MLP-Mixer论文与代码阅读
MLP-Mixer
- 思路
- 网络结构
- 代码
- idea
没有采用convolution以及attention的网络结构,纯粹使用MLP作为主要架构。
不得不说,MLP->CNN->Transformer->MLP,CV是个循环还是螺旋上升? 还是看看神仙打架吧
思路
算了,我怎么知道大神咋想,还是看看具体框架吧
网络结构
整体结构图如图所示,感觉跟ViT很像

首先将输入图片拆分成 p a t c h e s patches patches,然后通过Per-patch Fully-connected将每个patch转换成feature embedding,然后送入N个Mixer Layer,最后通过Fully-connected进行分类。
Mixer 的输出基于输入的信息,因为全连接层,所以交换任意两个 token 会得到不同的结果,所以无需 position embedding。
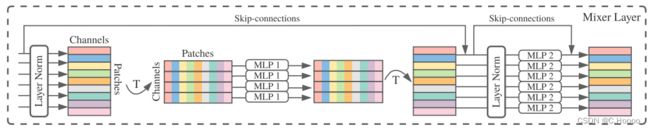
Mixer Layer是由channel-mixing MLP 和 token-mixing MLP 两类所构成。每个Mixer 结构由两个MLP blocks构成,其中红色框部分是token-mixing MLP,绿色框部分是channel-mixing MLP.
channel-mixing MLP是在不同通道之间进行交流;token-mixing MLP是在不同空间位置进行交流。这两种类型的layer是交替堆叠的,方便支持两个输入维度的交流,每个MLP由两层fully-connected和一个GELU构成。
代码
import torch
from torch import nn
from functools import partial
from einops.layers.torch import Rearrange, Reduce
class PreNormResidual(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.fn = fn
self.norm = nn.LayerNorm(dim)
def forward(self, x):
return self.fn(self.norm(x)) + x
def FeedForward(dim, expansion_factor = 4, dropout = 0., dense = nn.Linear):
return nn.Sequential(
dense(dim, dim * expansion_factor),
nn.GELU(),
nn.Dropout(dropout),
dense(dim * expansion_factor, dim),
nn.Dropout(dropout)
)
def MLPMixer(*, image_size, channels, patch_size, dim, depth, num_classes, expansion_factor = 4, dropout = 0.):
assert (image_size % patch_size) == 0, 'image must be divisible by patch size'
num_patches = (image_size // patch_size) ** 2
# 沿列方向的特征提炼,利用kernel_size为1的conv1d实现全连接
# 沿行方向的特征提炼,利用linear实现
chan_first, chan_last = partial(nn.Conv1d, kernel_size = 1), nn.Linear
return nn.Sequential(
# 图片拆成多个patches
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_size, p2 = patch_size),
# 用一个全连接网络对所有patch进行处理,提取出tokens
nn.Linear((patch_size ** 2) * channels, dim),
# 利用N个Mixer层,混合提炼特征信息
*[nn.Sequential(
PreNormResidual(dim, FeedForward(num_patches, expansion_factor, dropout, chan_first)),
PreNormResidual(dim, FeedForward(dim, expansion_factor, dropout, chan_last))
) for _ in range(depth)],
nn.LayerNorm(dim),
Reduce('b n c -> b c', 'mean'),
nn.Linear(dim, num_classes)
)
model = MLPMixer(
image_size = 256,
channels = 3,
patch_size = 32,
dim = 512,
depth = 12,
num_classes = 1000
)
# img = torch.randn(1, 3, 256, 256)
# pred = model(img)
- 一张图片被分成了9个patch,然后每一个patch经过embedding,变成了一个128的向量。那么原图经过embedding,最终得到的是9x128这样的一个矩阵。
- 这个矩阵经过LayerNorm,相当于是在128这个维度上进行归一化,然后矩阵经过转置,变成128x9的样式;
- 经过第一个全连接层 channel-mixing,对9这个patch维度进行计算;
- 然后再转置成 9x128,再进行layer norm;
- 然后token-mixing channels,在128这个spatial维度上进行计算;
- 再加上两个skip connection。
idea
…emmm…