Centos7.5 性能评估CPU、内存、磁盘、TCP/IP 等属性
- CPU
主要从三方面:负载情况、统计输出、当前运行状况,来对CPU进行评估。
1. vmstat命令,显示各种关于系统资源之间相关性能的简要信息,体现CPU负载情况。
vmstat 1 1 表示每隔1秒采集1次CPU负载情况。

描述:
procs:r 列 表示运行和等待CPU时间片的进程数,这个值如果长期大于系统CPU个数,说明需要增加CPU。
memory:cache列 表示页面缓存的内存数量,一般作为文件系统缓存;
如果cache值较大,说明缓存的文件数较多,与此同时io中bi比较大,说明文件系统效率比较差。
system:显示采集间隔内发生的中断次数;
in列 表示在某一段时间间隔中观测到的每秒设备中断次数
cs列 表示每秒产生的上下文切换次数
这两个值越大,由内核占用CPU时间就会越多。
cpu:显示CPU的使用状态;
us列显示了用户进程占用CPU的时间百分比,us的值比较高时,说明用户进程占用的CPU的时间多
sy显示了内核进程占用CPU的时间百分比,sy的值较高时,说明内核消耗的CPU资源很多
us+uy的参考值为80%,如果us+uy大于80%说明可能存在CPU资源不足。
2. sar -u 命令,对CPU统计输出,对系统整体CPU使用状况进行统计。
对CPU计数是从0开始,表示对系统的第一颗CPU进行统计,依此类推。
sar -u 1 1 表示查看CPU利用率 每隔1秒写入1次

描述:
%user列 显示CPU处在空闲状态的时间的百分比
%nice列 显示运行正常进程占用CPU的时间百分比
%System列 显示系统进程占用CPU的时间百分比
%iowait列 显示i/o等待所占用CPU的时间百分比
%steal列 显示在内存中相对紧张的环境下pagein强制对不同的页面进行的steal操作
%idle列 显示CPU处在空闲状态的时间百分比
输出结果是对系统整体CPU使用状况的统计及其平均值,每项输出都非常直观。
3. uptime命令,用来统计系统当前的运行状况。
uptime
![]()
描述:
输出的信息依次为:系统现在的时间、系统从上次开机到现在运行了多长时间、有多少用户登陆、系统在1分钟内,
5分钟内,15分钟内的平均负载。
load average的三个值如果长期大于系统中CPU个数,说明CPU负载很高,可能会影响系统性能。
- 内存
主要从三方面:可用内存/物理内存占比、内存参数输出、sar -r,来对内存进行说明。
1. 利用free指令监控并计算可用内存/物理内存占比进行说明,参数-m以M为单位显示,-h人性化显示单位。
free -h

描述:
当可用内存/物理内存:大于70%时,表示系统内存非常充足。
当可用内存/物理内存:大于20%并小于70%时,表示能满足需求,暂时不影响系统性能。
当可用内存/物理内存:小于20%时,表示系统内存资源紧缺,要增加系统内存。
2. 利用vmstat命令,对某些细节参数输出进行间接说明。
vmstat 1 1 表示每隔1秒采集1次信息。

描述:
memory、swap:
si列 表示有磁盘调入内存,也就是内存进入内存交换区的数量
so列 表示由内存调入磁盘,也就是内存交换区进入内存的数量
swpd列 表示切换到内存交换区的内存数量(以kb为单位),
如果swpd值为0,或者si、so的值长期不为0,说明系统内存不足。
3. 利用sar -r 命令,对内存进行说明。
sar -r 1 1 表示每隔1秒写入1次

描述:
kbcommit:当前工作负载所需的内存量(RAM + Swap、以千字节为单位),用来保证不会出现内存不足的情况。
%commit:当前工作负载所需内存占内存总量(RAM + Swap)的百分比;
这个占比可能大于100%,因为内核通常会过度使用内存。
如果%commit长时间大于100%,则此时内存可能不足。
- 磁盘
主要从三方面:vmstat、iostat –d 、sar -d 来描述磁盘的性能。
1. 利用vmstat命令,对读写性能进行说明。
vmstat 1 1 表示每隔1秒采集1次信息。

描述:
io:显示磁盘读写状况
bi列:表示从块设备读入数据的总量(既读磁盘)(每秒kb)
bo列:表示写入到块设备的数据总量(既写磁盘)(每秒kb)
cpu:
wa列 表示i/o等待所占用的cpu时间百分比。
bi+bo参考值为1000,而且wa值较大,说明i/o等待越严重,则表示系统磁盘i/o有问题。
根据经验,wa的参考值为20%,如果wa超过了20%,可能是磁盘大量随机读写造成的i/o等待,也可能是磁盘
或者磁盘控制器的带宽瓶颈造成的(主要是块操作)。
2. 利用iostat -d 命令,对读写性能进行说明。
iostat -d 1 1 表示每隔1秒输出1次磁盘信息(不包含CPU信息)
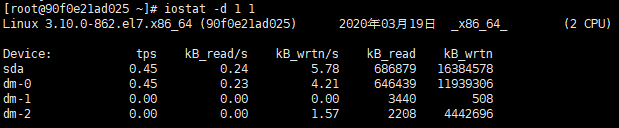
描述:
KB_read/s:表示每秒读取的数据块数
KB_wrtn/s:表示每秒写入的数据块数
KB_read:表示读取的所有块数
KB_wrtn:表示写入的所有块数
如果KB_wrtn/s值很大,表示磁盘的写操作很频繁,可以考虑优化磁盘或优化程序;
如果KB_read/s值很大,表示磁盘直接读取操作很多,可以将读取的数据放入内存中进行操作。
对于以上两个值没有一个固定的大小,但是数值长期的过大说明磁盘读写则不正常。
3. 利用sar -d 命令,对读写性能进行说明。
sar -d 1 1 表示每隔1秒写入1次

描述:
avgrq-sz:表示平均每次设备I/O操作的数据大小(以扇区为单位)
avgqu-sz:表示平均I/O队列长度
await:表示平均每次设备I/O操作的等待时间(以毫秒为单位)
svctm:表示平均每次设备I/O操作的服务时间(以毫秒为单位)
%util:表示一秒钟有百分之几的时间用于I/O操作
一般情况下svctm应该是小于await值的,而svctm的大小和磁盘性能有关,CPU、内存的负荷也对svctm值
造成影响,过多的请求也会间接导致svctm值的增加。
如果wait的值一般取决于svctm的值和I/O队列长度以及I/O请求模式。如果svctm的值与await的值很接近,
就表示几乎没有I/O等待,磁盘性能很好;
如果await的值远高于svctm的值,则表示I/O队列等待太长,系统运行的应用程序将变慢,此时要更换更快
的硬盘。
%util的值也是衡量磁盘I/O的一个重要指标,如果%util接近100%,就表示磁盘产生的I/O请求太多,I/O系统已经
满负荷地在工作,该磁盘可能要尽快更换。
- TCP/IP
通过以下两方面:netstat命令、Socket Statistics命令来对TCP/IP连接数进行说明。
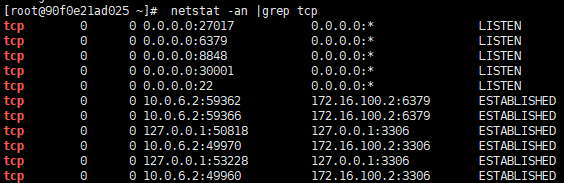
1. netstat命令
netstat -an |grep tcp 查看当前所有的TCP连接相关信息
2. Socket Statistics命令
之前采用netstat命令会发现在服务器繁忙的时候效果不理想,有时会占用高达90%以上的CPU。
而Socket Statistics(ss)命令底层使用TCP协议栈中用于分析统计的tcp_diag模块,所以速度更快、更高效。
ss -t 显示系统目前所有TCP连接的连接情况

描述:
-t 只显示TCP连接信息
-a 显示所有连接信息
-u 只显示UDP连接信息
几乎所有的Linux系统都会默认包含netstat命令,但并非都会包含ss命令(Centos默认包含)。
ss命令包含iproute工具集中,这是一套可以支持IPv4/IPv6网络的用于管理TCP/UDP/IP网络的工具集。
如果找不到ss命令,可以如下安装此工具集: yum install iproute iproute-doc