搭建一个通用监控告警平台,架构上需要有哪些设计

大家好,又见面了。
说到监控告警平台,大家应该都不会陌生,对于线上系统而言可以说是个标配,各个公司或项目也都会有搭建自己的监控告警平台的实际诉求。
当前比较主流的监控告警平台实现方案,很多都是基于Prometheus + Grafana + AlertManager来实现的。但是实际使用的时候会发现不易实施:
-
在运维部署对接方面存在一些不便,接入新的被监控节点时需要到平台部署机器上去修改配置文件、甚至重启服务来生效
-
配置告警规则等也是基于xml配置,必须要到平台服务器上去添加文件,对于一个各项目通用的平台而言,显然不可能将后端服务地址暴露让各业务负责人员去自行修改服务器上的配置文件
-
Grafana界面相对单一、可以用于看板或者大屏展示,但是一些公司内高度定制化的页面能力实现起来会比较麻烦(当然也可以基于Grafana二次开发定制),或者想在公司已有的运维平台中深度集成,实现难度较大。
前段时间研究了下基于Prometheus构建监控系统相关的概念,并以此为基准设计了一个企业级通用的监控告警平台的方案。这里分享一下架构的分析过程以及上述问题的解决思路。

平台与业务职责规划
既然是构建通用平台,就会涉及到平台与业务的职责划分的问题,这条线究竟按照什么尺度去画,究竟将平台做厚还是做薄,将直接决定了平台的整体定位:
- 平台做的太厚重,势必导致业务使用的约束增加、且定制化能力减弱,适用范围受限;
- 平台做的太轻薄,业务虽然有更多的主导权与定制灵活度,但也导致各个业务需要重复构建相关能力,平台将失去意义。

从构建通用平台的角度而言,很明显厚平台方案更具优势,可以统一整个公司各个业务的监控水平、可以持续的汇聚能力、积累沉淀。
所以,最终选择采用厚平台模式来构建:
- 集成数据存储、统计、告警策略、告警推送等能力,业务仅负责埋点数据上报即可。
- 告警能力扩展性强,全业务无差别共享
- 业务接入简单,但平台实现工作量较大
- 业务可以有限定制,但是需要基于管理界面上去配置规则,受平台规则支持度限制

用户场景诉求分析
先分析下对监控平台的一个整体的诉求情况、以及监控平台需要支持的一些核心业务场景。
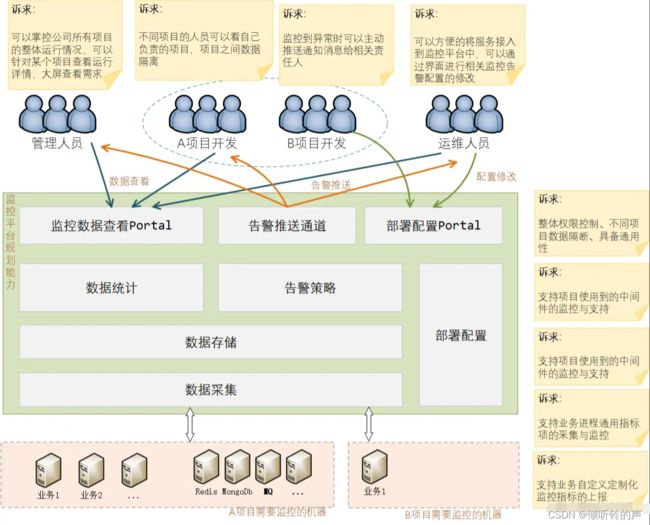
从用户角度,收集下不同角色的人员的诉求:
-
管理人员:
- 掌控全局整体情况
- 可以按照不同维度查看(比如按照部门、按照项目、按照负责人等维度进行查看)
-
开发人员:
- 知晓自己负责的项目的状态
- 若有异常能第一时间收到告警通知
- 可定制自己项目的告警规则与告警接收人员
-
运维人员:
- 查看负责的所有机器情况
- 部署接入简单
- 中间件可以一键接入,不要有额外的部署安装操作
- 监控平台自身的稳定与可靠
总结下来,用户层面对系统的诉求点主要有:
能用:能查看整体情况、能划分权限控制、能接收告警 易用:业务接入简单、方便自定义规则

选型与整体设计
作为监控平台,当前主流的一个方案就是Prometheus + Grafana + AlertManager的配套,本次方案也使用此常规配套。
关键设计点:
-
由于
prometheus采用配置文件的方式管理数据采集、告警规则等,为方便使用,设计搭建配置界面与配套服务,负责web端修改配置,server端写入prometheus配置文件中的逻辑、中间件探针自动启动部署等能力。 -
考虑到
prometheus告警推送通道有限、因此设计了消息推送服务,提供rest接口接收prometheus的告警推送,然后转发到现有的微信推送通道中,实现在微信上接收告警。 -
通常
Prometheus探针会部署到被监控的进程所在机器上,较为分散,维护难度较大。对于常见的各种中间件的数据采集探针,采用集中服务器部署的方案,通过web下发命令部署对应中间件的探针服务。
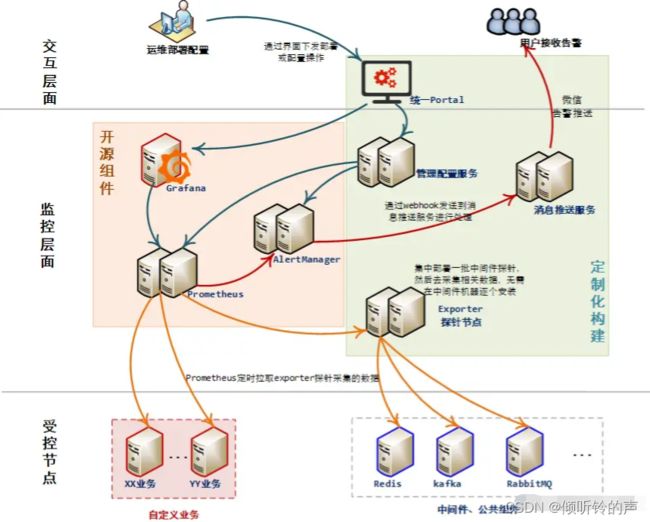
最终整体构建的全貌图如上所示,橙色的部分为使用开源组件实现,绿色部分为自行构建,作为辅助能力,打通平台的辅助操控能力,降低用户的使用门槛。

关键点设计
监控平台管理界面方案
作为与用户层面打交道的门面,管理界面端的实现既要承载用户维度的基本使用诉求,更是解决前述说的Prometheus + Grafana + AlertManager使用配置与规则定制门槛过高的关键一环。
基于Prometheus构建的监控平台中,很多都是标配了Grafana作为界面展示。但是Grafana作为通用开源组件,侧重点在dashboard展示能力上,其余一些管理能力较为弱化。

所以在界面的规划上,采用的策略是继续以现有的运维平台界面为主,设计整合grafana的dashboard展示能力。也即对用户而言,入口都是运维平台Poral,一些规则配置、部署操作等统一由运维平台portal提供,只是点击查看某个项目的数据时,跳转到Grafana展示。

分层、分组告警实现机制
作为一个监控告警平台,告警能力自然是最关键的一个部分。此部分使用Prometheus已有能力。
具体实施时,为了实现告警的按需推送、精准推送,规划在Prometheus配置采集探针数据的时候,为每个探针配置对应的标签数据,比如项目组、系统、模块、环境类型等等信息。这样就可以进一步按照项目组或者系统维度进行推送给相关人员。
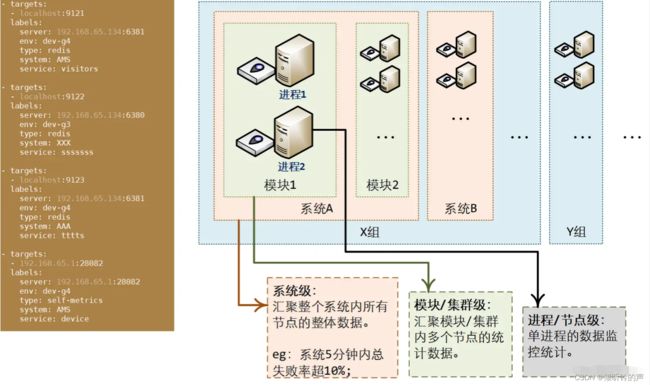
此处规划是在prometheus拉取探针服务的地方进行配置追加固定分组tag信息,而不是由各个探针的指标项中自己上报,主要也是从平台统一控制维度进行考量。
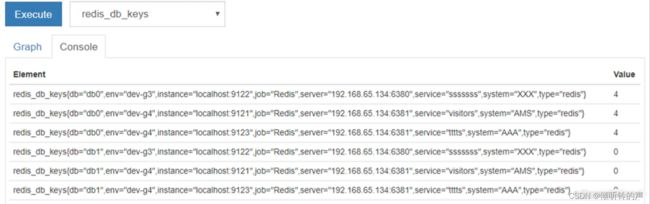
对接告警通道设计
Prometheus实现告警有2种可选方案:
- 对接
Prometheus AlarmManager组件, 通过修改服务器上的本地配置文件,实现告警规则的设置; - 对接
Grafana,使用Grafana告警功能,直接在Grafana的界面指标项中进行配置。
其实,不管是Prometheus AlertManager还是Grafana,其配置都需要遵循一定的规则,对于没接触过的人而言,还是有一定的使用门槛的,而且两种配置起来都很不方便,尤其是AlertManager,还得登录部署服务器上去新增或修改配置文件 —— 这个作为一个平台,显然是不可接受的。
所以,从功能与便捷性角度考虑,选定使用AlertManager实现告警能力。作为对其弊端的补偿,规划构建管理配置服务,并在平台统一Portal上提供无门槛易用的配置能力,如下:
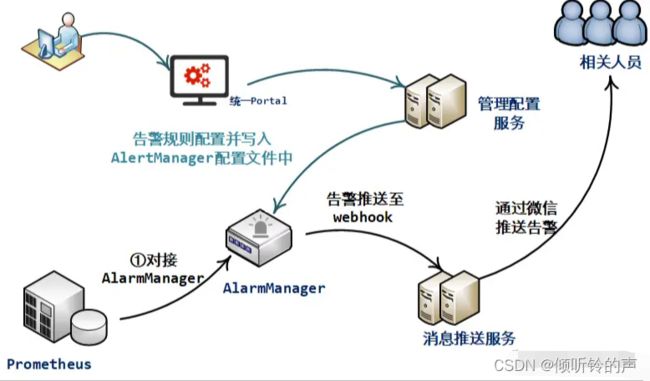
用户通过界面上配置好之后,变更的配置文件经由管理配置服务中转,自动写入AlertManager对应配置文件中,由此避免人为修改AlertManager服务端配置文件可能引发的问题。
AlarmManage预置的告警通道主要有邮箱、钉钉、企业微信、或者webhook等。出于可自由定制、以及后续可自由定制的角度触发,此处选择采用webhook的方式:
- 新开发一个
webhook告警接收服务,提供rest接口用来接收告警信息; - 对接收到的告警信息进行处理后,调用当前监控平台提供的微信告警推送接口,推送给用户。

部署与运维管理策略
基于Prometheus的机制,数据上报采用探针的方式暴露相关接口,然后Prometheus定时轮询拉取。
对于探针的部署,考虑可选常规模式与集中模式两种。
常规模式: 各业务、各中间件节点自行部署自己的探针服务。
集中模式: 各中间件的探针服务集中部署,打通web端配置逻辑,根据自动部署探针服务。

从实施工作量上进行评估,最终敲定混合使用两种模式:
- 中间件监控,采用集中部署,作为平台能力一部分,集中监管。
- 各业务监控,采用常规模式,各个业务自行定制提供探针服务并部署。
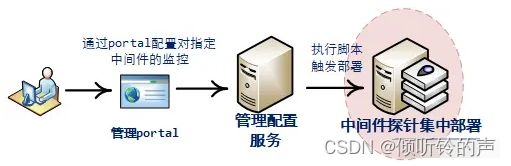
关于中间探针集中部署:
- 将各常见中间件的exporter包安装到服务器上
- 根据web传过来的被监控中间件的类型
- 执行命令,z启动对应探针
- 为了后续可维护,将启动命令写入脚本文件中,设定开机自启动
- 相关配置信息、每个exporter绑定的port信息以及监控的中间件信息,保存到DB中,便于维护。

高可用设计
作为一个用来监控其他服务是否正常的告警平台,其自身的高可用性显然是必须要考虑的事情。一旦监控平台挂掉,业务出问题可能就无法第一时间通知到责任人,很容易引发线上事故。
对整个平台的高可用设计,采用分模块不同的策略:
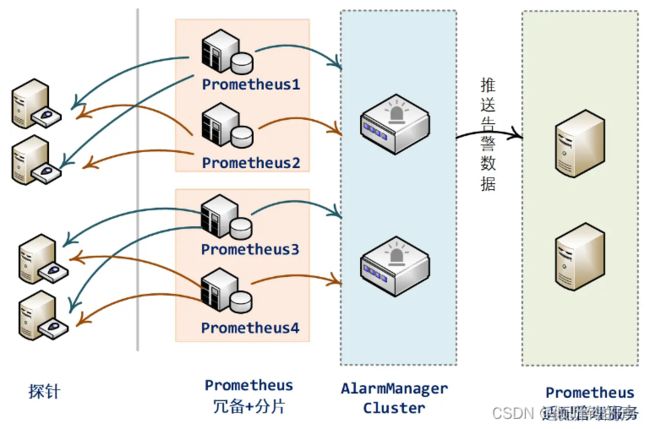
Prometheus 高可用:冗备方案。部署2套prometheus进程,两套prometheus采集相同的探针节点,拥有完全相同的配置数据。 可扩展:分片策略。当监控对象数量太多时,将监控对象分片,每个分片部署一套(2个进程)prometheus服务,实现水平无限制扩展。
AlarmManager 高可用、可扩展:集群部署。多个prometheus进程发送到AlarmManager Cluster中的重复告警信息,最终只会有1条告警会被发送出去。
配置部署服务 高可用、可扩展:集群部署。部署多个进程节点,对外提供统一访问地址。
探针服务 非监控平台主体,不做高可用保证,宕机会有告警,满足要求。

总体回顾
回顾下整个方案的分析与设计过程,其实整体逻辑很简单,选型确定之后,根据选型结果,以及选型与目标诉求之间的差异度,考虑如何抹平两者之间的差异。也即所谓的“不忘初心、以始为终”。
按照上述策略搭建完成后,整体的监控平台的功能全貌为如下:
