Spark原理、Yarn 、资源参数
一、名词解释:
1、master 节点:
常驻master进程,负责管理全部worker节点。Master其实就是调度资源,还有就是集群的监控
2、worker 节点:
常驻worker进程,负责管理executor 并与master节点通信。进行资源的分配,一个物理节点可以有一个或多个worker。一个worker中可以有一个或多个executor,一个executor拥有多个cpu core和memory。
3、driver:
Spark驱动器节点,用于执行Spark任务中的main方法,负责实际代码的执行工作。Driver在Spark作业执行时主要负责:driver是启动在本地机器的,而且driver是全权负责所有的任务的调度的,也就是说要跟yarn集群上运行的多个executor进行频繁的通信(中间有task的启动消息、task的执行统计消息、task的运行状态、shuffle的输出结果)。
- 将用户程序转化为作业(job);
- 在Executor之间调度任务(task);
- 跟踪Executor的执行情况;
- 通过UI展示查询运行情况;
用户自己编写的应用程序。主要完成任务的调度以及和executor和cluster manager进行协调。有client和cluster联众模式。client模式driver在任务提交的机器上运行,而cluster模式会随机选择机器中的一台机器启动driver。

4、Executor 执行器:
Spark Executor节点是一个JVM进程,负责在 Spark 作业中运行具体任务,任务彼此之间相互独立。Spark 应用启动时,Executor节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。
- 每个节点可以起一个或多个Executor。
- 每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task。
- 每个Task执行的结果就是生成了目标RDD的一个partiton。
这里的core是虚拟的core而不是机器的物理CPU核,可以理解为就是Executor的一个工作线程。在每个WorkerNode上为某应用启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上,每个任务都有各自独立的Executor。
Executor是一个执行Task的容器。它的主要职责是:
1、初始化程序要执行的上下文SparkEnv,解决应用程序需要运行时的jar包的依赖,加载类。
2、同时还有一个ExecutorBackend向cluster manager汇报当前的任务状态,这一方面有点类似hadoop的tasktracker和task。
总结:Executor是一个应用程序运行的监控和执行容器。Executor的数目可以在submit时,由 --num-executors (on yarn)指定.
5、Application:
application(应用)其实就是用spark-submit提交的程序。比方说spark examples中的计算pi的SparkPi。一个application通常包含三部分:从数据源(比方说HDFS)取数据形成RDD,通过RDD的transformation和action进行计算,将结果输出到console或者外部存储(比方说collect收集输出到console)。
6、Job:
包含很多task的并行计算,可以认为是Spark RDD 里面的action,每个action算子的操作都会生成一个job。 比方说count,groupbykey。用户提交的Job会提交给DAGScheduler,DAGScheduler会对Job进行拆分,Job会被分解成Stage和Task。
拆分的依据:根据FinalRDD(在这里ForeachRDD)递归向上解析Lineager的依赖关系,以宽依赖为切分stage的依据,
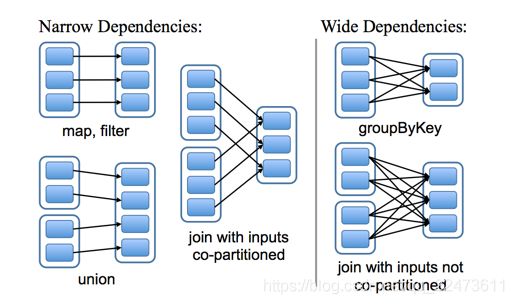

7、Stage:
每个Stage对应一个宽依赖wide transformation。
Stage概念是spark中独有的。一般而言一个Job会切换成一定数量的stage。各个stage之间按照顺序执行。至于stage是怎么切分的,首选得知道spark论文中提到的narrow dependency(窄依赖)和wide dependency( 宽依赖)的概念。其实很好区分,看一下父RDD中的数据是否进入不同的子RDD,如果只进入到一个子RDD则是窄依赖,否则就是宽依赖。宽依赖和窄依赖的边界就是stage的划分点。
只有shuffle操作时才算作一个stage。若干个Transformation的算子RDD组成Stage,所以一个RDD中有多少个partition,就有多少个Task,因为每一个Task只对一个partition数据做处理。
一个Job会被拆分为多组Task,每组任务被称为一个Stage就像Map Stage, Reduce Stage。
8、Task :
一个partition对应一个task。即 stage 下的一个任务执行单元,最小单元,每个Task执行的结果就是生成了目标RDD的一个partiton。一般来说,一个 rdd 有多少个 partition,就会有多少个 task,因为每一个 task 只是处理一个partition 上的数据.
每个executor执行的task的数目, 可以由submit时,--num-executors和--executor-cores来指定。Task被执行的并发度 = Executor数目 * 每个Executor核数。
8、Reduce个数等于文件个数
(1) 如果 ReduceTask 的数量 > getPartition 的结果数,则会产生几个空的输出文件 part-r-000xx。
(2) 如果 1 < ReduceTask 的数量 < getPartition 的结果数,则有一部分分区数会无处放,会报错。
(3) 如果 ReduceTask 的数量 = 1,则不管 MapTask 端输出多少个分区文件,最终结果都会交给这一个 ReduceTask,最终也就只会产生一个结果文件 part-r-00000。
9、RDD
RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。
1)一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
2)一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
3)RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
4)一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
5)一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
二、Yarn工作原理 、角色
YARN 在 Hadoop 集群中充当资源管理和任务调度的框架,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
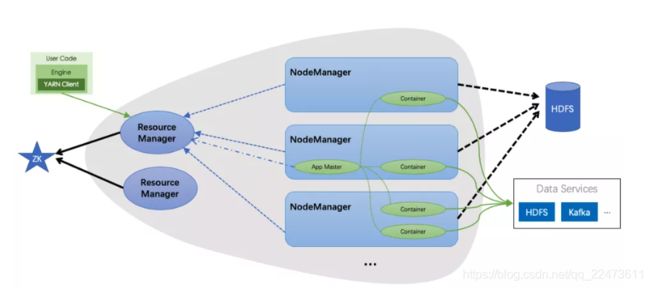
上图中灰色背景区域是 YARN 的主要架构, 主要包含两种角色
2.1 YARN 的主要架构、两种角色
1、ResourceManager
- 整个集群的大脑,负责为应用调度资源,管理应用生命周期。
- 对用户提供接口,包括命令行接口,API, WebUI 接口。
- 可以同时存在多个 RM,但同一时间只有一个在工作,RM 之间通过 ZK 选主。
- ResourceManager是master上的进程,负责整个分布式系统的资源管理和调度。他会处理来自client端的请求(包括提交作业/杀死作业);启动/监控Application Master;监控NodeManager的情况,比如可能挂掉的NodeManager。
2、NodeManager
-
为整个集群提供资源,接受 Container 运行。
-
管理 Contianer 的运行时生命周期,包括 Localization,资源隔离,日志聚合等。
-
NodeManager时处在slave节点上的进程,他只负责当前slave节点的资源管理和调度,以及task的运行。他会定期向ResourceManager回报资源/Container的情况(heartbeat);接受来自ResourceManager对于Container的启停命令。
3、Application Master
每一个提交到集群的作业application都会有一个与之对应的Application Master来负责应用程序的管理。 它是Appliaction启动的第一个容器,他负责进行数据切分;为当前应用程序向ResourceManager去申请资源(也就是Container),分配资源,并分配给具体的任务;与NodeManager通信,同时通知NodeManager来为Application启动container,用来启停具体的任务,任务运行在Container中;而任务的监控和容错也是由Application Master来负责的。 Application Master避免了需要一个活动的client来维持,启动Applicatin的client可以随时退出,而由Yarn管理的进程继续在集群中运行
4、Container
它包含了Application Master向ResourceManager申请的计算资源,比如说CPU/内存的大小,以及任务运行所需的环境变量和队任务运行情况的描述。AM也是在container上运行的,不过AM的container是RM申请的。
YARN 上运行的作业:
-
在运行时会访问外部的数据服务,常见的如 HDFS,Kafka 等
-
会在运行结束后由 YARN 负责将日志上传到 HDFS 中
工作流程:

(1)Client向ResourceManager提交作业(可以是Spark/Mapreduce作业)
(2)ResourceManager与NodeManager通信,ResourceManager会为这个作业分配一个container
(3)ResourceManager与NodeManager通信,要求NodeManger在刚刚分配好的container上启动应用程序的Application Master
(4)Application Master先去向ResourceManager注册,而后ResourceManager会为各个任务申请资源,并监控运行情况
(5)Application Master采用轮询(polling)方式向ResourceManager申请并领取资源(通过RPC协议通信)
(6) Application Manager申请到了资源以后,就和NodeManager通信,要求NodeManager启动任务
最后,NodeManger启动作业对应的任务。
2.2、yarn任务调度策略
Yarn 中实现的调度策略有三种:
- FIFO(先进先出)
- capacity scheduler(容量调度)
- fair scheduler(公平调度)
(1)FIFO Scheduler:

将所有application 按提交的顺序排队,先进先出
- 优点:简单易懂且不用任何配置
- 缺点:不适合于shared clusters;大的应用会将集群资源占满从而导致大量应用等待
小结:
1、一个队列可以使用yarn的全部资源;
2、后提交的任务必须等前面的任务运行完成之后,才可以得到资源并执行。
(2)Capacity Scheduler (容量调度)
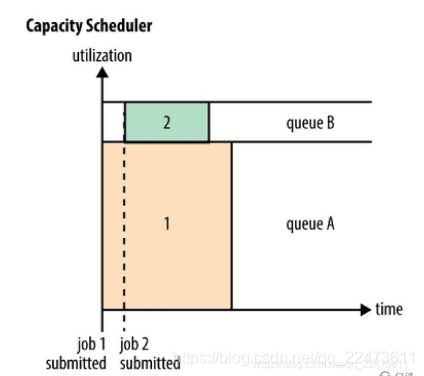
将application 划分为多条任务队列,每条队列拥有相应的资源在队列的内部,资源分配遵循FIFO 策略队列资源支持弹性调整:一个队列的空闲资源可以分配给“饥饿”队列(注意:一旦之前的空闲队列需求增长,因为不支持“先占”,不能强制kill 资源container,则需要等待其他队列释放资源;为防止这种状况的出现,可以配置队列最大资源进行限制)
任务队列支持继承结构
小结:
最大化集群吞吐量
•核心思想
集群资源由多个队列分享
空闲队列可以把资源“借”给忙队列
需要时可以取回
•调度策略
应该获得的资源/实际获得的资源,选择比值最低的队列
队列内FIFO
考虑限制:单个用户使用资源、使用其他队列资源
(3)Fair Scheduler(公平调度)
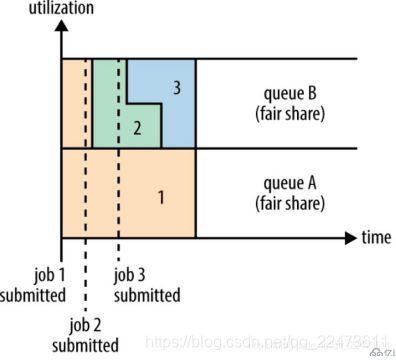
不需要为特定small application 保留资源,而是在需要执行时进行动态公平分配;动态资源分配有一个延后,因为需要等待large job 释放一部分资源 Small job 资源使用完毕后,large job 可以再次获得全部资源 Fair Scheduler 也支持在application queue 之间进行调度
小结:
多用户公平共享集群资源
•作业池
–每个用户单独资源池
–作业放进共享资源池
–每个作业最低资源保障
•调度策略
–默认FIFO
–队列内调度策略可配置
Fair调度器的设计目标是为所有的应用分配公平的资源(对公平的定义可以通过参数来设置)。
在上面的“Yarn调度器对比图”展示了一个队列中两个应用的公平调度;当然,公平调度在也可以在多个队列间工作。
举个例子,假设有两个用户A和B,他们分别拥有一个队列。当A启动一个job而B没有任务时,A会获得全部集群资源;当B启动一个job后,A的job会继续运行,不过一会儿之后两个任务会各自获得一半的集群资源。如果此时B再启动第二个job并且其它job还在运行,则它将会和B的第一个job共享B这个队列的资源,也就是B的两个job会用于四分之一的集群资源,而A的job仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享。
二、架构详解
1、spark提交任务工作流
1、在客户端机器上用spark-submit来提交我们的程序,以standload模式来提交作业
2、spark会通过反射的方式,创建和构造一个DriverActor进程(Driver进程的作用是执行我们的Application,就是我们的代码)
3、入口是从sc开始的,每次都是先构造SparkConf,在构造SparkContext或SparkSession
4、sparkContext在初始化时,做的最重要两件事就是构造DAGScheduler和TaskScheduler(它有自己的后台进程)
5、TaskSchedule实际上,负责通过后台进程去连接Master,向Master注册Application
6、Master接收到Application注册请求后,会使用自己的资源调度算法,在spark集群的worker上,为这个Application启动多个Executor
7、Master会连接Worker,通知worker为Application启动一个或多个Executor(进程)
8、Executor启动后,第一件事情是到反向注册到TaskScheduler上,这样TaskScheduler就知道服务于自己的Application的Executor有哪些
9、所有的Executor注册到TaskScheduler后,Driver就完成了sparkContext或sparkSession的初始化,
10、继续执行代码 ,每执行到一个Action就会创建一个job
11、job会被提交给DAGScheduler,DAGScheduler会根据RDD的宽依赖或者窄依赖,进行阶段stage的划分。DAGScheduler会调用stage划分算法,将job划分为多个stage,划分好后放入taskset中
12、DAGScheduler会把stageSet给到TaskScheduler,TaskScheduler会把每个TaskSet里每个task提交到executor上执行(task分配算法)
13、executor中有个重要的组件--线程池。Executor每接收到一个task,都会用TaskRunner来封装task,然后从线程池里取出一个线程来执行这个task
14、TaskRunner的作用是将我们编写的代码,也就是要执行的算子和函数,拷贝、反序列化,然后执行task
15、Task有两种:ShuffleMapTask和ResultTask,只有最后一个stage是ResultTask,其他都是ShuffleMapTask
16、所以,最后整个spark应用程序的执行,就是stage分批次作为taskSet提交到executor执行,每个task针对RDD的一个partition,执行我们定义的算子和函数。以此类推,直到所有操作执行结束
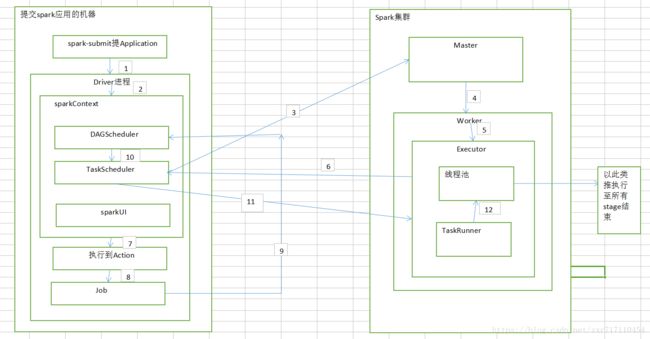
一般来讲我们编写的Spark程序就是在Driver上,由Driver进程执行Driver进程启动以后就会做一些初始化操作,
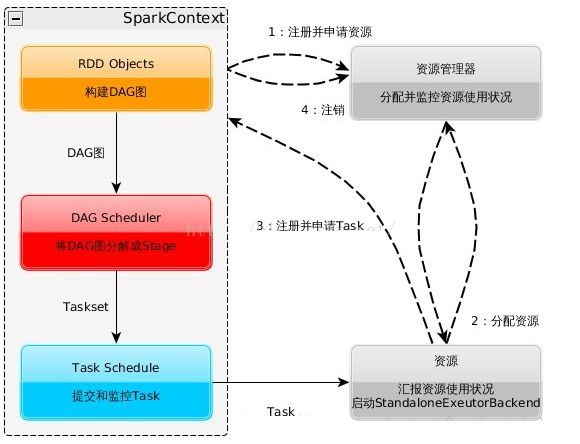
在这个过程中,就会发送请求到Master上进行Spark应用程序的注册,其实就是告诉Master,有一个新的Spark程序要跑起来,
构建Spark Application的运行环境,启动SparkContext,
DAGScheduler根据FinalRDD递归向上解析Lineager的依赖关系
创建TaskScheduler即TaskSchedulerImpl接着又创建SparkDeploySchedulerBackend对资源参数创建AppClient与Master注册Application,并替每个TaskSet创建TaskManager负责监控此TaskSet中任务的执行情况
Master跟Worker通信,然后让Worker启动Executor
SparkContext向资源管理器(可以是Standalone,Mesos,Yarn)申请运行Executor资源,并启动StandaloneExecutorbackend,
Executor向Driver发送注册消息,Driver接收到Executor注册消息后,响应注册成功的消息
Executor接受到请求以后就会调用多个Task节点进行执行。
Executor向SparkContext申请Task
task就会对RDDpartition数据执行指定的算子操作,形成新的RDD分区,
SparkContext将应用程序分发给Executor
SparkContext构建成DAG图,将DAG图分解成Stage、将Taskset发送给Task Scheduler,最后由Task Scheduler将Task发送给Executor运行
Task在Executor上运行,运行完释放所有资源
Task运行完成,向TaskManager汇报情况,并且释放线程资源
所有Task运行结束之后,Executor向Worker注销自身,释放资源。
三、Spark 部署模式
1、Yarn-client
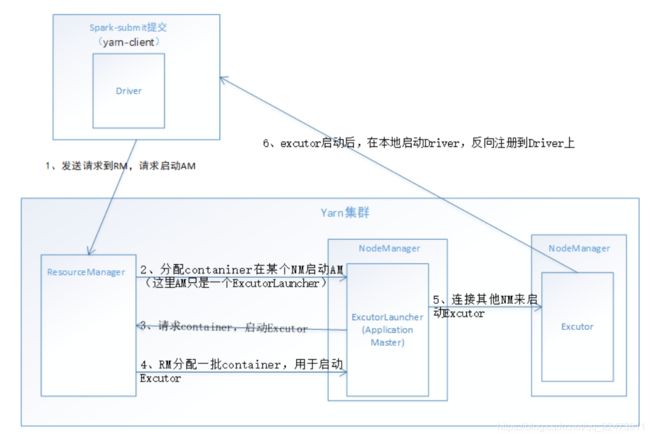
在Yarn-client中,Application Master仅仅从Yarn中申请资源给Executor,之后client会跟container通信进行作业的调度
Driver运行位置
- Driver 在本地运行,并没有在nodemanager上,在nodemanager上启动的applicationMaster仅仅是一个ExecutorLanucher,功能十分有限。
Yarn-client模式下作业执行流程:
1. 客户端Client生成作业信息提交给ResourceManager(RM)申请启动Application Master。
同时在SparkContent初始化中将创建DAGScheduler和TASKScheduler等,由于我们选择的是Yarn-Client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend;
2 .ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,
与YARN-Cluster区别的是:Yarn-client模式下在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派;
3 .Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container);
4. ApplicationMaster向RM申请资源,RM会返回一个资源列表,去进行分配资源,资源是以container的方式,
4 .一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,分配资源同时通知其他NodeManager启动相应的Executor,要求它在获得的Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task;
5. Executor向本地启动的Application Master注册汇报并完成相应的任务
6 .Client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
7 .应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己。
2、Yarn-cluster
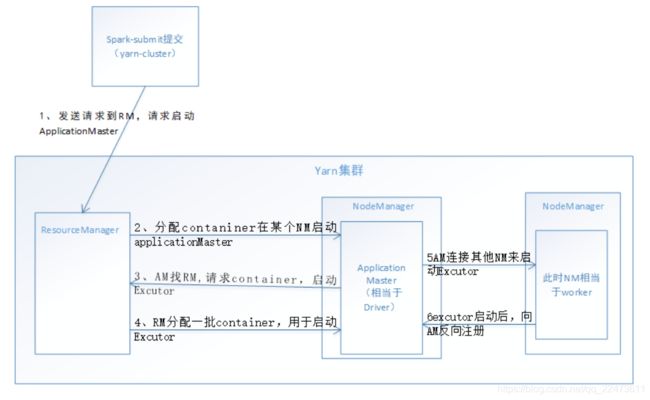
在Yarn-cluster模式下,driver运行在Appliaction Master上,Appliaction Master进程同时负责驱动Application和从Yarn中申请资源,该进程运行在Yarn container内,所以启动Application Master的client可以立即关闭而不必持续到Application的生命周期,
Driver 运行位置
- Driver运行在nodemanager上,Appliaction Master上
Yarn-cluster模式下作业执行流程:
1. 客户端生成作业信息提交给ResourceManager(RM)
2. ResourceManager收到请求后,在集群中选择一个NodeManager(由Yarn决定)启动container,
3. NM接收到RM的分配,启动Application Master(相当于Driver客户端) 并初始化作业,此时这个NM就称为Driver
其中ApplicationMaster进行SparkContext等的初始化;
4. ApplicationMaster向RM申请资源(也就是Container),RM会返回一个资源列表,去进行分配资源,资源是以container的方式,
4、分配资源同时通知其他NodeManager启动相应的Executor,一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,分配资源同时通知其他NodeManager启动相应的Executor,要求它在获得的Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task;
5. Executor向NM上的Application Master注册汇报, ApplicationMaster中的SparkContext分配Task给Executor并完成相应的任务
6、Executor执行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
7、 应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。
3、yarn-client模式下,会产生什么样的问题呢?
由于driver是启动在本地机器的,而且driver是全权负责所有的任务的调度的,也就是说要跟yarn集群上运行的多个executor进行频繁的通信(中间有task的启动消息、task的执行统计消息、task的运行状态、shuffle的输出结果)。
来想象一下。比如你的executor有100个,stage有10个,task有1000个。每个stage运行的时候,都有1000个task提交到executor上面去运行,平均每个executor有10个task。接下来问题来了,driver要频繁地跟executor上运行的1000个task进行通信。通信消息特别多,通信的频率特别高。运行完一个stage,接着运行下一个stage,又是频繁的通信。
在整个spark运行的生命周期内,都会频繁的去进行通信和调度。所有这一切通信和调度都是从你的本地机器上发出去的,和接收到的。这是最要人命的地方。你的本地机器,很可能在30分钟内(spark作业运行的周期内),进行频繁大量的网络通信。那么此时,你的本地机器的网络通信负载是非常非常高的。会导致你的本地机器的网卡流量会增!!!
你的本地机器的网卡流量激增,当然不是一件好事了。因为在一些大的公司里面,对每台机器的使用情况,都是有监控的。不会允许单个机器出现耗费大量网络带宽等等这种资源的情况。运维人员。可能对公司的网络,或者其他(你的机器还是一台虚拟机),对其他机器,都会有负面和恶劣的影响。
————————————————
实际上线了以后,在生产环境中,都得用yarn-cluster模式,去提交你的spark作业。yarn-cluster模式,就跟你的本地机器引起的网卡流量激增的问题,就没有关系了。也就是说,就算有问题,也应该是yarn运维团队和基础运维团队之间的事情了。使用了yarn-cluster模式以后,就不是你的本地机器运行Driver,进行task调度了。是yarn集群中,某个节点会运行driver进程,负责task调度。
————————————————
yarn-client和yarn-cluster的区别就在于,Driver是运行在本地客户端,它的AM只是作为一个Executor启动器,并没有Driver进程。
- yarn-client:
- 用于测试,因为driver运行在本地客户端,负责调度application,会与yarn集群产生超大量的网络通信。从而导致网卡流量激增。
- 好处是直接执行时,本地可以看到所有的log,方便调试。
- Application Master仅仅向YARN请求Executor,Client会和请求的Container通信来调度他们工作,也就是说Client不能离开。
- yarn-cluster:
- 生产环境使用, 因为driver运行在nodemanager上,没有网卡流量激增的问题。
- 缺点在于调试不方便,本地用spark-submit提价以后,看不到log,只能通过yarn application-logs application_id这种命令查看,很麻烦
- Driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,因而YARN-Cluster模式不适合运行交互类型的作业;
四. spark-submit 详细参数说明
spark-submit 可以提交任务到 spark 集群执行,也可以提交到 hadoop 的 yarn 集群执行。
spark-submit --class org.apache.spark.examples.SparkPi \ #作业类名 main函数
--master yarn \ #spark模式
--deploy-mode cluster \ #spark on yarn 模式
--driver-memory 4g \ #每一个driver的内存
--executor-memory 2g \ #每一个executor的内存
--executor-cores 1 \ #每一个executor占用的core数量
--queue thequeue \ #作业执行的队列
--conf spark.yarn.maxAppAttempts=0 \ #提交申请的最大尝试次数, 小于等于YARN配置中的全局最大尝试次数。
examples/jars/spark-examples*.jar \ #jar包
10 #传入类中所需要的参数
| 参数名 | 参数说明 |
| --master | master 的地址,提交任务到哪里执行,例如 spark://host:port, yarn, local |
| --deploy-mode | 在本地 (client) 启动 driver 或在 cluster 上启动,默认是 client |
| --class | 应用程序的主类,仅针对 java 或 scala 应用 |
| --name | 应用程序的名称 |
| --jars | 用逗号分隔的本地 jar 包,设置后,这些 jar 将包含在 driver 和 executor 的 classpath 下 |
| --packages | 包含在driver 和executor 的 classpath 中的 jar 的 maven 坐标 |
| --exclude-packages | 为了避免冲突 而指定不包含的 package |
| --repositories | 远程 repository |
| --conf PROP=VALUE | 指定 spark 配置属性的值, 例如 -conf spark.executor.extraJavaOptions="-XX:MaxPermSize=256m" |
| --properties-file | 加载的配置文件,默认为 conf/spark-defaults.conf |
| --driver-java-options | 传给 driver 的额外的 Java 选项 |
| --driver-library-path | 传给 driver 的额外的库路径 |
| --driver-class-path | 传给 driver 的额外的类路径 |
| --driver-cores | Driver 的核数,默认是1。在 yarn 或者 standalone 下使用 |
| --driver-memory | Driver内存,默认 1G,Driver 不做任何计算和存储,只是下发任务与yarn资源管理器和task交互,除非你是 spark-shell,否则一般 1-2g |
| --executor-memory | 每个 executor 的内存,默认是1G 线程内存:参考值4g-10g,最大不超过20G,否则会导致GC代价过高,或资源浪费严重。 num-executor * executor-memory不能超过队列最大内存,Spark作业申请到的总内存量(也就是所有Executor进程的内存总和),申请的资源最好不要超过最大内存的1/3-1/2 |
| --num-executors | 启动的 executor 数量。默认为2。在 yarn 下使用 线程数: 一般设置在50-100之间 ,不然默认启动的executor非常少,不能充分利用集群资源,运行速度慢 |
| --executor-cores | 每个 executor 的核数。在yarn或者standalone下使用 不宜为1!否则 work 进程中线程数过少,一般 2~4 为宜。 executor_cores * num_executors 表示的是能够并行执行Task的数目,不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。 |
| --queue | 指定了放在哪个队列里执行 |
3. 几个重要的参数说明:
一、参数可以通过提交spark-submit提交任务
--conf spark.dynamicAllocation.minExecutors=4 执行器最少数量
--conf spark.dynamicAllocation.maxExecutors=10 执行器最大数量
--conf spark.dynamicAllocation.initialExecutors=4 若动态分配为true,执行器的初始数量
--conf spark.executor.memoryOverhead=2g 堆外内存:处理大数据的时候,这里都会出现问题,导致spark作业反复崩溃,无法运行;此时就去调节这个参数,到至少1G(1024M),甚至说2G、4G)
--conf spark.speculation=true 推测执行:在接入kafaka的时候不能使用,需要考虑情景
--conf spark.shuffle.service.enabled=true 提升shuffle计算性能
二、参数可以通过spark_home/conf/spark-default.conf配置文件设置。
spark.master spark://master:7077
spark.default.parallelism 10
spark.driver.memory 2g
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.sql.shuffle.partitions 50