详解RocketMQ不同类型的消费者push/pull
转载:https://blog.csdn.net/eo63y6pKI42Ilxr/article/details/80780513
云栖君导读:本文节选自云栖社区系列丛书《RocketMQ原理与实战解析》,作者:阿里巴巴数据专家杨开元。本节将重点讲解RocketMQ不同类型的消费者。
根据使用者对读取操作的控制情况,分为两种类型。一个是DefaultMQPushConsumer,由系统控制读取操作,收到消息后自动调用传入的处理方法来处理;另一个是DefaultMQPullConsumer,读取操作中的大部分功能由使用者自主控制。
1.1.1 DefaultMQPushConsumer的使用
使用DefaultMQPushConsumer主要是设置好各种参数和传入处理消息的函数。系统收到消息后自动调用处理函数来处理消息,自动保存Offset,而且加入新的DefaultMQPushConsumer后会自动做负载均衡。下面结合org.apache.rocketmq.example.quickstart包中的源码来介绍。
代码清单1-1 DefaultMQPushConsumer示例
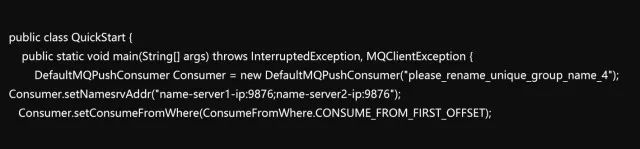
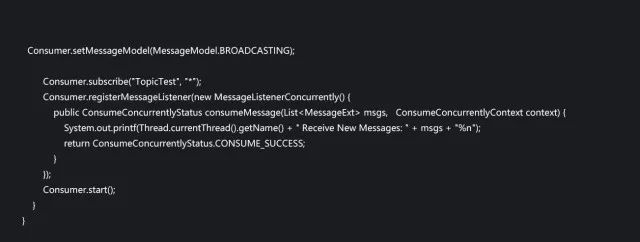
DefaultMQPushConsumer需要设置三个参数:一是这个Consumer的GroupName,二是NameServer的地址和端口号,三是Topic的名称,下面详细介绍。
Consumer的GroupName用于把多个Consumer组织到一起,提高并发处理能力,GroupName需要和消息模式(MessageModel)配合使用。
RocketMQ支持两种消息模式:Clustering 和 Broadcasting。
-
在Clustering 模式下,同一个ConsumerGroup(GroupName相同)里的每个Consumer只消费所订阅消息的一部分内容,同一个ConsumerGroup里所有的Consumer消费的内容合起来才是所订阅Topic内容的整体,从而达到负载均衡的目的。
-
在Broadcasting模式下,同一个ConsumerGroup里的每个Consumer都能消费到所订阅Topic的全部消息,也就是一个消息会被多次分发,被多个Consumer消费。
NameServer的地址和端口号,可以填写多个,用分号隔开,达到消除单点故障的目的,比如 “ip1:port;ip2:port;ip3:port”。
Topic名称用来标识消息类型,需要提前创建。如果不需要消费某个Topic下的所有消息,可以通过指定消息的Tag进行消息过滤,比如:Consumer.subscribe("TopicTest", "tag1 || tag2 || tag3"),表示这个Consumer要消费“TopicTest”下带有tag1或tag2或tag3的消息(Tag是在发送消息时设置的标签)。在填写Tag参数的位置,用null或者“*”表示要消费这个Topic的所有消息。
1.1.2 DefaultMQPushConsumer的处理流程
本节通过分析源码来说明DefaultMQPushConsumer的处理流程。
DefaultMQPushConsumer主要功能实现在DefaultMQPushConsumerImpl类中,消息的处理逻辑是在pullMessage这个函数里的PullCallBack中。在PullCallBack函数里有个switch语句,根据从Broker返回的消息类型做相应的处理,具体处理逻辑可以查看源码。
代码清单1-2 DefaultMQPushConsuer的处理逻辑
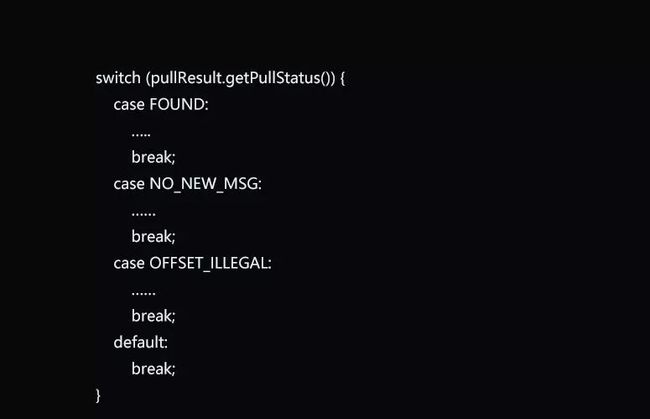
DefaultMQPushConsuer的源码中有很多PullRequest语句,比如DefaultMQPushConsumerImpl.this.executePullRequestImmediately(pullRequest),为什么“PushConsumer”中使用“PullRequest”呢?这是通过“长轮询”方式达到Push效果的方法,长轮询方式既有Pull的优点,又兼具Push方式的实时性。
Push方式是Server端接收到消息后,主动把消息推送给Client端,实时性高。对于一个提供队列服务的Server来说,用Push方式主动推送有很多弊端;首先是加大Server端的工作量,进而影响Server的性能,其次Client的处理能力各不相同,Client的状态不受Server控制,如果Client不能及时处理Server推送过来的消息,会造成各种潜在问题。
Pull方式是Client端循环地从Server端拉取消息,主动权在Client手里,自己拉取到一定量消息后,处理妥当了再接着取。Pull方式的问题是循环拉取消息的间隔不好设定,间隔太短就处在一个“忙等”的状态,浪费资源;每个Pull的时间间隔太长,Server端有消息到来有可能没有被及时处理。
“长轮询”方式是通过Client端和Server端的配合,既拥有Pull的优点,又能达到保证实时性的目的。我们结合源码来分析:
代码清单1- 3 发送Pull消息代码片段

源码中有这一行设置语句
requestHeader.setSuspendTimeoutMillis(brokerSuspendMaxTimeMillis),设置Broker最长阻塞时间,默认设置是15秒,注意是Broker在没有新消息的时候才阻塞,有消息会立刻返回。
从Broker的源码中可以看出,服务端接到新消息请求后,如果队列里没有新消息,并不急于返回,通过一个循环不断查看状态,每次 waitForRunning一段时候(默认是5秒),然后后再Check。默认情况下当Broker一直没有新消息,第三次Check的时候,等待时间超过Request里面的 BrokerSuspendMaxTimeMillis,就返回空结果。在等待的过程中,Broker收到了新的消息后会直接调用notifyMessageArriving函数返回请求结果。“长轮询”的核心是,Broker端HOLD住客户端过来的请求一小段时间,在这个时间内有新消息到达,就利用现有的连接立刻返回消息给Consumer。“长轮询”的主动权还是掌握在Consumer手中,Broker即使有大量消息积压,也不会主动推送给Consumer。
长轮询方式的局限性,是在HOLD住Consumer请求的时候需要占用资源,它适合用在消息队列这种客户端连接数可控的场景中。
1.1.3 DefaultMQPullConsumer
使用DefaultMQPullConsumer像使用DefaultMQPushConsumer一样需要设置各种参数,写处理消息的函数,同时还需要做额外的事情。接下来结合org.apache.rocketmq.example.simple包中的例子源码来介绍。
示例代码的处理逻辑是逐个读取某Topic下所有Message Queue的内容,读完一遍后退出,主要处理额外的三件事情:
(1) 获取Message Queue并遍历
一个Topic包括多个Message Queue,如果这个Consumer需要获取Topic下所有的消息,就要遍历多有的Message Queue。如果有特殊情况,也可以选择某些特定的Message Queue来读取消息。
(2) 维护Offsetstore
从一个Message Queue里拉取消息的时候,要传入Offset参数(long类型的值),随着不断读取消息,Offset会不断增长。这个时候由用户负责把Offset存储下来,根据具体情况可以存到内存里、写到磁盘或者数据库里等。
(3) 根据不同的消息状态做不同的处理
拉取消息的请求发出后,会返回:FOUND,NO_MATCHED_MSG,NO_NEW_MSG,OFFSET_ILLEGAL四种状态,要根据每个状态做不同的处理。比较重要的两个状态是FOUNT和NO_NEW_MSG,分别表示获取到消息和没有新的消息
实际情况中可以把while(true)放到外层,达到无限循环的目的。因为PullConsumer需要用户自己处理遍历Message Queue、保存Offset,所以PullConsumer有更多的自主性和灵活性。
----------------
本文节选自云栖社区系列丛书《RocketMQ原理与实战解析》,点击左下角【阅读原文】进入赢取图书!
