SQL基础
说明:本文为个人学习笔记,主要根据B站未明学院【MySQL教程】整理(链接如下),部分内容有改动调整。本文仅做学习交流使用,未经允许不得转载,引用请标明出处。如有侵权,可联系删改。
【【MySQL教程】SQL零基础教程,带你掌握最受企业欢迎的数据库语言!-哔哩哔哩】https://b23.tv/xy8AgT
目录
1 导入导出
1.1 创建表格
2 基于SELECT关键字
2.1 选出列后,重命名-day3
2.2 选出列后,进行拼接操作-day4
2.3 选出列后,进行排序操作-day4
2.4 选出列后,进行过滤/筛选-day5-6
3 数据分析
3.1 数据类型
3.2 简单函数-day7
3.3 聚合函数-day8
3.4 分组数据-day8
4. 多表查询-day9
4.1 标量子查询
4.2 关联子查询
4.3 普通子查询
5 表联结-day9
5.1 多表联结(横向)
5.2 多表联结(纵向)
6 增删改-day10
6.1 增删操作(表、数据、变量)
6.2 改操作
软件安装:MySQL、Navicat
1 导入导出
Navicat导入数据
1、窗口“导入向导”——选择“excel”格式——单击“下一步”——选择数据位置——单击“下一步”
2、入股有日期格式数据注意选择日期——单击“下一步”
3、可以重命名sheet,记得勾选“新建表”——单击“下一步”
4、注意修改“字段类型”
varchar类型:文本类型;data类型:日期类型;
decimal类型:浮点型;int类型:整数类型
Attention:注意导入时excel需要是打开的,数据是不允许有格式(如加粗、网格线等)
5、需要敲代码的话:窗口单击“查询”——下方下拉选择数据库——左边可以预览数据表格。
Attention:一个语句会输出一个result
/*
SQL基础代码
crtl+R --运行全部代码
crtl+shift+R --运行光标所在行
*/
--导入导出数据
source D:/question.sql; --导入sql数据
SHOW DATABASES; --查看所有数据库
CREATE DATABASE sqllearning; --创建一个数据库,名字叫sqllearning
USE sqllearning; --使用这个数据库
DROP sqllearning; --删除这个数据库
CREATE TABLE users(); --创建表格
DESCRIBE users; --描述表格结构
DROP TABLE users; --删除表格1.1 创建表格
CREATE TABLE users(); --创建表格
DESCRIBE users; --描述表格结构
DROP TABLE users; --删除表格
--创建表格的变量
CREATE TABLE users(
user_id INT PRIMARY KEY, --变量名+数据类型+定义为主键
name VARCHAR(20),
age INT,
city VARCHAR(20),
state VARCHAR(20),
monthly_active INT --最后不用加逗号
);
--创建表格的变量:加一些限制
CREATE TABLE users(
user_id INT auto_increment, --主键会自动升序
name VARCHAR(20) NOT NULL, --限制必须是非空的
age INT,
city VARCHAR(20) UNIQUE, --限制不能有重复
state VARCHAR(20) DEFAULT 'unknown', --如果有空值会自动填充成‘unknown’
monthly_active INT,
PRIMARY KEY(user_id) --主键也可以这么创建,最后不用逗号
);
--填充数据
INSERT INTO users VALUES
(1,'Jack',19,'Dallas','Taxas',22),
(2,'Lucy',20,'Boston','Massachusetts',15),
(3,'Tom',13,'Los Angeles','California',8),
(4,'Alice',22,'San Jose','California',17),
(5,'Zhang',32,'Chicago','Illinois',22); --最后分号
--增加数据:全部变量都增加
INSERT INTO users VALUES (6,'Wang',32,'Chicago','Taxas',22)
--增加数据:中间要漏掉哪个数值不填,需要指明填入的变量
INSERT INTO users(user_id,name,age,state,monthly_active) VALUES(1,'Tom',19,'Texas',22)
--调整数据表格
ALTER TABLE users ADD gender CHAR(1); --增加一个变量 [ADD + 变量名 + 数据类型]
ALTER TABLE users DROP COLUMN gender; --删除一个变量 [DROP COLUMN + 变量名]
2 基于SELECT关键字
SELECT——单表查询:从一个数据表中,查询一列或多列数据。
操作对象:单个数据表
操作结果:输出一列或多列数据
--SELECT;单表查询;从一个数据表中,查询一列或多列数据。
--SELECT XX FROM XX 为必需字句搭配,选出的结果也是一个表格
SELECT prod_name FROM prod_info; --单列查询
SELECT prod_info.prod_name FROM prod_info;
SELECT prod_name,XXX,XXX FROM prod_info; --多列查询
SELECT * FROM prod_info; --所有列查询
2.1 选出列后,重命名-day3
注意:这里仅展示结果有修改,对原来的表格是没有影响的
--别名设置 SELECT [列名1], [列名2] AS [别名2], [列名3] FROM [表名];
SELECT prod_name, net_w AS net_weight, pro_data FROM prod_info;
SELECT prod_name, net_w AS 净重量, pro_data FROM prod_info; --中文直接改
SELECT prod_name, net_w AS 净重量, pro_data FROM prod_info AS p; --也可以给表起别名,系统会记住
--常数添加 SELECT '常数' AS [别名] FROM [表名];
SELECT prod_name, net_w, 0.9 AS sale_rate FROM prod_info;
SELECT prod_name, net_w, '零食' AS food FROM prod_info; --增加中文用‘’
--四则运算 SELECT [四则运算表达式] FROM [表名];
SELECT prod_name, in_price, sale_price, in_price-sale_price FROM df; --计算利润
SELECT prod_name, in_price, sale_price, sale_price*0.9 FROM df; --计算折扣价格2.2 选出列后,进行拼接操作-day4
--字符拼接 SELECT CONCAT([列名1], [列名2],...) FROM [表名];
--组合多列信息为一列
SELECT m.* CONCAT(prod_name, net_w) FROM milk_tea AS m; --选出全部变量,并拼配一列
SELECT m.* CONCAT(prod_name, net_w) AS 产品信息 FROM milk_tea AS m; --给拼接的一列起名字
SELECT m.* CONCAT(prod_name, '是', net_w, '是', sale_price) AS 产品信息 FROM milk_tea AS m; --输出:奶茶是150g是15:00,遇到Null输出Null
--指定拼接符 SELECT CONCAT_WS('拼接符', [列名1], [列名2],...) FROM [表名];
--多字段拼接,字段间使用相同的拼接符;遇到Null会跳过
SELECT m.* CONCAT(‘是’, prod_name, net_w, sale_price) AS 产品信息 FROM milk_tea AS m; --输出:奶茶是150g是15:00,遇到Null先跳过
--内容去重 DISTINCT
--去除不重复的列值:SELECT DISTINCT [列名] FROM [表名];
--列中有多个相同值,查看值的种类
SELECT DISTINCT m.valid_month FROM milk_tea AS m; --valid_month只有12、18两个值,输出只有两行,一行12、一行18,空值Null算一类2.3 选出列后,进行排序操作-day4
+ORDER BY [列名1], [列名2]; 升序ASC(Ascending),降序DESC(Descending)
--字符排序 SELECT [列名1], [列名2] FROM [表名] ORDER BY [列名1], [列名2];
SELECT m.* FROM milk_tea AS m ORDER BY m.sale_price; --数值型,默认升序
SELECT m.* FROM milk_tea AS m ORDER BY m.sale_price DESC; --数值型,降序
SELECT m.* FROM milk_tea AS m ORDER BY m.sale_price DESC LIMIT 5; --显示销售价最低的5个
SELECT m.* FROM milk_tea AS m ORDER BY m.pro_date; --日期型,默认升序
SELECT m.* FROM milk_tea AS m ORDER BY CONVERT(pro_name USING gbk); --字符型,需转化为gbk编码
--两个字段排序,DESC仅作用于紧跟着的关键字
SELECT m.* FROM milk_tea AS m ORDER BY m.valid_month, m.sale_price; --先排字段1,再排字段2,默认升序
SELECT m.* FROM milk_tea AS m ORDER BY m.valid_month, m.sale_price DESC; --字段1升序,字段2降序
SELECT m.* FROM milk_tea AS m ORDER BY m.valid_month DESC, m.sale_price DESC; --字段1降,字段2降序
SELECT m.* FROM milk_tea AS m ORDER BY 5, 7; --使用列的位置也是可以的,但不建议
--排序后,不展示排序列也是可以的
SELECT m.prod_id, m.prod_name FROM milk_tea AS m ORDER BY m.sale_price; --可以不需要展示排序列
2.4 选出列后,进行过滤/筛选-day5-6
(1)+where 判断语句
--指标过滤 SELECT m.* FROM [表名] WHERE 判断;
SELECT m.* FROM milk_tea AS m WHERE m.prod_id = 2; --数值型
SELECT m.* FROM milk_tea AS m WHERE m.prod_name = '奶糖'; --文本型
SELECT m.* FROM milk_tea AS m WHERE m.in_price > 5; --采购价>5
--仅展示需要的列
SELECT m.prod_name FROM milk_tea AS m WHERE m.in_price > 5; --采购价>5的商品名字
SELECT m.prod_name FROM milk_tea AS m WHERE m.sale_price * 0.9 > 15; --销售价打九折还>15元的商品名字
SELECT m.prod_name FROM milk_tea AS m WHERE m.sale_price - m.in_price > 5; --利润>5元的商品名字
--对空值的处理:m.sale_price中含空值,出现空值被遗漏
SELECT m.* FROM milk_tea AS m WHERE m.sale_price = 15; --不含Null
SELECT m.* FROM milk_tea AS m WHERE m.sale_price != 15; --不含Null
--先将空值设为一个数值,再筛选
IFNULL(sale_price,0)
SELECT m.* FROM milk_tea AS m WHERE m.sale_price = 15; --不含Null
SELECT m.* FROM milk_tea AS m WHERE m.sale_price != 15; --不含Null
--直接处理
SELECT m.* FROM milk_tea AS m WHERE IFNULL(sale_price,0) = 15; --不含Null
SELECT m.* FROM milk_tea AS m WHERE IFNULL(sale_price,0) != 15; --不含Null
--空值过滤 SELECT m.* FROM [表名] WHERE [列] IS NULL
SELECT m.* FROM milk_tea AS m WHERE m.sale_price IS NULL; --筛选出空值
SELECT m.* FROM milk_tea AS m WHERE m.sale_price IS NOT NULL; --筛选出非空值
(2)+where + 一些字段
--BETWEEN ... AND ...(两段包含)
SELECT m.* FROM milk_tea AS m WHERE m.in_price BETWEEN 5 AND 10; --包含5和10
--AND、OR
SELECT m.* FROM milk_tea AS m WHERE m.in_price >=5 AND m.in_price <= 10;
SELECT m.* FROM milk_tea AS m WHERE m.in_price >=5 AND m.sale_price IS NOT NULL;
SELECT m.* FROM milk_tea AS m WHERE m.in_price >=5 AND m.pro_name LIKE "薯_";
SELECT m.* FROM milk_tea AS m WHERE m.in_price >=5 OR m.in_price <= 10;
--取值限制 IN ()
SELECT m.* FROM milk_tea AS m WHERE m.pro_name IN ('奶茶'. '薯片', '棒棒糖');
--否定条件 NOT
--注意它仅否定紧跟着的那个条件(3)+where ... like 通配符
单个、任何字符: WHERE [列] LIKE '..._...'
任一个、任何字符:WHERE [列] LIKE '...%...'
转意字符,告诉我们'\'后面的仅仅是本来意思,没有什么特殊含义
--单个、任何字符:WHERE [列] LIKE '..._...'
--任一个、任何字符:WHERE [列] LIKE '...%...'
SELECT m.* FROM milk_tea AS m WHERE m.pro_name LIKE ‘奶_’; --筛选出“奶茶”、“奶糖”列
SELECT m.* FROM milk_tea AS m WHERE m.pro_name LIKE ‘_糖’; --筛选出“奶糖”列
SELECT m.* FROM milk_tea AS m WHERE m.pro_name LIKE ‘%糖’; --筛选出“奶糖”、"棒棒糖"列
--遇到原来文本就有%的,可用转义字符/%表示这里的百分号就是原来的百分号
SELECT m.* FROM pet AS m WHERE owner LIKE ‘Gw/%_en’; 3 数据分析
3.1 数据类型
MySQL 数据类型 | 菜鸟教程



3.2 简单函数-day7
可以直接用【SELECT + 函数】进行试调用。
| 函数名 | 函数 | 示例 |
| 绝对值函数 | ABS | ABS(-3) = 3 |
| 平方根函数 | SQRT | SQRT(4) = 2 |
| 指数函数 | EXP | EXP(4) = e^4 |
| 四舍五入函数 | ROUND | ROUMD(1.234,2) = 1.23 |
| 圆周率函数 | PI | PI() = π |
| 函数名 | 函数 | 示例 |
| 字符长度 | CHAR_LENGTH | CHAR_LENGTH(‘数据’) = 2 |
| 字节数 (汉子3字节;英文、数字1字节) |
LENGTH | LENGTH(‘数据’) = 6 |
| 去除右边空格 | RTRIM | RTRIM('home ') = 'home' |
| 去除左边空格 | LTRIM | LTRIM(‘ home’) = 'home' |
| 大写字母转换 | UPPER | UPPER('home') = 'HOME' |
| 小写字母转换 | LOEWR | LOWER('HOME') = 'home" |
| 函数名 | 函数 | 示例 |
| 获取具体日期段 | YEAR/M/D |
YTAR('2019-1-2’) = ‘2019’ |
| 获取具体时间段 | HOUR/M/S | HOUE('14:01:24') = '14' |
| 获取月份名称 | MOMTHNAME | MONTHNANE('2019-1-2') = 'JAN' |
| 获取当前日期时间 | NOW | NOW() = systime |
| 获取当前日期 | CURDATE | CURDATE() = '20190501' |
| 获取当前时间 | CURTIME | CURTIME() = '15:10:39' |
| 时间增加 | DATE_ADD | DATE_ADD('20190501', INTERVAL 1 MONTH) |
| 时间减少 | DATE_SUB | DATE_SUB('20190501', INTERVAL 1 YEAR) |
--可以迭代使用
SELECT UPPER(LTRIM(' home')) --输出'HOME'
SELECT MONTHNAME(NOW()) --输出'MAY'
--作用于数据表时,仅改变输出,原内容不变
SELECT UPPER(t.id_char) FROM text_sjlx AS t; --小写字母的行输出会变成大写字母,其他单元格输出不变3.3 聚合函数-day8
| 函数 | 作用 | 注意 |
| COUNT(*)或COUNT(1) | 计算表格行数目 | |
| COUNT(COL) | 计算某一列行数 | 不对NULL计数,不可以同时计算多列 |
| COUNT(DISTINCT col) | 对行去重计数 | |
| SUM(col)、AVG(col) | 求列和、列平均 | 不对NULL计数,可以同时操作多个列 |
| MAX(col)、MIN(col) | 求最大值、最小值 | 忽略NULL、要求该列可以排序 |
--COUNT
SELECT COUNT(1) FROM milk_tea AS m; --计算表格行数
SELECT COUNT(m.prod_name) FROM milk_tea AS m; --计算某列行数,注意是不计算空值的
SELECT COUNT(DISTINCT m.sale_price) FROM milk_tea AS m; --对行去重计数
--Attention:可以COUNT(DISTINCT [列名])两列,但不能直接COUNT两列
SELECT COUNT(DISTINCT m.in_price), COUNT(DISTINCT m.sale_price) FROM milk_tea AS m;
--SUM
SELECT SUM(m.sale_price) FROM milk_tea AS m; --计算总销售额(不算空值)
SELECT SUM(0.9 * m.sale_price) FROM milk_tea AS m; --计算如果打九折总销售额
--Attention,以下两行代码运算结果不一定是一样的
SELECT SUM(m.sale_price)-SUM(m.in_price) FROM milk_tea AS m; --94.5-78.5=16
SELECT SUM(m.sale_price - m.in_price) FROM milk_tea AS m; --31.5,sale_price有空值,计算忽略了那一行,所以会少减一个in_price
SELECT SUM(IFNULL(m.sale_price,0) - m.in_price) FROM milk_tea AS m; --=16 ,也可用这行代码处理空值
--AVG
--Attention:由于都忽略空值,以下两行代码计算结果一致
SELECT AVG(m.sale_price) FROM milk_tea AS m; --13.5
SELECT SUM(m.sale_price)/COUNT(m.in_price) FROM milk_tea AS m; --13.5
--Attention:由于COUNT(*)按全表格,不太可能出现全空行,以下两行代码计算结果不一定一致
SELECT SUM(m.sale_price)/COUNT(m.in_price) FROM milk_tea AS m; --13.5
SELECT SUM(m.sale_price)/COUNT(*) FROM milk_tea AS m; --11.8125
--MAX、MIN
SELECT MAX(m.sale_price) FROM milk_tea AS m;
SELECT MIN(m.sale_price) FROM milk_tea AS m;
--加入过滤
SELECT SUM(m.sale_price) FROM milk_tea AS m WHERE m.net_w = '100g'; --34,计算重量为100g的商品的总销售额(不算空值)
--多个聚合函数同时使用也是可以的~
SELECT COUNT(m.sale_price), SUM(m.sale_price), AVG(m.sale_price) FROM milk_tea AS m;3.4 分组数据-day8
group by ... having ...
--分组求和
--选出重量和价格,按商品重量分组求和、分组求平均
SELECT m.net_w, SUM(m.sale_price) FROM milk_tea AS m GROUP BY m.net_w;
SELECT m.net_w, AVG(m.sale_price) FROM milk_tea AS m GROUP BY m.net_w;
--选出重量为100g和150g的商品,按商品重量分组求和
SELECT m.net_w, SUM(m.sale_price) FROM milk_tea AS m WHERE m.net_w in ('100g', '150g') GROUP BY m.net_w;
--先按商品重量分组求和,再选出重量为100g和150g的分组和,较上个语句计算量大
SELECT m.net_w, SUM(m.sale_price) FROM milk_tea AS m GROUP BY m.net_w HAVING m.net_w in ('100g', '150g');
--先按商品重量分组求和,再选出销售价格和大于20的分组
SELECT m.net_w, SUM(m.sale_price) FROM milk_tea AS m GROUP BY m.net_w HAVING m.sale_price > 20;
--Attention:理论上,去掉聚合键也可以输出结果,但你就不知到每个组对应哪一个关键字
SELECT SUM(m.sale_price) FROM milk_tea AS m GROUP BY m.net_w; --按商品重量分组求和
单表查询语句结构小结
4. 多表查询-day9
4.1 标量子查询
子查询:嵌套在其他查询中的查存
标量子查询:只返回一行一列(即一个单元格数据)的子查询,相当于是一个常数
--例1:找出销售价格大于奶茶价格的行
SELECT m.sale_price FROM milk_tea AS m WHERE m.prod_name = '奶茶'; --先找出奶茶价格:15
SELECT m.* FROM milk_tea AS m WHERE m.sale_price > 15; --找出销售价格>15的行
--合并成一句
SELECT m.*
FROM milk_tea AS m
WHERE m.sale_price > (
SELECT m.sale_price
FROM milk_tea AS m
WHERE m.prod_name = '奶茶');
--例2:找出prod_info表中,平均商品销售价格大于milk_tea表中奶茶价格的行
SELECT p.class, AVG(p.sale_price)
FROM prod_info AS p
GROUP BY p.class
HAVING AVG(p.sale_price) > (
SELECT m.sale_price
FROM milk_tea AS m
WHERE m.prod_name = '奶茶');
--例3:找出prod_info表中,日用品价格大于其均价的商品行
SELECT p.*
FROM prod_info AS p
WHERE p.class = '日用品' AND p.sale_price > (
SELECT AVG(p2.sale_price) --只要一个数,可以不用聚合键
FROM prod_info AS p2
WHERE p2.class = '日用品'
GROUP BY p2.class);
4.2 关联子查询
嵌套在其他查询中的查询。适用于组内比较。
子查询返回一列数据:子查询的结果,与主查询的目标列存在一定关联。
--例4:找出prod_info表中,每一个商品价格都都大于其均价的商品行
SELECT p.*
FROM prod_info AS p
WHERE p.sale_price > (
SELECT AVG(p2.sale_price) --只要一个数,可以不用聚合键
FROM prod_info AS p2
WHERE p2.class = p.class --精髓
GROUP BY p2.class);
4.3 普通子查询
形式1:子查询返回一列数据:姜子查询的结果列,作为主查询的取值范围。
形式2:子查询返回二维表:将查询结果的二维表作为新的目标表。
--例5:[子查询返回一列]筛选出milk_tea表中销售价格等于15的商品对于的行
--正常如下即可
SELECT m.* FROM milk_tea AS m WHERE m.sale_price = 15;
--为了示范,强调先选出sale_price=15的商品(一列数据),再从商品名字提取行
SELECT m.prod_name FROM milk_tea AS m WHERE m.sale_price =15;
--合并
SELECT m2.* FROM milk_tea AS m2
WHERE m2.prod_name IN (
SELECT m1.prod_name FROM milk_tea AS m1
WHERE m1.sale_price =15 );
--例6:[子查询返回一张表] 用筛选出的表子表,进一步做筛选
SELECT p.prod_name,p.type,p.sale_price FROM prod_info AS p WHERE p.prod_name = '抽纸';
SELECT * FROM () AS b WHERE b.sale_price > 26;
--合并
SELECT b.type
FROM (SELECT p.prod_name,p.type,p.sale_price
FROM prod_info AS p
WHERE p.prod_name = '抽纸') AS b
WHERE b.sale_price > 26;5 表联结-day9
类型1: 横向联结,对应Python的merge
(1) 取交集:表1 inner join 表2
全连接:FROM 表1, 表2 WHERE 联结条件
内联结:FROM 表1 INNER JOIN 表2 ON 联结条件
按照左/右显示,没联结的是Null
(2)取并集:表1 outer join 表2
外联结:FROM 表1 LEFT OUTER JOIN 表2 ON 联结条件 ;
自然联结(key只有一列):FROM 表1 NATURAL LEFT OUTER JOIN 表2 ;
类型2: 纵向联结,对应Python的concat
(1)纵向联结:表1 union 表2
mysql多表连接_zx33699659的博客-CSDN博客_mysql多表连接
python merge、concat合并数据集_三石-CSDN博客_concat合并
5.1 多表联结(横向)
类型1: 横向联结,对应Python的merge
(1) 取交集:表1 inner join 表2
全连接:SELECT 列名 FROM 表1, 表2 WHERE 联结条件
内联结:SELECT 列名 FROM 表1 INNER JOIN 表2 ON 联结条件
全联结那里,(a)可以FROM多个表,用“,”隔开;
(b)WHERE后先联结条件,再其他的过滤条件
内连接那里:两张表一定要有共同的可以联结的变量(不是变量名一样,是可以匹配)
(2)取并集:表1 outer join 表2
外联结:FROM 表1 LEFT OUTER JOIN 表2 ON 联结条件 ;
自然联结(key只有一列):FROM 表1 NATURAL LEFT OUTER JOIN 表2
--表prod_info和supplier_info都有一列supplier_id,即供应商id
SELECT * FROM prod_info AS p;
SELECT * FROM supplier_info AS S;
--把两张表拼接起来:会出现两列supplier_id,另一列为supplier_id(1)
SELECT p.*, s.*
FROM prod_info AS p , supplier_info AS S
WHERE p.suoolier_id = s.supplier_id;
--联结后,可以不展示整张表
SELECT p.prod_name, p.sale_price, s.supplier_name
FROM prod_info AS p , supplier_info AS S
WHERE p.suoolier_id = s.supplier_id;
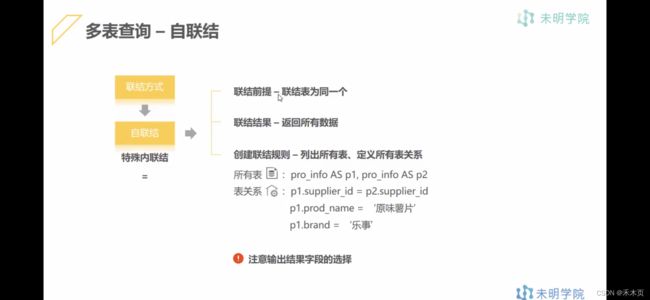

-- 内部联结:
-- SELECT [ ] FROM 表1 INNER JOIN 表2 ON 联结条件 AND 筛选
SELECT p.*, l.*
FROM prod_info AS p INNER JOIN order_list AS l
ON p.prod_id = l.prod_id
AND l.order_id = '20190403002';
-- 外部联结:两张表信息都全(左连接即左表是全的)
-- SELECT [ ] FROM 表1 LEFT OUTER JOIN 表2 ON 联结条件 AND 筛选
SELECT c.*, l.*
FROM cust_info AS c LEFT OUTER JOIN order_list AS l
ON c.cust_id = l.cust_id
AND l.order_id = LIKE '20190407%';
-- 子表也可以存储为变量c2
SELECT c2.cust_id, COUNT(c2.prod_id)
FROM(SELECT c.cust_id, c,cust_name, l.prod_id, l.prodname, l.order_id
FROM cust_info AS c LEFT OUTER JOIN orfrt_list AS l
on c.cust_id = l.cust_id
AND l.order_id Like '20190401%') AS c2
GROUP BY c2.cust_id;

5.2 多表联结(纵向)
(1)语法:表1 UNION 表2
(2)对应Python的concat
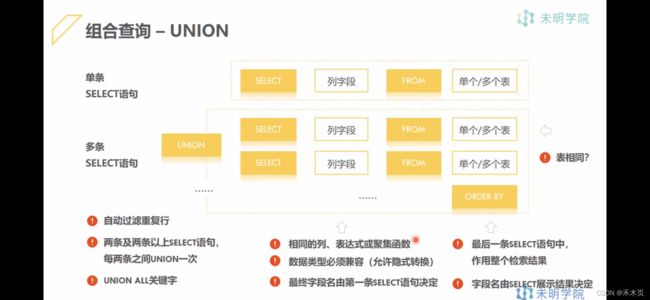
-- 表联结[纵向]:要求结构一致
-- Union 完全一样会删除
SELECT * FROM order_list AS l WHERE l.order_id LIKE '20190407%'
UNION
SELECT * FROM order_list AS l WHERE l.order_id LIKE '20190409%';
-- Union all 完全一样也保留
SELECT * FROM order_list AS l WHERE l.order_id LIKE '20190407%'
UNION ALL
SELECT * FROM order_list AS l WHERE l.order_id LIKE '20190409%';
6 增删改-day10
| 操作数据库、表 | 操作数据 | ||
| CREAT | 创建数据库和表等对象 | INSERT | 增:插入数据(横向) |
| DROP | 删除数据库和表等对象 | DELETE | 删:删除表中数据 |
| ALTER | 修改数据库和表等对象的结构 (也可理解为增加字段-纵向) |
UPDATE | 改:更新表中数据 |
| SELECT | 查:查询表中数据 | ||
6.1 增删操作(表、数据、变量)
(1)操作数据库、表
创建表格:CREAT TABLE 表名( )
删除表格:DROP TABLE 表名 (不用括号了)
增加变量:ALTER TABLE users ADD 变量名 变量类型;
删除变量:ALTER TABLE users DROP COLUMN 变量名;
(2)操作数据
插入数据:INSERT INTO 表名() VALUES( )
删除数据:DELECT FROM 表名( ) WHERE( )
TRUNCATE TABLE 表名 (删除表中所有数据,但表还存在)
更新数据:UPDATE 表名 SET 字段=值 WHERE 过滤条件
CREATE TABLE users(); --创建表格
DESCRIBE users; --描述表格结构
DROP TABLE users; --删除表格
--创建表格的变量
CREATE TABLE users(
user_id INT PRIMARY KEY, --变量名+数据类型+定义为主键
name VARCHAR(20),
age INT,
city VARCHAR(20),
state VARCHAR(20),
monthly_active INT --最后不用加逗号
);
--创建表格的变量:加一些限制
CREATE TABLE users(
user_id INT auto_increment, --主键会自动升序
name VARCHAR(20) NOT NULL, --限制必须是非空的
age INT,
city VARCHAR(20) UNIQUE, --限制不能有重复
state VARCHAR(20) DEFAULT 'unknown', --如果有空值会自动填充成‘unknown’
monthly_active INT,
PRIMARY KEY(user_id) --主键也可以这么创建,最后不用逗号
);
--填充数据
INSERT INTO users VALUES
(1,'Jack',19,'Dallas','Taxas',22),
(2,'Lucy',20,'Boston','Massachusetts',15),
(3,'Tom',13,'Los Angeles','California',8),
(4,'Alice',22,'San Jose','California',17),
(5,'Zhang',32,'Chicago','Illinois',22); --最后分号
--增加数据:全部变量都增加
INSERT INTO users VALUES (6,'Wang',32,'Chicago','Taxas',22)
--增加数据:中间要漏掉哪个数值不填,需要指明填入的变量
INSERT INTO users(user_id,name,age,state,monthly_active) VALUES(1,'Tom',19,'Texas',22)
--调整数据表格
ALTER TABLE users ADD gender CHAR(1); --增加一个变量 [ADD + 变量名 + 数据类型]
ALTER TABLE users DROP COLUMN gender; --删除一个变量 [DROP COLUMN + 变量名]
6.2 改操作
更新:UPDATE 表名 SET 字段=值 WHERE 过滤条件
(1)表名:必须是真实的表(不能是查询得到的子表),而且有且仅有一个
(2)字段:可以更新多个字段,用“,”隔开;允许整列是空值 SET XX=NULL
查一下可不可以用【UPDATE XX SET XX】来增加字段。
(3)过滤条件:指定更新的行,否则全部更新
-- 更新表格 UPDATE
UPDATE prod_info2
SET class = '日用品';
-- 有选择的更新
UPDATE prod_info2
SET class = '日用品'
WHERE prod_id LIKE 'T2%';
SELECT p* FROM prod_info2 AS p WHERE prod_id LIKE 'T2%'; --养成习惯:每次更新前先看一下要更新的数据
-- 可以用表格式更新列,比如价格变为原来的0.9倍
UPDATE prod_info2
SET sale_price = sale_price * 0.9;
UPDATE prod_info2
SET sale_price = sale_price * 0.9
WHERE prod_name = '抽纸' OR class = '饮料';
将更新【UPDATE XX SET XX】与插入【INSERT 】
SELECT p2.* p.*
FROM prod_info2 p2 INNER JOIN prod_info p --内联结,取交集;INNER JOIN 跟的是on ,where跟她无关
WHERE p2.prod_name = p.prod_name --
ADD p2.brand = p.brabd
ADD p2.type = p.type;
--分析 【SELECT 列名 FROM 表 WHERE】是一个结构??WHERE后面的是联结条件吗?
UPDATE prod_info p2 --更新两个表
INNER JOIN prod_info p --内联结,取交集;INNER JOIN 跟的是on ,where跟她无关
SET p2.cost = p.sale_price
WHERE p2.prod_name = p.prod_name
ADD p2.brand = p.brabd
ADD p2.type = p.type;