软件架构风格 仓库风格
持久数据结构。
到目前为止,我们已经详细讨论了不变性。 特别是,我们介绍了如何用递归函数调用替换循环以进行迭代,同时避免重新分配任何变量。 从表面上看,该技术可能在内存方面效率极低,但我们已经看到,消除尾部调用可以消除对额外子例程调用的需求,从而避免了扩展调用栈,并使功能算法本质上相同到它们在计算机级别上的当务之急。
标量值太多了,但是诸如数组和字典之类的复杂数据结构又如何呢? 在功能语言中,它们也是不可变的。 因此,如果我们在Clojure中有一个列表:
(def a-list (list 1 2 3))然后通过向其中添加元素来构建新列表:
(def another-list (cons 0 a-list)) 那么我们现在有两个列表,一个等于(1 2 3) ,另一个等于(0 1 2 3) 。 这是否意味着为了以功能样式修改数据结构,我们必须制作原始文件的完整副本,以使其保持不变? 这似乎效率很低。
但是,有一些方法可以使数据结构看起来可修改,同时又保留了程序中仍保留对其引用的任何部分的原始完整性。 与可变的“临时”数据结构相比,此类数据结构被称为“持久”数据。 当可以修改结构的每个版本时,数据结构都是完全持久的,这就是我们将在此处讨论的类型。 当只能修改最新版本时,结构将部分保留。
完全堆叠。
堆栈是如何实现持久数据结构的一个很好的例子,因为它还显示了此技术的附带好处。 代码也变得越来越简单。 我们稍后会谈到。
因为我们在这里创建功能堆栈,所以我们的界面如下所示:
public interface Stack {
Stack pop();
Optional top();
Stack push(T top);
} 鉴于这是一个持久的数据结构,我们永远无法对其进行修改,因此在推送或弹出时,我们将获得一个新的Stack实例,该实例反映了我们推送或弹出的堆栈。 程序中持有对堆栈先前状态的引用的任何部分将继续看到该状态不变。
为了获得全新的堆栈,我们将提供静态工厂方法:
public interface Stack {
... // pop, top, push
static Stack create() {
return new EmptyStack();
}
} 为空堆栈创建一个特定的实现似乎是一个奇怪的设计选择,但是当我们这样做时,它会非常整洁。 这就是我前面提到的好处:
public class EmptyStack implements Stack {
@Override
public Stack pop() {
throw new IllegalStateException();
}
@Override
public Optional top() {
return Optional.empty();
}
@Override
public Stack push(T top) {
return new NonEmptyStack<>(top, this);
}
} 如您所见, top返回空,而pop抛出非法状态异常。 我认为在这种情况下抛出异常是合理的,因为考虑到堆栈的后进先出性质及其典型用法,任何试图弹出空堆栈的尝试都表明程序中可能是错误,而不是用户错误。
对于非空实现,如下所示:
public class NonEmptyStack implements Stack {
private final T top;
private final Stack popped;
public NonEmptyStack(T top, Stack popped) {
this.top = top;
this.popped = popped;
}
@Override
public Stack pop() {
return popped;
}
@Override
public Optional top() {
return Optional.of(top);
}
@Override
public Stack push(T top) {
return new NonEmptyStack<>(top, this);
}
} 值得注意的是,为空和非空情况选择单独的实现避免了任何条件逻辑的需要。 上面的代码中没有if语句。
在使用中,堆栈的行为如下:
-
Stack.create返回EmptyStack实例。 - 对其进行推送将返回一个
NonEmptyStack,其推送值为其顶部。 - 当将另一个值推入非空堆栈的顶部时,将创建另一个NonEmptyStack实例,并将新推入的值放在顶部:
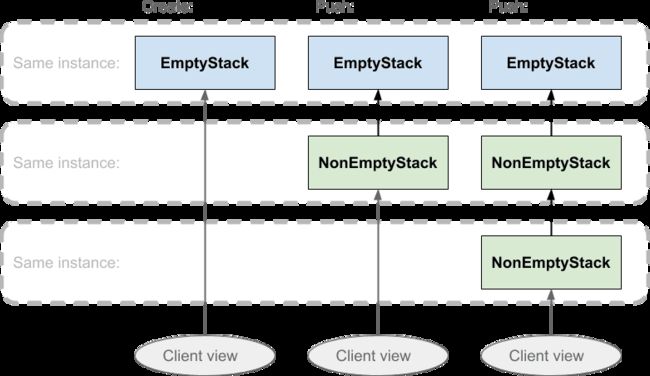
此处的时间轴从左到右,图底部的椭圆形代表客户端看到的堆栈“视图”。 虚线包围的区域表示其中的所有框都是相同的对象实例。 箭头的方向表明,每个NonEmptyStack实例都拥有对另一个堆栈实例(其父对象)的引用,该实例将为空或非空。 弹出堆栈时,将返回此父对象引用,这将使事情变得很聪明:
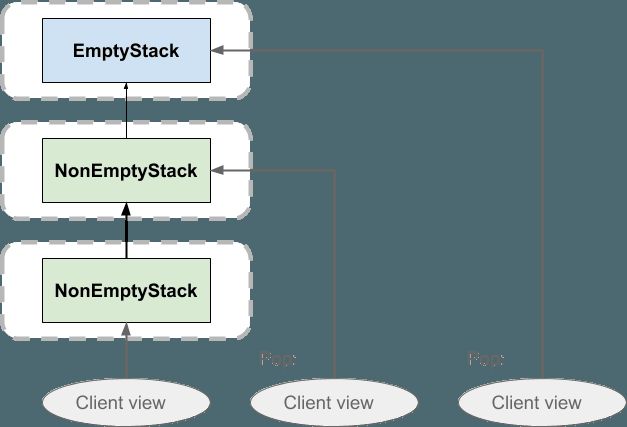
在弹出堆栈时,客户端只需将其视图移至先前推送的元素。 什么都不会被删除。 这意味着,如果有两个客户端具有相同的堆栈视图,则一个客户端可以弹出它而不会影响另一个客户端的堆栈视图。 推送同样如此:
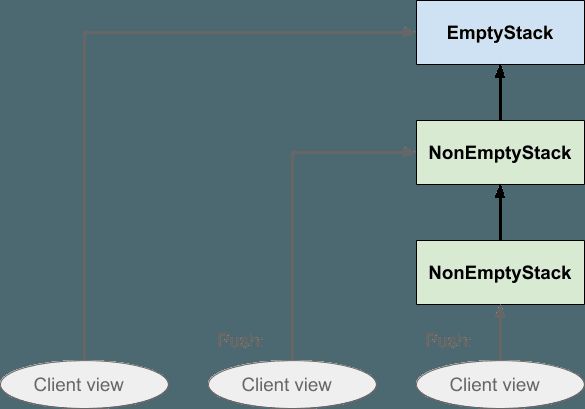
这与第一张图基本相同,除了我们省去了水平的虚线区域,而是明确指出了堆栈是单个数据结构而不是多个副本。 我们只是将每个Stack实例(无论是否为空)简单地表示为一个框。 最初,客户端看到一个空堆栈; 推送时,将创建一个非空的堆栈实例,该实例指向空堆栈,客户端将其视图移至新实例。 当客户端第二次推送时,将创建另一个非空堆栈实例,该实例指向先前的非空堆栈,并且客户端再次移动其视图。 堆栈通过push和pop操作的返回值告诉客户端下一步将其视图指向何处,但实际上是客户端在移动其视图。 堆栈不移动任何东西。
现在您可能会认为“客户改变了看法”意味着某些东西已经被突变了,的确是这样,但这只是一个持有对Stack实例的引用的变量。 在本系列的第2部分中,我们已经详细讨论了如何在不重新分配变量的情况下管理变化的标量值。
我们已经提到了程序的不同部分可能在堆栈结构上持有不同视图的可能性,因此现在让我们明确地想象这三个椭圆代表一个堆栈结构的三个不同客户视图。 客户端1正在查看新创建的堆栈,客户端2已将其压入一次,而客户端3已将其压入两次:
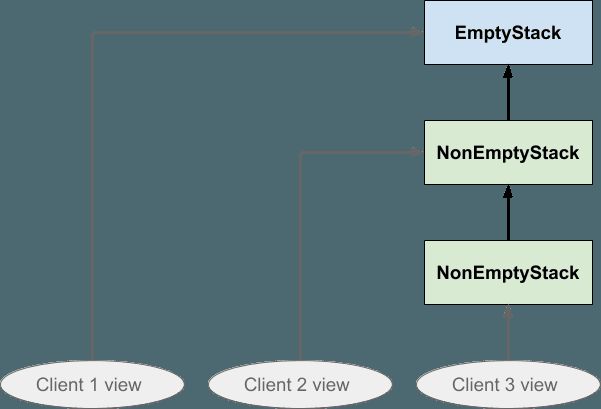
如果客户端2随后将某些内容压入堆栈,则效果将如下所示:
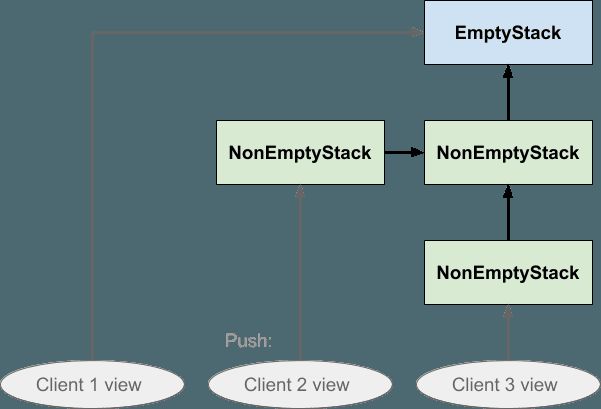
请注意,箭头的方向确保客户机1或客户机3均不受客户机2的影响:客户机3不能向后跟随箭头以查看刚刚推送的值,客户机1也不能。堆栈中的任何一个都不受影响:
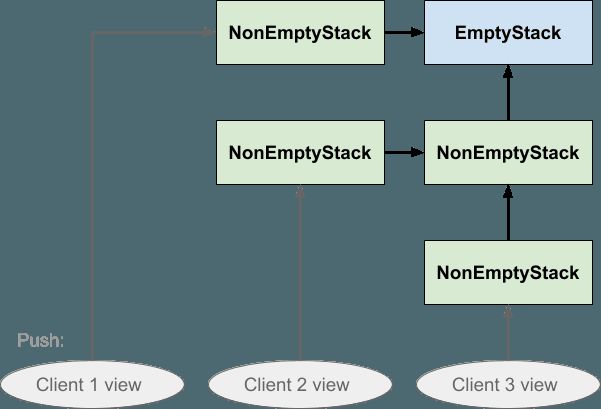
关于此数据结构要注意的另一件事是没有重复。 所有三个客户端共享同一个EmptyStack实例,并且客户端2和3还共享首先推送的NonEmptyStack。 可以分享一切都是共享的。 只要它们中的任何一个按下,就不会复制任何内容,并且弹出不会导致结构中的任何链接断开。
那么什么时候删除呢? 最终,我们必须回收资源,否则我们的程序可能会耗尽内存。 如果已弹出堆栈元素,而程序的任何部分都不再保留对其的引用,那么垃圾收集器将及时回收该元素。 确实,垃圾回收对于任何语言的函数式编程都是必不可少的功能。
Cons细胞,CAR和CDR。
您可能对这种堆栈结构很熟悉。 如果是这样,则有充分的理由。 这种结构称为链接列表 ,它是计算机科学中的基础数据结构。 通常,链表由如下图表示:
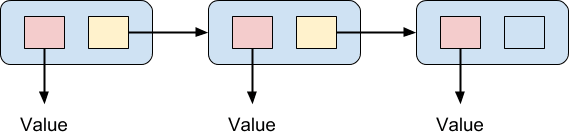
该列表是一个元素链,每个元素包含一对指针。 两个指针之一指向一个值。 另一个指向链中的下一个元素,但链中的最后一个元素不指向另一个元素。 通过这种方式,可以将价值链链接在一起。 在命令式编程中,通常为这种数据结构引用的一个优点是,在列表的中间插入一个值非常便宜:您要做的就是创建新元素,将其链接到以下元素,并将列表中的前一个元素重新指向新元素。 与数组不同,链表的元素不必在内存中是连续的,也不需要按顺序存储。 数组需要在插入的元素之后将所有元素改组,以便为其腾出空间,这确实是非常昂贵的操作。 另一方面,链表的随机访问性能很差,这是O(n)操作。 这是因为要找到第n个元素,必须遍历前面的(n – 1)个元素,这与数组中可以在常量O(1)时间内访问任何元素的数组不同。
链接列表是功能编程中必不可少的数据结构。 Lisp编程语言实际上是从它们中构建的。 在Lisp中,链表的单个元素称为cons单元格 :
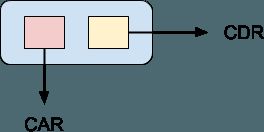
CAR指针指向cons单元的值,而CDR指针指向列表中的下一个元素。 CAR和CDR是古老的术语,不再常用,但是出于历史的考虑,我提到它们,也许您可能会碰到它们。 Lisp编程语言最初是在IBM 704大型机上实现的,实现者发现将cons单元存储在机器字中很方便。 指向单元格值的指针存储在单词的“地址”部分,而指向下一个单元格的指针存储在“减量”部分。 之所以方便,是因为当单元加载到寄存器中时,机器具有可用于直接访问这两个值的指令。 因此, 寄存器的地址部分的 内容和 寄存器 的减量部分的内容或简称CAR和CDR。
这种命名法使其成为语言。 Lisp将car用作返回列表的第一个元素的关键字,将cdr用作返回列表的其余部分的关键字。 如今,Clojure使用“ first和“ rest来代替它们,这更加透明:以1950年代的计算机体系结构命名基本语言操作几乎是不合适的。 其他语言可能是指他们为头部和尾部来代替。
创建一个新的cons单元称为cons-ing ,因此它意味着通过在另一个列表的开头添加一个元素来创建列表:
user => (cons 0 (list 1 2 3))
(0 1 2 3)正如我们在堆栈示例中看到的那样,将元素限制在列表上不会改变程序中仍在使用它的任何其他部分的列表。
二叉树。
没关系,但是如果我们想在列表中插入值或将其附加到末尾怎么办? 在这种情况下,必须进行复制; 我们将必须复制所有元素,直到列表中要插入新元素的位置为止。 在最坏的情况下-将元素追加到末尾-我们将被迫重复整个列表。
另一种方法是使用二叉树而不是链表。 这是一种有序的数据结构,其中每个元素都有零,一个或两个指针指向该结构中的其他元素:一个指向其值被认为低于当前元素的元素,另一个指向其值被视为元素的元素通过适合于树中保存的数据类型的任何比较来实现:

与链接列表相比,搜索二叉树的效率更高,但是为了获得最佳性能,必须对其进行平衡。 为了达到最佳效果,树的顶部元素必须是树中所有值的中间值,所有子树的顶部元素也必须相同。 在最坏的情况下,当二叉树的两侧完全偏斜时,它与链表变得无法区分。
上面的结构t包含按字母顺序排列的元素树:A,B,C,D,F,G,H。请注意,E缺失。 沿着箭头向下,左侧元素的值比右侧元素低,因此您可以轻松地遍历树以找到值,方法是依次将值与每个元素进行比较,并相应地沿树向下+向左或向下+向右。 因此,这样的数据结构非常适合搜索,并且通常使用称为B树的通用变体来为数据库表建立索引。
现在让我们想象一下,我们想将缺失的值E插入到这棵树中,这可能看起来像这样的代码:
t' = t.insert(E)和以前一样,我们希望该插入操作使原始树t保持不变,而同时我们希望尽可能多地重用t ,以最大程度地减少重复。 结果看起来像这样:
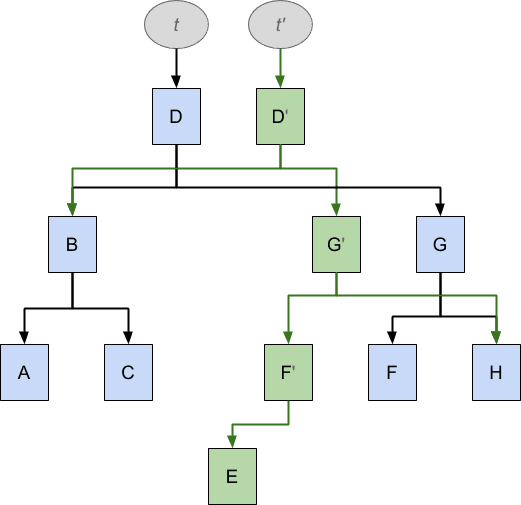
为了实现E的插入,必须复制D,G,F,而在两个数据结构之间共享A,B,C,但是结果是,沿着t的箭头,原始数据结构不变,在遵循t'箭头的同时,我们看到一个数据结构,该数据结构现在在适当位置还包括E。
一个方向。
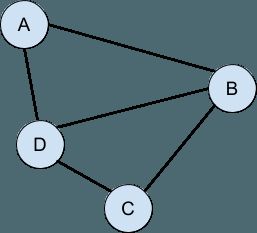
链表和二叉树有一个共同点:两个都是有向无环图的例子。 如果您以前从未听过这个词,请不要失望,因为这很简单。 图是它们之间具有联系的事物(节点,点,顶点等)的集合:
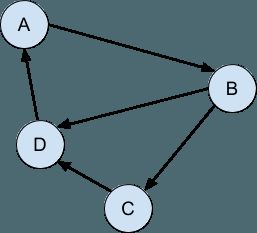
当连接仅以一种方式发生时,将定向图形:
最后,在没有周期的情况下该图是非循环的,也就是说,不可能从任何点跟随该图并在同一点返回:
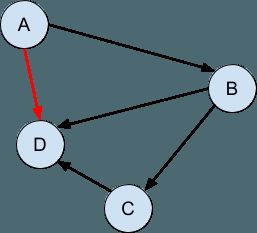
这些结构的有向非循环性质-连接只能沿一个方向进行,而不会循环返回-使得我们可以“附加”其他结构以给出修改或复制的外观,同时不会影响程序的任何仍在查看结构原始版本的部分。
不要惊慌!
我希望这里的解释是有道理的,但是如果没有的话,请不要太担心。 当您进行函数式编程时,不必实现此类数据结构–函数式语言和混合函数式语言具有不可变的数据结构,其中内置的数据结构工作正常,很可能比我们大多数人都能写的更好。
我之所以将其包含在本系列文章中,部分原因是出于技术兴趣-我想知道事情的运作方式-部分是为了减轻对效率的担忧。 不变的数据结构并不意味着在每次需要修改某些内容时都要批发整个结构。 存在更有效的方法来执行此操作。
下次。
到此为止,我们对功能编程的迷人主题进行了介绍。 我希望它会有用。 在下一篇文章中,我们将总结一些最终的想法。 我们将讨论函数风格的声明性,以及函数风格和面向对象的编程风格是否可以共存。 我们将简要地看一下我在本系列文章中并未真正涉及到的函数式编程的好处之一,即并发的简便性,并考虑函数式样式和效率问题之间的矛盾。
整个系列:
- 介绍
- 第一步
- 一流的函数I:Lambda函数和映射
- 一流的功能II:过滤,缩小和更多
- 高阶函数I:函数组成和Monad
- 高阶函数II:咖喱
- 懒惰评估
- 持久数据结构
翻译自: https://www.javacodegeeks.com/2018/12/functional-style-part-8.html
软件架构风格 仓库风格