python常用表达式

本章 Python 教程的目的是对正则表达式进行详细的描述性介绍。本介绍将解释正则表达式的理论方面,并将向您展示如何在 Python 脚本中使用它们。
术语“正则表达式”,有时也称为 regex 或 regexp,起源于理论计算机科学。在理论计算机科学中,它们用于定义具有某些特征的语族,即所谓的正则语言。每个正则表达式都存在一个接受由正则表达式定义的语言的有限状态机 (FSM)。您可以在我们的网站上找到用 Python实现的有限状态机。
正则表达式在编程语言中用于过滤文本或文本字符串。可以检查文本或字符串是否与正则表达式匹配。正则表达式的一大优点:正则表达式的语法对于所有编程和脚本语言都是相同的,例如 Python、Perl、Java、SED、AWK 甚至 X#。
第一个包含使用正则表达式功能的程序是 Unix 工具 ed(编辑器)、流编辑器 sed 和过滤器 grep。
操作系统中还有另一种机制,不应将其误认为正则表达式。通配符,也称为通配符,在语法上与正则表达式非常相似。但是,语义差异很大。Globbing 在许多命令行 shell 中都为人所知,例如 Bourne shell、Bash shell 甚至 DOS。例如,在 Bash 中,命令“ls .txt”列出了所有以 .txt 结尾的文件(甚至目录);在正则表达式符号中“ .txt”没有意义,它必须写成“.*.txt”
介绍
当我们介绍顺序数据类型时,我们了解了“in”运算符。我们在下面的例子中检查,如果字符串“easyly”是字符串“Regular expressions easy Explain!”的子字符串:
s = "正则表达式很容易解释!"
“容易” 在 小号
输出:
真的
我们用下图一步一步地展示了这个匹配是如何执行的: 我们检查字符串 sub = "abc"

包含在字符串 s = "xaababcbcd" 中

顺便说一下,字符串 sub = "abc" 可以看作是一个正则表达式,只是一个非常简单的表达式。
首先,我们检查两个字符串的第一个位置是否匹配,即 s[0] == sub[0]。这在我们的例子中是不满足的。我们用红色标记这一事实:
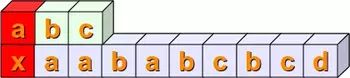
然后我们检查,如果 s[1:4] == sub。换句话说,我们必须首先检查 sub[0] 是否等于 s[1]。这是真的,我们用绿色标记它。然后,我们必须比较下一个位置。s[2] 不等于 sub[1],因此我们不必进一步处理 sub 和 s 的下一个位置:

现在我们必须检查 s[2:5] 和 sub 是否相等。前两个位置相等但第三个位置不相等:

下面的步骤应该很清楚了,不做任何解释:

最后,我们与 s[4:7] == sub 完全匹配:

一个简单的正则表达式
正如我们在上一节中已经提到的,我们可以将介绍中的变量“sub”视为一个非常简单的正则表达式。如果你想在 Python 中使用正则表达式,你必须导入 re 模块,它提供了处理正则表达式的方法和函数。
在 Python 中表示正则表达式
在其他语言中,您可能习惯于在斜杠“/”中表示正则表达式,例如,这是 Perl、SED 或 AWK 处理它们的方式。在 Python 中没有特殊符号。正则表达式表示为普通字符串。
但是这种方便带来了一个小问题:反斜杠是正则表达式中使用的特殊字符,但也用作字符串中的转义字符。这意味着 Python 将首先评估字符串的每个反斜杠,然后 - 没有必要的反斜杠 - 它将被用作正则表达式。防止这种情况的一种方法是将每个反斜杠都写为“\”,并以此方式保留它以用于正则表达式的评估。这会导致非常笨拙的表达。例如,正则表达式中的反斜杠必须写成双反斜杠,因为反斜杠在正则表达式中用作转义字符。因此,必须引用它。这同样适用于 Python 字符串。反斜杠必须用反斜杠引用。因此,匹配 Windows 路径的正则表达式“
克服这个问题的最好方法是将正则表达式标记为原始字符串。我们的 Windows 路径示例的解决方案看起来像这样作为一个原始字符串:
r"C:\\程序"
让我们再看一个例子,对于习惯使用通配符的人来说,这可能会非常令人不安:
r"^a.*\.html$"
我们前面示例的正则表达式匹配所有以“a”开头并以“.html”结尾的文件名(字符串)。我们将在下面的章节中详细解释上面例子的结构。
正则表达式的语法

r"猫"
是一个正则表达式,虽然非常简单,没有任何元字符。我们的 RE
r"猫"
例如,匹配以下字符串:“猫和老鼠不能成为朋友。”
有趣的是,前面的示例已经显示了一个“最喜欢”的错误示例,不仅初学者和新手经常犯,而且正则表达式的高级用户也经常犯这种错误。这个例子的想法是匹配包含单词“cat”的字符串。我们在这方面取得了成功,但不幸的是,我们也匹配了很多其他词。如果我们在一个字符串中匹配“cats”可能仍然没问题,但是所有包含这个字符序列“cat”的单词呢?我们匹配诸如“教育”、“交流”、“伪造”、“后果”、“牛”等词。这是一种“过度匹配”的情况,即我们收到了积极的结果,根据我们要解决的问题,这些结果是错误的。
我们已经在上图中说明了这个问题。深绿色圆圈 C 对应于我们想要识别的“对象”集。但是我们匹配集合 O(蓝色圆圈)的所有元素。C 是 O 的子集。此图中的集合 U(浅绿色圆圈)是 C 的子集。U 是“欠匹配”的情况,即如果正则表达式未匹配所有预期字符串。如果我们尝试修复之前的 RE,使其不会创建过度匹配,我们可能会尝试表达式
r“猫”
. 这些空白阻止了上面提到的“教育”、“伪造”和“分支”等词的匹配,但我们又犯了另一个错误。字符串“名叫奥斯卡的猫爬上了屋顶。”怎么样?问题是我们不希望有一个逗号,而只是在“cat”这个词周围有一个空格。
在我们继续描述正则表达式的语法之前,我们想解释一下如何在 Python 中使用它们:
导入 re
x = re 。search ( "cat" , "猫和老鼠不能成为朋友。" )
打印( x )
输出:
x = 重新。搜索(“牛” , “猫和老鼠不能成为朋友。” )
打印(x )
输出:
没有任何
在前面的示例中,我们必须导入模块 re 才能使用正则表达式。然后我们使用了 re 模块中的搜索方法。这很可能是本模块中最重要和最常用的方法。re.search(expr,s) 检查字符串 s 中是否出现与正则表达式 expr 匹配的子字符串。将返回满足此条件的第一个子字符串(从左起)。如果匹配是可能的,我们就会得到一个所谓的匹配对象作为结果,否则该值将为 None。这种方法已经足以在 Python 程序中以基本方式使用正则表达式。我们可以在条件语句中使用它:如果正则表达式匹配,我们将返回一个 SRE 对象,该对象被视为 True 值,如果不匹配,则返回值 None 被视为 False:
如果 重新。search ( "cat" , "猫和老鼠不能成为朋友。" ):
print ( "找到某种猫:-)" )
else :
print ( "没有找到猫:-)" )
输出:
发现了某种猫:-)
如果 重新。search ( "cow" , "A cat and a rat 不能成为朋友。" ):
print ( "Cats and Rats and a cow." )
else :
print ( "No cow around." )
输出:
周围没有牛。
任何字符
让我们假设我们对前面的例子没有兴趣识别单词 cat,而是所有以“at”结尾的三个字母的单词。正则表达式的语法提供了一个元字符“.”,它用作“任何字符”的占位符。我们示例的正则表达式可以这样写: r" .at " 这个正则匹配三个字母的单词,由空格隔开,以“at”结尾。现在我们得到诸如“rat”、“cat”、“bat”、“eat”、“sat”等许多词。
但是,如果文本包含诸如“@at”或“3at”之类的“单词”怎么办?这些词也匹配,这意味着我们再次导致过度匹配。我们将在下一节中学习解决方案。
字符类
方括号“[”和“]”用于包含字符类。[xyz] 表示例如“x”、“y”或“z”。让我们看一个更实际的例子:
r"M[ae][iy]er"
这是一个正则表达式,它匹配德语中很常见的姓氏。具有相同发音和四种不同拼写的名称:Maier、Mayer、Meier、Meyer 识别此表达式的有限状态自动机可以这样构建:

简化了有限状态机 (FSM) 的图形以保持设计简单。起始节点中应该有一个指向它自己的箭头,即如果处理了大写“M”以外的字符,则机器应保持在起始状态。此外,应该有一个箭头从除最终节点(绿色节点)之外的所有节点指向起始节点,除非预期的字母已被处理。例如,如果机器处于状态 Ma,在处理了“M”和“a”之后,如果可以读取除“i”或“y”之外的任何字符,则机器必须返回到状态“开始”。对这个 FSM 有问题的人不必担心,因为它不是本章其余部分的先决条件。
我们经常需要在更大的字符类之间进行选择,而不是在两个字符之间进行选择。我们可能需要例如“a”和“e”之间或“0”和“5”之间的一类字母。为了管理这样的字符类,正则表达式的语法提供了一个元字符“-”。[ae] [abcde] 或 [0-5] 的简化写法表示 [012345]。
如果我们必须将诸如“任何大写字母”之类的表达式转换为正则表达式,则优势是显而易见的,甚至更令人印象深刻。因此,我们可以写 [AZ],而不是 [ABCDEFGHIJKLMNOPQRSTUVWXYZ]。如果这不能令人信服:为字符类“任何小写或大写字母”写一个表达式[A-Za-z]
还有更多关于破折号的东西,我们用来标记字符类的开始和结束。破折号只有在方括号内使用时才具有特殊含义,并且在这种情况下,仅当它不直接位于开头之后或右括号之前。所以表达式 [-az] 只是在“-”、“a”和“z”三个字符之间进行选择,而没有其他字符。[az-] 也是如此。
练习:[-az] 描述了什么字符类?
答案 字符“-”和所有字符“a”、“b”、“c”一直到“z”。
方括号内唯一的其他特殊字符(字符类选择)是插入符号“^”。如果它直接在开方括号之后使用,则会否定选择。[^0-9] 表示选择“除数字外的任何字符”。方括号内插入符号的位置至关重要。如果它没有定位为左方括号后面的第一个字符,则它没有特殊含义。[^abc] 表示“a”、“b”或“c”以外的任何内容 [a^bc] 表示“a”、“b”、“c”或“^”
Python 中的实践练习
在我们继续介绍正则表达式之前,我们想插入一个 Python 实践练习。我们有辛普森一家的电话列表,没错,就是美国动画电视剧中著名的辛普森一家。有一些人姓Neu。我们正在寻找一个 Neu,但我们不知道名字,我们只知道它以 J 开头。让我们编写一个 Python 脚本,它找到电话簿的所有行,其中包含一个人的描述姓氏和以 J 开头的名字。如果您不知道如何阅读和处理文件,您应该阅读我们的文件管理一章。所以这是我们的示例脚本:
import re
fh = open ( "simpsons_phone_book.txt" )
for line in fh :
if re 。搜索(- [R “J. * NEU” ,线):
打印(线。rstrip ())
FH 。关闭()
输出:
杰克纽 555-7666
Jeb Neu 555-5543
詹妮弗·纽 555-3652
除了下载 simpsons_phone_book.txt,我们还可以通过使用模块 urllib.request 中的 urlopen 直接从网站使用该文件:
import re
from urllib.request import urlopen
with urlopen ( 'https://www.python-course.eu/simpsons_phone_book.txt' ) as fh :
for line in fh :
# line 是一个字节串,所以我们把它转换成 utf- 8:
线 = 线。解码('utf-8' )。rstrip ()
如果 重新。搜索( r "J.*Neu" , line ):
打印( line )
输出:
杰克纽 555-7666
Jeb Neu 555-5543
詹妮弗·纽 555-3652
预定义的字符类
您可能已经意识到解释某些字符类可能非常麻烦。一个很好的例子是字符类,它描述了一个有效的单词字符。这些都是小写和大写字符加上所有数字和下划线,对应于以下正则表达式:r"[a-zA-Z0-9_]"
特殊序列由“\\”和以下列表中的字符组成:
\d 匹配任何十进制数字;等价于集合 [0-9]。
\D \d 的补码。它匹配任何非数字字符;等价于集合 [^0-9]。
\s 匹配任何空白字符;相当于 [ \t\n\r\f\v]。
\S \s 的补码。它匹配任何非空白字符;相当于 [^ \t\n\r\f\v]。
\w 匹配任何字母数字字符;相当于 [a-zA-Z0-9_]。使用 LOCALE,它将匹配集合 [a-zA-Z0-9_] 加上定义为当前语言环境的字母的字符。
\W 匹配 \w 的补码。
\b 匹配空字符串,但只在单词的开头或结尾。
\B 匹配空字符串,但不匹配单词的开头或结尾。
\\ 匹配文字反斜杠。
字界
前面对特殊序列的概述中的\b 和\B 经常没有被正确理解甚至误解,尤其是新手。当其他序列匹配字符时, - 例如 \w 匹配“a”、“b”、“m”、“3”等字符,- \b 和 \B 不匹配字符。它们根据它们的邻域匹配空字符串,即前驱和后继是哪种字符。所以 \b 匹配 \W 和 \w 字符之间以及 \w 和 \W 字符之间的任何空字符串。\B 是补码,即\W 和\W 之间的空字符串或\w 和\w 之间的空字符串。我们在下面的例子中说明了这一点:
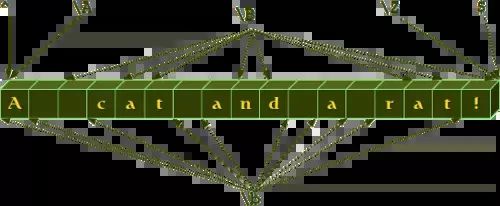
我们将进一步了解“虚拟”匹配字符,即用于标记字符串开头的插入符号 (^) 和用于标记字符串结尾的美元符号 ($) . \A 和 \Z,也可以在我们之前的图表中找到,很少用作插入符号和美元符号的替代品。
匹配开始和结束
正如我们之前在本介绍中所做的那样,表达式 r"M[ae][iy]er" 能够匹配名称 Mayer 的各种拼写,并且该名称可以位于字符串中的任何位置:
import re
line = "他是德国人,叫迈耶。"
如果 重新。search ( r "M[ae][iy]er" , line ):
print ( "I found one!" )
输出:
我找到了一个!
但是如果我们想在字符串的开头并且只在开头匹配正则表达式怎么办?
Python 的 re 模块提供了两个函数来匹配正则表达式。我们已经遇到过其中之一,即search()。在我们看来,另一个具有误导性的名称:match() 误导性,因为 match(re_str, s) 仅在字符串的开头检查 re_str 的匹配项。但无论如何,match() 是我们问题的解决方案,我们可以在以下示例中看到:
" import re
s1 = "Mayer 是一个很常见的名字"
s2 = "他叫 Meyer 但他不是德国人。"
打印(重。搜索([R “M [曝光] [IY] ER” , S1 ))
印刷(重。搜索([R “M [曝光] [IY] ER” , S2 ))
#匹配,因为它与梅耶开始
打印(重。匹配(- [R “M [AE] [IY] ER” , S1 ))
# 不匹配,因为它不以 Meyer 或 Meyer、Meier 等开头:
print ( re . match ( r "M[ae][iy]er" , s2 ))
输出:
没有任何
所以,这是一种匹配字符串开头的方法,但它是 Python 特定的方法,即它不能用于其他语言,如 Perl、AWK 等。有一个通用的解决方案,它是正则表达式的标准:
插入符号 '^' 匹配字符串的开头,并且在 MULTILINE(将在下面进一步解释)模式中也立即在每个换行符之后匹配,而 Python 方法 match() 不这样做。插入符号必须是正则表达式的第一个字符:
" import re
s1 = "Mayer 是一个很常见的名字"
s2 = "他叫 Meyer 但他不是德国人。"
打印(重。搜索(- [R “^ M [AE] [IY] ER” , S1 ))
打印(重。搜索(- [R “^ M [AE] [IY] ER” , S2 ))
输出:
没有任何
但是如果我们按照以下方式连接两个字符串 s1 和 s2 会发生什么?
s = s2 + " \n " + s1
现在字符串不以任何类型的 Maier 开头,但名称跟随一个换行符:
小号 = S2 + “ \ n ” + S1
打印(重。搜索(- [R “^ M [AE] [IY] ER” , š ))
输出:
没有任何
名称尚未找到,因为只检查字符串的开头。如果我们使用多行模式,它会发生变化,可以通过添加以下参数进行搜索来激活:
打印(重。搜索(- [R “^ M [AE] [IY] ER” , š , 再。MULTILINE ))
打印(重。搜索(- [R “^ M [AE] [IY] ER” , š , 再。中号))
打印( re . match ( r "^M[ae][iy]er" , s , re . M ))
输出:
没有任何
前面的示例还表明多行模式不影响匹配方法。match() 从不检查匹配字符串的开头以外的任何内容。
我们已经学习了如何匹配字符串的开头。结局呢?这当然是可能的。美元符号""isusedasametacharacterforthis purpose.''匹配字符串的末尾或字符串末尾的换行符之前。如果在 MULTILINE 模式下,它也会在换行符之前匹配。我们在以下示例中演示了“$”字符的用法:
打印(重。搜索([R “巨蟒\ $” ,“我像Python。” ))
打印(重。搜索([R “巨蟒\ $” ,“我喜欢Python和Perl。” ))
打印(重。search ( r "Python\.$" , "我喜欢 Python。\n有些人更喜欢 Java 或 Perl。" ))
打印( re . search ( r "Python\.$" , "我喜欢 Python。\n有些人更喜欢 Java 或 Perl。", 重新。米))
输出:
没有任何
没有任何
可选项目
如果您认为我们收集的 Mayer 姓名是完整的,那您就错了。世界上还有其他一些国家,例如伦敦和巴黎,他们放弃了他们的“e”。所以我们还有四个名字 ["Mayr", "Meyr", "Meir", "Mair"] 加上我们的旧集合 ["Mayer", "Meyer", "Meier", "Maier"]。
如果我们试图找出一个合适的正则表达式,我们就会意识到我们错过了一些东西。一种告诉计算机“这个“e”可能会或可能不会发生”的方法。使用问号作为表示法。问号声明前面的字符或表达式是可选的。
最终的 Mayer-Recognizer 现在看起来像这样:
r"M[ae][iy]e?r"
一个子表达式由圆括号分组,在这样一个组后面的问号表示这个组可能存在也可能不存在。使用以下表达式,我们可以匹配“2011 年 2 月”或“2011 年 2 月”之类的日期:
r“2 月(ruary)?2011 年”
量词
如果您只使用我们目前介绍的内容,您仍然需要很多东西,尤其是一些重复字符或正则表达式的方式。为此,使用了量词。我们在上一段中遇到过一个,即问号。
标记后的量词(可以是括号中的单个字符或组)指定允许前面元素出现的频率。最常见的量词是
- 问号?
- 星号或星号 *,源自 Kleene 星
- 和加号 +,源自 Kleene 十字
我们之前已经使用了这些量词之一,但没有解释它,即星号。字符或子表达式组后面的星号表示该表达式或字符可以任意重复,甚至零次。
r"[0-9]*"
上面的表达式匹配任何数字序列,甚至是空字符串。r".*" 匹配任何字符序列和空字符串。
练习:编写一个正则表达式,匹配以一系列数字开头的字符串——至少一个数字——后面跟着一个空格。
解决方案:
r"^[0-9][0-9]*"
因此,您使用了加号“+”。没关系,但在这种情况下,您要么通过继续阅读文本而作弊,要么您对正则表达式的了解比我们在课程中介绍的要多:-)
现在我们已经提到了:加号运算符很方便解决前面的练习。加号运算符与星号运算符非常相似,不同之处在于后跟“+”号的字符或子表达式必须至少重复一次。以下是我们使用加量词的练习的解决方案:
加量词的解决方案:
r"^[0-9]+"
如果您使用这个运算符库一段时间,您将不可避免地错过在某些时候重复表达式精确次数的可能性。假设您想识别瑞士信封上地址的最后一行。这些行通常包含一个四位数长的邮政编码,后跟一个空格和一个城市名称。使用 + 或 * 对我们的目的来说太不具体了,下面的表达式似乎太笨拙了:
r"^[0-9][0-9][0-9][0-9] [A-Za-z]+"
幸运的是,有一个替代方案可用:
r"^[0-9]{4} [A-Za-z]*"
现在我们要改进我们的正则表达式。假设瑞士没有城市名称,由少于3个字母,至少3个字母组成。我们可以用 [A-Za-z]{3,} 来表示。现在我们还必须识别带有德国邮政编码(5 位数字)的行,即邮政编码现在可以由四位或五位数字组成:
r"^[0-9]{4,5} [AZ][az]{2,}"
一般语法是 {from, to},这意味着表达式必须至少出现“from”次且不超过“to”次。{, to} 是 {0,to} 的缩写拼写,而 {from,} 是“至少从时间但没有上限”的缩写
分组
我们可以将正则表达式的一部分用括号(圆括号)括起来。这样我们就可以将运算符应用于整个组而不是单个字符。
捕获组和反向引用
括号(圆括号、大括号)不仅是组子表达式,而且还创建了反向引用。与正则表达式的分组部分匹配的字符串部分,即括号中的子表达式,存储在反向引用中。借助反向引用,我们可以重用正则表达式的一部分。这些存储的值既可以在表达式本身中重用,也可以在执行 regexpr 之后重用。在我们继续我们关于反向引用的论文之前,我们想在一段关于匹配对象的段落中加入,这对我们下一个带有反向引用的例子很重要。
仔细观察匹配对象
到目前为止,我们刚刚检查了表达式是否匹配。我们使用了 re.search() 如果匹配则返回匹配对象的事实,否则返回 None 。例如,我们对匹配的内容不感兴趣。匹配对象包含大量关于已匹配内容、位置等的数据。
匹配对象包含方法 group()、span()、start() 和 end(),如以下应用程序所示:
进口 re
mo = re 。search ( "[0-9]+" , "客户编号:232454,日期:2011 年 2 月 12 日" )
mo . 组()
输出:
'232454'
莫。跨度()
输出:
(17, 23)
莫。开始()
输出:
17
莫。结束()
输出:
23
莫。跨度()[ 0 ]
输出:
17
莫。跨度()[ 1 ]
输出:
23
这些方法不难理解。span() 返回一个带有开始和结束位置的元组,即正则表达式在字符串中开始匹配和结束匹配的字符串索引。start() 和 end() 方法在某种程度上是多余的,因为信息包含在 span() 中,即 span()[0] 等于 start() 而 span()[1] 等于 end() . group(),如果不带参数调用,则返回与完整正则表达式匹配的子字符串。在 group() 的帮助下,我们还可以通过对括号进行分组来访问匹配的子字符串,为了获得第 n 个组的匹配子字符串,我们使用参数 n 调用 group():group(n)。我们也可以使用多个整数参数调用 group,例如 group(n,m)。组(n, m) - 如果存在子组 n 和 m - 返回一个带有匹配子串的元组。group(n,m) 等于 (group(n), group(m)):
进口 re
mo = re 。搜索( "([0-9]+).*: (.*)" , "客户编号:232454,日期:2011 年 2 月 12 日" )
mo . 组()
输出:
'232454,日期:2011 年 2 月 12 日'
莫。组( 1 )
输出:
'232454'
莫。组( 2 )
输出:
'2011 年 2 月 12 日'
莫。组( 1 , 2 )
输出:
(“232454”、“2011 年 2 月 12 日”)
一个非常直观的例子是 XML 或 HTML 标签。例如,假设我们有一个文件(称为“tags.txt”),内容如下:
Wolfgang Amadeus Mozart
Samuel Beckett
London
我们想自动将这段文字改写为
作曲家:沃尔夫冈·阿马德乌斯·莫扎特
作者:塞缪尔·贝克特
城市:伦敦
下面的小 Python 脚本可以解决问题。这个脚本的核心是正则表达式。这个正则表达式是这样工作的:它试图匹配一个小于符号“<”。在此之后,它会读取小写字母,直到到达大于号。在 "<" 和 ">" 中遇到的所有内容都存储在反向引用中,可以通过写入 \1 在表达式中访问该引用。让我们假设 \1 包含值“composer”。当表达式到达第一个“>”时,它继续匹配,因为原来的表达式已经是“(.*)”:
import re
fh = open ( "tags.txt" )
for i in fh :
res = re 。搜索( r "<([az]+)>(.*)" , i )
打印( res . group ( 1 ) + ":" + res . group ( 2 ))
输出:
作曲家:沃尔夫冈·阿马德乌斯·莫扎特
作者:塞缪尔·贝克特
城市:伦敦
如果表达式中有一对以上的括号(圆括号),则反向引用按括号对的顺序编号为 \1、\2、\3。
练习:下一个 Python 示例使用了三个反向引用。我们有一个虚构的辛普森一家的电话清单。并非所有条目都包含电话号码,但如果电话号码存在,则它是条目的第一部分。然后,以空格分隔,后跟姓氏,后跟名字。姓氏和名字用逗号分隔。任务是按以下方式重写此示例:
艾莉森纽 555-8396
C. 蒙哥马利·伯恩斯
莱昂内尔·普茨 555-5299
荷马杰·辛普森 555-73347
解决重排问题的Python脚本:
import re
l = [ "555-8396 Neu, Allison" ,
"Burns, C. Montgomery" ,
"555-5299 Putz, Lionel" ,
"555-7334 Simpson, Homer Jay" ]
for i in l :
res = re 。搜索( r "([0-9-]*)\s*([A-Za-z]+),\s+(.*)" , i )
打印( res . group ( 3 ) + " " + res .组( 2 ) + " " + 资源。组( 1 ))
输出:
艾莉森纽 555-8396
C. 蒙哥马利·伯恩斯
莱昂内尔·普茨 555-5299
荷马杰·辛普森 555-7334
命名反向引用
在上一段中,我们介绍了“捕获组”和“反向引用”。更准确地说,我们可以称它们为“编号的捕获组”和“编号的反向引用”。使用捕获组而不是“编号”捕获组允许您为组分配描述性名称而不是自动编号。在以下示例中,我们通过从 UNIX 日期字符串中捕获小时、分钟和秒来演示此方法。
import re
s = "Sun Oct 14 13:47:03 CEST 2012"
expr = r "\b(?P\d\d):(?P\d\d):(?P<秒>\d\d)\b"
x = re 。搜索( expr , s )
x 。组('小时' )
输出:
'13'
× 。组('分钟' )
输出:
'47'
× 。开始('分钟' )
输出:
14
× 。结束('分钟' )
输出:
16
× 。跨度('秒' )
输出:
(17, 19)
综合Python练习
在这个综合练习中,我们必须将两个文件的信息放在一起。在第一个文件中,我们有一个包含近 15000 行邮政编码以及相应城市名称和附加信息的列表。以下是该文件的一些任意行:
osm_id ort plz bundesland
1104550 亚赫 78267 巴登符腾堡
...
446465 弗莱堡(易北河)21729 下萨克森
62768 Freiburg im Breisgau 79098 Baden-Württemberg
62768 Freiburg im Breisgau 79100 Baden-Württemberg
62768 Freiburg im Breisgau 79102 Baden-Württemberg
...
454863 富尔达 36037 黑森州
454863 富尔达 36039 黑森州
454863 富尔达 36041 黑森州
...
1451600 加林 19258 梅克伦堡-前波美拉尼亚
449887 Gallin-Kuppentin 19386 Mecklenburg-Vorpommern
...
57082 加特林根 71116 巴登-符腾堡
1334113 加茨(奥德)16307 勃兰登堡
...
2791802 Giengen an der Brenz 89522 Baden-Württemberg
2791802 Giengen an der Brenz 89537 Baden-Württemberg
...
1187159 萨尔布吕肯 66133 萨尔
1256034 萨尔堡 54439 Rheinland-Pfalz
1184570 萨尔路易斯 66740 萨尔
1184566 萨尔韦林根 66793 萨尔
另一个文件包含德国 19 个最大城市的列表。每行由等级、城市名称、人口和州(联邦)组成:
1. 柏林 3.382.169 柏林
2. 汉堡 1.715.392 汉堡
3. 慕尼黑 1.210.223 拜仁
4. 科隆 962.884 北莱茵-威斯特法伦
5. 美因河畔法兰克福 646.550 黑森州
6. 埃森 595.243 北莱茵-威斯特法伦
7. 多特蒙德 588.994 北莱茵-威斯特法伦
8. 斯图加特 583.874 巴登-符腾堡
9. 杜塞尔多夫 569.364 Nordrhein-Westfalen
10. 不来梅 539.403 不来梅
11. 汉诺威 515.001 下萨克森
12. 杜伊斯堡 514.915 北莱茵-威斯特法伦
13. 莱比锡 493.208 萨克森
14. 纽伦堡 488.400 拜仁
15. 德累斯顿 477.807 萨克森
16. 波鸿 391.147 北莱茵-威斯特法伦
17. 伍珀塔尔 366.434 北莱茵-威斯特法伦
18. 比勒费尔德 321.758 北莱茵-威斯特法伦
19. 曼海姆 306.729 巴登-符腾堡
我们的任务是创建一个包含前 19 个城市的列表,城市名称和邮政编码。如果您想测试以下程序,您必须将上面的列表保存在一个名为 large_cities_germany.txt 的文件中,并且您必须下载并保存德国邮政编码列表。
import re
with open ( "zuordnung_plz_ort.txt" , encoding = "utf-8" ) as fh_post_codes :
code4city = {}
for line in fh_post_codes :
res = re 。搜索( r "[\d ]+([^\d]+[az])\s(\d+)" , line )
如果 res :
city , post_code = res 。组()
如果 城市 在 code4city :
代码4city [城市] 。添加( post_code )
else :
code4city [ city ] = { post_code }
with open ( "largest_cities_germany.txt" , encoding = "utf-8" ) as fh_largest_cities :
for line in fh_largest_cities :
re_obj = re 。搜索( r "^[0-9]{1,2}\.\s+([\w\s-]+\w)\s+[0-9]" , line )
city = re_obj 。group ( 1 )
打印( city , code4city [ city ])
输出:
柏林 {'12685'、'12279'、'12353'、'12681'、'13465'、'12163'、'10365'、'12351'、'13156'、'12629'、'1203',218 '13086'、'12057'、'12157'、'10823'、'12621'、'14129'、'13359'、'13435'、'10963'、'12209'、'129,6083' ', '12277', '14059', '12459', '13593', '12687', '10785', '12526', '10717', '12487', '12205', 3,13'13' '12627'、'10783'、'12559'、'14050'、'10969'、'10367'、'12207'、'13409'、'10555'、'10623'、'1051939' ','12055', '13353', '13509', '10407', '12051', '12159', '10629', '13503', '13591', '10961', '109,347' '、'10999'、'12309'、'12437'、'10781'、'12305'、'10965'、'12167'、'10318'、'10409'、'12359'、94、'107' '10437'、'12161'、'10589'、'13581'、'12679'、'13505'、'12555'、'10405'、'10119'、'13355'、'10673929' ', '13351', '14055', '14089', '10627', '10829', '12107', '12435', '10319', '13507', '10551', 3,13'13' '13627'、'12524'、'13599'、'13189'、'13129'、'13467'、'12589'、'12489'、'10825'、'13585'、'106525'3' , '10439', '13597', '10317', '10553', '12101', '10557', '12355', '13587', '13053', '10967', '5'124' 10707'、'13629'、'13088'、'10719'、'10243'、'12045'、'12105'、'12349'、'13125'、'10117'、'141737'3' , '13349', '13403', '10178', '12047', '13055', '12165', '12249', '13407', '12169', '12587', '50405' 12103', '10245', '14193', '12205', '10827', '10585', '10587', '12557', '10435', '12623', '10713', '50585', '1205' 14109', '13051', '13127', '12307', '10715', '14057', '14195', '12619', '13158', '12043', '1309707'0' , '12099', '10247', '10709', '13595', '14165', '12247', '13159', '14167', '10789', '12049', '5', 1419 10115', '14163'}13059'、'14109'、'13051'、'13127'、'12307'、'10715'、'14057'、'14195'、'12619'、'13158'、'120137'0' , '10997', '12099', '10247', '10709', '13595', '14165', '12247', '13159', '14167', '10789', '10789', '1204' 10559'、'10115'、'14163'}13059'、'14109'、'13051'、'13127'、'12307'、'10715'、'14057'、'14195'、'12619'、'13158'、'120137'0' , '10997', '12099', '10247', '10709', '13595', '14165', '12247', '13159', '14167', '10789', '10789', '1204' 10559'、'10115'、'14163'}12049'、'14197'、'10559'、'10115'、'14163'}12049'、'14197'、'10559'、'10115'、'14163'}
汉堡 {'22589'、'22305'、'22587'、'22395'、'20457'、'22391'、'22763'、'20359'、'22393'、'22527'、'2629' '21037', '27499', '22547', '20097', '22147', '20255', '22765', '22115', '22309', '20259', '229,207' '、'22113'、'22087'、'21129'、'22299'、'22159'、'22083'、'22455'、'20144'、'21033'、'22119'、4'203' '22041'、'22049'、'21035'、'21077'、'20099'、'20459'、'20149'、'21031'、'22453'、'20539'、'2149239' ','20251'、'22607'、'22529'、'22179'、'21075'、'22339'、'22397'、'22335'、'22047'、'22175'、'2203205' ', '22111', '22525', '21107', '20537', '22143', '21029', '22081', '20253', '22301', '22337', '20531', '2029' '20355'、'22559'、'22549'、'22761'、'21149'、'20357'、'22415'、'22307'、'22177'、'22045'、'207246' ', '22417', '22769', '22419', '22117', '22609', '20535', '21073', '20257', '22523', '22359', 4,'201' '21147'}
慕尼黑 {'81241', '81669', '80336', '80796', '80799', '80339', '80539', '80689', '80939', '81929', 4,900' '81545'、'80469'、'81475'、'80803'、'81371'、'81373'、'81476'、'80686'、'80999'、'81667'、'81379207' '、'80997'、'80687'、'80798'、'80933'、'81477'、'81541'、'81369'、'81379'、'81549'、'81675'、'8075'、'806' '80992'、'80993'、'81377'、'81543'、'81677'、'81925'、'81479'、'81247'、'80337'、'81673'、'859,8040' ','80333'、'80638'、'81827'、'81671'、'80809'、'80639'、'81547'、'81825'、'81245'、'81829'、'8157373' ', '80805', '80335', '81679', '80331', '80636', '80935', '80538', '80807', '80937', '81539', '81539', '81'800
科隆 {'50939', '50827', '50668', '50676', '50999', '51065', '50968', '50733', '50937', '50769', 6,511' '51061'、'50823'、'50767'、'50829'、'50674'、'51069'、'50735'、'50672'、'50679'、'50737'、'509,50961' ', '51103', '50667', '50858', '50859', '50933', '51105', '51467', '51063', '51107', '50825', 61,5'5' “51145”、“50935”、“50765”、“51067”、“50997”、“51149”、“50739”、“50677”、“51143”}
美因河畔法兰克福 {'60437'、'60311'、'60439'、'60329'、'60549'、'60320'、'60322'、'60486'、'65934'、'60489'、9'605' ', '60431', '60594', '60529', '60488', '60386', '60310', '60306', '60325', '60313', '60598', 3,6'65 '60308', '65936', '60327', '60435', '60385', '60316', '60596', '60433', '60318', '60528', '657,604' '、'60388'、'60323'、'65929'、'60326'}
埃森 {'45259'、'45276'、'45327'、'45145'、'45138'、'45355'、'45219'、'45257'、'45326'、'45141'、24'4'4' '45130'、'45289'、'45279'、'45139'、'45307'、'45356'、'45136'、'45144'、'45239'、'45357'、'453954' '、'45127'、'45329'、'45309'、'45134'、'45143'、'45133'、'45149'}
多特蒙德 {'44139'、'44263'、'44141'、'44267'、'44265'、'44319'、'44145'、'44289'、'44339'、'44229'、304'4'4'4' '44147'、'44379'、'44143'、'44149'、'44227'、'44328'、'44135'、'44359'、'44137'、'44329'、'4464269' ', '44388', '44225'}
斯图加特 {'70191'、'70186'、'70193'、'70195'、'70176'、'70378'、'70197'、'70327'、'70435'、'70192'、7017'2' '70174', '70569', '70190', '70188', '70597', '70374', '70567', '70499', '70599', '70184', '70597'70379 ', '70563', '70439', '70629', '70469', '70619', '70199', '70372', '70173', '70180', '70437'}
杜塞尔多夫 {'40227', '40215', '40549', '40225', '40593', '40476', '40625', '40231', '40595', '40221', 102,4'29' '40470'、'40721'、'40489'、'40627'、'40479'、'40212'、'40211'、'40219'、'40235'、'40547'、'402923' ', '40233', '40599', '40589', '40597', '40213', '40237', '40472', '40474', '40468', '40591', 105,402' '40239'}
不来梅 {'28195'、'28201'、'28215'、'27568'、'28759'、'28307'、'28755'、'28217'、'28279'、'28777'、'28777'、'282' “28325”、“28197”、“28779”、“28757”、“28209”、“28309”、“28207”、“28219”、“28277”、“28203”、“287289” '、'28205'、'28211'、'28329'、'28717'、'28357'、'28359'、'28355'、'28239'、'28259'}
汉诺威 {'30459'、'30519'、'30627'、'30669'、'30539'、'30419'、'30177'、'30521'、'30629'、'30559'、5'303' '30659'、'30169'、'30455'、'30449'、'30179'、'30175'、'30625'、'30159'、'30451'、'30171'、'30175'30407' ', '30173', '30161', '30163', '30167'}
杜伊斯堡 {'47249'、'47229'、'47055'、'47179'、'47138'、'47139'、'47198'、'47057'、'47166'、'47199'、'6199'、'6192' “47259”、“47269”、“47228”、“47137”、“47226”、“47119”、“47051”、“47167”、“47058”、“47059”、“47059”、“47119” '}
莱比锡 {'4155'、'4289'、'4357'、'4205'、'4349'、'4229'、'4288'、'4275'、'4209'、'4179'、'4347'、'4328' '4177'、'4129'、'4319'、'4178'、'4318'、'4277'、'4315'、'4103'、'4105'、'4317'、'4249'、'4315'、 ', '4329', '4109', '4356', '4279', '4107', '4207', '4159', '4157', '4299'}
纽伦堡 {'90480'、'90482'、'90427'、'90475'、'90411'、'90471'、'90439'、'90403'、'90478'、'90451'、304、'3'9 '90453', '90473', '90459', '90469', '90402', '90408', '90455', '90489', '90441', '90449', '904,904' ', '90425', '90409', '90429'}
德累斯顿 {'1159'、'1139'、'1326'、'1187'、'1156'、'1069'、'1108'、'1099'、'1465'、'1109'、'1127'、'1169 '1324'、'1328'、'1259'、'1277'、'1239'、'1257'、'1237'、'1217'、'1157'、'1097'、'1219'、'1307'、 ', '1129', '1189', '1279', '1067'}
波鸿 {'44869'、'44809'、'44799'、'44787'、'44803'、'44867'、'44801'、'44866'、'44795'、'44894'、'84'54' “44807”、“44791”、“44879”、“44797”、“44892”、“44789”}
伍珀塔尔 {'42389'、'42399'、'42327'、'42115'、'42107'、'42279'、'42109'、'42103'、'42369'、'42111'、74'4'4' '42113'、'42283'、'42281'、'42329'、'42105'、'42289'、'42119'、'42277'、'42287'、'42349'、'42285
比勒费尔德 {'33613', '33699', '33729', '33611', '33602', '33615', '33739', '33605', '33659', '33609', '33609', '1336' '33647'、'33619'、'33719'、'33607'、'33604'、'33649'}
曼海姆 {'68199'、'68309'、'68239'、'68305'、'68161'、'68167'、'68165'、'68229'、'68159'、'68307'、63,681 '68169', '68219'}
另一个综合例子
我们想在 Python 课程中展示另一个真实的例子。英国邮政编码的正则表达式。我们编写了一个表达式,它能够识别英国的邮政编码或邮政编码。
邮政编码单元由 5 到 7 个字符组成,这些字符由空格分隔成两部分。空格前的两到四个字符代表所谓的外码或外码,旨在从分拣处直接邮寄到派送处。空格后面的部分由一个数字和两个大写字符组成,包括所谓的内向代码,在最终投递处对邮件进行分类时需要使用该代码。最后两个大写字符不使用字母 CIKMOV,以免手写时与数字或彼此相似。
外向代码可以采用以下形式:一个或两个大写字符,后跟一个数字或字母 R,可选地后跟一个大写字符或一个数字。(我们不考虑邮政编码的所有详细规则,即根据位置和上下文,只有某些字符集是有效的。)用于匹配英国邮政编码超集的正则表达式如下所示:
r"\b[AZ]{1,2}[0-9R][0-9A-Z]? [0-9][ABD-HJLNP-UW-Z]{2}\b"
下面的 Python 程序使用了上面的正则表达式:
import re
example_codes = [ “SW1A 0AA” , #下议院
“SW1A 1AA” , #白金汉宫
“SW1A 2AA” , #唐宁街
“BX3 2BB” , #巴克莱银行
“DH98 1BT” , #英国电信
“N1 9GU” , #卫报
“E98 1TT” , #泰晤士报
“TIM E22” , #假邮编
“A B1 A22” , #不是有效邮编
“EC2N 2DB” , #德意志银行
“SE9 2UG” , #格林大学
“N1 0UY”, #伊斯灵顿,伦敦
“EC1V 8DS” , #Clerkenwell,伦敦
“WC1X 9DT” , #WC1X 9DT
“B42 1LG” , #伯明翰
“B28 9AD” , #伯明翰
“W12 7RJ” , #伦敦,BBC 新闻中心
“BBC 007” " # 一个假邮政编码
]
pc_re = r "[Az]{1,2}[0-9R][0-9A-Z]? [0-9][ABD-HJLNP-UW-Z] {2} ”
为 邮政编码 在 example_codes :
- [R = 重新。搜索( pc_re ,
:
打印(邮政编码 + “匹配!” )
否则:
打印(邮政编码 + “不是有效的邮政编码!” )
输出:
SW1A 0AA 匹配!
SW1A 1AA 匹配!
SW1A 2AA 匹配!
BX3 2BB 匹配!
DH98 1BT 已配!
N1 9GU 匹配!
E98 1TT 匹配!
TIM E22 不是有效的邮政编码!
A B1 A22 不是有效的邮政编码!
EC2N 2DB 匹配!
SE9 2UG 搭配!
N1 0UY 匹配!
EC1V 8DS 匹配!
WC1X 9DT 匹配!
B42 1LG 搭配!
B28 9AD 匹配!
W12 7RJ 匹配!
BBC 007 不是有效的邮政编码!
