elasticsearch并发问题与锁机制
并发冲突
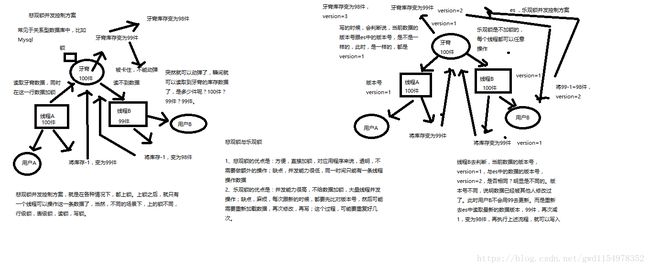
举个例子,比如在电商的场景下,假设我们有个程序,其工作流程为:
1.读取商品信息(包含库存,以牙膏为例);
2.用户下单购买;
3.更新商品库存(库存减一);
如果该程序是多线程的,那么总有一个线程是先得到的,假设我们牙膏库存一开始有100件,此时线程A先得到线程将牙膏的库存设置为99件,然后线程B再将牙膏设置为99件,这个时候就已经错了。
上面所述问题就是ES中的并发冲突问题,会导致数据不准确。
并发解决方案
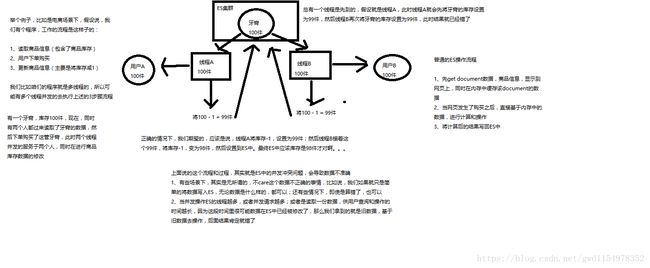
在ES中如何解决这类并发冲突问题?
——通过_version版本号的方式进行乐观锁并发控制
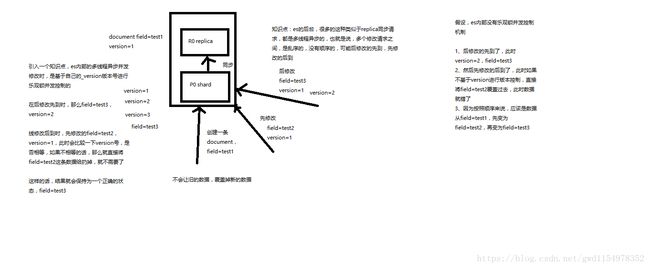
在es内部第次一创建document的时候,它的_version默认会是1,之后进行的删除和修改的操作_version都会增加1。可以看到删除一个document之后,再进行同一个id的document添加操作,版本号是加1而不是初始化为1,从而可以说明document并不是正真地被物理删除,它的一些版本号信息一样会存在,而是会在某个时刻一起被清除。
在es后台,有很多类似于replica同步的请求,这些请求都是异步多线程的,对于多个修改请求是乱序的,因此会使用_version乐观锁来控制这种并发的请求处理。当后续的修改请求先到达,对应修改成功之后_version会加1,然后检测到之前的修改到达会直接丢弃掉该请求;而当后续的修改请求按照正常顺序到达则会正常修改然后_version在前一次修改后的基础上加1(此时_version可能就是3,会基于之前修改后的状态)。
es提供了一个外部版本号的乐观控制方案来替代内部的_version。例如:
?version=1&version_type=external和内在的_version的区别在于。对于内在_version=1,只有在后续请求满足?_version=1的时候才能够更新成功;对于外部_version=1,只有在后续请求满足?_version>1才能够修改成功,即必须大于对应的版本才可以进行修改。
replica同步图示如下图:
说明
乐观锁和悲观锁都是指对待并发控制的两种思想,共享锁(S锁,也叫读锁),排他锁(X锁,又称写锁),行锁,表锁,全局锁,文档锁等是具体的锁的实现,且都属于悲观锁,乐观锁没有锁。
乐观锁
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
在ES中乐观锁主要通过版本号等数据来进行判定该数据是否有被修改过,如果发现版本version与自己不相同,那就说明数据是已经被修改过的,那么它会重新去es中读取最新的数据版本,然后再进行数据上的操作。
测试
(1)先构造一条数据出来
PUT /test_index/test_type/7
{
"test_field": "test test"
}(2)模拟两个客户端,都获取到了同一条数据
GET test_index/test_type/7
返回:
{
"_index": "test_index",
"_type": "test_type",
"_id": "7",
"_version": 1,
"found": true,
"_source": {
"test_field": "test test"
}
}(3)其中一个客户端,先更新了一下这个数据
同时带上数据的版本号,确保说,es中的数据的版本号,跟客户端中的数据的版本号是相同的,才能修改
PUT /test_index/test_type/7?version=1
{
"test_field": "test client 1"
}
返回:
{
"_index": "test_index",
"_type": "test_type",
"_id": "7",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}(4)另外一个客户端,尝试基于version=1的数据去进行修改,同样带上version版本号,进行乐观锁的并发控制
PUT /test_index/test_type/7?version=1
{
"test_field": "test client 2"
}
返回:
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[test_type][7]: version conflict, current version [2] is different than the one provided [1]",
"index_uuid": "6m0G7yx7R1KECWWGnfH1sw",
"shard": "3",
"index": "test_index"
}
],
"type": "version_conflict_engine_exception",
"reason": "[test_type][7]: version conflict, current version [2] is different than the one provided [1]",
"index_uuid": "6m0G7yx7R1KECWWGnfH1sw",
"shard": "3",
"index": "test_index"
},
"status": 409
}(5)在乐观锁成功阻止并发问题之后,尝试正确的完成更新
GET /test_index/test_type/7
返回:
{
"_index": "test_index",
"_type": "test_type",
"_id": "7",
"_version": 2,
"found": true,
"_source": {
"test_field": "test client 1"
}
}基于最新的数据和版本号,去进行修改,修改后,带上最新的版本号,可能这个步骤会需要反复执行好几次,才能成功,特别是在多线程并发更新同一条数据很频繁的情况下
PUT /test_index/test_type/7?version=2
{
"test_field": "test client 2"
}
返回:
{
"_index": "test_index",
"_type": "test_type",
"_id": "7",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}
悲观锁
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,上锁之后就只有一个线程可以操作这条数据了,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁和悲观锁对比
悲观锁
优点:方便,直接加锁,对应用程序来说比较透明,不需要额外的操作;
缺点:并发能力低,同一时间只能有一条线程操作数据;
乐观锁
优点:并发能力高,不给数据加锁,可大量线程并发操作;
缺点:麻烦,每次更新的时候,都要先比对版本号,然后可能需要重新加载数据,再次修改,再次更改……这个过程可能需要重复多次;