Google's BBR拥塞控制算法如何对抗丢包
分享一下我老师大神的人工智能教程!零基础,通俗易懂!http://blog.csdn.net/jiangjunshow
也欢迎大家转载本篇文章。分享知识,造福人民,实现我们中华民族伟大复兴!
在BBR之前,存在着两种拥塞控制算法,基于丢包的和基于时延的,不管哪一种都是基于探测的,换句话说,基于丢包的算法将丢包作为一种发现拥塞的手段,而基于时延的算法则是将时延增加作为发现拥塞的手段,它们之所以错误是因为它们的初衷就是错的:
丢包算法:
为了发现拥塞就不得不制造拥塞,这TMD的太JIBA讽刺了,为了戒毒,就必须先TMD的染上毒瘾!然而根本没毒瘾的话何谈戒毒!TCP之所以这么玩我觉得很大程度上”归功“于30多年前最初的关于拥塞控制的论文。在那个年代,和我们现在的网络完全不同,几乎很少的队列,由于存储器比较贵,所以路由器和交换机上几乎都没有太深的队列,甚至都是很浅的队列,在那种情况下,丢包确实表明了拥塞的信号,然而后来随着设备队列越来越深(摩尔定律使然),在丢包前,一个TCP连接必须不断的去填充非常深的队列,当深队列被填满后,是什么情况?是拥塞!我不得不再次重复解释时间延展性缓存和时间墙缓存的区别,对于前者,时间可以消耗掉任何数据包,然而对于后者,时间墙的存在则必然会发生拥塞,如果不明白这个基本区别的话,就会设计出错误的拥塞控制方案。不幸的是,TCP在30年来都没有对这两类缓存进行区分!同样的大小,二者的表现完全不同!
后面我把时间延展性缓存称作第一类缓存,时间墙缓存称作第二类缓存。只有当第二类缓存被填满的时候,算法才会发现拥塞,而此时,拥塞已经要开始缓解了!滞后性!
时延算法:
OK!我承认时延算法主动避免了第二类缓存的数据堆积(如果你意识不到这一点,请停止阅读。),然而由于丢包算法的存在,时延算法一直处在被压制的状态。想知道时延算法的问题,请自己百度,根本不需要google。
两类方法中的无论哪一类,都是傻逼鸡屎做法!拥塞的判断应该关注“congestion (queue buildup) starts to occur”,而不是“buffer full”!!!
所以说,这些算法都是错的!那么BBR就一定对吗?
近几日,从9月16号开始,BBR被炒作的沸沸扬扬,好像就是神一般,但事实会证明都JIBA扯淡,TCP拥塞控制领域本身就是一个无解的领域,现在用BBR撕CUBIC好像还比较得心应手,到头来来个RBB就可以跟BBR势均力敌了,带宽还是那么多,硬件资源就摆在那,大家要公平共享这才是王道,任由一家独大抢占别人的带宽还不告诉别人,这是傻逼。所以我说,TCP加速这个行当是个丑行。
BBR不是神,甚至不是人,但它...
BBR区分了两类缓存,并且发誓不再将第二类缓存作为BDP的计算,然而BBR有原则,它将坚持在max-BW和min-RTT处,任由其它的算法去抢那些第二类缓存吧,CAO!TCP的君子协定让那些别的算法发现第二类缓存填满后,会降速到不足以填充第一类缓存的地步,此时,BBR会说:这是你们出让给我的。
总结一点,BBR不去抢占没有意义的第二类缓存,这类缓存不光没有意义--不会增加速率,一旦填满后后还要付出代价而降速!BBR只要属于自己的。BBR会尽可能完全利用第一类缓存!
所以,我觉得BBR既不是基于丢包的算法,也不是基于时延的算法,而是一个基于反馈的算法!既然搞不定猜测,那就不猜测,BBR只基于现在,而不考虑历史(win_minmax表明其仅仅在意时间窗口内的历史!)!
BBR算法避免了填充第二类缓存,因此它的初衷就是避免拥塞-真正的cong_avoid!。
避免了拥塞,在Linux传统看来就是避免了丢包!BBR的收敛点在第二类缓存左边,因此不会因为拥塞而丢包,但是丢包分三类:
1.噪声丢包
2.拥塞被动丢包
3.流量监管主动丢包
BBR已经可以应对1和2(对于1,通过时间窗口可以过滤,对于2,算法本身的反馈收敛特性决定),那么对于3,BBR有何杀手锏呢?这就是BBR的long-term rate特性。
我先来展示一段关于BBR long-term的注释:
Token-bucket traffic policers are common (see "An Internet-Wide Analysis of Traffic Policing", SIGCOMM 2016). BBR detects token-bucket policers and explicitly
models their policed rate, to reduce unnecessary losses. We estimate that we're policed if we see 2 consecutive sampling intervals with consistent throughput
and high packet loss. If we think we're being policed, set lt_bw to the "long-term" average delivery rate from those 2 intervals.
我之前说过,BBR会基于即时测量的上一次发送带宽来计算这次该发送的速率和cwnd,好像BBR根本不会经历丢包一样!但这是不真实的!任何算法都不能忽略上述第3种丢包。没有拥塞,没有噪声,但就是丢包了,Why?因为路由器有权力决定任何数据包的丢失。几乎所有的路由器交换机里都会一个令牌桶!TCP流在路由器面前就是渣!虽然是渣渣,BBR还是可以发现路由器的这种丢包行为。
BBR在采集即时带宽的同时,还在默默观察丢包率。
如果BBR发现连续两个delivered周期(类似RTT,但是在拥塞或者被监管情形下,RTT会变化)内,TCP连接内满足两点,其一是吞吐速率恒定,其二是持有高丢包率,那说明什么?说明连接被中间设备限速或者流量整形了...除此之外,你还能想到发生了别的什么情况,如果你想到了,那你就可以自己做一个算法了。
我已经提示了,温州皮鞋老板们,搞起来!我有能力,但我不会去做,因为我对瞎子哲学嗤之以鼻!
TCP这部分的代码在哪里?请patch最新的BBR补丁,然后就可以探知究竟了。
现在是中午12点整,老婆出去上班了,丈母娘在厨房做饭,而我却在这里写这些乱七八糟的东西!CAO!我在玩火!我很想多说几句,但我不得不上代码了:
static void bbr_lt_bw_sampling(struct sock *sk, const struct rate_sample *rs)
{
...
}
...
我还是还是不想去分析源码。我在这里只讲逻辑。
TCP发送端如何检测到自己连接的流量受到了限速设备的流量监管呢?我仍以经典VJ拥塞模型图为例:
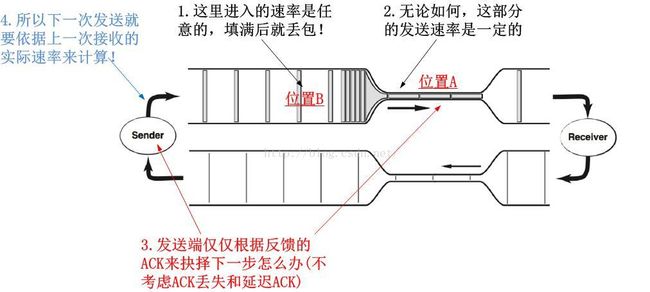
如图上所示,虽然由于发送端不断增加发送数据量或者别的连接增加了发送量,但是对于位置A而言,速率都是一定的,对于位置B而言,要么它是空的,要么它已经满了,这是TCP所察觉不到的!TCP唯一能做的是,按照反馈的ACK来进行发送速率的抉择!
这样的BBR可以避免第2类丢包,并且可以识别第1类丢包,但是对于第3类丢包无能为力,对于BBR而言,目前而言,第3类丢包的处理是最后要做的了。BBR处理第三类丢包的手段,非常简单,仅仅是记录丢包本身即可。当发生以下情况时,BBR认为网络Path上有流量监管或者限速:
1.持续一段时间保持高丢包率;
2.持续一段时间测量的当前带宽几乎一致。
当BBR检测到这种情况额时候,就不再用当前测量的带宽为计算Pacing Rate和cwnd的基准了,而是将这段时间内的平均测量带宽为基准!这个检测在最开始!
详细阅读bbr_lt_bw_sampling函数的代码,花上个十几分钟,就什么都懂了。BBR如此一来就相当于朴素地识别了流量监管设备的存在并且适配了它的速率!注意,这是一种朴素的算法,而不是什么可以让一群人噼里啪啦扯淡的算法!
靠这种long-term算法,BBR可以对抗监管设备的策略造成的丢包了。于此,BBR几乎可以检测到所有的丢包了:
1).如果收到重复ACK(重复ACK,SACKed数量,SACKed最高值...),虽然TCP核心认为发生了丢包,但是不会进入PRR,BBR会不屑一顾,继续自己的策略,参见BBR引擎说明书;
2).如果真的发生了拥塞,BBR在最小RTT周期之后会发现这是真的,虽然滞后,但总比CUBIC之类滞后发现第二类缓存被填满强多了。BBR不会盲目降速,而是依然根据检测到的max-BW来,除非max-BW已经非常小!
3).如果发生监管丢包,BBR会在一段比较长的周期内检测到,它发现在这个周期内持续持有比较高的丢包率(检测到的Lost计数器偏大),且速率保持一致,那么BBR会将发送量限制在实际带宽的平均值。
...
我一向对TCP是嗤之以鼻的,就像我对SSL/TLS协议嗤之以鼻一样,于工作,我持续七年先后与SSL,TCP打交道,并且有时候还做的不错,于私下,我呻吟着在诅咒中夹杂着叫骂,希望尽快结束这个丑行。每当我想到这些的时候,我甚至都有摔电脑的冲动,然而很多人会有疑问,我既然如此恶心这些,还为何分析它们,还为何如此上心...
我的求助开始了!
你有更好玩的东西吗?昨晚我看了将TLS offload到网卡的一个演讲,瞬间有了兴趣,可是我不可能去搞什么硬件,在后半夜又幸运的发现了一个KTLS的方案,我特别想今天把这个完成,然而作罢了,因为我没有时间!(我曾经不还吐槽过OpenSSL吗?是的,其实别人也有人吐槽,但人家改造了世界,实现额KTLS,而我,就是个傻逼!即便我是个傻逼,我也将OpenVPN移植到了内核,你呢?!)
TCP本身就是渣!这个渣渣玷污了IP网络的伟大,破坏了IP网络的简单,就想一碗拉面里的鸡屎一样!我希望,我希望呻吟着,呻吟着殴打所有与TCP相关的公司的老板,或者说,仅仅是咒骂!
给我老师的人工智能教程打call!http://blog.csdn.net/jiangjunshow

新的改变
我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客:
- 全新的界面设计 ,将会带来全新的写作体验;
- 在创作中心设置你喜爱的代码高亮样式,Markdown 将代码片显示选择的高亮样式 进行展示;
- 增加了 图片拖拽 功能,你可以将本地的图片直接拖拽到编辑区域直接展示;
- 全新的 KaTeX数学公式 语法;
- 增加了支持甘特图的mermaid语法1 功能;
- 增加了 多屏幕编辑 Markdown文章功能;
- 增加了 焦点写作模式、预览模式、简洁写作模式、左右区域同步滚轮设置 等功能,功能按钮位于编辑区域与预览区域中间;
- 增加了 检查列表 功能。
功能快捷键
撤销:Ctrl/Command + Z
重做:Ctrl/Command + Y
加粗:Ctrl/Command + B
斜体:Ctrl/Command + I
标题:Ctrl/Command + Shift + H
无序列表:Ctrl/Command + Shift + U
有序列表:Ctrl/Command + Shift + O
检查列表:Ctrl/Command + Shift + C
插入代码:Ctrl/Command + Shift + K
插入链接:Ctrl/Command + Shift + L
插入图片:Ctrl/Command + Shift + G
合理的创建标题,有助于目录的生成
直接输入1次#,并按下space后,将生成1级标题。
输入2次#,并按下space后,将生成2级标题。
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
如何改变文本的样式
强调文本 强调文本
加粗文本 加粗文本
标记文本
删除文本
引用文本
H2O is是液体。
210 运算结果是 1024.
插入链接与图片
链接: link.
图片: 
带尺寸的图片:
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
如何插入一段漂亮的代码片
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的 代码片.
// An highlighted block var foo = 'bar'; 生成一个适合你的列表
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' |
‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" |
“Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash |
– is en-dash, — is em-dash |
创建一个自定义列表
-
Markdown
- Text-to- HTML conversion tool Authors
- John
- Luke
如何创建一个注脚
一个具有注脚的文本。2
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
你可以找到更多关于的信息 LaTeX 数学表达式here.
新的甘特图功能,丰富你的文章
gantt
dateFormat YYYY-MM-DD
title Adding GANTT diagram functionality to mermaid
section 现有任务
已完成 :done, des1, 2014-01-06,2014-01-08
进行中 :active, des2, 2014-01-09, 3d
计划一 : des3, after des2, 5d
计划二 : des4, after des3, 5d
- 关于 甘特图 语法,参考 这儿,
UML 图表
可以使用UML图表进行渲染。 Mermaid. 例如下面产生的一个序列图::
这将产生一个流程图。:
- 关于 Mermaid 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
- 关于 Flowchart流程图 语法,参考 这儿.
导出与导入
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件或者.html文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。
mermaid语法说明 ↩︎
注脚的解释 ↩︎