进程的方法。调用 wait 函数时,如果没有已终止的子进程,那么 wait 函数将一直阻塞(Blocking)下去,直到有子进程终止,因此需谨慎调用该函数。
2.4 销毁僵尸进程方法2:使用 waitpid 函数
wait 函数会引起进程阻塞,还可以考虑使用 waitpid 函数。这是防止僵尸进程的第二种方法,也是防止阻塞的方法。
- waitpid() — 等待一个子进程结束运行或终止运行,但不会导致父进程阻塞。
#include
pid_t waitpid(pid_t pid, int *statloc, int options);
/*参数说明
pid: 等待终止的目标子进程的ID,若传递-1,则与wait函数相同,可以等待任意子进程终止
statloc: 与wait函数的statloc参数具有相同含义
options: 传递头文件sys/wait.h中声明的常量 WNOHANG,即使没有终止的子进程也不会进入阻塞状态,而是返回0并退出函数。
*/
//返回值: 成功时返回终止的子进程ID(或0),失败时返回-1 编程实例:编写示例程序调用 waitpid 函数。调用 waitpid 函数时,进程不会阻塞。应重点观察这点。
- waitpid.c
#include
#include
#include
int main(int argc, char *argv[])
{
int status;
pid_t pid = fork(); //创建一个子进程
if(pid == 0)
{
sleep(15); //调用sleep函数推迟子进程的结束
return 24;
}
else
{
//while循环中调用waitpid函数,向第3个参数传递WNOHANG,因此,若这之前没有终止的子进程将返回0
while(!waitpid(-1, &status, WNOHANG))
{
sleep(3);
puts("sleep 3sec.");
}
if(WIFEXITED(status))
printf("Child send %d\n", WEXITSTATUS(status));
}
return 0;
} 编译程序:gcc waitpid.c -o waitpid
运行结果:./waitpid
sleep 3sec.
sleep 3sec.
sleep 3sec.
sleep 3sec.
sleep 3sec.
Child send 24《结果分析》可以看出第21行的输出语句共执行了5次。另外,这也证明了 waitpid 函数并未阻塞。
三 信号处理
我们已经知道了进程创建及销毁方法,但还有一个问题没有解决。
“子进程究竟何时终止?调用 waitpid 函数后要无休止地等待吗?”
父进程往往与子进程一样繁忙,因此不能只调用 waitpid 函数以等待子进程终止。接下来讨论解决方案。
3.1 向操作系统求助
子进程终止的识别主体是操作系统,因此,操作系统能把把如下信息告诉正忙于工作的父进程,将有助于构建高效地程序。
“嘿,父进程!你创建的子进程终止运行了!”
此时父进程将暂时放下手头的工作,转头处理子进程终止相关事宜。这是不是既合理又很酷的想法呢?为了实现该想法,我们引入信号处理(Signal Handling)机制。此处的“信号”是在特定事件发生时由操作系统向进程发送的消息。另外,为了响应消息,执行与消息相关的自定义操作的过程称为“信号处理”。
3.2 关于 Java 的题外话:保持开放思维
“技术上要保持开放思维。”
Java语言具有平台移植性,经历了长时间的发展和变化,其优势在企业开发环境下尤为明显。
Java在编程语言层面支持进程或线程,但C语言及C++语言并不支持。也就是说,ANSI 标准并未定义支持进程或线程的函数(Java的方法)。但仔细想想,这也是合理的。进程或线程应该由操作系统提供支持。因此,Windows中按照Windows的方式,Linux中按照Linux的方式创建进程或线程。但Java为了保持平台移植性,以独立于操作系统的方式提供进程或线程的创建方法。因此,Java在语言层面支持进程和线程的创建。
既然如此,Java网络编程是否相对简单?就像大家之前学习过的,网络编程中需要一定的操作系统相关知识,因此,有些人会把网络编程当做系统编程的一部分。基于Java进行网络编程时,的确会摆脱特定的操作系统,所以有人会误认为Java网络编程相对简单。
如果在语言层面支持网络编程所需的所有机制,将延长学习时间。要通过面向对象的方法编写高性能网络程序,需要更多努力和知识。如果有机会,可以尝试Java网络编程,而不仅仅局限于Linux或Windows。Java在分布式环境中提供理想的网络编程模型,这是Java技术的优势所在。
对技术有偏见相当于限制了自己的学习范围,我们应当摒弃技术偏见。也许有人质疑,学习一门技术尚且困难,如何能同时学习多门技术呢?并不是要求大家同步学习,而是要以开放的思维多关注身边的技术。
3.3 信号与 signal 函数
下列进程与操作系统之间的对话是帮助我们理解信号处理而编写的,其中包含了所有信号处理相关内容。
- 进程:“嘿,操作系统!如果之前创建的子进程终止,就帮我调用 zombie_handle 函数。”
- 操作系统:“好的!如果你的子进程终止,我会帮你调用 zombie_handle 函数,你先把该函数要执行的语句编写好!”
上述对话中进程所讲的话相当于“注册信号”过程,即进程发现自己的子进程结束时,请求操作系统调用特定函数。该请求可通过 signal 函数调用来完成(因此称此函数为信号注册函数)。
- signal() — 信号注册函数。
#include
//signal函数原型声明方式1
typedef void (*sighandler_t)(int); //声明一个函数类型sighandler_t
sighandler_t signal(int signo, sighandler_t handler); 函数名:signal
参数:int signo, sighandler_t handler。其中函数指针类型变量 handler 的参数是由 signal 的第一个参数signo 传递给它的。
返回值类型:参数类型为 int 型,返回值为 void 型的函数指针。
函数功能:为了在产生信号时调用,返回之前注册的函数指针。
signal 函数的返回值类型为函数类型,因此函数声明有些繁琐。如果将上面两条声明语句合二为一的话就是下面这种形式。
//signal函数原型声明方式2
void (*signal(int signo, void (*handler)(int))) (int);《提示》强烈推荐大家使用第一种函数原型声明方式,简洁明了,层次分明,不易弄混淆。
调用 signal 函数时,第一个参数为指定的信号ID,第二个参数是为对应信号ID将要调用的信号处理函数的地址值(指针)。发生第一个参数代表的信号时,调用第二个参数所指向的函数。下面给出可以在 signal 函数中注册的部分信号名和对应的信号ID(用符号常量表示)。
- SIGALRM:已到通过调用 alarm 函数注册的时间。
- SIGINT:输入组合键 Ctrl+C
- SIGCHLD:子进程终止
《提示》要查看Linux下支持的所有的信号,可以使用命令:kill -l。
查看 kill 命令的用法:man kill。
接下来编写一个调用 signal 函数的语句完成如下请求:
“子进程终止时则调用 mychild 信号处理函数。”
此时 mychild 函数的函数原型应为形如:void func(int sig)。只有这样才能成为 signal 函数的第二个参数。另外,符号常数 SIGCHLD 定义了子进程终止的情况,应成为 signal 函数的第一个参数。也就是说,signal 函数调用语句如下:
signal(SIGCHLD, mychild);接下来编写 signal 函数的调用语句,分别完成如下2个请求。
“已到通过 alarm 函数注册的时间,请调用 timeout 函数。”
“输入 Ctrl+C 时调用 keycontrol 函数。”
代表这两种信号的符号常数分别为 SIGALRM 和 SIGINT,因此按如下方式调用 signal 函数。
signal(SIGALRM, timeout);
signal(SIGINT, keycontrol);以上就时信号注册过程。注册好信号后,当已注册的信号发生时,操作系统将调用该信号对应的信号处理函数。下面通过示例程序进行验证,先介绍 alarm 函数。
- alarm() — 设置产生 SIGALRM 信号的时间间隔,时间单位:秒。
#include
unsigned int alarm(unsigned int seconds);
//参数说明
//seconds: 设置产生 SIGALRM 信号的时间秒数
//返回值: 返回0或以秒为单位的距 SIGALRM 信号发生所剩时间 如果调用 alarm 函数的同时向它传递一个正整数实参,相应时间后(以秒为单位)将产生 SIGALRM 信号。若向该函数传递实参值0,则之前对 SIGALRM 信号的预约将取消。如果通过该函数预约信号后未指定该信号对应的处理函数,则(通过调用 signal 函数)终止进程,不做任何处理。希望引起注意。
编程实例:编写一个使用 signal 函数进行信号处理的示例程序。
- signal.c
#include
#include
#include
void timeout(int sig)
{
if(sig == SIGALRM)
puts("Time out!");
alarm(5); //每隔5秒重复产生SIGALRM信息
}
void keycontrol(int sig)
{
if(sig == SIGINT)
puts("Ctrl+C pressed");
}
int main(int argc, char *argv[])
{
int i;
signal(SIGALRM, timeout); //注册SIGALRM信号,timeout为该信号处理函数
signal(SIGINT, keycontrol); //注册SIGINT信号,keycontrol为该信号处理函数
alarm(2); //预约2秒后发生SIGALRM信号
for(i=0; i<3; i++)
{
puts("wait...");
sleep(100);
}
puts("main exit.");
return 0;
} 编译程序:gcc signal.c -o signal
运行结果1:./signal
wait...
Time out!
wait...
Time out!
wait...
Time out!
main exit.运行结果2:./signal
wait...
Time out!
wait...
^CCtrl+C pressed
wait...
Time out!
main exit.
运行结果1是没有任何输入时的运行结果。运行结果2是在运行过程中输入 Ctrl+C。可以看到输出 “Ctrl+C press” 字符串。有一点必须说明:
“发生信号时将会唤醒由于调用 sleep 函数而进入阻塞状态的进程。”
调用函数的主体的确是操作系统,但进程处于睡眠状态时无法调用函数。因此,产生信号时,为了调用信号处理函数,将唤醒由于调用 sleep 函数而进入阻塞状态的进程。而且,进程一旦被唤醒,就不会再进入睡眠状态。即使还未到 sleep 函数中规定的时间也是如此。所以,上述示例程序的运行不会真的每次都间隔100秒运行一次,连续输入 Ctrl+C 则有可能运行时间更短。
3.4 利用 sigaction 函数进行信号处理
sigaction 函数它类似于 signal 函数,也是用于信号处理的,而且完全可以代替后者,也更稳定。之所以稳定,是因为如下原因:
“signal 函数在 UNIX 系统的不同操作系统中可能存在区别,但 sigaction 函数则完全相同。”
实际上现在很少使用 signal 函数编写程序,它只是为了保持对旧程序的兼容。
- sigaction() — 信号注册函数。
#include
int sigaction(int signo, const struct sigaction *act, struct sigaction *oldact);
/*参数说明
signo: 与signal函数的第一个参数相同,传递指定信息信息。
act: 对应第一个参数的信号处理函数(信号处理器)信息。
oldact: 通过此参数获取之前注册的信号处理函数地址,若不需要则传递 0 或者 NULL。
*/
//返回值: 成功时返回0,失败时返回-1 《说明》可以在Linux终端输入命令:man 2 sigaction,查看 sigaction 函数的用法详情。
《参考链接》
linux中sigaction函数详解
sigaction(2) — Linux manual page
- sigaction 结构体定义如下:
struct sigaction
{
void (*sa_handler)(int);
void (*sa_sigaction)(int, siginfo_t*, void*);
sigset_t sa_mask;
int sa_flags;
void (*sa_restorer)(void);
};《结构体成员说明》
- sa_handler: 函数指针。此参数和signal()的参数handler相同,代表新的信号处理函数。
- sa_sigaction: 函数指针。它代表另一个信号处理函数,它有三个参数,可以获得关于信号的更详细的信息。当 sa_flags 成员的值包含了 SA_SIGINFO 标志时,系统将使用 sa_sigaction 函数作为信号处理函数,否则使用 sa_handler 作为信号处理。在某些系统中,成员 sa_handler 与 sa_sigaction 被放在联合体中,因此使用时不要同时设置。
- sa_mask: 用来指定在信号处理函数执行期间需要被屏蔽的信号,特别是当某个信号被处理时,它自身会被自动放入进程的信号掩码,因此在信号处理函数执行期间这个信号不会再度产生和发出。
- sa_flags: 用于指示信号处理函数的不同选项,可以通过位操作的或运算(or)连接不同的参数,从而实现所需的选项设置。如果将其赋值为 0 时,则选用所有的默认选项。具体的可选参数值请见下表。
(1)SA_NOCLDSTOP:使父进程在它的子进程暂停或继续运行时不会收到 SIGCHLD 信号。
(2)SA_NOCLDWAIT:使父进程在它的子进程终止运行时不会收到 SIGCHLD 信号,这时子进程如果终止运行也不会成为僵尸进程。
(3)SA_NODEFER :一般情况下, 当信号处理函数正在运行时,内核将阻塞该给定信号。但是如果设置了 SA_NODEFER 标记,那么在该信号处理函数执行期间,内核将不会阻塞该信号,仍能发出这个信号。
(4)SA_ONSTACK:调用sigaltstack(2)提供的备用信号栈上的信号处理程序。如果备用堆栈不可用,则将使用默认堆栈。此标志仅在建立信号处理程序时才有意义。
(5)SA_RESETHAND:当调用信号处理函数后,将信号的处理函数重新设置为默认的处理方式。
(6)SA_RESTART:如果信号中断了进程的某个系统调用,则系统自动启动该系统调用。
(7)SA_SIGINFO:使用 sa_sigaction 成员而不是 sa_handler 作为信号处理函数。
- re_restorer:该成员是一个已经废弃的结构体字段,不要使用,可以忽略掉。
sigaction 结构体的第二个成员 sa_sigaction 是指向函数的指针。它指向的函数有3个参数,其中第二个参数的数据类型为 siginfo_t 结构体指针类型。
- siginfo_t 结构体定义如下:
siginfo_t
{
int si_signo; /* Signal number */
int si_errno; /* An errno value */
int si_code; /* Signal code */
int si_trapno; /* Trap number that caused
hardware-generated signal
(unused on most architectures) */
pid_t si_pid; /* Sending process ID */
uid_t si_uid; /* Real user ID of sending process */
int si_status; /* Exit value or signal */
clock_t si_utime; /* User time consumed */
clock_t si_stime; /* System time consumed */
sigval_t si_value; /* Signal value */
int si_int; /* POSIX.1b signal */
void *si_ptr; /* POSIX.1b signal */
int si_overrun; /* Timer overrun count; POSIX.1b timers */
int si_timerid; /* Timer ID; POSIX.1b timers */
void *si_addr; /* Memory location which caused fault */
long si_band; /* Band event (was int in
glibc 2.3.2 and earlier) */
int si_fd; /* File descriptor */
short si_addr_lsb; /* Least significant bit of address
(since Linux 2.6.32) */
};- sa_flags 可选参数如下表所示
| sa_flags | 对应设置 |
| SA_NOCLDSTOP | 用于指定信号 SIGCHLD,当子进程被中断时,不产生此信号,当且仅当子进程结束运行时产生该信号。 |
| SA_NOCLDWAIT | 当信号为 SIGCHLD时,此选项可以避免子进程变成僵尸进程。 |
| SA_NODEFER | 当信号处理函数正在运行时,不阻塞信号处理函数对应的信号的再次产生。 |
| SA_ONSTACK | 调用sigaltstack(2)提供的备用信号栈上的信号处理程序。如果备用堆栈不可用,则将使用默认堆栈。此标志仅在建立信号处理程序时才有意义。 |
| SA_RESETHAND | 当用户注册的信号处理函数被调用过一次之后,该信号的处理函数恢复为默认的信号处理函数。 |
| SA_RESTART | 使本来不能进行自动重新运行的系统调用自动重新启动运行。 |
| SA_SIGINFO | 表明信号处理函数是由 sa_sigaction 指定,而不是由 sa_handler 指定,它将显示更多处理函数的信息。 |
编程实例:使用 sigaction 函数进行信号处理的示例程序。
- sigaction.c
#include
#include
#include
void timeout(int sig)
{
if(sig == SIGALRM)
puts("Time out!");
alarm(2); //预约每隔2秒产生1个SIGALRM信号
}
int main(int argc, char *argv[])
{
int i;
struct sigaction act; //声明一个sigaction结构体变量
//初始化结构体变量act
act.sa_handler = timeout; //将timeout函数赋值给sa_handler函数指针成员
sigemptyset(&act.sa_mask); //调用sigemptyset函数将sa_mask成员的所有位初始化为0
act.sa_flags = 0; //sa_flag成员同样初始化为0
sigaction(SIGALRM, &act, NULL); //在sigaction函数中注册SIGALRM信号的处理器
alarm(2); //调用alarm函数预约2秒后产生SIGALRM信号
for(i=0; i<3; i++)
{
puts("wait...");
sleep(100);
}
puts("main exit.");
return 0;
} 编译程序:gcc sigaction.c -o sigaction
运行程序:./sigaction
wait...
Time out!
wait...
Time out!
wait...
Time out!
main exit.
3.5 销毁僵尸进程方法3:使用信号处理机制(signal 或 sigaction)
本文前面的2.3节和2.4节我们使用了 wait 和 waitpid 函数来销毁僵尸进程。现在我们也知道了,当子进程终止运行时将会产生 SIGCHLD 信号,我们可以利用这一点,让操作系统内核将产生的SIGCHLD信号消息发送给父进程,然后父进程激活SIGCHLD信号对应的信号处理函数,在信号处理函数中,调用 wait 或者 waitpid 函数来销毁子进程。
使用信号处理机制来销毁僵尸进程的方式的好处就是父进程不需要无休止地等待,因为它不知道子进程究竟何时终止运行,这就完美解决了本节开始我们提出的那个问题。接下来我们使用 sigaction 函数编写示例程序。
编程实例:使用 sigaction 函数的信号处理机制来销毁僵尸进程的示例。
- remove_zombie.c
#include
#include
#include
#include
#include
#include
void read_childproc(int sig)
{
int status;
pid_t pid;
pid = waitpid(-1, &status, WNOHANG); //或者 pid = wait(&status);
if(WIFEXITED(status))
{
printf("[%ld]Remove proc ID: %d\n", time(NULL), pid);
printf("Child send: %d\n", WEXITSTATUS(status));
}
}
int main(int argc, char *argv[])
{
pid_t pid;
struct sigaction act;
act.sa_handler = read_childproc;
sigemptyset(&act.sa_mask);
act.sa_flags = 0;
sigaction(SIGCHLD, &act, NULL); //注册SIGCHLD信号对应的处理器,若子进程终止运行,则调用信号处理函数
//read_childproc,在该处理函数中调用了waitpid函数,所以子进程将正常终止,
//不会成为僵尸进程。
puts("Start main ...................................");
pid = fork(); //创建子进程1
if(pid == 0) //子进程1执行区域
{
printf("[%ld]Hi! I`m child1 process\n", time(NULL));
sleep(10);
return 12;
}
else //父进程执行区域
{
printf("Child1 proc ID: %d\n", pid);
pid = fork(); //创建子进程2
if(pid == 0) //子进程2执行区域
{
printf("[%ld]Hi! I`m child2 process\n", time(NULL));
sleep(15);
exit(24);
}
else
{
int i;
printf("Child2 proc ID: %d\n", pid);
for(i=0; i<5; i++)
{
printf("[%ld]Parent proc wait...%d\n", time(NULL), i+1);
sleep(5);
}
}
}
puts("End main .....................................");
return 0;
} 编译程序:gcc remove_zombie.c -o remove_zombie
运行结果:./remove_zombie
Start main ...................................
Child1 proc ID: 13727
[1641547396]Hi! I`m child1 process
Child2 proc ID: 13728
[1641547396]Parent proc wait...1
[1641547396]Hi! I`m child2 process
[1641547401]Parent proc wait...2
[1641547406]Remove proc ID: 13727
Child send: 12
[1641547406]Parent proc wait...3
[1641547411]Parent proc wait...4
[1641547411]Remove proc ID: 13728
Child send: 24
[1641547411]Parent proc wait...5
End main .....................................《代码说明》父进程共创建了2个子进程,为了等待 SIGCHLD 信号的发生,使父进程共暂停5次,每次间隔5秒。发生信号时,父进程将被唤醒,因此实际暂停时间不到 25 秒,为了方便知道进程的开始时间和结束时间差,我在程序中添加了时间打印信息。
《结果说明》从运行结果可以看出,当两个子进程终止运行后,都被正常销毁了,并没有变成僵尸进程。而且父进程实际暂停时间不到25秒,而是15秒,这是因为两个子进程终止运行时各自产生了一个 SIGCHLD 信号,从而使2次调用 sleep 函数失效,减少了10秒钟的时间。
《拓展说明》如果在上面的 remove_zombie.c 程序中将两个子进程的 sleep 时间设置成相同,比如都是 sleep(10),就有可能出现下面的运行结果。
$ ./remove_zombie
Start main ...................................
Child1 proc ID: 13642
[1641547055]Hi! I`m child1 process
Child2 proc ID: 13643
[1641547055]Parent proc wait...1
[1641547055]Hi! I`m child2 process
[1641547060]Parent proc wait...2
[1641547065]Remove proc ID: 13642
Child send: 12
[1641547065]Parent proc wait...3
[1641547070]Parent proc wait...4
[1641547075]Parent proc wait...5
End main .....................................<结果分析> 可以看到,子进程child2 终止时产生的 SIGCHLD 信号并没有被内核通知给父进程,也就没有触发 SIGCHLD 信号对应的信号处理函数 read_childproc 的执行。可能的原因是:在同一时刻,两个子进程同时产生了 SIGCHLD 信号,并且信号要通知的进程是同一个父进程,内核就只选择了其中最先产生该信号的进程,而忽略了另一个,这两个进程产生 SIGCHLD 信号的时间间隔极短。
未完待续。。。在下一篇博文中,我们将利用 fork 函数编写多进程并发服务器端。
参考
《TCP-IP网络编程(尹圣雨)》第10章 - 多进程服务器端
《Linux C编程从基础到实践(程国钢、张玉兰)》第7章 - Linux的进程、第8章 - Linux的信号