十分钟学会开发自己的Python AI应用【OpenAI API篇】
最近 OpenAI 宣布 ChatGPT 将很快推出他们的 API。虽然我们不知道这需要多长时间,但这之前我们可以熟悉下OpenAI API,快速开发自己的AI应用!
通过今天学习 OpenAI API,你将能够访问 OpenAI 的强大模型,例如用于自然语言的 GPT-3、用于将自然语言翻译为代码的 Codex 以及用于创建和编辑原始图像的 DALL-E。
这篇文章的例子将用Pyhon编写。
生成 API 密钥
在我们开始使用 OpenAI API 之前,我们需要登录我们的 OpenAI 帐户并生成我们的API 密钥。
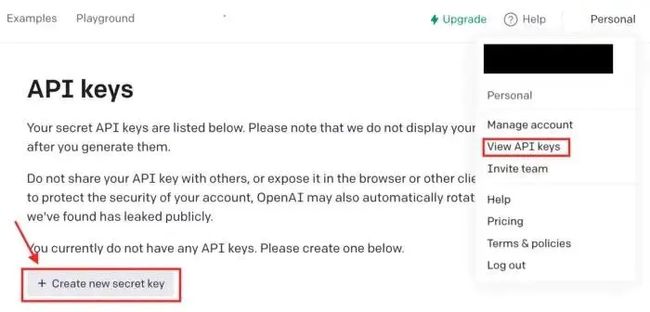
这里要注意,OpenAI 不会在生成 API 密钥后再次显示它,因此请及时复制你的 API 密钥并保存。我将创建一个名为 OPENAI_API_KEY 的环境变量,它将包含我的 API 密钥并将在下一节中使用。
使用 Python接入 OpenAI API
要与 OpenAI API 交互,我们需要通过运行以下命令来安装官方OpenAI包。
pip install openai
如果出现此类错误,大概率是该虚拟环境的配置文件中和安装openai配置文件存在冲突,所以最稳妥的解决办法创建一个新的虚拟环境专门用于openai

1.文本生成
文本生成可用于文字鉴别、文本生成、自动对话、转换、摘要等。要使用它,我们必须使用completion endpoint并为模型提供触发指令,然后模型将生成匹配上下文/模式的文本。
假设我们要对以下文本进行鉴别,我们向AI输入指令(中英文都可以):
判断以下Mike的发言情绪是正面、中立还是负面: Mike:我不喜欢做作业! Sentiment:
以下就是用到的代码:
import os import openai
openai.api_key = os.getenv("OPENAI_API_KEY") prompt = """
Decide whether a Mike's sentiment is positive, neutral, or negative.
Mike: I don't like homework!
Sentiment:
"""
response = openai.Completion.create( model="text-davinci-003", prompt=prompt, max_tokens=100, temperature=0 ) print(response)根据 OpenAI 文档,GPT-3 模型是与文本生成的endpoint一起使用。 这就是我们在此示例中使用模型 text-davinci-003 的原因。
以下是返回值的部分打印:
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": "Negative"
}
],
...
}在此示例中,推文的情绪被归类为负面Negative。
让我们看一下这个例子中使用的参数:
model :要使用的模型的 ID(在这里你可以看到所有可用的模型)
Prompt:生成结果的触发指令
max_token:完成时生成的最大token数量(这里可以看到OpenAI使用的tokenizer)
temperature:要使用的采样策略。 接近 1 的值会给模型带来更多风险/创造力,而接近 0 的值会生成明确定义的答案。
2. 代码生成
代码生成与文本生成类似,但这里我们使用 Codex 模型来理解和生成代码。
Codex 模型系列是经过自然语言和数十亿行代码训练的 GPT-3 系列的后代。 借助 Codex,我们可以将注释转化为代码、重写代码以提高效率等等。
让我们使用模型 code-davinci-002 和下面的触发指令生成 Python 代码。
代码生成一个序列,内容包含上海的温度。
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.Completion.create(
model="code-davinci-002",
prompt="\"\"\"\nCreate an array of weather temperatures for Shanghai\n\"\"\"",
temperature=0,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
print(response)以下是返回值的部分打印:
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": "\n\nimport numpy as np\n\ndef create_temperatures(n):\n \"\"\"\n Create an array of weather temperatures for Shanghai\n \"\"\"\n temperatures = np.random.uniform(low=14.0, high=20.0, size=n)\n return temperatures"
}
],
...
}
}把text部分重新显示格式化一下,你就会看到规整的代码生成了:
import numpy as np
def create_temperatures(n):
temperatures = np.random.uniform(low=14.0, high=20.0, size=n)
return temperatures如果想开发更多,我建议你在 Playground 中测试 Codex(这里有一些帮助你入门的示例)
3. 图像生成
我们可以使用 DALL-E 模型生成图像,我们使用图像生成endpoint并提供文本指令。
以下是我的测试指令(我们在指令中提供的细节越多,我们就越有可能获得我们想要的结果)。
一只毛茸茸的蓝眼睛白猫坐在花篮里,可爱地抬头看着镜头
import openai
response = openai.Image.create(
prompt="A fluffy white cat with blue eyes sitting in a basket of flowers, looking up adorably at the camera",
n=1,
size="1024x1024"
)
image_url = response['data'][0]['url']
print(image_url)以下是我得到的图片:

当然更有趣的是,还可以使用image edits and image variations endpoints编辑图像并生成原图像的调整。
参考链接:https://www.jianshu.com/p/acbcb4e6db5c