百度地图实时路况数据爬取
最近为了参加“华为杯”数学建模的国赛,学校组织了一次校内选拔,题目要求收集不同时段的交通方面数据,建立评价体系,并对整体交通划线效果给出相应评价,看到题目我就方了,这个交通数据怎么拿???!!!包括获取数据到建模结束总共三天时间,这不是为难我们???
于是我就各种网上找爬取交通实时数据的代码,终于我给找到了一篇爬取高德地图的代码,在我按照博主的步骤走的差不多的时候,结果等到爬的时候发现,高德地图的API早在几年前就已经不免费开放了,这个时候已经过去一个上午了,大后天晚上就要交论文,数据都还没有找到,我真是崩溃啊!
我又找我做IT的朋友看看有没有办法,但人家不擅长python这种东西,多多少少最终给我找到了百度地图的API,没有百度地图爬取的代码!!!,害!就照着高德地图自己编吧,时间来不及了,废话不多说,上代码:
1.首先,进入百度地图的控制台,注册自己的账号,网址和位置都给你展示好了,找到应用管理,进入我的应用

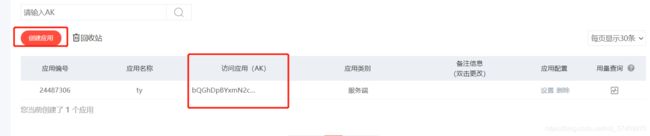
2.点击创建我的应用,创建成功以后就会有个AK地址,这就是你后面爬取时要用到的东西
3.终于到了代码这里啦
#导入模块
import pandas as pd
import requests
import os
import time #爬取实时交通数据记录时间
import datetime
from time import strftime,asctime,ctime,gmtime,mktime
import json
import csv
#构造关于['东二环','南二环','西二环','北二环'] 详细数据变量函数,我这里爬取的是长沙市二环交通路况数据
def fers(road_name): #road_name为你要爬取的交通路段名,我这里是'东二环','南二环','西二环','北二环'4个路段
city = '长沙市'
ak = '' #你自己的ak地址
url = 'http://api.map.baidu.com/traffic/v1/road?road_name={}&city={}&ak={}'.format(str(road_name),city,ak) #爬过数据的人应该都知道这是什么东西吧,哈哈
re=requests.get(url) #返回的原数据
decodejson=json.loads(re.text)
road_traffic_s=decodejson['road_traffic'][0] #获取交通路段拥堵信息 ,这个地方不懂的可以先打印一下看下数据结构
v=road_traffic_s['congestion_sections']
curr_time=datetime.datetime.now()
time_str = datetime.datetime.strftime(curr_time,'%Y-%m-%d %H:%M:%S') #获取当前爬取的时间段
ty=pd.DataFrame(v)
ty['名称']=pd.DataFrame([road_traffic_s['road_name']]*len(v)) #路段名称
ty['时间']=pd.DataFrame([time_str]*len(v)) #记录此刻交通拥堵时间
return ty
实际上数据结构是这样的,真正我们需要的交通拥堵数据是在’road_traffic’下面的值,但有时候交通不拥堵的情况下,数据结构又变了,这也就造成了数据爬取过程中格式不统一报错的问题,整个爬取过程中,难度就在于怎么解决拥堵时段和非拥堵时段格式不统一的问题
这里可以对比看一下拥堵时段和非拥堵时段的数据结构,长度是不一样的
![]()
#造关于['东二环','南二环','西二环','北二环'] 总体描述性数据变量函数
def es(road_name):
city = '长沙市'
ak = ''
url = 'http://api.map.baidu.com/traffic/v1/road?road_name={}&city={}&ak={}'.format(str(road_name),city,ak)
re=requests.get(url) #返回的原数据
res=re.json() #json处理后的数据
decodejson = json.loads(re.text)
description=decodejson['description'] #路段的总体描述性信息
evaluation=decodejson['evaluation'] #交通总体的评估状况
road_traffic=decodejson['road_traffic'][0]
road_data=pd.DataFrame([evaluation])
road_data['road_name']=road_traffic['road_name'] #交通路段名称
curr_time=datetime.datetime.now()
time_str = datetime.datetime.strftime(curr_time,'%Y-%m-%d %H:%M:%S')
road_data['时间']=pd.DataFrame([time_str]) #交通路况时间 #交通路段时间
road_data['路况描述']=description
# return road_data
if not os.path.exists('result_s1.csv'):
road_data.to_csv('result_s1.csv',encoding='gbk',mode='a',index=False,index_label=False) #保存数据
else:
road_data.to_csv('result_s1.csv', encoding='gbk', mode='a', index=False, index_label=False,header=False)
实际上,无论交通拥堵详细数据怎么变,'road_traffic’前面的数据格式是不变的,那好吧,我就只能给它分开爬取保存了

#定义详细交通数据爬取保存的函数
def get_page(road_name):
city = '长沙市'
s=fers(road_name)
if not os.path.exists('result.csv'):
s.to_csv('result.csv',encoding='gbk',mode='a',index=False,index_label=False)
else:
s.to_csv('result.csv', encoding='gbk', mode='a', index=False, index_label=False,header=False)
终于走到这一步啦,接下来就是编制循环开始爬取了
#设置休眠时间,每5分钟爬取一次实时交通数据
while True:
if __name__ == '__main__':
road_name = ['东二环','南二环','西二环','北二环']
for i in road_name:
city = '长沙市'
ak = ''
url = 'http://api.map.baidu.com/traffic/v1/road?road_name={}&city={}&ak={}'.format(str(i),city,ak)
re=requests.get(url) #返回的原数据
decodejson = json.loads(re.text)
road_traffics=decodejson['road_traffic'] #获取交通路段拥堵信息
if len(road_traffics[0])>=2: #对拥堵路段进行详细数据提取,为什么这样写呢,就是因为拥堵时数据长度为2,非拥堵时段长度为1,这真是我观察了好久,不断报错找到的规律啊,我太难了!!!苦啊
get_page(i) #拥堵时段爬取拥堵时段的详细数据,保存一个文件
es(i) #保存描述性数据
else:
es(i) #非拥堵时段,我们只需保存整体的描述性数据就可以啦
time.sleep(300)
但要注意一点的是百度地图有天配额,好像是 1000我记得,超限就会限制访问报错啦,此时你可以用其他账号创建ak继续整个爬取过程,好了,代码就写到这里就就结束啦,终于在我不断修修改改,实现了当天晚上数据的顺畅爬取,整个比赛过程真的是又累又紧张啊,之前网上找了好久,发现爬取交通实况数据的代码很少,但在研究的过程中其实有很多人需要它,记录下自己整个获取的过程,并希望这篇交通实时数据爬取可以帮助到你,谢谢。