Python数据分析师|Pandas之基础知识
版权声明:原创不易,本文禁止抄袭、转载,侵权必究!
目录
-
- 一、数据分析简介
- 二、数据分析简介
- 三、数据查看
- 四、知识总结
- 五、作者Info
一、数据分析简介
随着科技的发展,数据变得尤为重要,甚至有着“数据为王”,“得数据者得天下”这样的说法。爬虫工程师采集数据,数据分析/挖掘师分析/挖掘数据,机器学习工程师训练模型等,某某公司对这些岗位的需求还是比较迫切的,尤其是以AI为主的公司。本次教程以数据分析师岗位为目标,切中技术要点,用真实的数据集,实际工作场景来讲解
数据分析师获取到数据之后(爬虫,抽取数据库等),为了符合公司的业务逻辑需要对数据进行处理,包括加载、预处理、组合、分组、过滤、聚合(数据归一化)等,而pandas中的这些特性与方法都是基于DataFrame、Series这两种数据结构来实现的,再与其他的第三方库,比如numpy、scipy(比如傅立叶变换、统计学、线性代数、贝叶斯等)结合进行科学计算
安装Pandas
默认会安装最新版:
pip install pandas -i https://pypi.doubanio.com/simple
若想安装其他版本,可指定版本号,例如我们想安装版本1.2:
pip install pandas==1.2 -i https://pypi.doubanio.com/simple
Pandas中的DataFrame表示整个表格或矩形数据,比如csv、Excel,而Series是DataFrame的单个属性或单列。@可以把DataFrame看作由Series组成的字典或二维列表或集合,而把Series看作类似于Python中List类型或Numpy中的ndarray类型,这种解释非常有利于理解这两种数据结构,之所以这么说,是因为这两种数据结构的定义方式,后面会解释
就算主业不是数据分析师,掌握一些数据分析师的技能也能提高办公效率和优化代码性能,也能使代码变得更为简洁,简单举个例子,比如现在我们要将所有小字母以及所有大写字母数据插入到Excel文件中,我们希望小写字母和大写字母各占一列并且一一对应
首先我们采用xlwt库进行数据写入,代码如下:
import xlwt
from string import ascii_uppercase, ascii_lowercase
lower_case = ['lower_case'] + [s for s in ascii_lowercase]
upper_case = ['upper_case'] + [s for s in ascii_uppercase]
file = xlwt.Workbook(encoding='utf-8')
table = file.add_sheet('sheet1')
for i, s in enumerate(lower_case):
table.write(i, 0, s)
for j, s in enumerate(upper_case):
table.write(j, 1, s)
file.save('demo.xls')
打开demo.xls文件,查看数据:
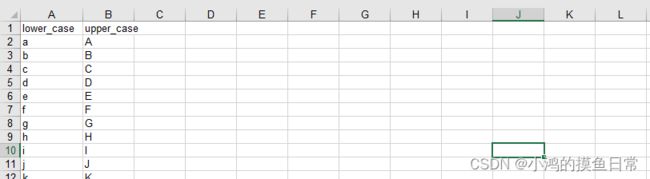
采用pandas进行写入,代码如下:
import pandas as pd
from string import ascii_uppercase, ascii_lowercase
df = pd.DataFrame(data={'lower_case': [s for s in ascii_lowercase], 'upper_case': [s for s in ascii_uppercase]}, columns=['lower_case', 'upper_case'])
df.to_excel('demo.xlsx', index=False)
打开demo.xlsx文件,查看数据:
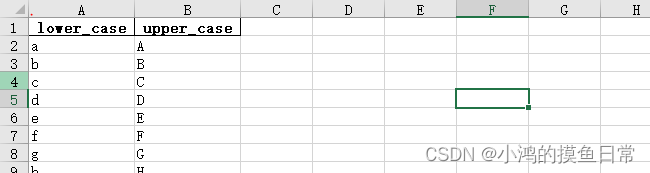
可以看到,去掉空格的话,采用xlwt需要写11行代码,而采用Pandas只需要4行代码,xlwt只支持后缀名为.xls的Excel文件,而Pandas既支持后缀名.xls也支持.xlsx的Excel文件,但有一点,如果用pandas保存为.xls的文件,pandas会有一个FutureWarning警告类型,如下:
df.to_excel('demo.xls', index=False)
警告如下:

大致的信息就是说:在未来的pandas版本中xlwt会被移除,提示用户安装openpyxl库来进行xlsx文件的写入,这个警告会以全局的方式建立起来
@可以在上面看到,在DataFrame定义时,我们通常会传入两个参数,data和columns,data是必须传入的,表示的是要写入的数据,我们定义的是一个字典,key为属性字段,value为列表,表示的是在每个属性字段中,一整列的数据,我们现在可以用一个二维列表来给data参数赋值,如下:
data = [
[s for s in ascii_lowercase],
[s for s in ascii_uppercase]
]
df = pd.DataFrame(data=data)
df.to_excel('demo1.xlsx', index=False, headers=False)
打开demo1.xlsx查看数据:

可以看到,当我们传入二维列表时,数据是可以写入的,但是列数据变为了行数据,这是因为当我们传入的不是字典而是二维列表时,数据是一行一行写入的;index=False表示不建立索引,默认是True,否则数据格式如下:
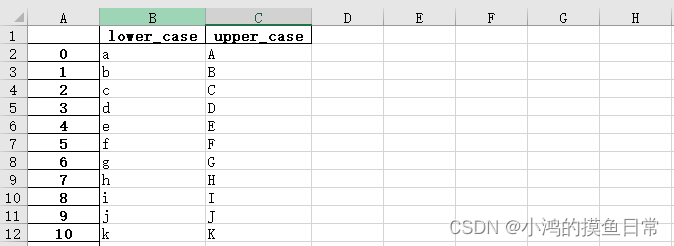
headers=False表示不建立数据头,默认是True,否则数据格式如下:

当然我们也可以把value变为Series类型,如下:
df = pd.DataFrame(data={'lower_case': pd.Series([s for s in ascii_lowercase]), 'upper_case': pd.Series([s for s in ascii_uppercase])}, columns=['lower_case', 'upper_case'])
也可以把value变为numpy.ndarray类型,需要导入numpy库,如下所示:
import numpy as np
df = pd.DataFrame(data={'lower_case': np.arange(1, 6), 'upper_case': np.arange(6, 11)})
这就解释了为什么我们可以把DataFrame看作由Series组成的字典或二维列表或集合,而把Series看作类似于Python中List类型或Numpy中的ndarray类型
如果由于某些业务逻辑,需要自定义索引,可以加index参数,传入一个索引列表,如下:
import numpy as np
df = pd.DataFrame(data={'lower_case': np.arange(1, 6), 'upper_case': np.arange(6, 11)}, index=['a', 'b', 'c', 'd', 'e'])
df.to_excel('demo2.xlsx')
打开demo2.xlsx查看数据:
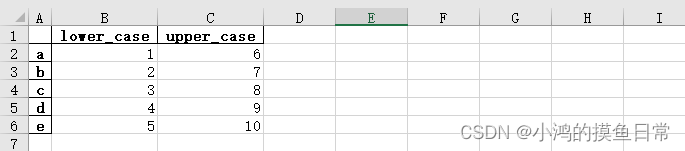
注意:当value的来源是numpy.ndarray类型时,索引列表的长度必须要和numpy.ndarray数组的长度相同,即:
len(np.arange(1, 6)) == len(['a', 'b', 'c', 'd', 'e'])
当然Series类型也可以自定义index参数,如下:
data = pd.Series(np.arange(1, 6), index=['a', 'b', 'c', 'd', 'e'])
#采用对比学习法可以帮助我们加强理解,在写相关的逻辑代码时会更加灵活;一个业务问题可能会有多种解决方法,我们希望采用的是更快,更简单,性能更好的方式去解决,大道至简
可能有些小伙伴之前没有使用过ascii_uppercase以及ascii_lowercase这两个模块,它能够导出所有小写字母和大写字母,返回类型是str类型,如下:
from string import ascii_uppercase, ascii_lowercase
print(type(ascii_lowercase), type(ascii_uppercase))
print(ascii_lowercase.__class__.__name__, ascii_uppercase.__class__.__name__)
控制台输出:

查看数据类型通常有二种方式,一是使用Python的全局函数type(),会返回完整数据类型(比如
本次教程使用Python3.9.3,pandas1.5.3(最新版),Python3.11和3.10目前仍在bugfix中,所以我们尽量选择Python3.9或3.8,而IDE选择自己喜欢的就行,Pycharm/Anaconda/Sublime Text/VS Code等都行,不过在学习的时候尽量选择没有代码提示的IDE,更有助于我们编写代码,实际开发时可以选择有代码提示的IDE,有些大厂在面试时会要求面试者使用没有代码提示的IDE
这里推荐一个工具IPython,它是一个Python交互式shell工具,可以帮助我们进行代码调试和实验,查看历史命令,代码运行性能等,使用pip直接安装即可:
pip install ipython -i https://pypi.doubanio.com/simple
然后在控制台输入ipython即可使用:

比如我们先导入库numpy,再定义变量a,输入命令%hist,这个命令会查看历史的输入,如下:

退出直接输入exit即可
更多用法和命令可查看官网:
https://ipython.org
数据分析过程中,最重要的是规划好分析的步骤,不要被编程细节所困
二、数据分析简介
本次教程数据集来源于实习僧网站(仅供学习与研究):
https:www.shixiseng.com
关于如何爬取实习僧网站Python实习数据请看爬虫实战篇:
Web爬虫|入门实战之实习僧(编码反爬)
数据集格式如下:
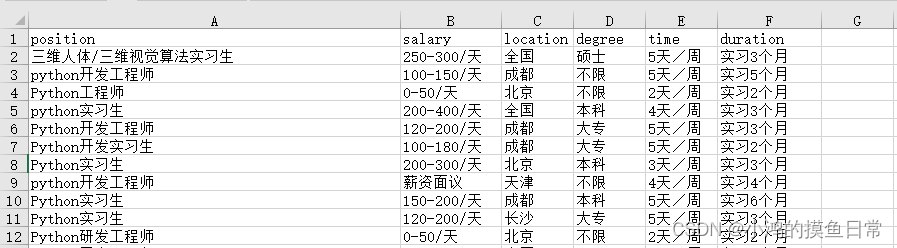
#使用Pandas的read_excel()方法加载数据集:
import pandas as pd
filename = '2021_Python_shixi_data.xlsx'
df = pd.read_excel(filename)
使用type()函数查看df的类型:
print(type(df))
类型如下:
<class 'pandas.core.frame.DataFrame'>
#使用head()方法,默认只显示前5条数据:
print(df.head())
控制台输出:
position salary location degree time duration
0 三维人体/三维视觉算法实习生 250-300/天 全国 硕士 5天/周 实习3个月
1 python开发工程师 100-150/天 成都 不限 5天/周 实习5个月
2 Python工程师 0-50/天 北京 不限 2天/周 实习2个月
3 python实习生 200-400/天 全国 本科 4天/周 实习3个月
4 Python开发工程师 120-200/天 成都 大专 5天/周 实习3个月
如果我们想查看更多数据,可由参数n来控制,比如我们想要查看前面10条数据:
print(df.head(n=10))
控制台输出:
position salary location degree time duration
0 三维人体/三维视觉算法实习生 250-300/天 全国 硕士 5天/周 实习3个月
1 python开发工程师 100-150/天 成都 不限 5天/周 实习5个月
2 Python工程师 0-50/天 北京 不限 2天/周 实习2个月
3 python实习生 200-400/天 全国 本科 4天/周 实习3个月
4 Python开发工程师 120-200/天 成都 大专 5天/周 实习3个月
5 Python开发实习生 100-180/天 成都 大专 5天/周 实习2个月
6 Python实习生 200-300/天 北京 本科 3天/周 实习3个月
7 python开发工程师 薪资面议 天津 不限 4天/周 实习4个月
8 Python实习生 150-200/天 成都 本科 5天/周 实习6个月
9 Python实习生 120-200/天 长沙 大专 5天/周 实习3个月
#而使用tail()方法可查看最后5条数据:
print(df.tail())
控制台输出:
position salary location degree time duration
234 清华大学机器学习课题组实习生 薪资面议 深圳 本科 5天/周 实习12个月
235 爬虫实习生 120-150/天 南京 不限 5天/周 实习3个月
236 数据采集实习生 100-150/天 北京 不限 4天/周 实习6个月
237 少儿编程讲师 400-500/天 北京 本科 6天/周 实习12个月
238 信息安全工程师 150-300/天 广州 大专 5天/周 实习8个月
同样的,我们想要查看最后10条数据,使用参数n来控制:
print(df.tail(n=10))
控制台输出:
position salary location degree time duration
229 TensorRT深度学习推理 150-200/天 上海 不限 3天/周 实习4个月
230 云计算技术培训工程师 150-200/天 杭州 硕士 5天/周 实习3个月
231 后端开发实习生 200-200/天 上海 本科 3天/周 实习3个月
232 BMW R&D Intern - Data analysis 120-150/天 北京 本科 4天/周 实习6个月
233 后端开发—远程办公实习 200-300/天 全国 本科 3天/周 实习3个月
234 清华大学机器学习课题组实习生 薪资面议 深圳 本科 5天/周 实习12个月
235 爬虫实习生 120-150/天 南京 不限 5天/周 实习3个月
236 数据采集实习生 100-150/天 北京 不限 4天/周 实习6个月
237 少儿编程讲师 400-500/天 北京 本科 6天/周 实习12个月
238 信息安全工程师 150-300/天 广州 大专 5天/周 实习8个月
其实不用给参数n赋值,直接写数字也可:
print(df.head(10))
print(df.tail(10))
三、数据查看
DataFrame属性查看
#使用shape属性查看DataFrame的行数和列数:
print(df.shape)
控制台输出:
(239, 6)
shape属性会返回一个元组
#使用columns属性查看列名:
print(df.index)
控制台输出:
Index([‘position’, ‘salary’, ‘location’, ‘degree’, ‘time’, ‘duration’], dtype=‘object’)
#使用dtypes属性查看每列的数据类型:
position object
salary object
location object
degree object
time object
duration object
dtype: object
注意:Pandas中的object类型相当于Python中的str类型
DataFrame子集查看
#获取单个列子集
比如我们想要获取position这个属性的整列数据:
position = df['position']
print(position.head())
查看前5行数据如下:
0 三维人体/三维视觉算法实习生
1 python开发工程师
2 Python工程师
3 python实习生
4 Python开发工程师
Name: position, dtype: object
查看单列子集的类型:
print(type(df['position']))
控制台输出:
<class 'pandas.core.series.Series'>
#获取多列子集
获取指定属性的多列子集,需要传入一个列表,也就是嵌套了两个方括号:
position = df[['position', 'salary', 'location']]
print(position.head())
同样查看前5行数据如下:
position salary location
0 三维人体/三维视觉算法实习生 250-300/天 全国
1 python开发工程师 100-150/天 成都
2 Python工程师 0-50/天 北京
3 python实习生 200-400/天 全国
4 Python开发工程师 120-200/天 成都
查看多列子集的类型:
print(type(df[['position', 'salary', 'location']]))
控制台输出:
<class 'pandas.core.frame.DataFrame'>
#获取单行子集
使用DataFrame的loc(索引标签)属性获取行数据,比如现在我们要获取第一行数据:
print(df.loc[0])
数据如下:
position 三维人体/三维视觉算法实习生
salary 250-300/天
location 全国
degree 硕士
time 5天/周
duration 实习3个月
Name: 0, dtype: object
如果我们要获取最后一行数据:
print(df.loc[df.shape[0] - 1])
数据如下:
position 信息安全工程师
salary 150-300/天
location 广州
degree 大专
time 5天/周
duration 实习8个月
Name: 238, dtype: object
也可以使用全局函数len()来获取DataFrame的总长度,然后减1,以此来获取最后一行数据:
print(df.loc[len(df) - 1])
查看第一行数据的类型:
print(type(df.loc[0]))
控制台输出:
<class 'pandas.core.series.Series'>
#获取多行子集
与获取多列子集一样,也需要使用两个方括号嵌套,比如我们想要获取第1行、第5行、第15行数据:
print(df.loc[[0, 4, 14]])
数据如下:
position salary location degree time duration
0 三维人体/三维视觉算法实习生 250-300/天 全国 硕士 5天/周 实习3个月
4 Python开发工程师 120-200/天 成都 大专 5天/周 实习3个月
14 Python开发实习生 250-500/天 上海 本科 5天/周 实习6个月
查看多行数据的类型:
print(type(df.loc[[0, 4, 14]]))
控制台输出:
<class 'pandas.core.frame.DataFrame'>
可见子集的类型取决于我们获取数据的字段属性和数量
我们也可以使用DataFrame的iloc(索引行号)属性获取行数据,请注意,索引标签包含索引行号,却不限于行号,比如之前我们在定义DataFrame时可以通过赋值index属性来自定义索引标签,之前所定义的索引标签就是字母符号,使用方式和上面是类似的:
print(df.iloc[0])
print(df.iloc[len(df) - 1])
print(df.iloc[[0, 4, 14]])
#使用混合方式获取子集
更进一步的数据获取可以选择混合方式,语法为df.loc[[row], [column]]或者df.iloc[[row], [column]]
#使用loc属性混合方式获取子集
比如我们想要获取python实习数据的实习岗位和酬劳字段的第1行、第5行、第15行数据:
print(df.loc[[0, 4, 14], ['position', 'salary']])
数据如下:
position salary
0 三维人体/三维视觉算法实习生 250-300/天
4 Python开发工程师 120-200/天
14 Python开发实习生 250-500/天
现在不同调用type()函数,我们也能知道这是一个DataFrame类型,因为有3条数据且还是两个字段属性
既然传入的是一个列表,那么我们可以使用切片语法或者range()函数来进行范围索引,比如我们想要获取前6行数据,并且希望每隔2个位置进行选取:
print(df.loc[:6:2, ['position', 'salary']])
数据如下:
position salary
0 三维人体/三维视觉算法实习生 250-300/天
2 Python工程师 0-50/天
4 Python开发工程师 120-200/天
6 Python实习生 200-300/天
如果改用range()函数(会返回一个生成器),代码如下:
print(df.loc[list(range(0, 6, 2)), ['position', 'salary']])
数据如下:
position salary
0 三维人体/三维视觉算法实习生 250-300/天
2 Python工程师 0-50/天
4 Python开发工程师 120-200/天
注意:此时不包含第6行数据,是因为使用切片语法进行跳跃选取时包含指定的最后索引,前提是最后索引位置要达到跳跃的整数倍,即:
last_index % skip == 0
而使用range()函数进行跳跃选取时是不包含最后索引位置的
那么现在有一个问题,就是loc的混合和iloc的混合有什么不同的?
假设我们使用loc[:8:2, [0, 1]]的方式能获取到相同数据吗?试验一下:
print(df.loc[:8:2, [0, 1]])
报错如下:
KeyError: "None of [Int64Index([0, 1], dtype=‘int64’)] are in the [columns]
很明显,当我们使用loc混合方式时,传入的字段属性列表只能是str(字符串)类型的
#使用iloc属性混合方式获取子集
想要使用iloc属性混合方式也可以使用切片语法及range()函数,比如获取所有实习岗位和酬劳这两个字段的行数据,如下:
print(df.iloc[:, [0, 1]])
数据如下:
position salary
0 三维人体/三维视觉算法实习生 250-300/天
1 python开发工程师 100-150/天
2 Python工程师 0-50/天
3 python实习生 200-400/天
4 Python开发工程师 120-200/天
.. ... ...
234 清华大学机器学习课题组实习生 薪资面议
235 爬虫实习生 120-150/天
236 数据采集实习生 100-150/天
237 少儿编程讲师 400-500/天
238 信息安全工程师 150-300/天
[239 rows x 2 columns]
相同的问题,假设我们使用iloc[:, [‘position’, ‘salary’]]的方式能获取到相同数据吗?试验一下:
print(df.iloc[:, ['position', 'salary']])
还是会报错:
IndexError: .iloc requires numeric indexers, got [‘position’ ‘salary’]
意思就是说使用.iloc混合方式时需要使用数值索引,也就是整型索引
四、知识总结
本篇教程简单介绍了数据分析师的就业前景,在这个以数据为王的时代还是比较受欢迎的,之后介绍了如何使用pandas加载Excel文件数据,查看DataFrame的属性,行数据,列数据,根据指定索引查看范围数据,使用混合方式查看数据,pandas还可以读取与存储更多类型的数据,会在后面的教程中介绍
采用pandas来处理数据,目的是为了实现自动化流程和代码复现性,避免执行重复性的任务,而借助脚本语言我们可以实现
五、作者Info
Author:小鸿的摸鱼日常,Goal:让编程更有趣!
专注于算法、爬虫,网站,游戏开发,数据分析、自然语言处理,AI等,期待你的关注,让我们一起成长、一起Coding!
版权说明:本文禁止抄袭、转载 ,侵权必究!