GPU存储器架构-- 全局内存 本地内存 寄存器堆 共享内存 常量内存 纹理内存
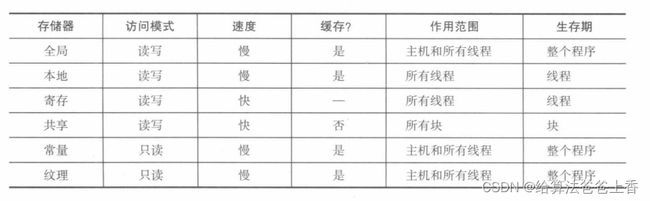
上表表述了各种存储器的各种特性。作用范围栏定义了程序的哪个部分能使用该存储器。而生存期定义了该存储器中的数据对程序可见的时间。除此之外,Ll和L2缓存也可以用于GPU程序以便更快地访问存储器。
总之,所有线程都有一个寄存器堆,它是最快的。共享内存只能被块中的线程访问,但比全局内存块。全局内存是最慢的,但可以被所有的块访问。
全局内存
所有的块都可以对全局内存进行读写。该存储器较慢,但是可以从代码的任何地方进行读写。缓存可加速对全局内存的访问。所有通过cudaMalloc分配的存储器都是全局内存。下面的简单代码演示了如何从程序中使用全局内存:
#include 本地内存和寄存器堆
本地内存和寄存器堆对每个线程都是唯一的。寄存器是每个线程可用的最快存储器。当内核中使用的变量在寄存器堆中装不下的时候,将会使用本地内存存储它们,这叫寄存器溢出。请注意使用本地内存有两种情况:一种是寄存器不够了,-种是某些情况根本就不能放在寄存器中,例如对一个局部数组的下标进行不定索引的时候。基本上可以将本地内存看成是每个线程的唯一的全局内存部分。相比寄存器堆,本地内存要慢很多。虽然本地内存通过Ll缓存和L2缓存进行了缓冲,但寄存器溢出可能会影响你的程序的性能。
下面演示一个简单的程序:
#include 代码中的t_local变量是每个线程局部唯一的,将被存储在寄存器堆中。用这种变量计算的时候,计算速度将是最快速的。
共享内存
共享内存位于芯片内部,因此它比全局内存快得多。(CUDA里面存储器的快慢有两方面,一个是延迟低,一个是带宽大。这里特指延迟低),相比没有经过缓存的全局内存访问,共享内存大约在延迟上低100倍。同一个块中的线程可以访问相同的一段共享内存(注意:不同块中的线程所见到的共享内存中的内容是不相同的),这在许多线程需要与其他线程共享它们的结果的应用程序中非常有用。但是如果不同步,也可能会造成混乱或错误的结果。如果某线程的计算结果在写入到共享内存完成之前被其他线程读取,那么将会导致错误。因此,应该正确地控制或管理内存访问。这是由_syncthreads()指令完成的,该指令确保在继续执行程序之前完成对内存的所有写入操作。这也被称为barrier。barrier 的含义是块中的所有线程都将到达该代码行,然后在此等待其他线程完成。当所有线程都到达了这里之后,它们可以一起继续往下执行。为了演示共享内存和线程同步的使用,我们这里给出一个计算MA的例子:
#include MA操作很简单,就是计算数组中当前元素之前所有元素的平均值,很多线程计算的时候将会使用数组中的同样的数据。这就是一种理想的使用共享内存的用例,这样将会得到比全局内存更快的数据访问。这将减少每个线程的全局内存访问次数,从而减少程序的延迟。共享内存上的数字或者变量是通过__shared__修饰符定义的。我们在本例中,定义了具有10个float元素的共享内存上的数组。通常,共享内存的大小应该等于每个块的线程数。因为我们要处理10个(元素)的数组,所以我们也将共享内存的大小定义成这么大。
下一步就是将数据从全局内存复制到共享内存。每个线程通过自己的索引复制一个元素,这样块整体完成了数据的复制操作,这样数据写到了共享内存中。在下一行,我们开始读取使用这个共享内存中的数组,但是在继续之前,我们应当保证所有(线程)都已经完成了它们的写入操作。所以,让我们使用__syncthreads()进行一次同步。
接着就是(每个线程)通过for循环,利用这些存储在共享内存中的值(读取后)计算(从第一个元素)到当前元素的平均值,并且将对应每个线程的结果存放到全局内存中的相应位置。
常量内存
CUDA程序员会经常用到另外一种存储器——常量内存,NVIDIA GPU 卡从逻辑上对用户提供了64KB的常量内存空间,可以用来存储内核执行期间所需要的恒定数据。常量内存对一些特定情况下的小数据量的访问具有相比全局内存的额外优势。使用常量内存也一定程度上减少了对全局内存的带宽占用。在本小节中,我们将看看如何在CUDA中使用常量内存。我们将用一个简单的程序进行a * x + b的数学运算,其中a,b都是常数,程序代码如下:
#include "stdio.h"
#include 常量内存中的变量使用__constant__ 关键字修饰。在之前的代码中,两个浮点数constant_f,constant_g 被定义成在内核执行期间不会改变的常量。需要注意的第二点是,使用__constant__ (在内核外面)定义好了它们后,它们不应该再次在内核内部定义。内核函数将用这两个常量进行一个简单的数学运算,在main 函数中,我们用一个特殊的方式将这两个常量的值传递到常量内存中。
在main 函数中,h_f, h_g两个常量在主机上被定义并初始化,然后将被复制到设备上的常量内存中。我们将用cudaMemcpyToSymbol函数把这些常量复制到内核执行所需要的常量内存中。该函数具有五个参数:第一个参数是(要写入的)目标,也就是我们刚才用__constant__ 定义过的h_f或者h_g常量;第二个参数是源主机地址;第三个参数是传输大小;第四个参数是写人目标的偏移量,这里是0;第五个参数是设备到主机的数据传输方向;最后两个参数是可选的,因此后面我们第二次cudaMemcpyToSymbol函数调用的时候省略掉了它们。
纹理内存
纹理内存是另外一种当数据的访问具有特定的模式的时候能够加速程序执行,并减少显存带宽的只读存储器。像常量内存一样,它也在芯片内部被cache缓冲。该存储器最初是为了图形绘制而设计的,但也可以被用于通用计算。当程序进行具有很大程度上的空间邻近性的访存的时候,这种存储器变得非常高效。空间邻近性的意思是,每个线程的读取位置都和其他线程的读取位置邻近。这对那些需要处理4个邻近的相关点或者8个邻近的点的图像处理应用非常有用。
通用的全局内存的cache将不能有效处理这种空间邻近性,可能会导致进行大量的显存读取传输。纹理存储被设计成能够利用这种访存模型,这样它只会从显存读取1次,然后缓冲掉,所以执行速度将会快得多。纹理内存支持2D和3D的纹理读取操作,在你的CUDA程序里面使用纹理内存可没有那么轻易,特别是对那些并非编程专家的人来说。我们将在本小节中为你解释一个如何通过纹理存储进行数组赋值的例子:
#include "stdio.h"
#include 通过“纹理引用”来定义一段能进行纹理拾取的纹理内存。纹理引用是通过texture<>类型的变量进行定义的。定义的时候,它具有3个参数:第一个是texture<>类型的变量定义时候的参数,用来说明纹理元素的类型。在本例中,是float类型;第二个参数说明了纹理引用的类型,可以是1D的,2D的,3D的。在本例中,是1D的纹理引用;第三个参数则是读取模式,这是一个可选参数,用来说明是否要执行读取时候的自动类型转换。请一定要确保纹理引用被定义成全局静态变量,同时还要确保它不能作为参数传递给任何其他函数。在这个内核函数中,每个线程通过纹理引用读取自己线程ID作为索引位置的数据,然后复制到d_out 指针指向的全局内存中。
在main函数中,定义并分配了内存和显存上的数组后,主机上的数组(中的元素)被初始化为0-9的值。本例中,你会第一次看到CUDA数组的使用。它们类似于普通的数组,但是却是纹理专用的。CUDA数组对于内核函数来说是只读的。但可以在主机上通过cudaMemcpyToArray函数写入,如同你在之前的代码中看到的那样。在cudaMemcpyToArray函数中,第二个和第三个参数中的0代表传输到的目标CUDA数组横向和纵向上的偏移量。两个方向上的偏移量都是О代表我们的这次传输将从目标CUDA数组的左上角(0,0)开始。CUDA数组中的存储器布局对用户来说是不透明的,这种布局对纹理拾取进行过特别优化。
cudaBindTextureToArray函数,将纹理引用和CUDA数组进行绑定。我们之前写入内容的CUDA数组将成为该纹理引用的后备存储。纹理引用绑定完成后我们调用内核,该内核将进行纹理拾取,同时将结果数据写入到显存中的目标数组。注意:CUDA对于显存中常见的大数据量的存储方式有两种,一种是普通的线性存储,可以直接用指针访问。另外一种则是CUDA数组,对用户不透明,不能在内核里直接用指针访问,需要通过texture或者surface的相应函数进行访问。本例的内核中,从texture reference进行的读取使用了相应的纹理拾取函数,而写入直接用普通的指针(d_out[])进行。当内核执行完成后,结果数组被复制回到主机上的内存中,然后在控制台窗口中显示出来。当使用完纹理存储后,我们需要执行解除绑定的代码,这是通过调用cudaUnbindTexture函数进行的。然后使用cudaFreeArray()函数释放刚才分配的CUDA数组空间。