Elasticsearch的核心技术
文章目录
- Elasticsearch介绍
-
- 利用数据库做搜索
- 全文检索与倒排索引
- 什么是Elasticsearch
- Elasticsearch的功能
- Elasticsearch的核心概念
- Elasticsearch操作入门
-
- Document数据格式
- 查看集群信息
- 文档的增删改查
- 五种搜索方式
-
- query string search
- query DSL
- query filter
- full-text search
- phrase search
- 聚合分析
- Elasticsearch的分布式
-
- 透明隐藏特性
- shard&replica机制
- ES的容错机制
- 分布式文档系统
-
- Document的核心元数据
- Document ID的生成
- Document的全量替换
- partial update
- 批量查询mget
- bulk批量增删改
- Document数据路由
- Document增删改查的原理
- Elasticsearch的并发控制
-
- 悲观锁与乐观锁
- 基于_version的乐观锁
- external version
- partial update内部的并发控制
- ElasticSearch的搜索引擎
-
- deep paging的原理
- _all metadata的原理
- mapping
-
- 自动创建mapping
- 手动创建mapping
- 复杂的数据类型
- normalization
- 分词器
- 字符串排序问题
- 相关度评分算法
- query phase
- 索引管理
-
- 创建索引
- 修改分词器
- type的底层数据结构
- 定制dynamic mapping策略
- Elasticsearch的内核原理
-
- 倒排索引的结构
- Document写入的内核级原理
Elasticsearch介绍
Elasticsearch是一个分布式、高性能、高可用、可伸缩的搜索和分析系统。
搜索,就是在任何场景下找寻你想要的信息,输入一段你要搜索的关键字,就能找到和这个关键字相关的有效信息。例如百度系统、垂直搜索(站内搜索)、IT系统的搜索。
利用数据库做搜索
例如一个电商中,搜索名字中带有牙膏两个字的商品,其SQL语句为:
select * from products where product_name like "%牙膏%"
- 数据库来处理的话(暂时不考虑索引),假如商品有1000万 个,那么基本上就要查找 1000 万次,且每次都需要加载商品的名称字段的整段字符串,并挨个寻找。每条记录的指定字段的文本可能会很长,比如说“商品描述”字段的长度,可能长达数千个字符,每次都要对每条记录的所有文本进行扫描,性能很差。
- 还不能将搜索词拆分开来,尽可能去搜索更多的符合你的期望的结果,比如输入“生化机”,就搜索不出来“生化危机”,没有分词机制。
全文检索与倒排索引
对于一个数据库中的数据进行全文搜索时,有顺序扫描法和建立索引法,对于ES,采用了建立索引法
如上面一个文档,用户输入“跳槽图”进行搜索,ElasticSearch会建立一个倒排索引,方式为:将每条数据进行词条拆分,每个关键词将对应所有包含此关键词的文档编号ID,搜索的时候,直接匹配这些关键词,就能拿到包含关键词的文档内容,如“跳槽图”被拆分为“跳槽”和“图”两个词,在倒排索引中找到倒排列表为1,4,返回文档1和4。
什么是Elasticsearch
Lucene
Lucene就是一个jar包,里面包含了封装好的各种建立倒排索引以及进行搜索的代码。当使用Java开发的时候,引入lucene.jar,然后基于Lucene的API去开发就可以了。利用Lucene,可以去将已有的数据建立索引,Lucene会在本地磁盘上面组织索引的数据结构。还可以利用Lucene提供的一些功能和API对磁盘上的数据进行搜索。
我们可以使用Lucene开发搜索服务,部署在一台机器上面,但是无法解决当数据量增大的时候出现的问题。当数据量过大时,需要建立多台机器的分布式系统,这时分布式一致性和数据的高可用便成为难题。Elasticsearch就是基于Lucene开发的,解决这些问题的方案。
- 自动维护数据分布到多个节点的索引建立、检索请求发布到多个节点的执行;
- 自动维护数据的冗余副本,保证一些机器宕机了,不会丢失任何数据;
- 封装了更多的高级功能,开发更加复杂的应用,如聚合分析,位置搜索等。
Elasticsearch的功能
1.分布式的搜索引擎和数据分析引擎
搜索:百度,网站的站内搜索,IT系统的检索;
数据分析:电商网站,最近7天牙膏这种商品销量排名前10的商家有哪些。
2.全文检索,结构化检索,数据分析
全文检索:搜索商品名称包含牙膏的商品;
结构化检索:搜索商品分类为日化用品的商品都有哪些;
数据分析:分析每一个商品分类下有多少个商品,select category_id,count(*) from products group by category_id
3.对海量数据进行近实时的处理
海量数据:ES自动可以将海量数据分散到多台服务器上去存储和检索,分布式以后,自然而然就可以实现海量数据的处理了;
近实时:在秒级别对数据进行搜索和分析。
Elasticsearch的核心概念
Lucene是最先进、功能最强大的搜索库。但直接基于Lucene开发非常复杂(实现一些简单的功能,需要写大量的 Java代码),需要深入理解各种索引结构的原理。
Elasticsearch基于Lucene,隐藏复杂性,提供简单易用的restful API、Java接口,开源,开箱即用。
Near Realtime近实时
从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级。
Cluster集群
包含多个节点(Node),每个节点属于哪个集群是通过配置来决定的,对于中小型应用来说,刚开始一个集群就一个节点。
Document文档
ES中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示。一个document里面有多个field,每个field就是一个数据字段。
product document
{
"product_id": "1",
"product_name": "高露洁牙膏",
"product_desc": "高效美白",
"category_id": "2",
"category_name": "日化用品"
}
Index索引
包含有相似结构的文档数据,比如可以有一个客户索引、商品分类索引、订单索引,索引都有一个名称。
一个Index包含很多Document,一个Index就代表了一类类似的或者相同的Document。
Type类型
每个索引里都可以有一个或多个Type,Type是Index中的一个逻辑数据分类,一个Type下的Document,都有相同的field,比如博客系统,有一个Index索引,可以定义用户数据 type,博客数据 type,评论数据 type。
商品Index,里面存放了所有的商品Document。但是商品分很多种类,每个种类的Document的field可能不太一样,比如说电器商品,可能还包含一些诸如售后时间范围这样的特殊field;生鲜商品,还包含一些诸如生鲜保质期之类的特殊field。
对比数据库:
| Elasticsearch | 数据库 |
|---|---|
| Document | 行 |
| Type | 表 |
| Index | 库 |
shard分片
单台机器无法存储大量数据,ES可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是Index的一部分。
replica副本
任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在 shard 故障时提供备用服务,保证数据不丢失,多个 replica 还可以提升搜索操作的吞吐量和性能。
默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
ES开箱即用,安装部署非常方便,本地运行后在浏览器输入:http://127.0.0.1:9200/?pretty,返回json:
{
"name" : "tV5bEC1",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "ADvPVXP2TkCe4faoeYwafQ",
"version" : {
"number" : "5.2.0",
"build_hash" : "24e05b9",
"build_date" : "2017-01-24T19:52:35.800Z",
"build_snapshot" : false,
"lucene_version" : "6.4.0"
},
"tagline" : "You Know, for Search"
}
name:node名称
cluster_name:集群名称(默认的集群名称就是elasticsearch)
version.number:ES版本号
Kibana提供了一个开发界面,启动后输入http://127.0.0.1:5601即可进入Dev Tools界面,可视化界面方便操作。
Elasticsearch操作入门
Document数据格式
例如一个Employee对象,里面包含了Employee类自己的属性,还有一个EmployeeInfo对象。
在MySQL数据库中对应两张表:employee表和employee_info表,employee_info表通过employee_id字段关联到employee表。
在ES中,只需要用一个JSON串即可:
{
"email": "[email protected]",
"first_name": "san",
"last_name": "zhang",
"info": {
"bio": "curious and modest",
"age": 30,
"interests": [ "bike", "climb" ]
},
"join_date": "2017/01/01"
}
查看集群信息
ES提供了一套cat API,用来查看ES集群的状态;
GET _cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1590043378 14:42:58 elasticsearch yellow 1 1 1 1 0 0 1 0 - 50.0%
可以通过status的值了解集群健康状态:
- green:每个索引的 primary shard 和 replica shard 都是 active 状态的;
- yellow:每个索引的 primary shard 都是 active 状态的,但是部分 replica shard 不是 active 状态,处于不可用的状态;
- red:不是所有索引的 primary shard 都是 active 状态的,部分索引有数据丢失了。
现在状态为yellow的原因是,目前ES中有一个 index,就是 kibana 自己内置建立的 index。由于默认的配置是给每个 index 分配5个 primary shard 和5个 replica shard,而且 primary shard 和 replica shard 不能在同一台机器上(为了容错)。现在 kibana 自己建立的 index 是1个 primary shard 和1个 replica shard。当前就一个 node,所以只有1个 primary shard 被分配了和启动了,但是一个 replica shard 没有第二台机器去启动。如果此时再启动一台ES服务器,那么state字段变为green。
查看集群中所有的索引:GET /_cat/indices?v
建立一个新的索引:PUT /test_index?pretty
删除一个索引DELETE /test_index?pretty
文档的增删改查
新增文档PUT /index/type/id
PUT /ecommerce/product/1
{
"name" : "gaolujie yagao",
"desc" : "gaoxiao meibai",
"price" : 30,
"producer" : "gaolujie producer",
"tags": [ "meibai", "fangzhu" ]
}
// 响应
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2, // 表示两个shard需要写入(primary + replica)
"successful": 1, // 由于没有replica只写入了一个
"failed": 0
},
"created": true
}
ES会自动建立index和type,不需要提前创建,而且ES默认会对Document每个field都建立倒排索引,让其可以被搜索到。
查询文档GET /index/type/id
GET /ecommerce/product/1
// 响应
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"name": "gaolujie yagao",
"desc": "gaoxiao meibai",
"price": 30,
"producer": "gaolujie producer",
"tags": [
"meibai",
"fangzhu"
]
}
}
替换文档PUT /index/type/id
替换时必须带上所有的field才能使用
PUT /ecommerce/product/1
{
"name" : "gaolujie yagao",
"desc" : "gaoxiao meibai",
"price" : 20,
"producer" : "gaolujie producer",
"tags": [ "meibai", "fangzhu" ]
}
// 响应
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 2,
"result": "updated", // 注意此处与新增文档的区别
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}
更新文档POST /index/type/id/_update
注意:使用POST请求,改变需要修改的field即可。
POST /ecommerce/product/1/_update
{
"doc": {
"price" : 20
}
}
// 响应
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 3, //注意版本号不断变化
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}
删除文档DELETE /index/type/id/
五种搜索方式
query string search
方法一:query string search GET /index/type/_search
还可以加入条件:GET /index/type/_search?q=filed:value
查询不满足条件:GET /index/type/_search?-q=filed:value
查询有该field字段的文档:GET /index/type/_search?q=filed
通俗来说,就是以HTTP GET方式去拼接参数的一种方式
GET /ecommerce/product/_search
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "ecommerce",
"_type": "product",
"_id": "2",
"_score": 1,
"_source": {
"name": "jiajieshi yagao",
"desc": "youxiao fangzhu",
"price": 25,
"producer": "jiajieshi producer",
"tags": [
"fangzhu"
]
}
},
......省略剩下数据
]
}
}
- took:耗费了几毫秒;
- timed_out:是否超时,默认无 timeout;
- _shards:数据拆成了5个分片,所以对于搜索请求,会打到所有的primary shard(或者是它的某个replica shard);
- hits.total:查询结果的数量,默认查询前十条;
- hits.max_score:score 的含义,就是 document 对于一个 search 的相关度的匹配分数,越相关,就越匹配,分数也高;
- hits.hits:包含了匹配搜索的 document 的详细数据。
带有条件的查询(不常用):GET /ecommerce/product/_search?q=name:yagao&sort=price:desc
timeout机制:指定每个 shard 就只能在 timeout 时间范围内,将搜索到的部分数据(也有可能是全部搜索到的数据)直接返回给 client 程序,而不是等到所有的数据全都搜索出来后再返回。
GET /_search?timeout=1ms
单位:timeout=10ms,timeout=1s,timeout=1m…
multi-index/type搜索模式
可以一次性搜索多个index和多个type下的数据:
/_search:所有索引,所有 type 下的所有数据都搜索出来/index1/_search:指定一个 index,搜索其下所有 type 的数据/index1,index2/_search:同时搜索两个index下的数据/*1,*2/_search:按照通配符去匹配多个索引index1/type1/_search:搜索一个 index 下指定的 type 的数据index1/type1,type2/_search:可以搜索一个 index 下多个 type的数据index1,index2/type1,type2/_search:搜索多个 index 下的多个 type的数据_all/type1,type2/_search:_all,搜索所有 index 下的指定 type 的数据
query DSL
方法二:query DSL
DSL:Domain Specified Language,特定领域的语言
http request body:请求体,可以用 json 的格式来构建查询语法,比较方便,可以构建各种复杂的语法,比 query string search强大得多。
p.s. HTTP协议一般不允许get请求带上request body,但是因为get更加适合描述查询数据的操作,就这样用了。
查询所有:
GET /ecommerce/product/_search
{
"query": {
"match_all": {}
}
}
条件查询:
GET /ecommerce/product/_search
{
"query": {
"match": { //如果把"match"变为"term",那么就不会分词了
"name": "yagao"
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
分页查询:
GET /ecommerce/product/_search
{
"query": {
"match_all": {}
},
"from": 1,
"size": 1
}
注意这里的from表示是从第几条数据开始,而不是表示页数。
组合条件查询:
GET /website/article/_search
{
"query": {
"bool": {
"must": [
{"match": {
"title": "elasticsearch"
}
}
],
"should": [
{"match": {
"content": "elasticsearch"
}
}
],
"must_not": [
{"match": {
"author_id": 111
}
}
]
}
}
}
- bool: 多个条件
- must:必须
- match:匹配
- should:可以匹配,可以不匹配,可以指明至少满足几个条件
- must_not:必须不满足
每个子查询都会计算一个 document 针对它的相关度分数,然后 bool 综合所有分数,合并为一个分数,对 filter 是不会计算分数的。
查询指定字段:
GET /ecommerce/product/_search
{
"query": {
"match_all": {}
},
"_source": ["name","price"] // 查询name与price字段
}
query filter
方法三:query filter
query filter就是在查询后,再进行过滤操作,如查询价格大于25元的牙膏:
GET /ecommerce/product/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "yagao"
}
}
],
"filter": {
"range": {
"price": {
"gte": 25
}
}
}
}
}
}
p.s. HTTP 1.1标准中没有规定GET方法是否可以有请求体,因此GET方法也可以带请求问体,完全符合标准。Elasticsearch中就是用GET方法的请求体传递搜索条件。为了兼容性考虑,Elasticsearch也接内受POST方法+请求体的搜容索方式。
对比 query 与 filter:
- filter:仅仅只是按照搜索条件过滤出需要的数据而已,不计算任何相关度分数,对相关度没有任何影响;
- query: 会去计算每个 document 相对于搜索条件的相关度,并按照相关度进行排序。
full-text search
方法四:full-text search(全文检索)
查询producer中包含"yagao"或"producer"的数据:
四条数据的producer字段分别是:jiajieshi producer、special yagao producer、gaolujie producer、zhonghua producer
GET /ecommerce/product/_search
{
"query" : {
"match" : {
"producer" : "yagao producer"
}
}
}
最终结果按照相关度分数排序:
special yagao producer -->gaolujie producer–>zhonghua producer–>jiajieshi producer
producer这个字段,会先被拆解,建立倒排索引:
| 关键词 | ids |
|---|---|
| special | 4 |
| yagao | 4 |
| producer | 1,2,3,4 |
| gaolujie | 1 |
| zhognhua | 3 |
| jiajieshi | 2 |
special yagao producer的评分为什么这么高呢?
仔细观察,搜索目标 “yagao producer” 会被拆解成yagao和producer,在倒排索引中出现了2次 ,而其他数据只出现了一次,所以它的评分是最高的。
同时全文检索还有更加高级的功能:
- 缩写 vs 全称:cn vs china
- 格式转化:like liked likes
- 大小写:Tom vs tom
- 同义词:like vs love
- 日期:2017-01-01,2017 01 01,搜索2017,或者01,都可以搜索出来
phrase search
方法五:phrase search(短语搜索)
要求输入的搜索串,必须在指定的字段文本中,完全包含一模一样的,才可以算匹配,才能作为结果返回。
GET /ecommerce/product/_search
{
"query" : {
"match_phrase" : { // 对比match
"producer" : "yagao producer"
}
}
}
结果只有produce = special yagao producer结果返回
highlight search(高亮搜索结果)
GET /ecommerce/product/_search
{
"query" : {
"match_phrase" : {
"producer" : "yagao producer"
}
},
"highlight": {
"fields": {
"producer": {}
}
}
}
结果中会返回高亮信息。
聚合分析
例如:计算每个tag下的商品数量
做聚合分析,需要在text字段上的默认fielddata=false设置为 true,通过生成正向索引并加载到内存中进行计算。
PUT /ecommerce/product/_mapping
{
"properties": {
"tags":{
"type": "text",
"fielddata": true
}
}
}
聚合分析语法:
GET /INDEX/TYPE/_search
{
"aggs": { // 聚合函数
"NAME": { // 给这个操作取一个名字
"AGG_TYPE": {} // 聚合类型
}
}
}
GET /ecommerce/product/_search
{
"aggs": {
"group_by_tags": {
"terms": { // 可以理解为是分组的意思
"field": "tags"
}
}
},
"size": 0
}
// 响应
{
"took": 146,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "fangzhu",
"doc_count": 2
},
{
"key": "meibai",
"doc_count": 2
},
{
"key": "qingxin",
"doc_count": 1
}
]
}
}
}
更多案例参考:https://github.com/zq99299/note-book/blob/master/docs/elasticsearch-core/quick-start-texample/08-aggregation-analysis.md
Elasticsearch的分布式
透明隐藏特性
Elasticsearch是一套分布式的系统,分布式是为了应对大数据量,并隐藏了复杂的分布式机制。
-
分片机制
开发者可以直接就将一些Document插入到ES集群中去了,不用关心数据怎么进行分片的,数据到哪个shard 中去;
-
cluster discovery(集群发现机制)
启动一个ES进程后,直接启动了第二个ES进程,那个进程作为一个node自动就发现了集群,并且加入了进去,还接受了部分数据 (replica shard);
扩容分为垂直扩容和水平扩容(常用)
-
shard负载均衡
假设现在有3个节点,总共有25个shard要分配到3个节点上去,ES会自动进行均匀分配,以保持每个节点的均衡的读写负载请求。当有新节点加进来的时候,一些节点上承担数据量不平衡的时候,ES会自动做rebalance 操作,将这些数据分担一部分到新机器上去。
-
master节点
默认情况下回自动选举出一台节点作为master节点,管理ES集群的元数据,负责创建或删除索引、增加或删除节点。master节点不承载所有的请求,所以不存在单节点瓶颈。ES是节点对等的分布式架构。
shard&replica机制
- 一个Index包含多个shard;
- 每个shard都是一个最小工作单元,承载部分数据,是一个lucene实例,有完整的建立索引和处理请求的能力;
- 增减节点时,shard 会自动在 nodes 中负载均衡;
- shard分为primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard中;
- replica shard 是 primary shard 的副本,负责容错,以及承担读请求负载;
- primary shard 的数量在创建索引的时候就固定了,replica shard 的数量可以随时修改;
- primary shard 的默认数量是 5,replica 默认是 1,默认有 10个 shard,5个 primary shard,5个 replica shard;
- primary shard 不能和自己的 replica shard 放在同一个节点上(否则节点宕机,primary shard 和副本都丢失,起不到容错的作用),但是可以和其他 primary shard 的 replica shard 放在同一个节点上。
在两个Node上创建一个index,有3个primary shard,3个replica shard:
PUT /test_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
横向扩容:
将ES集群从两台扩展到三台

primary&replica会自动负载均衡,6个shard,3 primary,3 replica。扩容后每个 node 有更少的 shard,IO/CPU/Memory 资源给每个 shard 分配更多,每个 shard 性能更好;
扩容是有极限的,6个shard(3 primary,3 replica),最多扩容到6台机器,每个shard可以占用单台服务器的所有资源,性能最好;当超出扩容极限时,动态修改 replica 数量,9个shard(3primary,6 replica),扩容到9台机器,比3台机器时,拥有3倍的读吞吐量。
3台机器下,9个shard(3 primary,6 replica),每个shard资源更少,但是容错性更好,最多容纳2台机器宕机,6个shard只能容纳1台机器宕机。
ES的容错机制
以9 shard,3 node集群来说明ES最基本的容错机制:
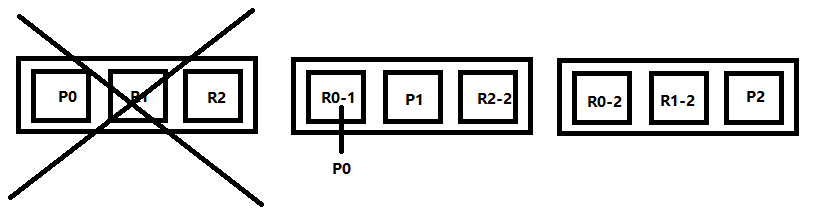
- master node 宕机,自动 master 选举,此时集群状态为red;
- replica容错:新 master 将 replica 提升为 primary shard,此时集群状态为yellow;
- 重启宕机node,master copy replica到该node,使用原有的shard并同步宕机后的修改,此时集群状态为恢复为green。
分布式文档系统
Elasticsearch运行起来以后,起到的第一个最核心的功能,就是一个分布式的文档数据存储系统(distributed document store)。
- 文档数据:ES可以存储和操作json文档类型的数据,而且这也是ES的核心数据结构,并且可以通过集群快速进行扩容,承载大量数据;
- 存储系统:ES可以对json文档类型的数据进行存储,查询,创建,更新,删除等操作,数据结构灵活多变。
其ES 满足了这些功能,就可以说已经是一个NoSQL的存储系统了。
Document的核心元数据
插入一条数据查看Document元数据信息:
PUT /test_index/test_type/1
{
"test_content": "test test"
}
// 响应
{
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"created": true
}
- _index元数据:类似的数据放在一个索引,非类似的数据放不同索引
- _type元数据:代表document属于index中的哪个类别(type)
- _id元数据:代表document的唯一标识
Document ID的生成
手动指定ID
当我们现在在开发一个电商网站做搜索功能,或者是OA系统做员工检索功能时,数据首先会存储在在网站系统或者IT系统内部的数据库中,此时就一定会有一个数据库的primary key(自增长,UUID,或者是业务编号)。如果将数据导入到ES中,此时就比较适合采用数据在数据库中已有的primary key。
自动生成ID
插入数据时采用POST代替PUT即可:
POST /test_index/test_type
{
"test_content": "test test"
}
生成的ID为:AWgPGM7zE8HO-7Ks86bu
自动生成的 ID 的特点:
- 长度为20个字符;
- URL安全:经过base64编码的id,可以放在url中传递;
- GUID方式,分布式系统并行生成时不可能发生冲突。
Document的全量替换
Document的全量替换语法与创建文档是一样的,均为PUT请求。
如果document id不存在,那么就是创建;如果document id已经存在,那么就是全量替换操作,替换Document 的json串内容。
同时Document是不可变的,采用全量替换的方式修改Document的内容,实际上直接对该Document重新建立索引,同时把版本号+1,新增这个Document。ES会将老的Document标记为deleted,当我们创建越来越多的Document的时候,ES会在适当的时机在后台自动删除标记为deleted的Document。
删除一个文档时和更新操作类似,也是一个lazy delete机制,将其标记为deleted,在适当的时间物理删除。
DELETE /test_index/test_type/1
partial update
partial update是用来更新Document的指令,语法为:
post /index/type/id/_update
{
"doc": {
"要修改的少数几个field即可,不需要全量的数据"
}
}
通过partial update,每次就传递少数几个发生修改的field即可,不需要将全量的document数据发送过去。在原理上与全量替换方法几乎一致。
partial update 相较于全量替换的优点:
- 所有的查询、修改操作,都发生在ES中的一个shard内部,避免网络数据传输的开销(减少两次网络请求,查询写回),大大提升性能;
- 减少了查询和修改中的间隔,可有效减少并发冲突情况。
p.s. Elasticsearch其实是有个内置的脚本支持的,可以基于 groovy 脚本实现各种各样的复杂操作。
批量查询mget
比如说要查询100条数据,那么就要发送100次网络请求,这个开销还是很大的;
如果进行批量查询的话,查询100条数据,就只要发送1次网络请求,网络请求的性能开销缩减100倍。
GET /_mget
{
"docs" : [
{
"_index" : "test_index",
"_type" : "test_type",
"_id" : 10
},
{
"_index" : "test_index",
"_type" : "test_type",
"_id" : 11
}
]
}
mget对提高性能十分关键
bulk批量增删改
buik是ES提供的一个批量传递操作的入口,每一个操作需要两个 json 串,语法如下:
{"action": {"metadata"}}
{"data"}
例如要创建一个文档,放 bulk 里面:
{"index": {"_index": "test_index", "_type", "test_type", "_id": "1"}} // 唯一定位信息
{"test_field1": "test1", "test_field2": "test2"} // doc 文档内容
可以使用的操作类型:
- delete:删除一个文档,只要1个json串就可以了;
- create:
PUT /index/type/id/_create,强制创建/存在则报错; - index:普通的put操作,可以是创建文档,也可以是全量替换文档;
- update:执行partial update操作。
Document数据路由
一个Index的数据会被分为多片,每片都在一个shard中, 所以一个Document只能存在于一个shard中。
当客户端创建Document时,ES此时就需要决定这个Document存放在哪一个shard上。这个过程,就称之为 docum routing (数据路由)。
路由算法:
- shard = hash(routing) % number_of_primary_shards
- routing =
_idor custom routing value
默认的 routing 就是 _id,也可以在发送请求的时候手动指定一个 routing value,比如说 put /index/type/id?routing=user_id。
Document增删改查的原理
增删改流程:
- 客户端选择一个 node 发送请求过去,这个 node 就是 coordinating node(协调节点);
- coordinating node 对 document 进行路由,将请求转发给对应的 node(有primary shard);
- 实际的 node 上的 primary shard 处理请求,然后将数据同步到 replica node;
- coordinating node 如果发现 primary node 和所有 replica node 都完成之后,就返回响应结果给客户端。
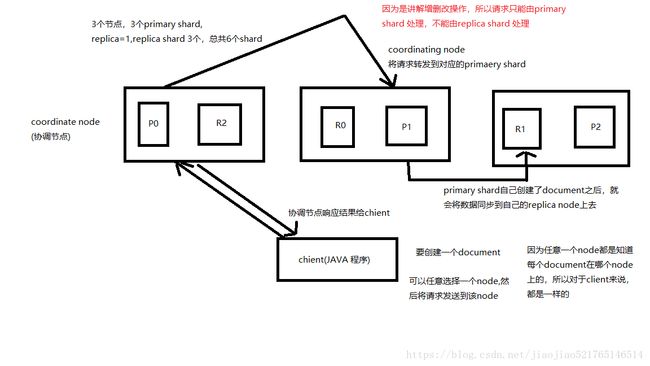
p.s. ES的分布式一致性可采用Quorum机制:https://zhuanlan.zhihu.com/p/61896391
查找数据流程:
- 客户端发送请求到任意一个 node,成为 coordinate node;
- coordinate node 对 document 进行路由,将请求转发到对应的 node。此时会使用 round-robin 随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,让读请求负载均衡;
- 接收请求的 node 返回 document 给 coordinate node;
- coordinate node 返回 document 给客户端。
可以指定preference参数来控制文档的取自何处,如果使用首选项:_primary,确保始终从主分片中获取文档。
Elasticsearch的并发控制
下面是一个常见的并发冲突问题:

悲观锁与乐观锁
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样另一个线程要想拿这个数据就会block,直到它拿到锁。传统的关系型数据库MySQL里边就用到了很多这种锁机制,比如行锁,表锁,读锁,写锁等,都是在做操作之前先上锁。
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
两种锁的对比:
- 悲观并发控制实际上是“先取锁再访问”的保守策略,为数据处理的安全提供了保证。但是并发效率很低,同一时间只能有一条线程操作数据。
- 乐观锁并发能力很高,不给数据加锁,大量线程并发操作,但是每次更新的时候,都要先比对版本号,然后可能需要再次读取数据,再次修改,再写,实现较为复杂。
基于_version的乐观锁
Elasticsearch内部是基于 _version 版本号控制。
第一次创建Document时,它的_version就是1,每次对Document进行修改或删除,都会对这个_version进行版本号的加1,哪怕是删除,也会对这条数据的版本号加1。
假设A操作修改条件是 version = 1,假设B操作修改条件也是 version = 1,那一条数据被先执行则生效,此时version变为2,后到的则因为版本号过期被丢弃。
实际案例演示:
step1:先添加一条数据,此时version = 1
PUT /test_index/test_type/7
{
"test_field": "test test"
}
step2:带上 version = 1 更新数据,客户端1更新成功
PUT /test_index/test_type/7?version=1
{
"test_field": "test client 1"
}
step3:客户端2带上 version = 1 更新数据
PUT /test_index/test_type/7?version=1
{
"test_field": "test client 2"
}
因为客户端1已结更新成功,那么此时再用版本1更新将会返回失败信息:
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[test_type][7]: version conflict, current version [2] is different than the one provided [1]",
"index_uuid": "g4RJx2v8TXK95LdwlhRx5A",
"shard": "0",
"index": "test_index"
}
],
"type": "version_conflict_engine_exception",
"reason": "[test_type][7]: version conflict, current version [2] is different than the one provided [1]",
"index_uuid": "g4RJx2v8TXK95LdwlhRx5A",
"shard": "0",
"index": "test_index"
},
"status": 409
}
想要这条数据更新成功,需要获取到这条数据的最新版本号,再带上新的版本号和数据去更新即可。
external version
external version是指外部版本号,是开发者自己维护的版本号。提供的值是与ES中的 _version 比较的提供的值必须比 _vesion 的值大,才能更新成功。
语法只多个一个version_type=external为:
?version
?version=1&version_type=external
partial update内部的并发控制
partial update的内部原理是先获取到源Document数据,将数据修改传入的字段,再写回shard,在高并发的情况下会出现并发问题,因此partial update使用了内置乐观锁进行并发控制。
参数:retry_on_conflict
retry 策略大致如下:
- 再次获取document数据和最新版本;
- 基于最新版本号再次去更新;
- 重试的次数为指定的次数,次数用完,还更新不了就失败了。
partial update也可以与_version共同使用。
POST /test_index/test_type/11/_update?retry_on_conflict=2&version=6
{
"doc": {
"num" : 2
}
}
ElasticSearch的搜索引擎
client发送一个搜索请求,会把请求发送到所有的primary shard上面去,因为每个shard都包含部分数据。如果每primary shard有replica shard,那么请求也可以打到replica shard上。
deep paging的原理
deep paging指查询的很深,比如一个索引有三个primary shard,分别存储了6000条数据,我们要得到第100页的数据(每页10个),类似这种情况就叫deep paging。
一种错误的算法为:在每个shard中搜索990到999这10条数据,然后用这30条数据排序,排序之后前10条数据就是要搜索的数据。这种做法是错的,因为3个shard中的数据的_score分数不一样,可能这某一个shard中第一条数据的_score分数比另一个shard中第1000条都要高,所以在每个shard中搜索990到999这个10条数据然后排序的做法是不正确的.
_all metadata的原理
下面的搜索,没有指定具体的字段,返回的数据是所有字段中包含test内容的数据。
GET /test_index/test_type/_search?q=test
在进行搜索时,不需要对Document中的每一个field都进行一次搜索。ES在建立索引时,插入一条Document,它里面包含了多个field, 此时ES会自动将多个field的值全部用字符串的方式串联起来,变成一个长的字符串,作为 _all field 的值,同时建立索引。后面如果在搜索的时候,没有对某个field指定搜索,就默认搜索 _all field即可。
{
"name": "jack",
"age": 26,
"email": "[email protected]",
"address": "guamgzhou"
}
将**“jack 26 [email protected] guangzhou”**,作为这条Document的_all field 的值,同时进行分词后建立对应的倒排索引.
mapping
自动创建mapping
自动或手动为 index 中的 type 建立的一种数据结构和相关配置,简称为 mapping
当直接向ES中插入数据时,使用的是 dynamic mapping,会自动为我们建立 Index,创建 Type,以及 Type 对应的 mapping,mapping 中包含了每个 field 对应的数据类型,以及如何分词等设置。
例如插入一条数据:
PUT /website/article/1
{
"post_date": "2017-01-01",
"title": "my first article",
"content": "this is my first article in this website",
"author_id": 11400
}
查看它的mapping结果GET /index/_mapping/type:
GET /website/_mapping/article
{
"website": {
"mappings": {
"article": {
"properties": {
"author_id": {
"type": "long"
},
"content": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"post_date": {
"type": "date" // 自动识别为日期类型
},
"title": {
"type": "text",
"fields": {
// 基于这个映射即可以在title字段上进行全文搜索, 也可以通过title.keyword字段实现关键词搜索及数据聚合
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
}
mapping核心的数据类型
- string
- byte,short,integer,long
- float,double
- boolean
- date
dynamic mapping规则(自动识别类型):
- true or false --> boolean
- 123 --> long
- 123.45 --> double
- 2017-01-01 --> date
- “hello world” --> string/text
手动创建mapping
索引类型有如下值:
- analyzed:全文full text
- not_analyzed:精准匹配exact value
- no:不索引
PUT /website
{
"mappings": {
"article": {
"properties": {
"author_id": {
"type": "long"
},
"title": {
"type": "text", //数据类型
"analyzer": "standard" //分词类型
},
"content": {
"type": "text"
},
"post_date": {
"type": "date"
},
"publisher_id": {
"type": "text",
"index": "not_analyzed" //索引类型
}
}
}
}
}
只能创建index时手动建立mapping,或者新增field mapping,但是不能update field mapping。
复杂的数据类型
multivalue field
建立索引时与 string 是一样的,数据类型不能混
{ "tags": [ "tag1", "tag2" ]}
empty field
主要是空值:null,[],[null]
object filed
{
"address": {
"country": "china",
"province": "guangdong",
"city": "guangzhou"
},
"name": "jack",
"age": 27,
"join_date": "2017-01-01"
}
------------分词后------------------
{
"name": [jack],
"age": [27],
"join_date": [2017-01-01],
"address.country": [china],
"address.province": [guangdong],
"address.city": [guangzhou]
}
normalization
normalization是指在建立倒排索引时,会执行一个操作,对拆分出的各个单词进行相应的处理(同义词、时态、单复数等),以提升后面搜索的时候能够搜索到相关联的文档的概率。
例如下面两个文档:
- doc1:I really liked my small dogs, and I think my mom also liked them.
- doc2:He never liked any dogs, so I hope that my mom will not expect me to liked him.
在建立倒排索引时会进行normalization,包括时态的转换,单复数的转换,同义词的转换,大小写的转换:
- mom —> mother
- liked —> like
- small —> little
- dogs —> dog
这样在搜索“mother like little dog”就可以搜索到内容了。
分词器
分词器将一段句子拆分成一个一个的单个的单词,同时对每个单词进行 normalization,处理好的结果去建立倒排索引。
分词器的作用:
- 切分词语
- normalization(提升recall召回率)
分词器组件:
-
character filter:在一段文本进行分词之前,先进行预处理,例如:
- 过滤 html 标签(
hello--> hello) - & --> and(I & you --> I and you)
- 过滤 html 标签(
-
tokenizer:分词,例如:hello you and me --> hello, you, and, me
-
token filter:例如:lowercase,stop word,synonymom,
- dogs --> dog
- liked --> like
- Tom --> tom
- a/the/an --> 去掉
ES中内置的分词器:
例如一句话:Set the shape to semi-transparent by calling set_trans(5),被以下 4 种分词器(内置常用)处理之后,会得到不同的结果:
-
standard analyzer (默认)
set, the, shape, to, semi, transparent, by, calling, set_trans, 5(默认的是standard)
-
simple analyzer
set, the, shape, to, semi, transparent, by, calling, set, trans
-
whitespace analyzer
Set, the, shape, to, semi-transparent, by, calling, set_trans(5)
-
language analyzer(特定的语言的分词器,例如English,英语分词器)
set, shape, semi, transpar, call, set_tran, 5
对于query string搜索方式的分词,默认情况下ES会使用它对应的 field 建立倒排索引时相同的分词器去进行分词和normalization,只有这样,才能实现正确的搜索。
一个分词不同导致结果不同的例子:https://github.com/zq99299/note-book/blob/master/docs/elasticsearch-core/search-engine/42-query-string-participle-mapping.md
查看具体分词结果:
GET /_analyze
{
"analyzer": "standard",
"text": "2017-01-01"
}
// 响应
{
"tokens": [
{
"token": "2017",
"start_offset": 0,
"end_offset": 4,
"type": "" ,
"position": 0
},
{
"token": "01",
"start_offset": 5,
"end_offset": 7,
"type": "" ,
"position": 1
},
{
"token": "01",
"start_offset": 8,
"end_offset": 10,
"type": "" ,
"position": 2
}
]
}
字符串排序问题
如果对一个 string field 进行排序,结果往往不准确,因为分词后是多个单词,再排序就不是我们想要的结果了;
通常解决方案是,将一个 string field 建立两次索引,一个分词,用来进行搜索;一个不分词,用来进行排序。
将title字段索引两次:
PUT /website
{
"mappings": {
"article": {
"properties": {
"title": {
"type": "text",
"fields": {
"raw": { // 不分词用来排序
"type": "string",
"index": "not_analyzed"
}
},
"fielddata": true //建立doc values正排索引
},
"content": {
"type": "text"
},
"post_date": {
"type": "date"
},
"author_id": {
"type": "long"
}
}
}
}
}
排序时用title.raw可以得到不分词的结果:
GET /website/article/_search
{
"query": {},
"sort": [
{
"title.raw": {
"order": "asc"
}
}
]
}
相关度评分算法
relevance score(相关度得分)算法:简单来说,就是计算出一个索引中的文本与搜索文本之间的关联匹配程度。
Elasticsearch使用的是 term frequency / inverse document frequency 算法,简称为 TF/IDF 算法.
TF/IDF 有以下三个组成:
-
Term frequency
搜索文本中的各个词条在 field 文本中出现了多少次,出现次数越多,就越相关。
例如:对下面两个文档搜索hello world
doc1:hello you, and world is very good doc2:hello, how are youdoc1中hello world出现两次,doc2中只有hello出现一次,doc1得分高。
-
Inverse document frequency
搜索文本中的各个词条在整个索引的所有文档中出现了多少次,出现的次数越多,就越不相关。
例如搜索请求:hello world ,hello在所有文档中中出现了两次多余world,得分较低:
doc1:world today is very good doc2:hello hello world is very good -
Field-length norm
field长度越长,相关度越弱
例如搜索请求:hello world
doc1:{"title": "hello article", "content": "babaaba1万个单词" } doc2:{"title": "my article", "content": "blablabala1万个单词 hi world" }hello world 在整个 index 中出现的次数是一样多的,doc1更相关,因为其content field更短。
query phase
- 搜索请求发送到某一个 coordinate node,构建一个 priority queue,长度以 paging 操作 from 和 size 为准,默认为 10;
- coordinate node 将请求转发到所有 shard,每个 shard 本地搜索,并构建一个本地的 priority queue;
- 各个 shard 将自己的 priority queue 返回给 coordinate node,并构建一个全局的 priority queue;
- coordinate node 构建完 priority queue 之后,就发送 mget 请求去所有 shard 上获取对应的 document;
- 各个 shard 将 document 返回给 coordinate node;
- coordinate node 将合并后的 document 结果返回给 client 客户端。
索引管理
创建索引
创建索引的语法:
PUT /my_index
{
"settings": { ... any settings ... },
"mappings": {
"type_one": { ... any mappings ... },
"type_two": { ... any mappings ... },
...
}
}
创建索引的示例
PUT /my_index
{
"settings": {
"number_of_shards": 1, // 设置shard数
"number_of_replicas": 0
},
"mappings": {
"my_type": {
"properties": {
"my_field": {
"type": "text" //默认是standard分词器
}
}
}
}
}
p.s. 修改索引时只能修改它的number_of_replicas属性
修改分词器
启用 english 停用词 token filter(去除a、an、the等单词)
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"es_std": {
"type": "standard",
"stopwords": "_english_"
}
}
}
}
}
同时还可以自定义分词器。
type的底层数据结构
type 是一个 index 中用来区分类似的数据的。
同一 index 下类似的数据,可能有不同的 fields,而且有不同的属性来控制索引建立、分词器。每个 field 的 value,在底层的 lucene 中建立索引的时候,全部是 opaque bytes (二进制)类型,不区分类型的。
Lucene 是没有 type 的概念的,在 document 中,实际上是将 type 作为一个 document 的 field 来存储,即 _type,ES也是通过_type来进行 type 的过滤和筛选。
一个 index 中的多个 type,实际上是放在一起存储的,因此一个 index 下,不能有多个 type 重名,因为那样是无法处理的。
例如:在 ecommerce(电子商务) index 下有电子商品和生鲜产品两个 type,只有一个保质期字段是不同名的
{
"ecommerce": {
"mappings": {
"elactronic_goods": {
"properties": {
"name": {
"type": "string",
},
"price": {
"type": "double"
},
"service_period": { //不同字段
"type": "string"
}
}
},
"fresh_goods": {
"properties": {
"name": {
"type": "string",
},
"price": {
"type": "double"
},
"eat_period": { //不同字段
"type": "string"
}
}
}
}
}
}
两条示例数据可能是这样:
{
"name": "geli kongtiao",
"price": 1999.0,
"service_period": "one year"
}
{
"name": "aozhou dalongxia",
"price": 199.0,
"eat_period": "one week"
}
但是在底层存在却是多了一个 _type 属性
{
"_type": "elactronic_goods",
"name": "geli kongtiao",
"price": 1999.0,
"service_period": "one year",
"eat_period": ""
}
{
"_type": "fresh_goods",
"name": "aozhou dalongxia",
"price": 199.0,
"service_period": "",
"eat_period": "one week"
}
在底层的存储如下:
{
"ecommerce": {
"mappings": {
"_type": {
"type": "string",
"index": "not_analyzed"
},
"name": {
"type": "string"
},
"price": {
"type": "double"
},
"service_period": {
"type": "string"
},
"eat_period": {
"type": "string"
}
}
}
}
如果两个 type 的 field 完全不同,放在一个 index 下,那么就每条数据都至少有一半的 field 在底层的 lucene 中是空值,会有严重的性能问题,因此不要将大多数字段不一致的 type 放到同一个 index 中。
定制dynamic mapping策略
dynamic mapping有如下三种可选:
- true:遇到陌生字段,就进行 dynamic mapping
- false:遇到陌生字段,就忽略
- strict:遇到陌生字段,就报错
创建一个策略实例:
PUT /my_index {
"mappings": {
"my_type": {
"dynamic": "strict",
"properties": {
"title": {
"type": "text"
},
"address": {
"type": "object",
"dynamic": "true"
}
}
}
}
}
- 对于 my_type 全局设置策略为遇到陌生字段就报错
- 对于 my_type.address 字段策略设置为自动 mapping
这时插入新文档:
PUT /my_index/my_type/1
{
"title": "my article",
"content": "this is my article",
"address": {
"province": "guangdong",
"city": "guangzhou"
}
}
报错,因为content字段校验未通过。
Elasticsearch的内核原理
倒排索引的结构
倒排索引不仅包括关键字所对应的Document ID,还包括其它的一些数据,基本上都是用来算相关度评分的:
- 包含这个关键词的 document list
- 包含这个关键词的所有 document 的数量:IDF(inverse document frequency)
- 这个关键词在每个 document 中出现的次数:TF(term frequency)
- 这个关键词在这个 document 中的次序
- 每个 document 的长度:length norm
- 包含这个关键词的所有 document 的平均长度
倒排索引不可变的好处:
- 不需要锁,提升并发能力,避免锁的问题
- 数据不变,一直保存在 os cache 中,只要 cache 内存足够
- filter cache 一直驻留在内存,因为数据不变
- 可以压缩,节省 CPU 和 IO 开销(因为不可变,所以可以压缩不存在修改)
Document写入的内核级原理
参考资料:https://learnku.com/articles/38468
三个概念:
- buffer:内存
- segment:lucene 底层的 index 是分为多个 segment 的,每个 segment 都会存放部分数据。当有新文档写入时,会生成新的 segment,查询时会同时查询所有的 segment,并且对结果汇总。Luncene 中有个文件,用来记录所有的 segment 的信息,叫做 Commit Point;
- commit:将 buffer 的数据写入到 segment 中

写入步骤(重点):
step1:数据写入buffer缓冲和translog日志文件(保证数据不丢);
step2:每隔一秒钟,buffer中的数据被写入新的segment file,并进入os cache,此时segment被打开并供search使用,不立即执行commit,实现近实时搜索;
数据写入OS cache,并被打开供搜索的过程,叫做refresh,默认是每隔1秒refresh一次。也就是说,每隔一秒就会将buffer中的数据写入一个新的index segment file,写入os cache中。因此是近实时的,数据写入到可以被搜索,默认是1秒;
step3:buffer被清空
step4:重复step1 ~ step3,新的segment不断添加,buffer不断被清空,而translog中的数据不断累加;
step5:当translog长度达到一定程度的时候,commit操作发生:
(5-1)buffer中的所有数据写入一个新的segment,并写入os cache,打开供使用;
(5-2)buffer被清空;
(5-3)一个commit ponit被写入磁盘,标明了所有的index segment;会有一个.del文件,标记了哪些segment中的哪些document被标记为deleted了;
(5-4)filesystem cache中的所有index segment file缓存数据,被fsync强行刷到磁盘上;
(5-5)现有的translog被清空,创建一个新的translog。
为了避免每个segment file过小,默认会在后台执行segment merge操作,在merge的时候,被标记为deleted的document也会被彻底物理删除;选择一些有相似大小的segment,merge成一个大的segment,将新的segment flush到磁盘上去;写一个新的commit point,包括了新的segment,并且排除旧的那些segment;将新的segment打开供搜索,再将旧的segment删除。
Document删除原理:
每次 commit point 时,会有一个 .del 文件,标记了哪些 segment 中的哪些 document 被标记为 deleted 了;
搜索的时候,会依次查询所有的 segment,从旧的到新的, 比如被修改过的 document,在旧的 segment 中,会标记为 deleted,在新的 segment 中会有其新的数据。