cpu报警
进程CPU额度使用率报警
背景知识 (background)
无论是物理机或容器化部署的应用,通常使用CGroup进行资源隔离,开发可在应用大盘看到进程的CPU额度。
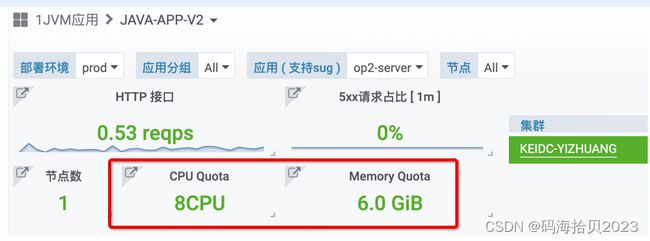
其中,CPU Quota是进程最大可用的CPU额度,若进程CPU使用率超过额度,会被操作系统限制CPU使用,慢请求会上升。
生产环境可能不同节点的内存/CPU额度不一样,可选择节点查看单台的准确额度。
进程 CPU Qutoa 使用率的取值范围是 [0 , 1],最大100%,衡量的是单位时间内,进程可用的CPU额度已使用了多少,考察的是CPU够不够用,是否应该扩容了。
目前进程CPU额度的使用率超过了80%且持续1分钟,则会触发报警。
查看指标 (dashboard)
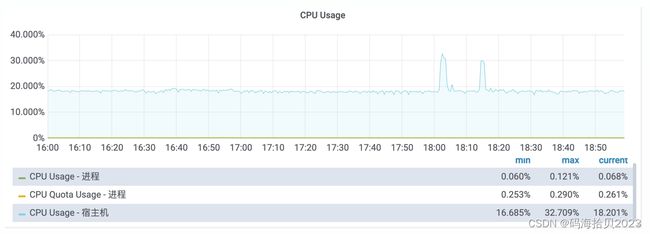
其中,CPU Quota Usage - 进程即已分配给进程的CPU额度现在用了多少。
另外,开发也应关注监控面板: [CGroup 统计[1m]]里的近一分钟CPU Throttled占比,这个指标可侧面印证进程是否因CPU额度提前用尽而被限制了。

止损措施 (action)
注意,因历史原因,不同节点的CPU额度可能不一样,另外,物理机的配置、性能也不尽相同。
关注 / 7层的499、监控狗的慢请求报警,若报错、报警集中在单台,可临时摘流节点。
事后改进(postmortem)
CPU额度不足,除了申请的套餐容量比较小之外,也可能是进程的CPU使用率过高。
容量套餐,基础服务建议在12CPU,核心应用8CPU,普通应用4CPU 。除此之外,可尝试扩容节点,降低单个节点的流量。
基础服务虽然可申请12CPU,但建议
进程CPU使用率控制在10%以内,可适当冗余20%的节点数。通常基础服务对性能、稳定性要求高,即在任何情况下,线程数、GC停顿、CPU使用率都尽可能稳定,避免毛刺。申请12CPU纯粹是为了避免OS限制CPU导致的长尾请求波动。
总之,CPU是极度稀缺的资源,内存相对比较充足,应用设计时,尽可能支持横向扩容、多部署一些节点,关注代码性能问题导致的单节点CPU消耗过多。
在实际排查中,可借助 Accesslog 、业务日志、慢请求统计等缩小范围,借助Arthas / JVisualvm等工具的CPU采样功能,筛选可能的业务线程。
生产环境的DEBUG、采样、Dump内存等操作,建议先手动摘流或调小流量权重。
进程CPU使用率报警
背景知识 (background)
无论是物理机或容器化部署的应用,最终都是混合部署的,共享CPU资源,部分应用CPU使用过多,会拖累其他应用的稳定性。
CPU使用率的取值范围是 [0 , 1],最大100%,衡量的是单个进程对整个物理机CPU资源的占用情况 ( 进程占用的CPU/所有CPU可用时间 )。
目前单进程超过20%且持续2分钟,则会触发报警。
大部分JVM应用是多线程、IO密集型,建议进程CPU控制在10%以内(排除定时任务),超过则考虑优化代码或扩容节点。
进程CPU使用率过高除了影响其他混部应用外,也可能被CGroup限制CPU,慢请求增多。
查看指标 (dashboard)
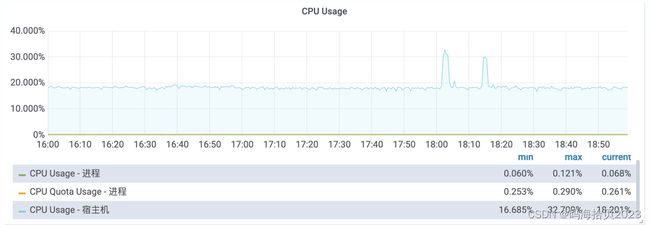
其中,CPU Quota Usage - 进程即已分配给进程的CPU额度现在用了多少,CPU Usage - 进程为进程对整个物理机CPU的占用情况。
另外,开发也应关注监控面板: [CGroup 统计[1m]里的近一分钟CPU Throttled占比,这个指标可侧面印证进程是否因CPU额度提前用尽而被限制了。

止损措施 (action)
7层的499、监控狗的慢请求报警,若受到影响,可临时摘流节点。
事后改进(postmortem)
大部分JVM应用的CPU使用率在5%以内,不少应用甚至在1%以内。除了凌晨的定时任务,一般进程的CPU使用率波动不大。
CPU问题可借助 VisualVM 的抽样器或 arthas的火焰图,采样CPU,方便快速定位。
大部分情况下,可归结为不合理的代码设计,参考原因 (cause) 部分针对性优化。
可能的原因 (cause)
进程CPU使用率的报警,关注的是单个应用对其他混部应用的潜在影响以及不合理的设计对资源的浪费。
一、定时任务、计算逻辑过多
我们建议定时任务尽可能在凌晨的流量低峰期执行,避免白天的流量高峰期,减少对其他应用的影响。
若无法避免高峰时段执行,可尝试任务分片、隔离部署,比如,薪酬月初算薪,进程CPU使用率达到40%,k8s容器部署的话,月初可临时调度薪酬进程到独享的物理机,和其他应用隔离,算薪完成了再调度回去,释放资源。
另一种情况是,业务加载大批量数据、在内存里聚合计算的场景,建议分批加载、预计算,避免内存和CPU占用过多。
若涉及到批量加解密,建议限制单节点流量,尽可能多部署节点。
二、GC频率过高
通常是内存分配压力大, YoungGC频率过高,比如:ParNew / G1。
过于频繁的垃圾回收,则会占用更多CPU。最严重的是垃圾回收时,CPU时间片耗尽,暂停GC活动,GC日志里却停顿正常,可参考 CGroup 指标里近一分钟进程CPU Throttled 触发的次数来交叉验证。 see application-pauses-when-running-jvm-inside-linux-control-groups
对 ParNew / CMS组合来说,其设计目标就是低停顿,相应的Young区内存占用小,Young GC频繁是合理的,建议一分钟Young GC次数控制在20次以内,单次停顿在30ms以内。
内存分配压力大,可能是每次查询返回的数据过多、批量导入导出时内存数据过多。
导入导出时,我们建议确保内存里的数据在任意数据量下都是稳定、固定的开销,尽可能Stream、逐批写入;分页或List接口,确保在任意查询条件下返回合适的数据量,杜绝返回全量数据。
作为临时方案,可申请套餐扩容,增加CPU额度或内存。
若不是代码设计问题,可尝试调整GC线程数(ParallelGCThreads),以应用的CPU额度为基准,建议灰度一个节点观察。
三、线程数上升
线程数不是多多益善,Runable状态的线程越多,操作系统需同时调度的任务就越多,线程上下文切换的成本虽然比进程小,但依旧会消耗不少CPU。
无论是节点流量突增,还是慢请求过多,对稳定性有要求的项目,需确保在任何情况下,线程数量都是稳定的,尽可能Fail Fast。
GC线程、Netty Eventloop线程数,建议以CPU额度为基准,默认以物理机CPU个数为基准可能导致线程过多。
jdk8u121以下版本不支持container-aware,部分组件,比如Netty、GC算法以
Runtime.getRuntime().availableProcessors()来设置并行度。
+XX:ParallelGCThreads用于STW时GC并行处理的线程数,默认算法是max(8, 8+ (5/8) * NCPU),我们建议NCPU(CPU数量)以进程的CPU额度为准。
+XX:ConcGCThreads是Concurrent Phase阶段的GC并行处理的线程数,默认为ParallelGCThreads的四分之一,如果并发标记耗时长,可适当调大观察GC耗时。
对Web容器来说,比如 Tomcat/Undertow等线程池 ,最大线程数控制在800个以内。业务自定义线程池的,建议设置合理的队列大小和最大线程数,并严格控制网络IO超时。
WEB应用通常对延迟敏感,若用户或调用方已取消请求,那么线程池/队列里等待的越久越浪费资源,反而会挤占后续到来的新请求,甚至会妨碍服务恢复正常。
总之,我们建议横向扩展,多部署一些节点,尽可能避免单个节点占用过多资源(CPU/内存)。
参考资料
-
https://bugs.java.com/bugdatabase/view_bug.do?bug_id=JDK-8226575
-
https://jaxenter.com/nobody-puts-java-container-139373.html