Flink run 参数解释
1 Flink的前世今生(生态很重要)
很多人可能都是在 2015 年才听到 Flink 这个词,其实早在 2008 年,Flink 的前身已经是柏林理工大学一个研究性项目, 在 2014 被 Apache 孵化器所接受,然后迅速地成为了 ASF(Apache Software Foundation)的顶级项目之一。
Apache Flink is an open source platform for distributed stream and batch data
processing. Flink’s core is a streaming dataflow engine that provides data
distribution, communication, and fault tolerance for distributed computations
over data streams. Flink builds batch processing on top of the streaming engine,
overlaying native iteration support, managed memory, and program optimization.
复制代码

- Apache Flink 是一个开源的分布式,高性能,高可用,准确的流处理框架。
- 主要由 Java 代码实现,提供Java 和scala接口。
- 支持实时流(stream)处理和批(batch)处理,批数据只是流数据的一个极限特例。
- Flink原生支持了迭代计算、内存管理和程序优化。
- Flink目前也在重力打造属于自己的大数据生态。(FinkSQL , Flink ML ,Flink Gelly等)

2 吞吐量悖论
流处理和批处理的纠结选择和不容水火,Flink通过灵活的执行引擎,能够同时支持批处理任务与流处理任务,但是悖论是永远存在的。
- 流处理:Flink以固定的缓存块为单位进行网络数据传输,用户可以通过设置缓存块超时值指定缓存块的传输时机。如果缓存块的超时值为0,则Flink的数据传输方式类似上文所提到流处理系统的标准模型,此时系统可以获得最低的处理延迟。
- 批处理:如果缓存块的超时值为无限大,则Flink的数据传输方式类似上文所提到批处理系统的标准模型,此时系统可以获得最高的吞吐量。
- 灵活的秘密:缓存块的超时值也可以设置为0到无限大之间的任意值。缓存块的超时阈值越小,则Flink流处理执行引擎的数据处理延迟越低,但吞吐量也会降低,反之亦然。通过调整缓存块的超时阈值,用户可根据需求灵活地权衡系统延迟和吞吐量。
3 容错的抉择(Flink or Spark)
-
SparkStreaming :微批次模型,EOS语义,基于RDD Checkpoint进行容错,基于checkpoint状态管理。状态的状态操作基于DStream模板进行管理,延时中等水平,吞吐量很高。详情请参考我的SparkStreaming源码解读。
-
Flink :流处理模型,EOS语义,基于两种状态管理进行容错,即:State和checkpoint两种机制。状态操作可以细粒化到算子等操作上。延时不仅低,而且吞吐量也非常高。
- State 基于task和operator两种状态。State类型进一步细分为 Keyed State和 Operator State 两种类型 - checkpoint 基全局快照来实现数据容错,注意:State的状态保存在java的堆里面, checkpoint则通过定时实现全局(所有State)状态的持久化。 复制代码
说实在的,Flink很狂妄:

4 Stanalone 环境全方位剖析
4.1 Stanalone 模式
集群节点规划(一主两从)
1 基础环境:
jdk1.8及以上【需要配置JAVA_HOME】
ssh免密码登录(至少要实现主节点能够免密登录到从节点)
主机名hostname
/etc/hosts文件配置主机名和ip的映射关系
192.168.1.160 SparkMaster
192.168.1.161 SparkWorker1
192.168.1.162 SparkWorker2
关闭防火墙
复制代码2 在SparkMaster节点上主要需要修改的配置信息
cd /usr/local/flink-1.6.1/conf
vi flink-conf.yaml
jobmanager.rpc.address: SparkMaster
复制代码3 slaves修改
vi slaves
SparkWorker1
SparkWorker2
复制代码4 然后再把修改好的flink目录拷贝到其他两个节点即可
scp -rq flink-1.6.1 SparkWorker1:/usr/local/
scp -rq flink-1.6.1 SparkWorker2:/usr/local/
复制代码4.2 Stanalone 运行展示
这里发生一个小插曲,因为yarn配置文件不一致,导致 hadoop Web UI 无法正常显示所有NodeManager。所以注意配置文件的一致性。
SparkMaster节点进程:
14273 SecondaryNameNode
15010 Worker
14038 DataNode
25031 StandaloneSessionClusterEntrypoint
13895 NameNode
14903 Master
14424 ResourceManager
14569 NodeManager
25130 Jps
复制代码SparkWorker节点进程:
5732 Worker
10420 NodeManager
10268 DataNode
10540 Jps
8351 TaskManagerRunner
复制代码上图一张:
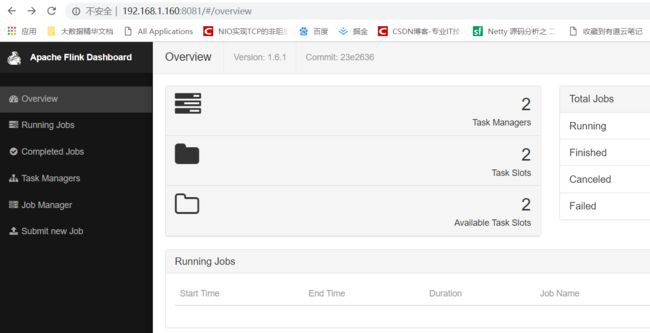
4.3 Stanalone 简单任务测试
(1) 增量聚合: 窗口中每进入一条数据,就进行一次计算
-
实现方法主要有:
reduce(reduceFunction) aggregate(aggregateFunction) sum(),min(),max()
(2) 全量聚合: 等于窗口内的数据到齐,才开始进行聚合计算
-
全量聚合:可以实现对窗口内的数据进行排序等需
-
实现方法主要有:
apply(windowFunction) process(processWindowFunction) processWindowFunction比windowFunction提供了更多的上下文信息。 复制代码 -
全量聚合详细案例如下:
public class SocketDemoFullCount { public static void main(String[] args) throws Exception{ //获取需要的端口号 int port; try { ParameterTool parameterTool = ParameterTool.fromArgs(args); port = parameterTool.getInt("port"); }catch (Exception e){ System.err.println("No port set. use default port 9010--java"); port = 9010; } //获取flink的运行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String hostname = "SparkMaster"; String delimiter = "\n"; //连接socket获取输入的数据 DataStreamSourcetext = env.socketTextStream(hostname, port, delimiter); DataStream out) throws Exception { System.out.println("执行process......"); long count = 0; for(Tuple2 }
(3) 数据源
root@SparkMaster:/usr/local/install/hadoop-2.7.3/sbin# nc -l 9010
12
1
复制代码(4) 运行结果

4.4 Stanalone 参数调优设置
参数调优设置:
1.jobmanager.heap.mb:jobmanager节点可用的内存大小
2.taskmanager.heap.mb:taskmanager节点可用的内存大小
3.taskmanager.numberOfTaskSlots:每台机器可用的cpu数量
4.parallelism.default:默认情况下任务的并行度
5.taskmanager.tmp.dirs:taskmanager的临时数据存储目录
slot和parallelism总结:
1.slot是静态的概念,是指taskmanager具有的并发执行能力
2.parallelism是动态的概念,是指程序运行时实际使用的并发能力
3.设置合适的parallelism能提高运算效率,太多了和太少了都不行
复制代码4.5 Stanalone 集群启动与挂机
启动jobmanager
如果集群中的jobmanager进程挂了,执行下面命令启动。
bin/jobmanager.sh start
bin/jobmanager.sh stop
启动taskmanager
添加新的taskmanager节点或者重启taskmanager节点
bin/taskmanager.sh start
bin/taskmanager.sh stop
复制代码5 资源调度环境(Yarn 模式)
5.1 模式1:(常驻session)

开辟资源 yarn - session . sh
1启动一个一直运行的flink集群
./bin/yarn-session.sh -n 2 -jm 1024 -tm 1024 -d
2 附着到一个已存在的flink yarn session
./bin/yarn-session.sh -id application_1463870264508_0029
3 资源所在地/tmp/.yarn-properties-root.
2018-11-24 17:24:19,644 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli
- Found Yarn properties file under /tmp/.yarn-properties-root.
4:yarn资源描述
root@SparkMaster:/usr/local/install/flink-1.6.1# vim /tmp/.yarn-properties-root
#Generated YARN properties file
#Sat Nov 24 17:39:07 CST 2018
parallelism=2
dynamicPropertiesString=
applicationID=application_1543052238521_0001
复制代码执行任务flink run
3 执行任务
hadoop fs -mkdir /input/
hadoop fs -put README.txt /input/
./bin/flink run ./examples/batch/WordCount.jar -input hdfs://SparkMaster:9000/input/README.txt -output hdfs://SparkMaster:9000/wordcount-result.txt
4:执行结果
root@SparkMaster:/usr/local/install/flink-1.6.1# hadoop fs -cat /wordcount-result.txt
1 1
13 1
5d002 1
740 1
about 1
account 1
administration 1
复制代码

停止任务 【web界面或者命令行执行cancel命令】
复制代码5.2 模式2:(session独立互不影响)
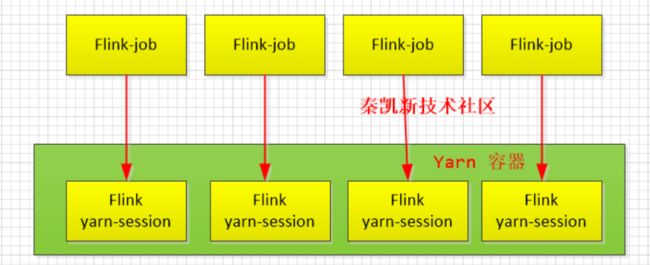
1 启动集群,执行任务
./bin/flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar -input hdfs://SparkMaster:9000/input/README.txt -output hdfs://SparkMaster:9000/wordcount-result6.txt
2018-11-24 17:56:18,066 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Waiting for the cluster to be allocated
2018-11-24 17:56:18,078 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deploying cluster, current state ACCEPTED
2018-11-24 17:56:24,901 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - YARN application has been deployed successfully.
复制代码2 :提交一次,生成一个Yarn-session

6 flink run 参数指定:
1 参数必选 :
-n,--container 分配多少个yarn容器 (=taskmanager的数量)
2 参数可选 :
-D 动态属性
-d,--detached 独立运行
-jm,--jobManagerMemory JobManager的内存 [in MB]
-nm,--name 在YARN上为一个自定义的应用设置一个名字
-q,--query 显示yarn中可用的资源 (内存, cpu核数)
-qu,--queue 指定YARN队列.
-s,--slots 每个TaskManager使用的slots数量
-tm,--taskManagerMemory 每个TaskManager的内存 [in MB]
-z,--zookeeperNamespace 针对HA模式在zookeeper上创建NameSpace
-id,--applicationId YARN集群上的任务id,附着到一个后台运行的yarn session中
3 run [OPTIONS]
run操作参数:
-c,--class 如果没有在jar包中指定入口类,则需要在这里通过这个参数指定
-m,--jobmanager 指定需要连接的jobmanager(主节点)地址,使用这个参数可以指定一个不同于配置文件中的jobmanager
-p,--parallelism 指定程序的并行度。可以覆盖配置文件中的默认值。
4 启动一个新的yarn-session,它们都有一个y或者yarn的前缀
例如:./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar
连接指定host和port的jobmanager:
./bin/flink run -m SparkMaster:1234 ./examples/batch/WordCount.jar -input hdfs://hostname:port/hello.txt -output hdfs://hostname:port/result1
启动一个新的yarn-session:
./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar -input hdfs://hostname:port/hello.txt -output hdfs://hostname:port/result1
5 注意:命令行的选项也可以使用./bin/flink 工具获得。
6 Action "run" compiles and runs a program.
Syntax: run [OPTIONS]
"run" action options:
-c,--class Class with the program entry point
("main" method or "getPlan()" method.
Only needed if the JAR file does not
specify the class in its manifest.
-C,--classpath Adds a URL to each user code
classloader on all nodes in the
cluster. The paths must specify a
protocol (e.g. file://) and be
accessible on all nodes (e.g. by means
of a NFS share). You can use this
option multiple times for specifying
more than one URL. The protocol must
be supported by the {@link
java.net.URLClassLoader}.
-d,--detached If present, runs the job in detached
mode
-n,--allowNonRestoredState Allow to skip savepoint state that
cannot be restored. You need to allow
this if you removed an operator from
your program that was part of the
program when the savepoint was
triggered.
-p,--parallelism The parallelism with which to run the
program. Optional flag to override the
default value specified in the
configuration.
-q,--sysoutLogging If present, suppress logging output to
standard out.
-s,--fromSavepoint Path to a savepoint to restore the job
from (for example
hdfs:///flink/savepoint-1537).
7 Options for yarn-cluster mode:
-d,--detached If present, runs the job in detached
mode
-m,--jobmanager Address of the JobManager (master) to
which to connect. Use this flag to
connect to a different JobManager than
the one specified in the
configuration.
-yD use value for given property
-yd,--yarndetached If present, runs the job in detached
mode (deprecated; use non-YARN
specific option instead)
-yh,--yarnhelp Help for the Yarn session CLI.
-yid,--yarnapplicationId Attach to running YARN session
-yj,--yarnjar Path to Flink jar file
-yjm,--yarnjobManagerMemory Memory for JobManager Container with
optional unit (default: MB)
-yn,--yarncontainer Number of YARN container to allocate
(=Number of Task Managers)
-ynl,--yarnnodeLabel Specify YARN node label for the YARN
application
-ynm,--yarnname Set a custom name for the application
on YARN
-yq,--yarnquery Display available YARN resources
(memory, cores)
-yqu,--yarnqueue Specify YARN queue.
-ys,--yarnslots Number of slots per TaskManager
-yst,--yarnstreaming Start Flink in streaming mode
-yt,--yarnship Ship files in the specified directory
(t for transfer)
-ytm,--yarntaskManagerMemory Memory per TaskManager Container with
optional unit (default: MB)
-yz,--yarnzookeeperNamespace Namespace to create the Zookeeper
sub-paths for high availability mode
-z,--zookeeperNamespace Namespace to create the Zookeeper
sub-paths for high availability mode
复制代码