北航计算机组成原理课程设计-2021秋 PreProject-MIPS-MIPS 指令集架构
北航计算机学院-计算机组成原理课程设计-2021秋
PreProject-MIPS
MIPS 指令集架构
本系列所有博客,知识讲解、习题以及答案均由北航计算机学院计算机组成原理课程组创作,解析部分由笔者创作,如有侵权联系删除。
从本节开始,课程组给出的教程中增添了很多视频讲解。为了避免侵权,本系列博客将不会搬运课程组的视频讲解,而对于文字讲解也会相应地加以调整,重点在于根据笔者自己的理解给出习题的解析。因此带来的讲解不到位敬请见谅。
认识 MIPS 汇编指令
初识指令
在真正开始掌握 MIPS 汇编指令之前,我们需要先知道,什么是「指令」。指令,即是由处理器指令集架构(Instruction Set Architecture,可以理解为计算机体系结构中对程序相关的部分所做的定义)定义的处理器的独立操作,这个操作一般是运算、存储、读取等。一个指令在 CPU 中真正的存在形式是高低电平,也可以理解为由 01 序列组成的机器码。但因为机器码人类难以阅读和理解,所以指令一般由汇编语言来表示,也就是我们俗称的汇编指令。从这个角度上来说,汇编指令只是指令的一种表示形式而已,其实质是一样的。
一条指令的功能较为单一,一般不具有复杂的逻辑。例如「将某两个寄存器的值相加并存入另一个寄存器」,或者是「如果某个寄存器的值满足某个条件则跳转至某条指令」。不过,虽然这些指令很简单,但最终,我们可以用它们组合出丰富多彩、功能强大的程序。
那么,指令究竟长什么样呢?让我们来一起看一小段汇编程序:
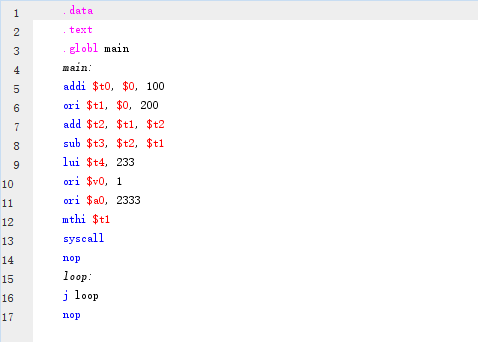
其中第 5 行的 addi $t0, $0, 100 就是一条指令,它的含义为“将 $0 寄存器的值加上 100,并将结果存入 $t0 寄存器”。
需要注意的是,虽然其主要由指令构成,但汇编语言并非全部由指令组成。上面的代码中,第 5-14、16-17 行为严格意义上的指令,其余有标签、伪指令等。相信看了上面一段代码样例,你已经找出了指令的规律,下面我们就来详细地进行解读。
指令的格式
在 MIPS 汇编语言中,指令一般由一个指令名作为开头,后跟该指令的操作数,中间由空格或逗号隔开。指令的操作数的个数一般为 0-3 个,每一个指令都有其固定操作数个数。一般来说,指令的格式如下:
指令名 操作数 1, 操作数 2, 操作数 3
不过,也有如下的指令格式,一般用于存取类指令:
指令名 操作数 1, 操作数 3(操作数 2)
所谓操作数,即指令操作所作用的实体,可以是寄存器、立即数或标签,每个指令都有其固定的对操作数形式的要求。而标签最终会由汇编器转换为立即数。所谓立即数,即在指令中设定好的常数,可以直接参与运算,一般长度为 16 位二进制。而标签,用于使程序更简单清晰。标签用于表示一个地址,以供指令来引用。一般用于表示一个数据存取的地址(类似于数组名)、或者一个程序跳转的地址(类似于函数名,或者 C 语言中 goto 的跳转目标)。在 MIPS 汇编中(以及其他大部分汇编语言中),标签用如下的方式写出:
name:
其中的「name」代表这个标签的名称,可以自行取名。
常见的指令格式样例:
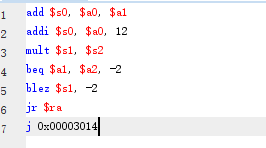
当然,前面说过,可以使用标签来代替某个地址,因此也可以以如下方式书写:
![]()
这里的 loop 就是一个标签,他所代表的是一段代码的起始地址。在进行汇编时,汇编器会自动把标签转换成我们所需要的立即数,这样就不用我们自己去计算这些地址偏移量,简化了编程难度。
注意:在 MARS 中,跳转指令只能使用标签来进行跳转,不能使用立即数!
由此可以看出,在 MIPS 汇编语言中,操作数的形式并非绝对严格固定的,而是具有一定的灵活度。虽然在 MIPS 标准指令集中,一条机器码指令的格式是固定的,但汇编器可以将多种形式的汇编指令转换为同样意思的机器码指令。因此,许多指令有比标准写法简单的写法。这部分内容会在后面进行讲解(详见「扩展指令」),或者也可以自行查阅 MARS 的帮助文档。
为了更好的理解汇编指令,下一小节将详细讲解 MIPS 机器码指令,这一汇编指令转换后的形式。
PS:在本教程中,没有特殊说明的情况下都不需要考虑到延迟槽的存在。
汇编入门测试
汇编入门测试1
汇编语言是_____?
A. 机器语言
B. 低级语言
C. 高级语言
D. C语言
答案:B
汇编入门测试2
指令ori $t0,$0,100具有_____个操作数
答案:3
汇编入门测试3
请判断下列说法是否正确:
1 每一条指令至少有两个操作数?
2 每一条指令至少需要使用一个寄存器?(32个基础寄存器)
答案:错;错
汇编入门测试4
在mips汇编语言中,标签作为指令的操作数,最终会由汇编器转化为:
A. 寄存器
B. 立即数
C. 指令
答案:B
机器码指令
认识机器码
大家都知道,计算机只能理解二进制形式的数据。而我们前面所说的汇编语言,最终就会转化为机器语言——也就是机器码指令, CPU 可以直接识别这种机器语言,从而去完成相应的操作。在我们学习的 MIPS 汇编中,所有的指令长度均为 32 位,即 4 字节,或者说 1 字。同时,从硬件的角度来讲,每条指令的执行周期大多为 1 个 CPU 周期,这在深入学习之后可以更好地理解,这里只是阐述一个概念。因此机器码就是 CPU 最基本的一种操作,也是原子操作,不可被打断。
所有指令长度均相同,这是精简指令集(RISC,Reduced Instruction Set Computing)的特征,这种指令集包括 MIPS 和手机中常用的 ARM 等;与之相对的是复杂指令集(CISC,Complex Instruction Set Computing),包括 PC 中常用的 x86 架构,这种指令集的特点是指令数目多、指令长度并不完全相同。
一段汇编语言可以转换为一段机器码,例如下面这段汇编指令:
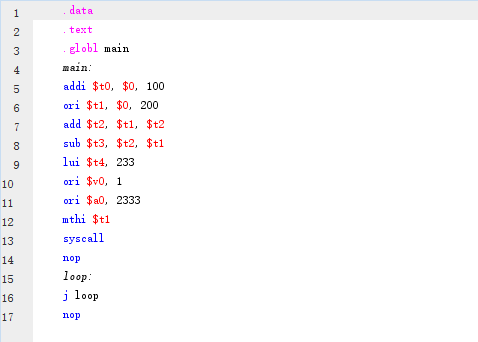
其转换后的结果为(16 进制):
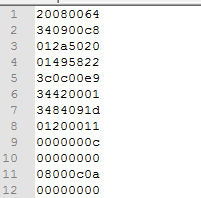
机器码的指令格式
32 位的机器码需要一定的格式才能被理解。一般来说,在 MIPS 指令集中,指令分为三种格式:R 型、I 型和 J 型。
- R 型指令
R 型指令的操作数最多,一般用于运算指令。例如 add、sub、sll 等。其格式如下(左侧为高位,右侧为低位):

- I 型指令
I 型指令的特点是有 16 位的立即数(偏移也是一样的道理)。因此,I 型指令一般用于 addi、subi、ori 等与立即数相运算的指令(这里需要注意:在写汇编语言的时候,需要使用负号来标记负数,而不要和机器码一样认为首位的 1 就代表负数),或 beq、bgtz 等比较跳转指令,因为它们要让两个寄存器的值相比并让 PC 偏移 offset 这么多,刚好利用了全部的字段。还有存取指令,例如 sw、lw,它们在使用时需要对地址指定一个偏移值,也会用到立即数字段。
![]()
- J 型指令
J 型指令很少,常见的为 j 和 jal。他们需要直接跳转至某个地址,而非利用当前的 PC 值加上偏移量计算出新的地址,因此需要的位数较多。
![]()
需要注意的是,严格来说,并非所有的指令都严格遵守上面三种格式,有的如 eret、syscall 指令一样没有操作数;有的如 jalr 指令一样某些字段被固定为某个值。不过,就大部分指令而言,都可按上面三种格式进行解释,某些字段被固定也可以按照格式来识别为 R、I、J 中的一种,因此这三种格式要着重理解。
解读:
-
op:也称 opcode、操作码,用于标识指令的功能。CPU 需要通过这个字段来识别这是一条什么指令。不过,由于 op 只有 6 位,不足以表示所有的 MIPS 指令,因此在 R 型指令中,有 func 字段来辅助它的功能。
-
func: 用于辅助 op 来识别指令。
-
s、rt、rd: 通用寄存器的代号,并不特指某一寄存器。范围是
$0~$31,用机器码表示就是 00000~11111。 -
shamt:移位值,用于移位指令。
-
offset:地址偏移量。
-
immediate:立即数。
-
address:跳转目标地址,用于跳转指令。
结合手册读懂指令
下面我们结合文档《MIPS-C 指令集》来讲解如何读懂一条机器码指令的功能与格式。下表为 add 指令的指令详解:

- 编码:二进制指令各字段的值和功能。这里可以看出,
add指令的 opcode 为 000000;其后跟随着 rs、rt、rd 三个指示寄存器的字段;之后为全 0 的 shamt 字段,最后的 func 字段值为 100000。 - 格式:汇编指令的书写格式。其中的 rd、rs 和 rt 在真正编写时要替换为具体的寄存器。
- 描述:指令的功能。GPR 表示寄存器堆,在此和中括号括起来的寄存器编号结合起来可以理解为某个寄存器。例如 GPR[rd] 表示编号为 rd 的寄存器。
add指令的描述表示该指令的功能为将编号为 rs 和 rt 的寄存器的值相加,存入编号为 rd 的寄存器中。 - 操作:指令的具体执行过程及细节。 \tt{GPR[rs]31||GPR[rs]}GPR[rs]31∣∣GPR[rs] 表示将 rs 号寄存器的 bit31 和 rs 号寄存器原本的值进行拼接,组合成一个 33 位的数值。进一步地,\tt{temp ← (GPR[rs]31||GPR[rs])+(GPR[rt]31||GPR[rt])}temp←(GPR[rs]31∣∣GPR[rs])+(GPR[rt]31∣∣GPR[rt]) 表示将这两个 33 位的数值相加,存入一个临时变量 temp 中。接着,判断这个临时变量的 bit32 和 bit31 进行比较,若不相等,则说明出现了溢出,那么就会引发整数溢出异常(关于异常的知识会在以后学到);如果没有发生溢出,则会将 temp 的低 32 位存入 rd 号寄存器中,作为最终的结果。
- 示例:汇编指令书写样例。这里的 rs、rt 和 rd 已经替换为了具体的寄存器。
- 其他:补充说明。这里提到如果不考虑溢出,则
add与另一个指令:addu等价,这便是指出了add的特性:add会检验计算的结果是否会溢出。在一些C语言编译器中,加法的计算并不会引发异常。例如计算 \tt{2000000000+2000000000}2000000000+2000000000,得到的结果 -2094967296,说明计算出现了溢出,但并未引发异常。这说明该编译器使用的是addu。
下图更加直观地表示了汇编指令转变为机器码指令的过程:
事实上在 CPU 中,机器码还要按照同样的格式进行解码,并使 CPU 执行相应的功能。相关的知识会在今后学到。
上面的 add 指令中,所有的操作数形式均为寄存器,那么当操作数为标签时会怎样呢?事实上,汇编器会将标签翻译为一个立即数,再转化为机器码,下面以另一个指令:beq 为例子再进行一次详解。

其所在的程序如下:

操作详解:\tt{sign_extend()}sign_extend() 代表符号扩展至 32 位,而符号扩展是与非符号扩展相对的,其扩展结果的正负会与原数相同,一般用于有符号数。其符号扩展的方法是在数字之前补若干个 0 或者 1 。这个取决于需要被符号扩展的数原本的正负性。如果原来的数为负数,那么符号扩展将在其前面增加若干个 1;如果原来的数为非负数,那么符号扩展将在前面增加若干个 0。具体增加 0 或者 1 的多少,根据具体的语境而定。\tt{offset||0^2}offset∣∣02 代表 offset 后面拼接 2 位的 0。例如 offset 为 1010,则拼接后的结果为 101000。
可以看到,offset 是一个数值,而 label 是一个标签,因此需要将 label 转化具体的数值。根据代码,beq 跳转之后的指令应为第3行:add $s1, $s2, $s3。这一条指令是 beq 的上一条指令,也就是说这两条指令的地址差 4。而根据手册,beq 跳转的结果为 \tt{PC+4+sign_extend(offset||0^2)}PC+4+sign_extend(offset∣∣02),也就是说 \tt{4+sign_extend(offset||0^2)=-4}4+sign_extend(offset∣∣02)=−4。可以计算出,offset 为 0xfffe(注意这是一个 16 位的负数)。因此,最终 beq $0, $s1,label 的转化结果为 0x1011fffe。
除了上述的运算指令和跳转指令之外,MIPS 汇编中常用的指令还有存取指令,其中存、取的指令结构基本相同。下面以最基本的 lw 指令为例进行解读。

-
编码:
lw是条 I 型指令,op=100011,base 字段其实就是一般I型指令格式中的 rs 寄存器字段。 -
**格式:**存取指令的格式与一般 I 型指令不同:要把基地址 base 用括号括起来,外面是偏移量 offset。
-
**操作:**首先将偏移量 offset 符号扩展为 32 位后与 base 寄存器中的值相加,求出具体的内存地址。然后将该地址中数据提取出来赋给 rt 寄存器。这里的 memory[Addr] 指的是内存中以 Addr 为首地址的 4 字节内存中存储的数据。
-
**约束:**对于存取指令,最终计算出来的地址 Addr 一般都是有强制约束的,比如
lw指令的 Addr 就必须是 4 的倍数,因为 1 个字 = 4 个字节;lh(取半字)指令的 Addr 就必须是 2 的倍数,因为 1 个半字 = 2 个字节。这样做可以防止你对内存数据随意进行操作。
MIPS指令手册解读测试
MIPS指令手册解读测试1
结合MIPS指令手册,下列指令操作过程中,需要在立即数后面拼接两位的0的是:
A. beq $s2,$s3,4
B. lw $s2,4($s3)
C. ori $s2,$s3,4
D. addi $s2,$s3,4
E. sltiu $s1, $s2, 0x8888
答案:A
MIPS指令手册解读测试2
结合MIPS指令手册,下列指令操作过程中,需要将立即数符号扩展的是:
A. beq $s2,$s3,4
B. lw $s2,4($s3)
C. ori $s2,$s3,4
D. addi $s2,$s3,4
E. sltiu $s1, $s2, 0x8888
答案:ABDE
MIPS指令手册解读测试3
结合MIPS指令手册,下列指令操作过程中,需要将立即数无符号扩展的是:
A. beq $s2,$s3,4
B. lw $s2,4($s3)
C. ori $s2,$s3,4
D. addi $s2,$s3,4
E. sltiu $s1, $s2, 0x8888
答案:C
指令分类测试1
下列指令中属于R型指令的是:
A. sub $s2,$s2,$s2
B. ori $s0,$s0,0xffff
C. j 0x00100000
D. jalr $s0,$a0
E. lw $s0,4($t0)
答案:AD
指令分类测试2
下列指令属于I型指令的是:
A. sub $s2,$s2,$s2
B. ori $s0,$s0,0xffff
C. j 0x00100000
D. jalr $s0,$a0
E. lw $s0,4($t0)
答案:BE
指令分类测试3
下列指令属于J型指令的是:
A. sub $s2,$s2,$s2
B. ori $s0,$s0,0xffff
C. j 0x00100000
D. jalr $s0,$a0
E. lw $s0,4($t0)
答案:C
指令翻译测试1
1.查阅MIPS指令手册,我们可以知道,指令add $s1, $s2, $s3 对应的操作码是:(用6位二进制表示,例如111111)
2.32位二进制机器码是:(用32位二进制表示,例如00000000000000000000000000000000)
3.8位十六进制机器码是:(用8位十六进制表示,例如0x11101111)
答案:
- 000000
- 00000010010100111000100000100000
- 0x02538820
指令翻译测试2
ori $t0,$0,4
bne $t0,$t1,next
nop
next:
sw $t0,4($t1)
根据上面这段程序(首条指令的地址为0x00003000),将下述指令中的特定指令翻译成机器码,注意比较立即数在各个机器码中的结果(八位十六进制,前面要加上「0x」,例如「0x12345678」,如有字母,请使用小写)。
1.ori $t0,$0,4 机器码:_____________________________
2.bne $t0,$t1,next 机器码:_____________________________
3.sw $t0,4($t1) 机器码:_____________________________
答案:
(1) 0x34080004
(2) 0x15090001
(3) 0xad280004
bne指令功能测试

运行上述代码之后,寄存器$a2的值为多少?(9,10两行指令的功能是结束程序)
A. 10
B. 18
C. 0
D. 2
答案:D
load/store指令功能测试
在一个小端存储的CPU中,执行下例指令:

1.$t0寄存器中的值是多少?(答案用16进制表示,例0x00000000)___________________________
2.$t1寄存器中的值是多少?(答案用16进制表示,例0x00000000)___________________________
3.$t2寄存器中的值是多少?(答案用16进制表示,例0x00000000)___________________________
答案:
(1) 0x00000056
(2) 0x12785678
(3) 0x56785678
jal/jr指令功能测试
运行下列代码之后,$a2寄存器的值是多少?(第一条指令的地址为0x00003000,不考虑延迟槽; 4,5两行指令的功能是结束程序,答案用16进制表示,例0x00000000)

答案:0x00003001
乘除法指令功能测试
在MIPS汇编指令中,乘除法指令的结果最多可以是64位(包括符号位),所以就需要hi和lo两个寄存器来共同保存一个乘除法运算的结果。乘法的结果分为高32位和低32位,除法的结果分为商(32位)和余数(32位),他们分别是由哪个寄存器保存的呢?
A. 乘法:hi保存高32位,lo保存低32位; 除法:hi保存商,lo保存余数。
B. 乘法:hi保存低32位,lo保存高32位; 除法:hi保存商,lo保存余数。
C. 乘法:hi保存高32位,lo保存低32位; 除法:hi保存余数,lo保存商。
D. 乘法:hi保存低32位,lo保存高32位; 除法:hi保存余数,lo保存商。
答案:C
数据溢出测试
根据MIPS指令集,我们知道,指令对于立即数都是有位数限制的。
下面将会给出几条带有立即数的指令,请问哪条指令的立即数存在数据溢出的情况?
PS:不同于机器码,汇编指令的参数需要以负号来区分正负数。
A. addi $a0,$0,0x7643
B. addi $a0,$0,0x8165
C. ori $a0,$0,0x7643
D. ori $a0,$0,0x8165
答案:B
跳转指令范围1
j指令只有26位用于存储跳转到的地址,那么j指令能跳转到的代码范围有多大?
A. 64KB
B. 64MB
C. 256MB
D. 4GB
答案:C
跳转指令范围2
jr指令可以跳转到的代码范围有多大?
A. 64KB
B. 64MB
C. 256MB
D. 4GB
答案:D
跳转指令范围3
Beq指令可以跳转的代码范围有多大?
A. 64KB
B. 128KB
C. 256KB
D. 512KB
答案:C
扩展指令和伪指令
为了方便编程,MIPS 汇编在标准指令的基础上又提供了许许多多的扩展指令,其中就包括前面提到过的对基本指令的转写(例如用标签代替立即数)。此外还有对基本指令的操作数的略写和使用基本指令组合出新的指令。这类扩展指令称为「Pseudo Instructions」。
虽然使用标签、基本指令和扩展指令已经可以写出汇编程序,但其灵活性仍有限制。例如,仅用标签和指令无法初始化变量(数据段中的数据);无法区分代码属于普通代码或异常处理代码。因此,汇编器提供了伪指令(Directives)来让我们指导汇编器的工作。有了伪指令,我们可以声明全局标签、声明宏、设置异常数据段和代码段等等。
扩展指令(PSEUDO INSTRUCTIONS)
学过机器码之后,我们就可以将一条机器码还原为一条汇编指令,例如将 0x08000c0a 还原为 j 0xc0a。而 j 0xc0a 这种形式,我们可以将其称之为标准指令,或者叫**基本指令。**也就是说它的每个操作数都和机器码中的相应字段完美对应。然而,完全使用基本指令会大大降低程序的易读性和灵活性,因此便诞生了扩展指令。
扩展指令的功能主要是简化程序。汇编器将一些常用、但标准指令集不提供的功能封装为一条指令;或者改变现有指令的操作数的形式或个数,使其以新的形式出现。需要注意的是,它们只是形式上是一条新指令,而实际上,在汇编器将其汇编之后,还是使用标准指令来实现的。
最常用到的一条扩展指令是li指令,它用来为某个寄存器赋值,比如 li $a0,100 就是将 100 赋给 $a0 寄存器。汇编器在翻译这条扩展指令时会根据需要,将它翻译成不同的基本指令或基本指令的组合。如下,第一条 li 指令后面的立即数不多于 16 位,因此只被翻译成了一条 addiu;第二条 li 指令后面的立即数多于 16 位,因此被翻译成了 lui+ori 的组合。

另一条常用的扩展指令是 la 指令,这条指令与 li 指令非常类似,都是为寄存器赋值,只不过是使用标签来为寄存器赋值。经过了前面的学习,大家应该已经知道标签本质上对应一个 32 位地址,但 li 指令并不能直接使用标签来为寄存器赋值,必须要使用 la。比如 la $t0, fibs 这条指令就是把 fibs 这个标签的地址存入$t0 中。

上面的例子就是利用现有基础指令组合出新的扩展指令。当然,我们也可以对现有指令进行简化或转写,例如前面提到过的 j 0xc0a,我们可以将其立即数改为一个标签,这样汇编器会在进行汇编时,会将标签所代表的立即数计算出来,形成基本指令的形式,例如下图:
![]()
想要了解更多的扩展指令,可以查看 Mars 的 Help 文档中 Extended (pseudo) Instructions 一栏。
伪指令(DIRECTIVES)
伪指令(Directives)是用来指导汇编器如何处理程序的语句,有点类似于其他语言中的预处理命令。伪指令不是指令,它并不会被编译为机器码,但他却能影响其他指令的汇编结果。常用的伪指令有以下几个:
- **.data:**用于预先存储数据的伪指令的开始标志。
- **.text:**程序代码指令开始的标志。
- **.word:**以字为单位存储数据。
- **.asciiz:**以字节为单位存储字符串。
- **.space:**申请若干个字节的未初始化的内存空间。
这些指令的详细介绍请参考第 4 节(MIPS 汇编程序解析)第 2 单元(变量的声明与分配)。想要了解更多的伪指令可以查看 Mars 的 Help 文档中 Directives 一栏。
注:Mars 的 Help 文档写得比较简略,例如它没有指出 .data 和 .text 伪指令后面可以跟着参数。因此优先以教程中的说法为准(也就是说你要去看看[汇编语言与 MARS:MIPS 汇编程序解析 / 变量声明与定义])。
扩展指令与伪指令测试
扩展指令测试
除了像li这种标准指令集中不存在的指令是扩展指令,一些标准指令集中的指令也可能以扩展指令的形式出现。后者与标准指令不同之处大都在于参数的类型、参数的个数或参数的位数。
例如: ori $a0, 4
这就是一条扩展指令,汇编器会把它翻译为:ori $a0, $a0, 4
到这,想必大家对扩展指令也有了大致的了解,那么请从下面选项中选出扩展指令(多选)。
A. andi $t1, 100
B. mult $t1 $t2
C. ori $a0, $a1, 0x12345678
D. la $t0, loop
答案:ACD
伪指令测试1
在使用伪指令初始化数据时,.word .asciiz等伪指令存储的数据在内存中是如何存储的?
A. 从数据段默认的首地址开始,按照伪指令声明顺序紧密有序存储。
B. 从.data声明的首地址开始,按照伪指令声明顺序紧密有序存储。
C. 从.text声明的首地址开始,按照伪指令声明顺序紧密有序存储。
D. 在内存空闲区域随意存储。
答案:B
伪指令测试2
以下哪些伪指令能够为12个大小为4字节的整数申请内存空间:
A. fibs: .space 12
B. fibs: .space 48
C. fibs: .word 12
D. fibs: .word 48
答案:B
伪指令辨析
如果要输出一个字符串,”Hello world”,应该使用下列哪条伪指令,请注意区分其区别
A. .ascii “Hello world”
B. .asciiz “Hello world”
答案:B