计算机网络
目录
OSI七层模型
目的
各层的作用
应用层
表示层
会话层
传输层
网络层
数据链路层
物理层
数据流通过程
TCP三次握手与四次挥手
TCP慢启动
握手之前
三次握手
握手后
四次挥手
IPv4地址
子网掩码
IPv6
IP地址分类:
IPv4与IPv6的区别:
边界网关协议BGP
HTTP
请求报文:
响应报文
HTTP缓存
HTTP缓存的工作原理
HTTP与缓存有关的首部
HTTPS
SSL与TLS
对称加密
非对称加密
SSL证书
TLS握手过程
TLS1.2与TLS1.3的区别
HTTP1.1、 HTTP2、 HTTP3的区别
HTTP1.1
HTTP2
HTTP3
DNS域名解析过程
DNS域名解析过程 === 域名转换为IP地址
域名是一个结构树
域名服务器
内容分发网络CDN
分发内容
分发流程——静态内容
分发流程——动态内容
安全性和可靠性
CDN也被当做加速器 / 加速方法
CDN减少费用
在浏览器输入URL回车后发生什么
浏览器渲染页面流程
Cookie、Session、Token的区别
Cookie
Session 会话
Token JWT(JSON Web Token)
跨域解决办法
XSS网络攻击
WebSockets
DDoS攻击
内容整理自:技术蛋老师的个人空间_哔哩哔哩_bilibili
OSI七层模型
只是作为参考,实际上不一定都用到7层。而TCP/IP本来只有4层,后来发现划分为5层更符合实际

目的
--解决主机之间的网络通信
各层的作用
应用层
作用:两个应用如何进行交互。最接近用户的一层
本质:在逻辑上将2个应用进行连通。实际物理上的联通是通过物理层实现的
协议:http编写应用程序,使应用之间实现沟通。
表示层
作用:不同计算机内部的各自表达方式不同,表示层进行这样的转换,编码和解码,数据加密(HTTPS SSL TLS),给文件压缩
会话层
作用:网站服务可以保存登录状态,还会管理和控制登录状态。负责同步服务(比如视频关掉后会自动跳到上一次播放的位置继续播放)。
传输层
数据名称:段。
作用:接收端可能同时运行多个软件进程,为了让数据去到指定的软件服务上,需要端口号作为地址进行定位。实现了服务进程到服务进程的传输。管理两个节点之间数据的传输,负责可靠传输(TCP:允许字节流将数据变成多个段,而不是整个字节数据完整的发出去)和不可靠传输(UDP)
流量控制:保证传输速度
错误控制:保证数据的完整接受
网络层
数据名称:包。可以被封装成二次帧。发送端IP数据报封装成帧,接收端解封装。
作用:互联网只用MAC地址座位唯一的寻址方式是不够的,需要IP地址进行寻址,还需要路由选择。IP地址实现端到端的基础。
路由器:是网络层的核心。路由器根据包里的IP地址进行路由转发。地址管理和路由选择就是这一层的核心。
数据链路层
数据名称:帧。数据链路层将比特封装成帧,封装时加上MAC地址(物理地址)。
作用:信号去到哪台设备是需要定向的,需要高级一点的网络模型。为了通过MAC地址对不同设备进行数据传输,就需要用到二层交换机(发送端A发送数据给交换机时,交换机知道了A的MAC地址,如果交换机也知道接收端B的MAC地址,交换机就可以将A的数据传给B)。物理地址是跳到跳传输
物理层
数据名称:比特。发送出去的数据在计算机内部是0或1的码(称之为比特)。
作用:物理层将这些比特用不同的媒介(电,光,其他形式的电磁波...)传输出去,数据从网络接口出去后,经过不同的网络拓扑,需要中继器、集线器等设备
差错检测+差错纠正:传输时可能会将0变成1,1变成0
流控制:避免信息传输的不对称(发送端大批量发送数据,而接收端只是“夹缝式”接收)
数据流通过程
客户端发送数据,也就是报文,报文来到传输层,加上端口号,封装成段。
段来到网络层,加上IP地址封装成包,这里的包含有目标IP地址。由于目标IP地址不是同一个网络下的,要发送到其他的网络,需要经过默认网关。
客户端主机最初不知道默认网关(客户端网关)的MAC地址,没办法封装成帧,就需要用ARP协议进行广播,找到网关IP对应的MAC地址,把包封装成帧,源MAC地址填自己的,目标MAC地址填广播地址。如果此时有二层交换机,交换机只用记录下不同接口对应的MAC地址即可,交换机收到广播后就帮忙发出去。默认网关收到交换机发送的消息后,查看了帧,发现了发送端的MAC地址,解封后发现包里的IP地址,将客户端的MAC地址与IP地址关联为一台主机。同时,默认网关将自己的IP地址放入包内,结合自己的MAC地址封装成帧,将帧响应出去原路返回,发送端就知道默认网关的MAC地址。
客户端封装成帧并发送数据,比特流到默认网关时,解封为帧,发现是发送给自己的,再解封包看到目标IP地址是在另一网络中的,就进行路由转发,最终到达目的网络。
如果目标网管知道目标IP地址和MAC是哪台主机,封装成帧就直接发出去给服务器,如果不知道就还是用ARP协议进行广播。
目标主机收到包,确认是自己IP地址后,解封包查看发现源和目标端口号,用目标端口号给指定的应用程序。
应用程序处理好后,按照源的信息作出相响应。
响应发回去的原理也是同上。
TCP三次握手与四次挥手
TCP慢启动
要进行堵塞控制,也不知道网络的情况,一开始发送较小量的TCP数据段,后面在慢慢增加,会导致新访问页面刷新速度较慢
握手之前
客户端和服务端都有IP地址,可以取得联系,但各自有自己的应用进程,都可能需要TCP连接。
除了IP地址,还需要端口号,才能区分应用进程。服务端会自动加上端口号443,用到HTTPS协议。
握手前的核心条件 =》套接字socket = IP地址 :端口号
传输层位于OSI七层模型中间,承上启下。就干从端到端建立联系。
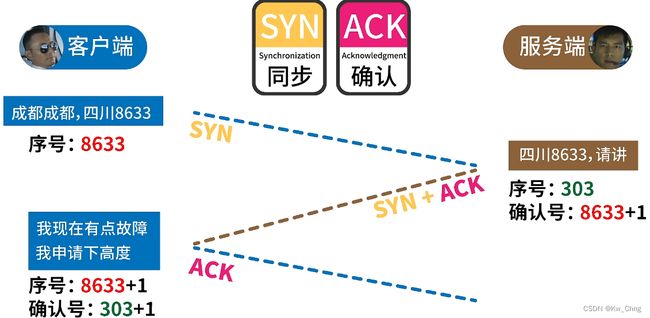
三次握手
TCP报文里有SYN(同步)、ACK、FIN等标识,设置1就开启标识,设置0就关闭标识。
- 客户端发送TCP报文给服务器:开启SYN,表示客户端想和服务端进行数据同步,还需要发送序号(Sequence,随机生成的,作为初始值进行后续判断依据,保证通道的唯一性),因为应用程序可能连续发送多个序号给服务器,服务器可以判断哪些信息是重复发送的
- 服务器开启SYN和ACK:ACK表示确认,服务器也生成自己的序号、确认号(确认号 = 客户端的序号 + 1,客户端将接收到的确认号-1就知道是不是自己发送的TCP报文)
- 客户端进行确认:服务器不知道自己发送的确认同步是否被客户端接收,所以需要客户端发送再次发送TCP报文正式建立二者的连接。开启ACK,此时客户端的序号 = 原客户端序号 + 1,并发送此时的确认号(确认号 = 服务器发过来的序号 + 1,这样传给服务器的时候,服务器就知道是不是发给自己的了)
服务器每次都要新生成并记住自己序号的话就会挂起很多资源,如果有黑客不断发送SYN又不进行下一步操作,服务器就会原地崩溃即DDoS攻击,于是服务器不保存自己的序号,而是根据服务器的IP地址和端口号等私有信息通过算法得到序号
握手后
客户端和服务器成功建立连接,可以发送HTTP请求,服务器响应内容
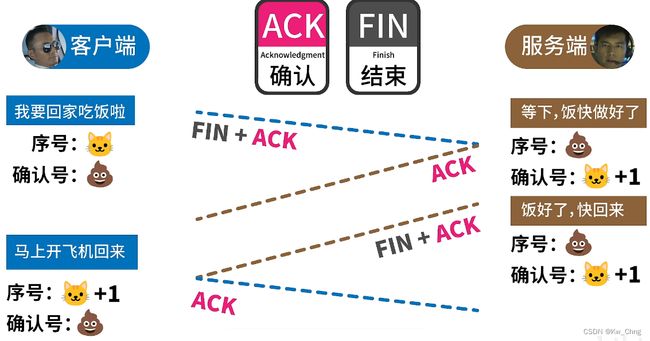
四次挥手
客户端和服务器的内容交流完毕,需要关闭二者的连接。客户端和服务器都可以主动发出关闭连接的请求。
以下假设客户端主动发起关闭二者连接的请求:
- 客户端向服务器发送TCP报文,开启FIN(结束)和ACK(确认),并发送自己的序号和确认号
- 服务器接收到后,将客户端确认号作为自己的序号,将自己的确认号 = 客户端序号 + 1,并开启ACK发给客户端
- 此时客户端还有没有正式关闭通道,因为服务器可能还有需要发送过来的消息,等服务器发送完数据之后,在发送FIN + ACK来进行最后的确认,此时服务器的序号和确认号并不需要改变(因为没有一来一回的交流)
- 客户端接收到服务器的最终结束确认后,发送ACK进行最后的确认,此时客户端序号 = 服务器序号 + 1,客户端确认号 = 服务器序号
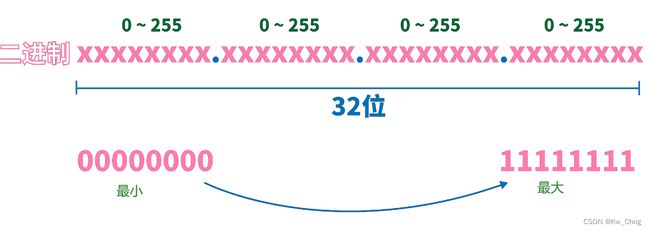
IPv4地址
IP地址的底层是二进制的,由4组8位二进制组成。
IP地址 = 网络号 + 主机号
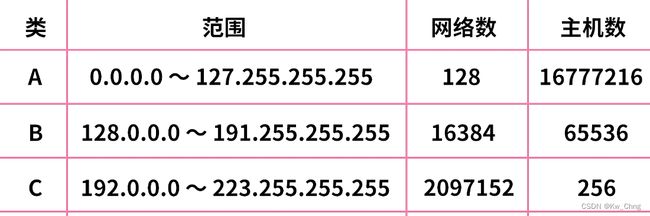
IP地址的分类:(D、E是特殊类)
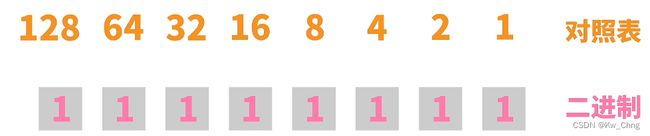
记住这个规律,就可以随便将十进制转换成二进制啦
子网掩码
目的:为了解决简单分类导致的IP分配不合理,比如一个地方分类了256个但实际需要更多,一个地方分了256个但实际只需要1个
作用:划分网络号和主机号

将十进制IP地址转换成二进制后,进行锁定和不锁定,就可以将完成锁定后的二进制转换成十进制,得到的就是子网掩码:

如何判断一个IP地址和其他IP地址是不是同一个网络的:将IP地址的每一组转换成二进制,看锁定的位置长度是不是一样,一样就是同一个网络

将IP地址和子网掩码放在一起,就知道网络号和主机号的额界限在哪里了:

可以用CIDR方法表示子网掩码:子网掩码的二进制有几个1,就写成IP地址/子网掩码1的数量。注意!IP地址最后一位用起始的0表示

例子:通过IP地址和子网掩码判断主机部分和网络部分

IPv6
IPv4结合CIDR和NAT可以解决大量IP地址不够的问题。
IPv6底层也是二进制,增加至128位,也就是8组16位二进制。而且分割每一组是用冒号,而不是点。
IPv6 = 网络部分(前64bit)+ 接口ID(后64bit)

由于将二进制转换为十进制,数字太大,所以采用十六进制。


IPv6存在类似CIDR的写法:

64是十进制,表明前面连续64位二进制数组成前缀, 即网络部分
缩写:
- 将每一组前面的0去掉
- 连续的0所在地方写成双冒号
例1:

例2:

但是这种写法就不知道到底省略的是几组0了,所以省前不省后,写成下面的形式:
![]()
IP地址分类:

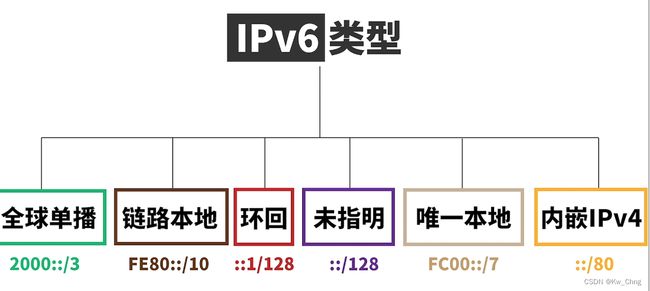
全球单播: 类似共有地址,可以被路由器转发,以2或3开头(因为规定前3个bit位001)
IPv4与IPv6的区别:
IPv6无子网掩码

IPv4与IPv6的安全性:未知
边界网关协议BGP
自治系统使用BGP规则进行数据的流通。需要手动配置。
分类:

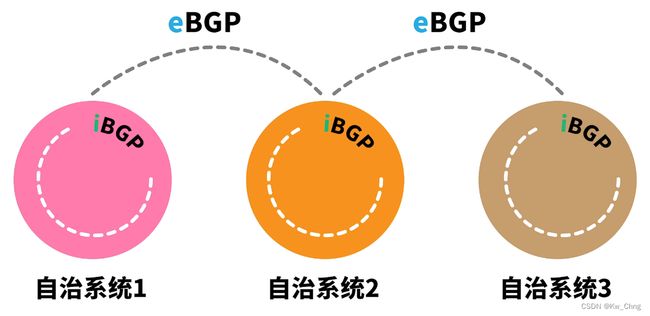
eBGP和iBGP的区别:
- iBGP从eBGP得到的自治系统路径是不会更新或修改的,只能eBGP更新或修改
- eBGP之间不需要全互联,iBGP需要全互联
使用的协议:TCP协议,179端口
两个BGP会话是有4种基本报文类型:

两个BGP会话是有6种状态:

BGP核心:
选择最优路径。涉及到的5个重要属性:

HTTP
客户端是主动型选手,服务器是被动型选手,服务器要等客户端发送请求了才能作出响应。在进行数据交流时,客户端要发送请求报文给服务器,服务器要发响应报文给客户端。HTTP规定了请求报文和相应报文的格式。
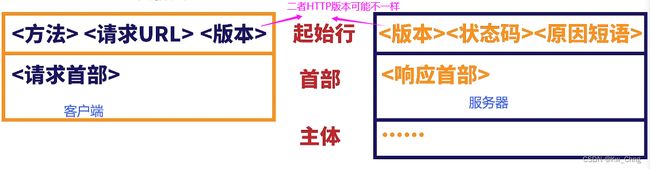
请求报文:
- 请求行:包含请求方法,请求地址,HTTP协议版本等
- 请求头:与浏览器有关的信息,键值对形式,空行表示请求头结束
- 请求数据:具体需要的数据,获取数据的形式
响应报文
格式与请求报文类似
- 状态行:状态码
- 响应头部:键值对形式,空行表示响应头结束
- 响应数据
GET请求只是简单的获取数据,可以没有主体
首部最后一行是空行,表示首部的结束
HTTP支持传输任意类型的内容
方法:
- GET:获取
- POST:传输提交数据
状态码:
- 服务端可以自行创建状态码
- 1开头表示接受的请求处理中
- 2开头表示成功,200表示正常被处理,201表示已创建用户,204表示无内容返回
- 3开头表示重定向,会让浏览器执行某些特别的处理,304表示可以使用缓存的内容,301表示数据被永久移到其他地方,302表示数据被临时移到其他地方,
- 4开头表示客户端错误,404表示被服务器拒绝or找不到请求的资源,400表示语法请求服务器无法理解,401表示身份认证查无此人,403表示拒绝客户端的请求,409表示请求冲突(可能是版本问题)
- 5开头表示服务端错误,500表示服务器内部发生错误或故障,502表示代理网关错误,503表示服务器超载或维护
响应首部:
1、content-type内容类型
每当客户端发送请求后,服务器会返回各种不同的数据类型,比如文件、图片、音视频等,浏览器能根据这个内容类型去处理不同类型的数据
请求首部:
1、Connection:close
客户端不需要发送请求时发送,进行关闭连接
报文发送形式:
在TCP/IP模式下,应用层浏览器根据用户输入的网址,分析出服务器地址和资源位置
对于HTTP,重要的是传输层,传输层协议配合HTTP所定义的传输数据的方式,也就是从传输层中选择协议,TCP或UDP,绝大部分HTTP用的是TCP,因为TCP是可靠传输,UDP是不可靠传输
在HTTP1.1中,默认为持久连接,客户端可以一直发送请求,没有请求要发送时就发送Connection:close首部给服务器
HTTP无状态:服务器不会把每次请求都记录下来。可以用cookie,需要在首部加上cookie信息实现保持登录、状态管理
HTTP缓存
目的:为了重复使用被存储的信息
好处:
- 减少服务器和客户端之间的通信次数
- 降低网络延迟
- 加速页面加载
- 提高用户体验
缓存类型:
1、浏览器缓存
本地存储
2、代理缓存
代理服务器在客户端和服务器之间,备份源服务器的资源作为缓存,客户端可以获取代理服务器的数据
3、数据库缓存
数据库操作有增删改查,数据库缓存可以减缓数据库重复资源的操作
HTTP缓存的工作原理
请求资源时,看看缓存里有没有,没有则向服务器获取,有则查看缓存是否过期
查看缓存没过期 =》使用,过期 =》与服务器进行验证
服务器告知没有过期 =》使用缓存,服务器告知过期 =》服务器返回新的资源作为新的缓存
HTTP与缓存有关的首部
1、Pragma(逐渐被抛弃)
2、Cache-Control
(1)max-age:资源保存为缓存的最长时间,单位秒
资源长期不需要改变的时候,浏览器存储、CDN都可以做到
(2)no-cache:资源可以进行缓存,但是每次使用前都要和服务器确认,代理服务器不可以对该资源进行缓存
一般html这种网页框架不会经常改变的就可以这样设置,如果想长期不变也只是发送体积量很小的信息与服务器进行确认
(3)no-store:让浏览器不要缓存,每次都要向服务器发送请求
(4)private:资源只能给当前的浏览器缓存,其他任何代理服务器都不可以缓存
(5)public:浏览器和代理服务器都可以缓存
3、etag:每次资源更新后,新的etag也会被服务器更新
4、表示缓存时间
由于浏览器和服务器的时间可能不同步,通常二者配合使用
(1)Expires:缓存的过期时间
未达到过期时间的资源都可以用,也不会向服务器要求更新资源
(2)Last-modified:资源最后修改时间
客户端发送请求之前检查一下修改资源的时间是否一致,时间一致就表示资源未修改,时间不一致就要向服务器发请求
HTTPS
HTTP请求和响应的报文都是明文的,不太安全
HTTPS = HTTP + TLS/SSL加密
SSL与TLS
SSL是TLS的前身,目前绝大部分浏览器都支持TLS
对称加密
加密和解密用的是同一种算法

如果第三方知道这个加密规则,就很麻烦了
非对称加密
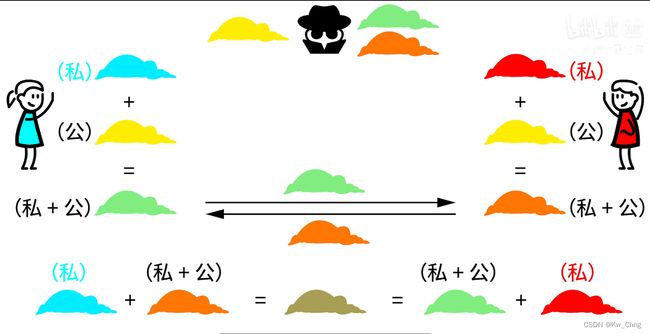
用两个密钥进行加密和解密,其中一个是公开密钥,另一个是持有方的私有密钥,一般放在服务器里。数据经过公钥加密只能被私钥解密,经过私钥加密只能被公钥解密
服务端拥有成对的私钥和公钥,只公布公钥给客户端,客户端用公钥给自己的数据加密,加密后公钥没法对这个数据解密,只有服务端的私钥才可以解密
SSL证书
保存在源服务器的数据文件,要让这个证书生效,就需要向CA(证书授权中心)申请。
这个证书包含公钥,服务器申请到这个证书后,客户端就可以通过HTTPS访问服务器了
TLS握手过程
先非对称加密,后对称加密,会话密钥只用在当前会话

TLS1.2与TLS1.3的区别
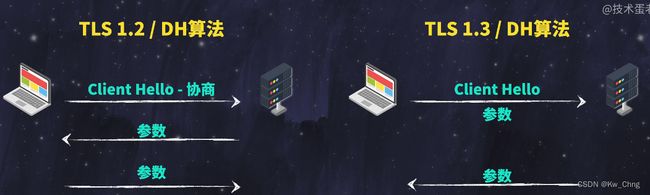
TLS1.2有2个核心算法:RSA,DH
使用RSA进行密钥交换,服务器有成对的公钥和私钥,公钥加密后只有私钥能打开,加密后公钥也无法打开 =》公钥加密,私钥解密的原理
使用DN进行交换,双方都有私钥,必须提供自己的协商参数给对方,接收到对方的协商参数后,双方用自己的私钥和对方的参数算出同一个密钥
TLS1.3
支持3种密钥交换模式
协议+ 对称加密+ 哈希


HTTP1.1、 HTTP2、 HTTP3的区别
安全性:HTTP3 > HTTP2 > HTTP1.1
报文的压缩:HTTP1.1只压缩报文主体,HTTP2压缩报文主体和首部
数据帧所在层:HTTP2在应用层,HTTP3在传输层

HTTP1.1
1、第一个标准意义上的HTTP协议
2、传输数据的方式是一次一份 =》客户端发送HTTP请求后需要等到收到HTTP响应,才可以发送下一个HTTP请求

3、HTTP队头阻塞:只要有一次请求没有获取响应,后面的请求就没法进行下去了。或者在允许多个连接时,只要有一个连接没收到,都会造成队头堵塞
4、默认持久连接keep-alive =》保持TCP连接,不需要对每个请求再进行TCP三次握手,请求和响应都可以放在同一个连接里
5、一个一个请求的连接方式太慢,连接过多容易DDos攻击,各个浏览器允许的持久连接数也不同
6、管线化技术:单个链接可以发多次请求,缺点是响应的顺序必须按照发送请求的顺序,造成执行难度大。解决方案:①雪碧图(精灵图),②Data URLs:图片用base64编码,就可以以字符形式将图片写进html或css文件里,③域名分片
7、报文主体压缩,首部不压缩
HTTP2
1、多路复用:解决HTTP1.1队头堵塞的问题。但解决的只是应用层上的
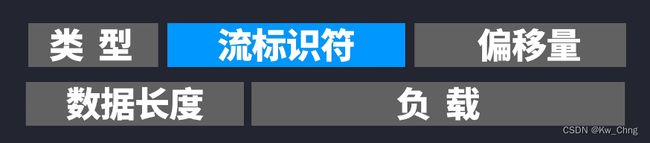
2、请求和响应报文被划分为各个不同的帧,帧又可以分为首部帧和数据帧。也就是把HTTP报文的首部和实体拆分为两部分,首部划分为首部帧,实体划分为实体帧
3、帧里的流标识符,使帧可以不用按照一定顺序就抵达对方那里


4、帧类型里可以设置优先级,标注流的权重,控制发送顺序
5、报文主体和首部都压缩,HPACK的压缩算法:要求浏览器和服务器都保存一张静态只读的表
6、服务器推送
7、报文变为二进制的帧
8、TLS加密
9、TCP的队头堵塞
HTTP3
1、整合是核心,将TCP和TLS的握手过程整合在一起,减少数据来回带来的开销
2、UDP协议,基于UDP新增QUIC协议。QUIC整合了TCP和TLS,使HTTP3默认是加密传输

3、从应用层传过来的数据被封装成QUIC帧 ,也有流标识符,但与HTTP2的不同在于HTTP3在应用层上没有帧的概念,而是在传输层才有帧,从源头解决队头堵塞问题
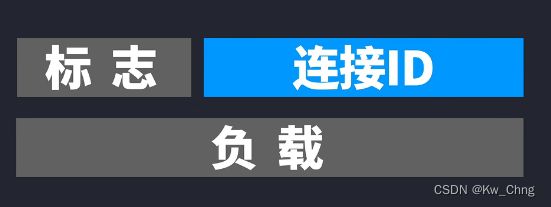
4、QUIC帧被封装成QUIC数据包,加上connection ID,用以识别当网络改变时(IP地址变了)还可以使用同一连接,避免再次握手
5、QUIC数据包会把QUIC帧加密
6、QUIC数据包会被UDP封装成数据段,UDP加上端口号,QUIC就会像TCP一样开启连接

DNS域名解析过程
DNS一般用UDP协议
查询浏览器缓存中有没有对应的IP记录,查询主机本地文件有没有对应的记录,有 =》不用进行后续操作
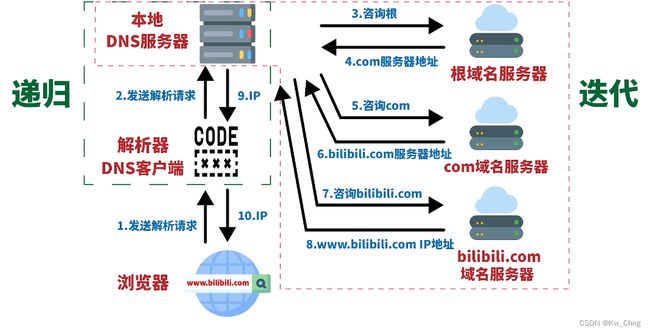
DNS域名解析过程 === 域名转换为IP地址
互联网的每台电脑都是通过IP地址来标识位置的,但是IP地址太多了记起来很麻烦,可以将IP地址与域名联系起来,记域名就行,在浏览器是输入域名得到相应网页的内容,而不是输入IP地址
域名是一个结构树
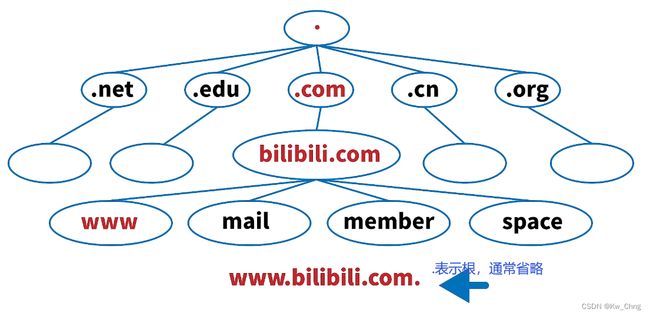
域名服务器
目前有13个域名服务器

内容分发网络CDN
客户端与服务器距离可能很远,数据传输时可能出现堵塞等情况,为了解决距离这个问题,有多台边缘服务器(接近用户的服务器)提供服务,CDN就是帮服务器近距离给用户分发网页内容的。
分发内容
静态内容:网页内不需要随意改变,长期保持的内容
动态内容:需要经常改变的内容
源服务器发送文件给CDN时利用HTTP头部的cache-control设置文件的缓存形式,告知CDN哪些资源可以保存、保存多长时间,哪些资源不可保存。静态资源不是一定保存在CDN里的。
分发流程——静态内容
CDN没有网站的源内容,源服务器会先把静态内容提前备份给CDN ------ push
在用户访问网页时 ------ request , 就近的CDN就会将静态内容提供给用户 ------ response
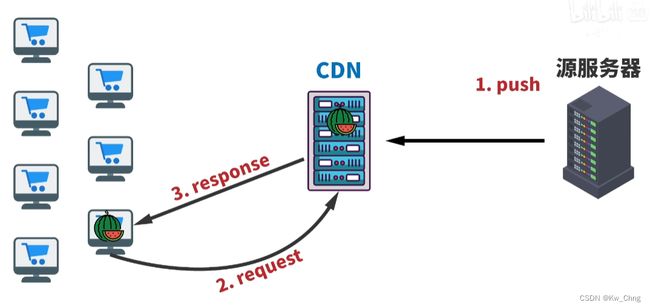
源服务器没有把静态内容提前备份给CDN,用户访问网页时,CDN就要向源服务器索取响应的静态内容 ------ pull
源服务器可以让CDN进行备份,CDN得到内容后再提供给用户,有了备份后,其他再请求网页的用户就可以马上拿到内容
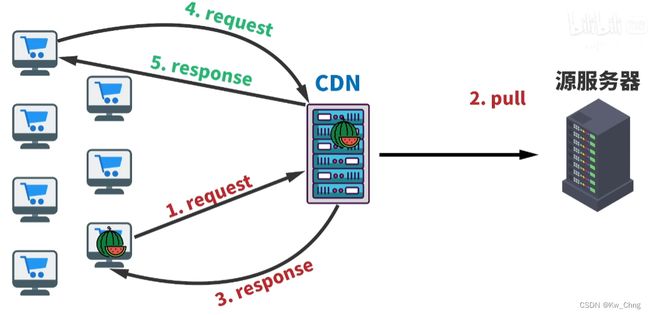
分发流程——动态内容
有些CDN会提供可以运行在CDN上的接口,让源服务器用这些接口而不是用自己的代码,这样用户可以直接从CDN获取时间,而不是从源服务器获取
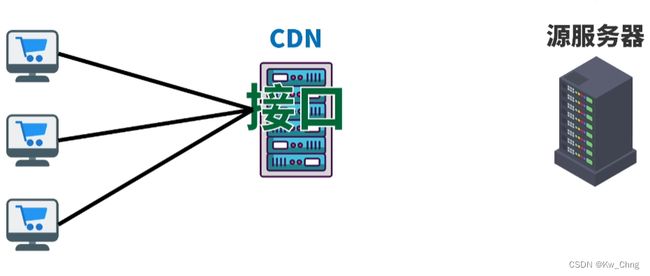
安全性和可靠性
布局多台CDN服务器,监控CDN服务器的负载情况,如果某台CDN服务器超载,就将用户的请求转移到没有超载的CDN服务器上,目的是平均分配网络流量,称为负载均衡
CDN用什么方法转移流量?任播。采用任播后,服务器对外都有同样的IP地址,这个IP地址接收用户请求后,请求会由离用户最近的服务器响应
采用TLS/SSL证书给网站进行保护
CDN也被当做加速器 / 加速方法
CDN将文件压缩或最小化
CDN自身会优化自己的硬件和软件,硬件不能比源服务器差
CDN减少费用
大部分网站由主机商托管,网站主需要向主机商支付费用(比如网络带宽)
CDN更接近用户来提供服务,减少了CDN到源服务器之间带宽的占用和使用
在浏览器输入URL回车后发生什么
用例子记:去医院看病 =》挂号告知去哪个科室看医生 --> 看医生之前在医生办公室门口敲门问看是否方便进去 --> 就诊,叙述病情和治疗请求 --> 医生告知病情确诊 --> 治病,人好了
- DNS解析:把URL地址解析为IP地址。DNS是一个数据库,记录着很多URL和对应的IP地址,有了IP地址就可找到指定的服务器
- 发送请求前,建立TCP连接,TCP三次握手
- 发送HTTP请求:浏览器发送HTTP请求报文(请求行、请求头、请求数据)给服务器
- 响应HTTP请求:服务器处理请求报文,作出响应
- 页面渲染:浏览器接收服务器响应后,页面开始进行渲染,解析接收到的html、css、js等文件
浏览器渲染页面流程
Cookie、Session、Token的区别
由于HTTP无状态,在登录页面之后再次登录,HTTP也不知道来过没有
- Session诞生并保存在服务器,由服务器主导一切
- Cookie是一种数据载体,把Session放入Cookie送到客户端,Cookie跟随HTTP的每个请求发送出去
- Token诞生在服务器,保存在浏览器,由客户端主导一切,可以放到Cookie或Storage里,Token像令牌一样被允许访问服务器
Cookie
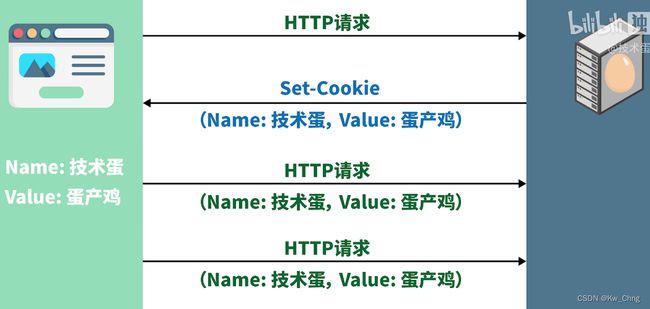
浏览器发起HTTP请求,服务器进行Cookie设置(Set-Cookie),将Set-Cookie里的name和value写好,Cookie发给浏览器,浏览器会保存,此后浏览器发送的每个请求都会加上这个Cookie
总结:Cookie就是存在浏览器的数据
缺点:在浏览器可以看到保存的Cookie,所以用户和密码保存在浏览器其实不太安全
Session 会话
浏览器访问服务器就是会话的开始
不同网站对每个用户的会话都设定了时间(结束会话的时间)和ID(Session ID)。服务器在发送Cookie之前对含有Session ID的Cookie签名,如果黑客拿到Session ID,也无法知道用户密码,拿到也没用
数据保存在数据库

Token JWT(JSON Web Token)
用户第一次登录网页,服务器生成一个JWT,服务器不需要保存这个JWT,只需要保存JWT签名的密文,把JWT发送给浏览器,让浏览器以Cookie或Storage的形式存储,如果以Cookie的形式保存下来,用户每次发请求都会将JWT发给服务器,用户不需要在输入账号密码
 JWT = header.payload.signature =》header声明用什么算法生成签名,payload特定数据,如有效期,signature
JWT = header.payload.signature =》header声明用什么算法生成签名,payload特定数据,如有效期,signature

跨域解决办法
XSS网络攻击
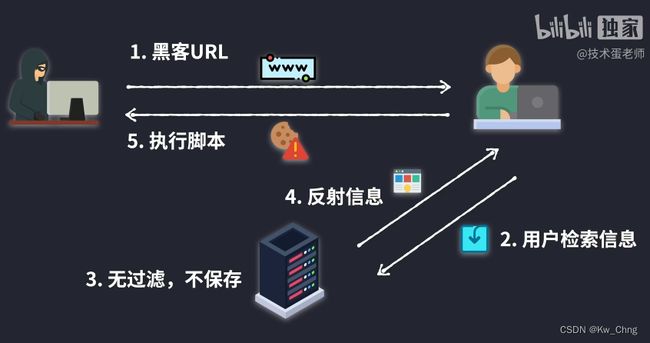
反射型:网络黑客制作了一个URL发给用户,用户将这个URL输入浏览器,浏览器访问网站服务器,服务器查看链接后以为用户要检索某些信息,没有进行额外过滤和信息存储就返回了页面结果,但URL里是有额外操作的(如把用户信息发送给黑客),那么恶意代码就会植入页面,用户点击URL就会中招
存储型:一般发生在可评论的网站,黑客不发表正常评论,而把恶意代码脚本作为评论发送网站服务器,服务器不过滤就会将评论永久保存起来,常见的保存在数据库,每个用户在这个网站一进评论区就可以看到恶意代码,那么就会把用户的信息发给黑客

DOM型:
