Flink + TiDB,体验实时数仓之美
▼ 关注「Apache Flink」,获取更多技术干货 ▼
摘要:本⽂由社区志愿者 L 帮忙整理,内容来源⾃王天宜在 7 月 10 日 Apache Flink x TiDB Meetup · 北京站分享的《Flink + TiDB,体验实时数仓之美》。主要内容包括:
实时数仓的经典架构
Flink 在 TiDB 上的实时读写场景
Flink + TiDB 的典型用户案例
Tips:点击「阅读原文」预约 FFA 2021~
一、实时数仓经典架构

实时数仓有三个著名的分水岭:
第一个分水岭是从无到有,Storm 的出现打破了 MapReduce 的单一计算方式,让业务能够处理 T+0 的数据。
第二个分水岭是从有到全,Lambda 与 Kappa 架构的出现,使离线数仓向实时数仓迈进了一步,而 Lambda 架构到 Kappa 架构的演进,实现了离线数仓模型和实时数仓模型的紧密结合。
第三个分水岭是从繁到简,Flink 技术栈的落地使实时数仓架构变得精简,并且是现在公认的流批一体最佳解决方案。
未来是否会有其他的架构呢?我觉得一定会有,可以大胆猜测一下,可能是 OLTP 和 OLAP 相结合的 HTAP 场景,也有可能是分析与服务一体化的 HSAP 的场景。
1.1 Storm 架构
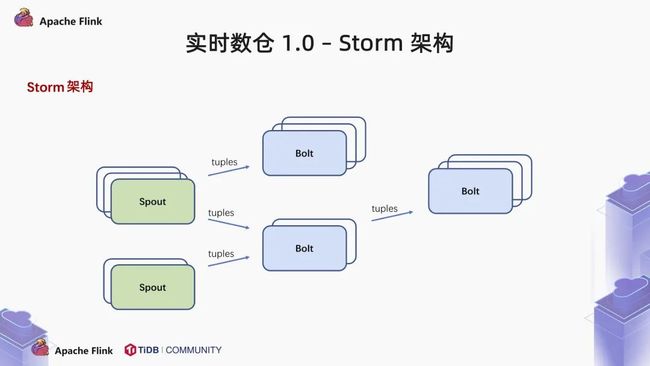
首先来看一下第一个分水岭,Storm 架构。Storm 是 Twitter 开源的分布式实时大数据处理框架,后来捐赠给了 Apache 社区,被业界称为实时版的 Hadoop。之前通用的 Hadoop 的 MapReduce 存在两大问题:一是运维成本高,二是高延迟影响业务处理速度。在此背景下,Storm 开始逐渐取代 MapReduce,成为了流式计算中的佼佼者。2017 年,Storm 成为了天猫双十一的流计算主流技术栈。
在这样一个拓扑中,包含了 spout 和 bolt 两种角色。数据在 spout 中传递,这些 spout 将数据以 tuples 的形式发送。Bolt 负责转换数据流,一般来说,简单的数据转换一个 bolt 就可以完成,而复杂的数据转换需要多个 bolt 串行完成。
Storm 架构,能够解决低延迟的问题,但是这个框架并不完美,有一个很大的痛点,Storm 无法支持基于时间窗口的逻辑处理。这个问题导致了 Storm 无法跨周期计算。为了解决这个问题,Storm 的爸爸 Nathan Marz 提出来 Lambda 架构。
1.2 Lambda & Kappa 架构
Lambda 架构可以分解为三层:
Batch layer:全体的数据,离线数据,更新 batch view。
Real time layer (speed layer):实时数据,增量流数据,更新 real time view。
Serving layer:用于合并 batch view 与 real time view,得到最终的数据集。

Lambda 相对来说需要维护两套架构,使用成本较高:
Batch enging & Real-time enging 两路架构,相互独立。
逻辑完全不同,对齐困难。
技术栈与模块多,结构复杂。

LinkedIn 的 Jay 为了简化这个逻辑,提出了 Kappa 架构,删除了批处理的逻辑,认为只需要流处理就可以了。从设计上讲,我们可以思考几个问题:
为什么不能改进流计算让它处理所有全量数据?
流计算天然的分布式性注定其扩展性一定是很好的,能够通过添加并发来处理海量数据?
如何使用流计算对全量数据进行重新计算?
使用 kafka 等 MQ 保存数据,需要几天就保存几天;当需要全量数据时,重新起一个流计算实例,从头开始读取数据进行处理,输出到结果集中存储;当新的实例完成后,停止老的流式计算实例,并且删除旧的结果。
1.3 Flink 架构
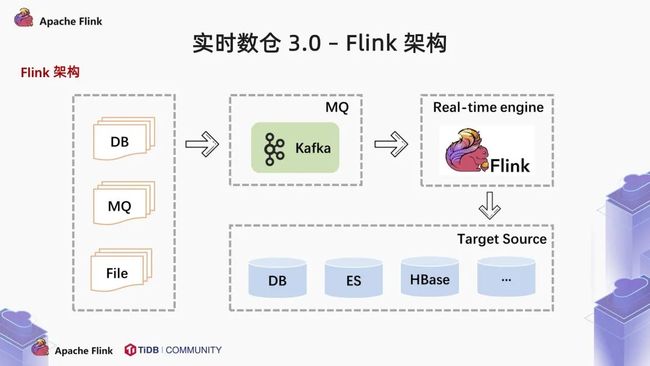
我们常说,天下武功,唯快不破。Flink 是一款 native streaming 的计算引擎,在实时计算场景最关心的就是速度快,延迟低。以 Flink 为计算引擎的实时数仓架构,重度依赖 OLAP 引擎。简单来说,就是将计算的压力从实时计算引擎转嫁到了 OLAP 分析引擎上,在应用层的分析能够更灵活。
一般来说,前端不同的数据源将数据写入 MQ 中,由 Flink 消费 MQ 中的数据,做一些简单的聚合操作,最后将结果写入 OLAP 数据库中。
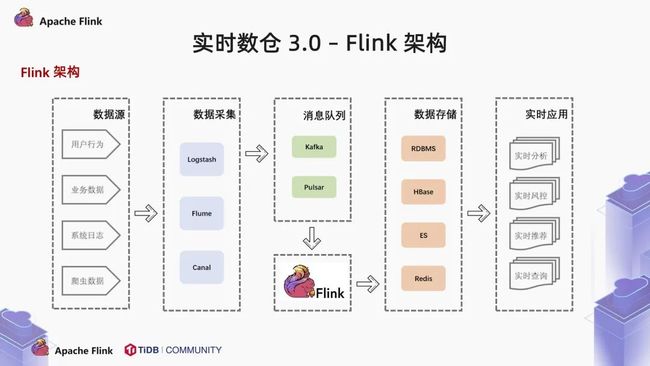
我们会遇到一些问题:
随着业务的变化,会引入越来越多的实时计算的需求,会有越来越多的实时分析,实时风控,实时推荐,实时查询场景。数据存储层没有统一的管理,使得单一的数据存储架构无法应对多变的需求。
此时我们需要思考两个问题:
怎样才能统一规划管理数据?使用数据仓库。
如何才能实现实时处理?使用实时计算引擎。
我们将离线数仓的一些设计架构结合实时计算引擎,就形成了标准的以 Flink + OLAP 为核心的实时数仓架构。这种架构我们称之为烟囱式的实时数仓。烟囱式的实时数仓会产生数据孤岛,导致严重的代码耦合,每次遇到新的需求,都要从原始数据重新计算。

那么什么才是一个好的数据模型呢?这里我们可以借鉴一下传统的离线数仓的架构,将数据存储层细分成 ODS,DWS 和 DWS。基于这样的结构,可以统一规范,更稳定,业务适配性也更强。

总结一下几种不同形态的实时数仓架构:从计算引擎上来看,Lambda 架构需要维护流批两套计算引擎,相对较为麻烦。同时维护两套引擎对于开发者的成本也是较高的。相比于 Lambda 和 Kappa 架构,Flink 把一部分的关联和预聚合操作从前面移到了后面,高度依赖于 OLAP 引擎。
应对逻辑变更的重算需求,Lambda 靠着独立的批处理引擎进行重算,Kappa 架构通过重新统计消息队列里面的数据进行重算,而 Flink 也需要将消息队列中的数据重新导入到 OLAP 引擎中重算。
在过去,我们面对实时,数仓的逻辑是:性能不够,架构来补。
在现在,我们面对实时,数仓的逻辑是:既要、还要,全都要。
1.4 实时数仓架构未来展望
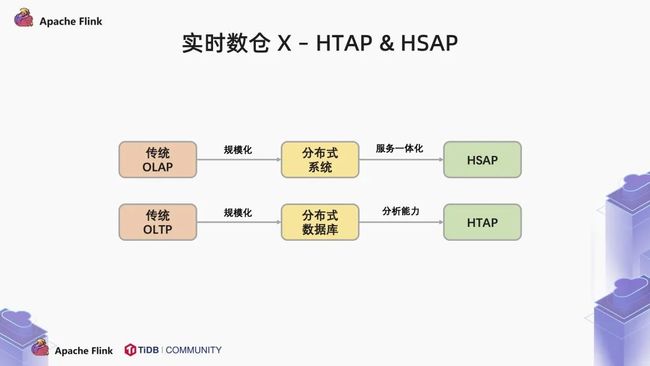
未来是一定会有第四个分水岭的。我们可以随意的畅想一下。
对于分布式 OLTP 数据库,我们通过添加分析类的引擎,最终实现将 OLTP 与 OLAP 合二为一,在使用上作为一个统一,在存储上分离,而做到 OLAP 与 OLAP 互不干扰。这种 HTAP 的架构允许我们在 OLTP 的库里面直接分析,而又不影响在线的业务,那么他会不会取代大数据系统呢?
在我看来,用户的业务数据只是交易系统的一部分。还有大量的用户行为事件,日志、爬虫数据等信息需要汇总到数仓中进行分析。如何做到技术栈的统一也是未来大数据行业需要面临的巨大的挑战。友商 hologress 已经为我们做出了一个典范。把 Flink + Holo 这一套系统服务化,用户不需要去学习和接受每个产品的问题和局限性,这样能够大大简化业务的架构,提升开发效率。
当然,我也看到的是越来越多的 HTAP 产品 HSAP 化,越来越多的 HSAP 产品 HTAP 化。边界与定义越来越模糊,就好比说 TiDB 有了自己的 DBasS 服务 TiDB Cloud,Holo 也有行存和列存两种引擎。在我看到的是,越来越多的用户,将爬虫业务,日志系统接入 TiDB 中,HTAP 和 HSAP 都将成为数据库生态中不可或缺的重要组成部分。
二、Flink 在 TiDB 上的实时读写场景
接下来我会从实时写入场景,实时维表场景,CDC 场景和混合场景四个方面介绍一下 Flink 与 TiDB 适配方案。在此之前,我们可以看一下 Flink + TiDB 的生态架构全貌。
2.1 Flink + TiDB 的生态架构全貌

一般来说,我们将 Flink + TiDB 的生态架构分成四层:
第一层是数据源。数据源可以是多种多样的,比如说 MySQL Binlog,比如说爬虫的数据,比如说平面的 log 文件。
第二层是实时计算层,也就是我们说的 Flink。不过在实时计算层之前,数据源的数据会通过采集工具写入 MQ 中,由 Flink 来消费 MQ 中的增量数据。
第三层是数据存储。由于 Flink 相比于其他技术栈来说更依赖于 OLAP 引擎,需要一款强大的数据库作为支撑。比如说 TiDB,我们既有适用于在线系统的行存 TiKV 引擎,也有适用于分析计算的列存 TiFlash 引擎。我觉得作为数据仓库,数据的流动性是最重要的。所以我们不仅有数据流入的方案,也可以通过 TiCDC 将数据流出到其他的外部应用中。
最后一层是后端应用。可能是直接连接实时监控系统,实时报表系统,也可能是将数据流入到 ES 这样的搜索引擎中,进行下一步操作。
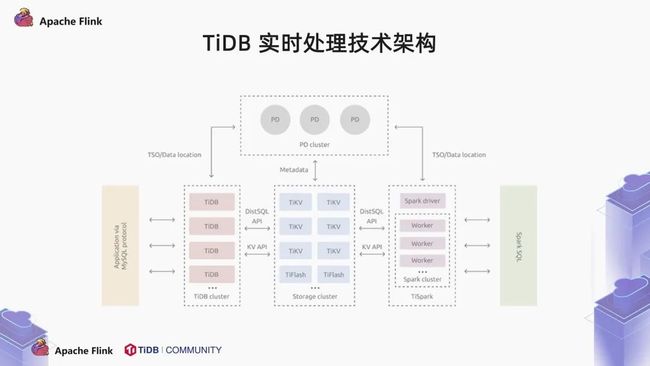
我们可以简单的看一下 TiDB 的体系架构,TiDB 主要分为三个部分:
最前面的计算层 TiDB 负责接受客户端的消息请求,将请求转化为分布式的执行计划,并且下推到存储层。TiDB 的存储层分为两种引擎,一种是行存的 TiKV 引擎,对于 OLTP 的查询更加友好。一种是列存的 TiFlash 引擎,对于 OLAP 的查询更加友好。
TiDB 兼容 MySQL 5.7 协议,我们常说,TiDB 是一个大号的 MySQL,其实我们希望用户能够像使用单节点的 MySQL 那样使用 TiDB。不用考虑什么分布式,不用考虑分库分表。这一切操作由 TiDB 来完成。那么 TiDB 是如何将执行计划下推的呢?这中间必然涉及到 metadata。我们的元数据存储在 PD server 中。TiDB 到 PD 中获取到数据分布的信息后再下推执行计划。所以我们也称 PD 是 TiDB 集群的大脑。
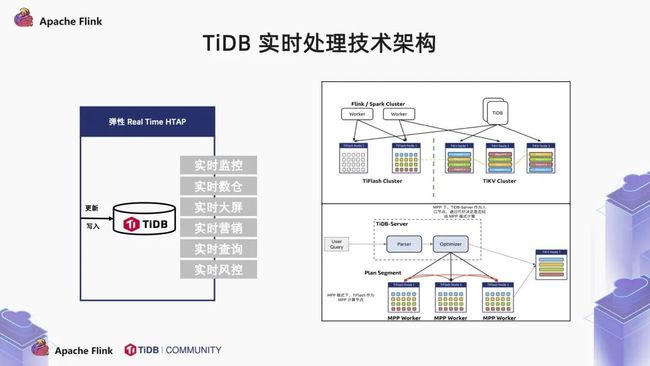
刚才提到过 Flink 重度依赖于 OLAP 引擎,我们也可以考量一下 TiDB 的 OLAP 能力。我们一直在提 HTAP,在同一套库中,既处理 OLTP 的业务,也处理 OLAP 的业务。
那么 HTAP 最重要的是什么,在我看来无非是资源隔离。如何做到 AP 的重量级查询不影响在线业务,是 HTAP 的基石。在这里,我们使用两套存储引擎,就如刚才所说,行存的 TiKV 天然的对点查比较友好,列存的 TiFlash 天然对重分析类查询比较友好。谈不上隔离,自始至终就不在一起。
2.2 实时写入场景

其实我们一直在讨论 Flink + TiDB 的链路解决方案。消息队列这个词反复地出现。Kafka,RabbitMQ,RocketMQ 这一类 MQ 工具,主要做的就是一发,一存,一消费这三件事情。我们可以看到使用 flink-sql-connector-kafka 这个 jar 包,可以轻松地通过 Flink 消费 Kafka 的数据。

与 MySQL 相似,我们可以使用 Flink 的 jdbc connector 将数据从 Flink 写入到 TiDB 中。
那么这里需要注意的是,如果 TiDB 的表没有设置主键,Flink 使用的是 Append Only 模式。如果 TiDB 中的表设置了主键,后面的数据会根据主键覆盖前面冲突的数据。
此外,前端业务量的突增可能导致流量高峰。那这种情况下,为了减少对下游数据库的压力,我们可以考虑在 Flink 与 TiDB 中间,接一个 Kafka 做削峰。
2.3 实时维表场景

还有一种非常重要的场景是实时维表场景。大家都知道,为了控制事实表的大小,我们尽可能地将事实表中的信息抽象成 ID。
在传统的数仓中,DW 层可能会做一些聚合操作。在现有的数仓体系结构中,单节点的 MySQL 可能无法承载庞大的事实表体量,于是我们把他放在 TiDB 中,而维度信息,可能存储在 TiDB 中,也可能存放在外部设备中,如 MySQL 等其他的数据库。通过 Flink,我们可以读取不同数据源的信息,在 Flink 中做预聚合。完成事实表与维表拼接的操作。
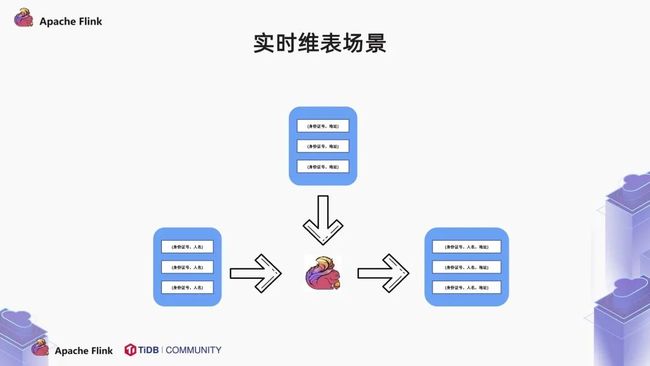
来看这个案例,实时表中存储了身份证编号等信息,维度表在外部设备中,存储了身份证相关的详细信息,比如说地址,发证时间等等。事实表增量的数据同步到 Flink 中,在 Flink 中做了预聚合,拼成宽表最终写入 TiDB 中。
2.4 CDC 场景

接下来看一下 CDC 的场景。什么是 CDC 呢?CDC 就是 change data capture。增量数据捕获。通过简单的配置,我们可以在 cdc 中捕获 TiKV 的数据变化,从而同步到消息队列中。
2.5 混合场景

除了以上的单一场景,还有很多时候是多种场景融合在一起的复杂场景。比如说增量数据从 TiDB 中通过 CDC 同步到消息队列中。
Flink 消费 Kafka 的增量数据的同时,也进行了维表关联的操作,最后写入到 TiDB 中。在这种情况下,我们可以考虑添加 TiFlash 结点,从而扩展 TiDB 的 OLAP 查询能力。

我们常说,功能不够,架构来凑。我个人有一种观点,做开源产品,功能不够的时候,无非是两条路来解决:
精力多的可以考虑自己手动修改源码。
精力少的可以考虑通过不同组件的拼接以搭积木的方式完善功能。
当然,TiDB 是一个以开源为初衷的产品,用户有什么想法可以直接到 github 上提 PR 或者到我们的开源社区,提一些建议。
我们来看这种情况,目前来看 TiDB 是没有提供物化视图的功能的。那么我们是不是可以通过 Flink 处理流数据的方式将数据写到 TiDB 中,生成一张动态表,模拟物化视图的场景呢?
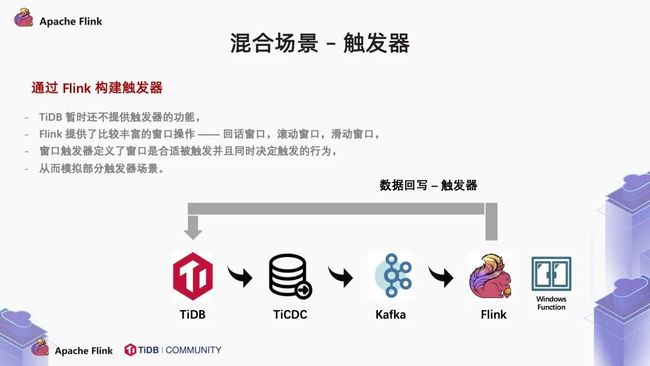
再比如说,TiDB 暂时也不提供触发器的功能,但是 Flink 提供了比较丰富的窗口操作。Flink 的窗口触发器不仅定义了窗口何时被触发,也定义了触发的行为。那此时,将数据回写到 TiDB 中,是不是可以模拟一些触发器的操作呢?
三、Flink + TiDB 的典型用户案例
最后,给大家分享几个比较经典的案例。
3.1 360 的实时报表案例

第一个案例是 360 基于 Flink + TiDB 构建的实时报表业务。利用 Flink 强大的流处理能力,两小时内大概写入 1.5 亿的数据,平均下来 1s 大概是 2W 的 TPS。我们可以看一下整体的架构,上游的数据源通过同步工具将数据写入到 Kafka 中,Flink 消费 Kafka 中的数据,在 Flink 中完成一个轻量级的聚合操作。然后写入到 TiDB 中。通过 TiFlash 的配置,提高了对于 OLAP 查询的处理能力。数据最终在 TiDB 中完成各种维度的聚合操作,实现了离线报表的在线统计。
3.2 小红书的物化视图案例

第二个是小红书的物化视图案例。TiDB 的增量数据通过 TiCDC 集群写入到 Kafka 中,再由 Flink 消费 Kafka 中的数据。在 Flink 中做了 Join 和聚合操作,最后的数据回写到 TiDB 中。实现了一张通过 Flink 动态表模拟的 TiDB 物化视图。最终业务方通过前端的应用拉去报表。这个案例中,QPS 大概是在 4w 每秒,单表 50 亿的数据,所以采用分区表实现。
3.3 贝壳金服的实时维表案例

最后是贝壳金服的实时维表案例。贝壳金服上游的数据是存在 MySQL 中的,由 Canal 拉取 MySQL 集群的 Binlog。然后推入到 Kafka 中。Flink 消费 Kafka 中的增量数据,进行聚合操作。最后写入到 TiDB 中,供其他业务调用。
Flink Forward Asia 2021
2022 年 1 月 8-9 日,FFA 2021 重磅开启,全球 40+ 多行业一线厂商,80+ 干货议题,带来专属于开发者的技术盛宴。
大会官网:
https://flink-forward.org.cn
大会线上观看地址 (记得预约哦):
https://developer.aliyun.com/special/ffa2021/live

更多 Flink 相关技术问题,可扫码加入社区钉钉交流群~

 戳我,预约 FFA 2021~
戳我,预约 FFA 2021~