【MySQL】子查询
一、基本概念
1、子查询指的就是一个查询语句嵌套在另外一个查询语句的内部
2、样例展示
还是使用之前的t_decade_bolg表,我们想查出那些浏览量views大于id为06bd6c69-e47e-4e78-9e02-5110a013e457的博客信息

# 方式一
SELECT views FROM t_decade_blog WHERE ID = '06bd6c69-e47e-4e78-9e02-5110a013e457';
SELECT id,name,views FROM t_decade_blog WHERE views > 4000;
# 方式二:自连接
SELECT blogB.id,blogB.views,blogB.name
FROM t_decade_blog blogA,t_decade_blog blogB
WHERE blogB.views > blogA.views
AND blogA.id = '06bd6c69-e47e-4e78-9e02-5110a013e457';
SELECT blogB.id,blogB.views,blogB.name
FROM t_decade_blog blogA,t_decade_blog blogB
WHERE blogB.views > blogA.views
AND blogA.id = '06bd6c69-e47e-4e78-9e02-5110a013e457';
# 方式三:使用子查询
SELECT id,name,views
FROM t_decade_blog
WHERE views > (SELECT views FROM t_decade_blog WHERE ID = '06bd6c69-e47e-4e78-9e02-5110a013e457');
执行结果为

注意:这三种方式中子查询方式更好
3、使用规范
- 外查询(或主查询)与内查询(或子查询)都是相对而言的
- 子查询在主查询之前执行,结果被主查询使用
- 子查询要用括号包起来,将其放在比较条件的右侧
- 单行操作符对应单行子查询,多行操作符对应多行子查询
4、子查询分类
- 从子查询返回的条目数:单行子查询 VS 多行子查询
- 单行子查询:子查询返回单行数据
- 多行子查询:子查询返回多行数据
- 子查询是否可以执行多次:相关子查询 VS 不相关子查询
- 相关子查询:比如我们要查询出所有工资大于
本部门平均工资的员工信息,不同部门的人他所执行的子查询所返回的结果是不相同的,因为子查询的结果和主查询遍历到那一行数据的部门信息有关 - 不相关子查询:子查询只需要执行一次,例如我们要查询出所有工资大于
公司平均工资的员工信息,这里和部门没关系,那就只用执行一次
- 相关子查询:比如我们要查询出所有工资大于
二、单行子查询
1、单行子查询的比较操作符
=:等于>:大于>=:大于等于<:小于<=:小于等于<>:不等于
我们再向t_decade_blog中插入一条数据
INSERT INTO t_decade_blog(id,name,author,create_time,views)VALUES('1hg6dc69-e47e-4e78-9e02-5110a2jdhg90','MySQL基础','Decade0712',NOW(),4000);
数据如下

# 返回浏览量大于06bd6c69-e47e-4e78-9e02-5110a013e457的博客信息
SELECT id,name,author,views
FROM t_decade_blog
WHERE views >
(SELECT views
FROM t_decade_blog
WHERE ID = '06bd6c69-e47e-4e78-9e02-5110a013e457'
);
# 返回浏览量大于06bd6c69-e47e-4e78-9e02-5110a013e457且作者与1hg6dc69-e47e-4e78-9e02-5110a2jdhg90相同的博客信息
SELECT id,name,author,views
FROM t_decade_blog
WHERE views >
(SELECT views
FROM t_decade_blog
WHERE ID = '06bd6c69-e47e-4e78-9e02-5110a013e457'
)
AND
author =
(SELECT author
FROM t_decade_blog
WHERE ID = '1hg6dc69-e47e-4e78-9e02-5110a2jdhg90');
# 返回浏览量最少的博客信息
SELECT id,name,author,views
FROM t_decade_blog
WHERE views =
(SELECT MIN(views)
FROM t_decade_blog
);
# 查出其他与'06bd6c69-e47e-4e78-9e02-5110a013e457'作者相同且浏览量相同的博客信息
# 方式一
SELECT id,name,author,views
FROM t_decade_blog
WHERE author = (SELECT author FROM t_decade_blog WHERE id = '06bd6c69-e47e-4e78-9e02-5110a013e457')
AND views = (SELECT views FROM t_decade_blog WHERE id = '06bd6c69-e47e-4e78-9e02-5110a013e457')
AND id <> '06bd6c69-e47e-4e78-9e02-5110a013e457';
# 方式二
SELECT id,name,author,views
FROM t_decade_blog
WHERE (author,views) = (SELECT author,views FROM t_decade_blog WHERE id = '06bd6c69-e47e-4e78-9e02-5110a013e457')
AND id <> '06bd6c69-e47e-4e78-9e02-5110a013e457';
执行结果如下




2、HAVING中的子查询
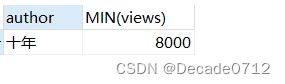
# 查询最低浏览量大于Decade0712写的博客最低浏览量的作者和他博客中的最低浏览量
SELECT author,MIN(views)
FROM t_decade_blog
GROUP BY author
HAVING MIN(views) > (SELECT MIN(views) FROM t_decade_blog WHERE author = 'Decade0712');
执行结果如下
3、case中的子查询
# 显示博客的名称,作者,浏览量,另外再加一行级别
# 如果浏览量和Mybatis系列相同就是初级,和Spring系列相同,就是中级,否则就是高级
SELECT name,author,views,(CASE views
WHEN (SELECT views FROM t_decade_blog WHERE name = 'Mybatis系列')THEN '初级'
WHEN (SELECT views FROM t_decade_blog WHERE name = 'Spring系列')THEN '中级'
ELSE '高级' END
) level
FROM t_decade_blog;
执行结果如下

4、子查询中的空值问题
如果子查询没有查到任何数据,返回空值,那么最后主查询得到的结果也会是null
5、非法使用子查询
单行操作符后面不能接多行子查询
三、多行子查询
1、多行子查询的比较操作符
- IN:等于列表中的
任意一个 - ALL:需要和单行比较操作符搭配使用,和子查询返回的
所有值进行比较 - ANY:需要和单行比较操作符搭配使用,和子查询返回的
某一个值比较 - SOME:ANY的别名,作用相同,通常使用ANY
2、样例演示
向t_decade_blog中插入新的数据
INSERT INTO t_decade_blog(id,name,author,create_time,views)VALUES('djah8b79-d543-49bb-9850-16cac756shgg','Java8新特性','十年',NOW(),5500);
数据更新后如下

# 查询出各个作者的最低浏览量,看看表中有哪些博客的浏览量等于这些值
SELECT id,name,author,views
FROM t_decade_blog
WHERE views IN (SELECT MIN(views) FROM t_decade_blog GROUP BY author);
# 查询出浏览量大于Decade0712所写的某一篇博客的博客信息
SELECT id,name,author,views
FROM t_decade_blog
WHERE author <> 'Decade0712'
AND views > ANY(SELECT views FROM t_decade_blog WHERE author = 'Decade0712');
# 查询出浏览量大于Decade0712所写的任意一篇博客的博客信息
SELECT id,name,author,views
FROM t_decade_blog
WHERE author <> 'Decade0712'
AND views > ALL(SELECT views FROM t_decade_blog WHERE author = 'Decade0712');
执行结果为



# 如果我们想查询出哪个作者的平均浏览量最小
# 方式一:使用虚拟表
# 第一步:查询每个作者的平均浏览量
SELECT author,AVG(views) FROM t_decade_blog GROUP BY author;
# 第二步:假设我想查出每个作者的平均浏览量后,找出最小平均值,直接使用MIN()嵌套AVG()是不允许的
SELECT MIN(AVG(views)) FROM t_decade_blog GROUP BY author;
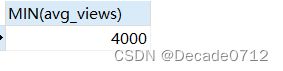
# 所以我们这里将AVG()查询出来的结果取一个别名,当作某个虚拟表的字段,并且给这个虚拟表取个名字就可以了
SELECT MIN(avg_views)
FROM (SELECT AVG(views) avg_views FROM t_decade_blog GROUP BY author) t_avg_views;
# 第三步:
SELECT author FROM t_decade_blog
GROUP BY author
HAVING AVG(views) = (
SELECT MIN(avg_views)
FROM (
SELECT AVG(views) avg_views
FROM t_decade_blog
GROUP BY author
)
t_avg_views);
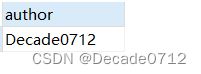
# 方式二:使用ALL
SELECT author FROM t_decade_blog
GROUP BY author
HAVING AVG(views) <= ALL(
SELECT AVG(views) avg_views
FROM t_decade_blog
GROUP BY author
);
执行SQL结果为


3、多行子查询空值问题
子查询返回的结果集中包含空值null
四、相关子查询
1、相关子查询的执行流程
- 如果子查询的执行依赖于外部查询,通常都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新执行一次,这样的子查询就称为相关子查询
- 相关子查询按照一行接一行的顺序执行,主查询的每一行都执行一次子查询
- 从主查询中获取候选数据—>子查询使用主查询传进来的数据—>如果满足子查询的条件则返回该行
2、代码示例
我们还是使用t_decade_blog表
# 查询那些浏览量大于自己作者博客平均浏览量的博客名、浏览量和作者
# 方式一:相关子查询
SELECT name,author,views
FROM t_decade_blog B1
WHERE views > (
SELECT AVG(views)
FROM t_decade_blog B2
WHERE author = B1.author
);
# 方式二:前面说过的在FROM中使用虚拟表,通过自连接的方式进行数据筛选
SELECT B1.name,B1.author,B1.views
FROM t_decade_blog B1,(
SELECT author,AVG(views) avg_views
FROM t_decade_blog
GROUP BY author) t_avg_views
WHERE B1.views > t_avg_views.avg_views
AND B1.author = t_avg_views.author;
SQL执行结果如下

# 假设我们有一个员工表和一个部门表
# 现在我们想查询员工的id,salary(员工表t_employee中),并且按照他的department_id(员工表t_dept中)对数据进行排序
# 使用外连接或者使用相关子查询都可
SELECT id,salary
FROM t_employee e
ORDER BY (
SELECT department_id
FROM t_dept d
WHERE e.department_id = d.department_id
);
3、子查询的位置
我们之前梳理过SELECT语句结构
SELECT 字段1,字段2,...(可能存在聚合函数)
FROM 表1 (LEFT / RIGHT) JOIN 表2 ON 多表的连接条件
(LEFT / RIGHT) JOIN 表2 ON 多表的连接条件2...
WHERE 不包含聚合函数的过滤条件
GROUP BY 分组字段1,分组字段2...
HAVING 包含聚合函数的过滤条件
ORDER BY 排序字段1,排序字段2...(ASC / DESC)
LIMIT 偏移量,条目数;
注意:在SELECT语句中,除了GROUP BY和LIMIT,其他地方都可以使用子查询
4、EXISTS和NOT EXISTS关键字
- 关联子查询通常也会和
EXISTS操作符一起来使用,用来检查子查询中是否存在满足条件的行 - 如果在子查询中不存在满足条件的行
- 条件返回false,并继续在子查询中进行遍历,寻找满足条件的行
- 如果在子查询中存在满足条件的行
- 条件返回true,不在子查询中继续遍历
假设表t_employee表中存有员工和员工直系领导的信息,那我们如何查出公司各领导的员工id,部门id和名称呢?
# 方式一:自连接
SELECT DISTINCT employee_id,dept_id,name
FROM t_employee emp JOIN t_employee mgr
ON emp.manager_id = mgr.employee_id;
# 方式二:使用子查询
SELECT employee_id,dept_id,name
FROM t_employee
WHERE employee_id IN
(
SELECT DISTINCT manager_id
FROM t_employee
);
# 方式三:使用EXISTS
# 主查询遍历表中的每一行,然后传入子查询中
# 子查询会带着传入行的employee_id去一行行匹配,看看是否存在某位员工的manager_id是主查询传入的employee_id,满足则退出遍历,开始传入主查询的下一行
SELECT employee_id,dept_id,name
FROM t_employee e1
WHERE employee_id EXISTS
(
# 这里随便填SELECT *还是 SELECT 什么
SELECT *
FROM t_employee e2
WHERE e1.employee_id = e2.manager_id
);
NOT EXISTS表示如果不存在某种条件,则返回true,否则返回false
# 查询t_dept表中那些dept_id没有出现在t_employee表内的部门,查询他们的部门id和名称
# 方式一:
SELECT dept.dept_id,dept.dept_name
FROM t_employee e RIGHT JOIN t_dept dept
ON e.dept_id = dept.dept_id
WHERE e.dept_id IS NULL;
# 方式二:
# 主查询遍历表中的每一行,然后传入子查询中
# 子查询会带着传入行的dept_id去一行行匹配,看看是否存在某个部门的dept_id是主查询传入的dept_id,满足则继续遍历,直到找到不满足的那一行,就停止遍历,开始传入主查询的下一行
SELECT dept_id,dept_name
FROM t_dept dept
WHERE dept_id NOT EXISTS
(
SELECT *
FROM t_employee e1
WHERE dept.dept_id = e1.dept_id
);
5、相关更新和相关删除
- 使用相关子查询,依据一个表中的数据更新另一个表中的数据
UPDATE table1 alias1
SET column = (
SELECT expr
FROM table2 alias2
WHERE alias1.column = alias2.column
);
- 使用相关子查询,依据一个表中的数据删除另一个表中的数据
DELETE table1 alias1
WHERE column 条件操作符(=、in等) (
SELECT expr
FROM table2 alias2
WHERE alias1.column = alias2.column
);
如有错误,欢迎指正!!!