预训练模型
目录
- 一、BERT
-
- 1、贡献
-
- 1.1 MLM任务
- 1.2 NSP任务
- 2、实验细节
- 二、ALBERT
-
- 1、贡献
-
- 1.1 词向量分解
- 1.2 层参数共享
- 1.3 SOP任务
- 三、 ERNIE
-
- 1、贡献
- 2、实验细节
-
- 2.1 语料
- 2.2 MLM任务
- 2.3 DLM任务
- 四、DistilBERT
-
- 1、贡献
- 2、实验细节
- 五、RoBERTa
-
- 1、贡献
- 2、实验细节
-
- 2.1 动态mask
- 2.2 去掉NSP任务
- 2.3 更大的batch_size
- 2.4 更多数据训练更久
- 2.5 语料
- 六、ERNIE 2.0
-
- 1、贡献
- 2、模型结构
- 3、预训练任务
-
-
- 3.1 词感知任务
- 3.2 结构感知任务
- 3.3 语义感知任务
-
- 七、ERNIE 3.0
-
- 1、贡献
- 2、模型结构
- 3、预训练任务
- 八、MacBERT
-
- 1、贡献
- 2、实现细节
一、BERT
论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
代码:https://github.com/google-research/bert
作者:google
1、贡献
提出一种双向语言模型,基于该预训练模型finetune后在各下游任务取得sota效果。
模型结构图如下,包括两个任务,一个是MLM(mask language model),另一个是NSP任务(next sentence predict)。

1.1 MLM任务
- mask策略
随机mask掉句子15%的token,然后让模型预测mask掉的词。因为应用到下游任务finetune时,是没有mask标记的,为了弥补pretrain和finetune两个截断输入的不同,实际操作的时候是随机选择15%的词,然后其中80%替换成[mask]标记,10%保持不变,10%随机替换成其他词。这样模型并不知道该位置是mask还是原词还是随机的词,就迫使模型结合上下文去预测。此外15%*10%=1.5%的随机替换,这个量不大,并不会影响对原有句子的理解。 - 对比
跟GPT任务每次都预测全部词相比,MLM任务每次只预测15%的词,因此bert训练时间要更长一点点。
1.2 NSP任务
- 初衷
有些下游任务(比如QA,句子蕴涵)需要判断两个句子的关系,因此作者设计了NSP任务,提高这类任务的泛化能力。 - 操作
从一个文档里面选取连续的两个句子作为正样本,从不同的文档选择两个句子作为负样本,以1:1的比例混合。用[CLS]位置的输出向量来做分类任务。 - 缺点
后面有论文证明该任务提升有限,作者在ALBERT的论文中进行了原因推测:主要是负样本选择的不好导致该任务太容易了,模型没学到东西。因为负样本从两个不同的文档里面选择的,所以他们的主题也不同,而主题是很容易学习的(MLM任务也可以学到一点主题)。所以NSP任务其实更倾向于学主题而不是是否两个句子是连续的。 - 改进
针对上面的缺点,ALBERT的论文将NSP任务调整为两个连续句子的顺序,正样本保持不变,负样本为连续的两个句子调换位置后,预测两个句子是否调换了位置。
2、实验细节
- 语料
一共33亿word的语料,包括8亿的BooksCorpus语料和25亿的英文wikipedia语料。 - pretrain
- 句子开头是[CLS],两个句子之间是[SEP],末尾还有个[SEP],第一个[SEP]的segment_id是0,表示第一个句子,第二个[SEP]的segment_id是1,表示第二个句子。
- input
- 包括两个segment(注意不是两个句子),每个segment包括多个连续的真实句子
- 两个segment来自不同的文档则是NSP任务的负样本,否则是NSP任务的正样本
- 每个segment的长度都小于max_len(512),如果两个segment的长度和大于512,则每次选择两个segment中较长的那个segment,随机从头部/尾部丢弃一个字。(处理的时候每个segment的长度期望值的相同的,也就是512的一半256)
- 为了提高计算效率,会尽可能长的填满segment;这就带来预训练和finetune的不一致,为缓解这种不一致,会以10%的概率选取一些short的input,即90%的概率输入总长度是max_len,10%的概率输入总长度是random.randint(2, max_len)。对于short的input,不到max_len的部分会补pad,最终输入到model的总长度都是max_len。
- 具体可以见代码
- batch_size:256
- lr:1e-4
- 优化器: Adam,β1=0.9,β2=0.999,L2 weight decay:0.01
- warmup: 10% steps
- 学习率线性调度,先升后降
- dropout: 0.1(all layer)
- gelu激活函数
gelu原理参见这里 - 90%的step用128的序列长度,后面10%采用512的长度,加速训练
- 采用上下截断的正太分布初始化
- 位置向量随机初始化可学习
- 可学习的位置编码 vs 三角函数位置编码
- 在attention is all you need的论文里面实验表明两者效果相差不大,用后者是因为可以推断比训练样本更长的文本
- bert用可学习参数位置编码的原因可能是语料足够大,两者效果相差小,前者实现更简单。可学习的参数在大语料情况下比公式赋值的效果可能更好一点。
- token是wordpiece(bpe是其中一种具体实现)
- 静态MASK:在预训练之前的数据预处理阶段先将语料复制n份,然后进行mask后固化到数据,在预训练阶段直接加载。比如复制10份,epoch=40,那么平均同一个样本同一种mask后的input会被模型见4次。
- finetune
- [CLS]位置的输出用于预测NSP任务,因此在下游任务中必须要微调,否则没有具体意义。
- finetune的时候要微调全部参数
- 分类任务使用[CLS]向量微调,token级别的任务使用全部输出
- 作者一些建议的设置
- batch_size: 16,32
- learning rate(Adam): 5e-5,3e-5,2e-5
- epoch: 2,3,4
- 单层transformer的时间复杂度(假设序列长度为n,隐层大小为d)
- self-attention的复杂度是nd(n+d)
- QKV先线性映射,复杂度是nd^2
- 计算attention的复杂度是n^2d
- FFN层的复杂度是nd^2
- 两者加起来就是单层transformer的复杂度,因此当n比较小的时候,复杂度主要是在FFN层,即bert base的512长度复杂度主要是在FFN层
- 参考:https://mp.weixin.qq.com/s/MhLXO_VE_VYb7iIJCgN_lQ
- self-attention的复杂度是nd(n+d)
- 显存和batch_size和序列长度的关系
- 跟batch_size成线性关系
- 跟序列长度,长度小于512近似线性,长度大于512近似平方关系

- 参考:https://zhuanlan.zhihu.com/p/527143823
二、ALBERT
论文:ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
代码:https://github.com/google-research/ALBERT
作者:google
1、贡献
提出一种轻量化bert,包括两种方法:一个是降低词向量的纬度,二是transformer层的参数共享。
在和BERT-large相同配置的前提下,参数只有之前的1/18,训练速度是之前的1.7倍。
1.1 词向量分解
不改变隐藏层大小,只降低词向量的纬度。将VH的词向量用两个小矩阵VE和E*H表示,这样当H>>E的时候,将显著降低参数。其次这也对模型起到正则的作用。作者这样做的两个原因:
- 模型角度:实验表明bert的效果提升主要来源于学到了上下文的信息,而词向量是上下文独立的,因此没有必要让隐藏层纬度H和词向量纬度E保持一致,这样可以让参数更好的利用。
- 工程角度:词向量纬度太大,很容易导致整体参数过大,在训练的时候这些参数更新是稀疏的。
1.2 层参数共享
有很多共享策略,只共享FFC层,只共享attention层或者分组共享,作者这里采用完全共享的方式,只有一层参数。作者发现这样作可以让训练更加稳定。
1.3 SOP任务
有研究表明原始BERT的NSP任务(next sentence predict)收效甚微,作者进行了原因推测:主要是负样本选择的不好导致该任务太容易了,模型没学到东西。因为负样本从两个不同的文档里面选择的,所以他们的主题也不同,而主题是很容易学习的(MLM任务也可以学到一点主题)。所以NSP任务其实更倾向于学主题而不是是否两个句子是连续的。针对上面的缺点,ALBERT的论文将NSP任务调整为两个连续句子的顺序SOP任务(sentence order predict),正样本保持不变,负样本为连续的两个句子调换位置后,预测两个句子是否调换了位置。
三、 ERNIE
论文:ERNIE: Enhanced Representation through Knowledge Integration
代码:https://github.com/PaddlePaddle/ERNIE
作者:百度
1、贡献
作者通过mask掉词组和实体的方式,让预训练模型隐式的学习到知识,属于BERT的效果改进版。
2、实验细节
2.1 语料
作者采用了多源语料,代表了不同类型的知识,可以提高迁移学习的能力。具体采用中文维基百科、百度百科、百度新闻、百度贴吧四种语料,分别2.1kw、5.1kw、4.7kw、5.4kw个句子。
- 百度百科 :语言比较正式,可以作为语言模型的强基线语料
- 百度新闻:提供最新的信息,包括电影名、演员、球队等
- 百度贴吧:论坛对话类的语料,可以提高模型在对话任务上的泛化能力(用于DLM任务)
作者作了繁化简、大写转小写处理后,词表为17964个字符。
2.2 MLM任务
跟BERT不同之处在于MASK策略,作者设计了3种粒度的mask策略:
- 基础粒度:随机mask掉15%的字
- 词组粒度
- 实体粒度
2.3 DLM任务
ERNIE设计DLM(Dialogue Language Model)来强化模型在对话领域的建模能力,类似原始BERT的NSP任务。DLM任务模型的输入是一个多个句子的序列,表示多轮对话,可以是QRQ、QRR、QQR等形式(Q表示query,R表示response)。负样本(fake)是用一个随机的句子替换query或者response。模型的目标是使用[CLS]位置的向量预测该多轮对话是真实的还是fake的。该任务可以和MLM任务兼容。
四、DistilBERT
论文:DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
代码:https://github.com/huggingface/transformers
作者:huggingface
一个Language Model效果评估的网址:https://nv-adlr.github.io/MegatronLM
1、贡献
作者提出了一个BERT的蒸馏版本,减少了40%的参数,保留了97%的效果,推理耗时减少到之前的60%。之前的研究都是针对特定任务的蒸馏,即BERT在特定任务finetune后蒸馏到小模型,本论文是直接在预训练阶段将语言模型蒸馏到小bert。
2、实验细节
teacher模型是bert,本模型为student,在预训练的过程中,进行知识蒸馏。
- 层数:减小为bert的一半。作者验证层数对性能影响大,而向量纬度对性能影响很小;减少层数也方便后续使用原bert训练好的参数初始化
- 初始化:因为纬度一样,采用训练好的原bert隔层的参数初始化。
- loss包括三部分(去掉NSP任务):
- 蒸馏的loss(Lce)
- MLM任务的loss(Lmlm)
- 词向量余弦距离loss(Lcos)
- 消融实验
如下图所示,使用训练好的bert的参数初始化影响最大,其次是蒸馏的loss,影响最小的是MLM任务的loss。

五、RoBERTa
论文:RoBERTa: A Robustly Optimized BERT Pretraining Approach
代码:https://github.com/pytorch/fairseq
作者:facebook
1、贡献
作者在语料、超参、训练方法上对原始BERT进行了优化,属于BERT的工程优化版。
2、实验细节
2.1 动态mask
- 静态mask
原BERT的mask策略是在预训练之前的数据处理阶段就做好然后固化到数据里面的,在预训练阶段直接加载。为了多样性,会先复制10份,然后mask,这样比如跑了40个epoch,那么同一条样本会有10种mask后的序列,同一条样本同一种mask后的序列会在训练阶段出现4次。 - 动态mask
本文采用动态mask,即在预训练过程中,在每个batch的data喂给模型之前进行mask,这样每次mask都不同。
本文分别实现了两种mask策略,实验结果如下,动态的会略好,但是影响不大。
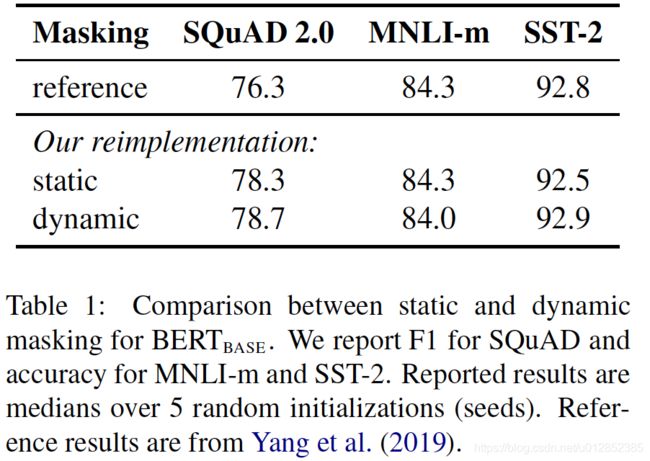
2.2 去掉NSP任务
作者设计了4个任务
- SEGMENT-PAIR+NSP:原始BERT的设置,两个segment,每个segment为来自相同或者不同文档的连续多个句子。
- SENTENCE-PAIR+NSP:两个自然句子,来自于相同或者不同的文档,因为这个有效token会比较少,所以作者提高了batch_size
- FULL-SENTENCES:连续的多个句子,可以跨文档,且删除NSP任务。
- DOC-SENTENCES:同一个文档内的连续多个句子,且删除NSP任务。该任务比第三个任务有效token会减少,因此提高batch_size
实验结果如下,前两个任务对比发现单个句子会损伤模型性能,应该是模型缺乏建模长依赖的能力;第三第四个任务跟第一个任务对比可以发现去掉NSP任务效果还提升了,说明NSP任务不是必须的。

2.3 更大的batch_size
原BERT的batch_size是256,作者对batch_size做了实验。结果如下,说明扩大batch_size效果更好。(扩大batch_size会减少step因此要加大学习率)。
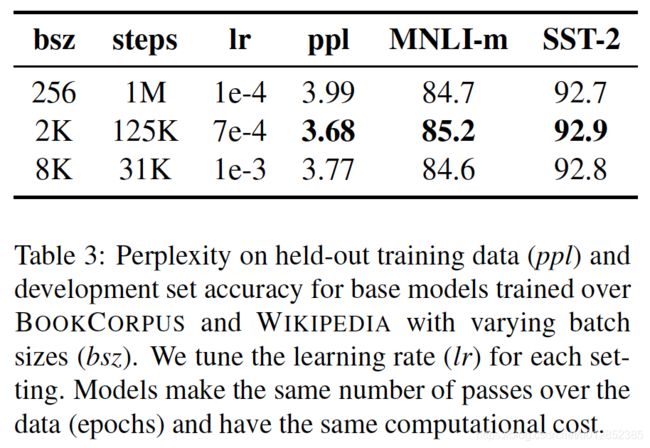
2.4 更多数据训练更久
作者还验证使用更多的数据,训练的更久,能提升效果。此外作者还对wordpiece的不同实现方式进行了对比,差别不大。

2.5 语料
- BOOKCORPUS + English WIKIPEDIA: 16G,原始BERT语料
- CC-NEWS:76G
- OPENWEBTEXT: 38G
- STORIES: 31G
六、ERNIE 2.0
论文:ERNIE 2.0: A Continual Pre-training Framework for Language Understanding
代码:https://github.com/PaddlePaddle/ERNIE
作者:百度
1、贡献
现在预训练任务都是利用句子/词共现信息,没有用到词法(比如ner)、语法(比如句子顺序)、语义信息(比如文档中句子相似度)。作者提出一种基于持续学习和多任务学习的预训练框架ERNIE2.0来利用这些信息。
2、模型结构
就是每来一个新任务,都和之前的所有任务一起重新训一遍。

3、预训练任务
3.1 词感知任务
- 实体/词组 整个mask,参见ERNIE 1.0的mask策略,可以引入知识
- 首都预测任务,提高NER任务的性能
- Token-Document Relation:一个document会切分多个segment,判断一个segment的词是否也在这个document中其他segment出现,原理是关键词判断,关键词一般是出现在多个地方
3.2 结构感知任务
- 句子重排序:将给定的段落随机划分为1到m段,然后将其打乱,预测段的正确顺序。是做k分类任务,

- 句子距离任务:是bert的nsp任务的扩展,三分类,0表示同一个文档相邻句子,1表示同一个文档不相邻句子,2表示不同文档的两个句子
3.3 语义感知任务
- Discourse Relation:判断两个句子间的修辞关系,has , is a 等
- IR Relevance Task:借助搜索引擎,0表示用户query搜索结果中展示了某个title并且用户点击了,1表示用户query搜索结果中展示了某个title但是用户没有点击,2表示用户query搜索结果中没有展示的title。
七、ERNIE 3.0
论文:ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
作者:百度
1、贡献
- 提出了一个统一的预训练框架ERNIE 3.0,统一了自回归任务和自编码任务。
- 在预训练模型中引入了大规模知识图谱,在54个中文任务上取得SOTA的结果,并在SuperGLUE排行榜取得了第一名。
2、模型结构
作者提出通用语义表示和任务语义表示结合的模型框架,该框架融合自编码和自回归等不同的任务语义表示网络,既可同时处理语言理解和语言生成任务,还能做无标注数据的零样本学习(Zero-shot Learning)和有标注数据的微调训练(Fine-tuning)
ERNIE3.0 框架分为两层:
- 第一层是通用语义表示网络,该网络学习数据中的基础和通用的知识。网络使用48层Transformer-XL,隐层大小4096,64头attention
第二层是任务语义表示网络,该网络基于通用语义表示,学习任务相关的知识。不同任务语义表示网络可通过自编码结构或者自回归结构实现,并通过底层共享实现交互和增强。在学习过程中,任务语义表示网络只学习对应类别的预训练任务,而通用语义表示网络会学习所有的预训练任务。网络使用12层Transformer-XL,隐层大小768,12头attention。

3、预训练任务
在ernie 2.0的基础上,新增了知识图谱的预测任务。输入包括两部分,一部分是知识图谱三元组(主体,关系,客体),第二部分是包括该条知识实体的句子。为了让模型能学习到这个知识图谱的关系,可以采用以下两种方法:
- 将三元组中的某个实体或者关系去掉,然后通过B段去预测A段的masked部分。(原理是如果一句话包括两个实体,那么这句话应该也包括了这两个实体的关系)
- 将B段的某个实体去掉,通过A段去预测B段被masked的部分。
因为A,B段包含的信息是冗余的,那么通过A理应可以预测B的缺失部分,而通过B也应该可以预测A的缺失部分。如果缺失部分是和语义(知识)有关的,那么模型应该可以学习到一定的知识才对。因此在ERNIE 3.0中作者称之为“知识图谱加强”。
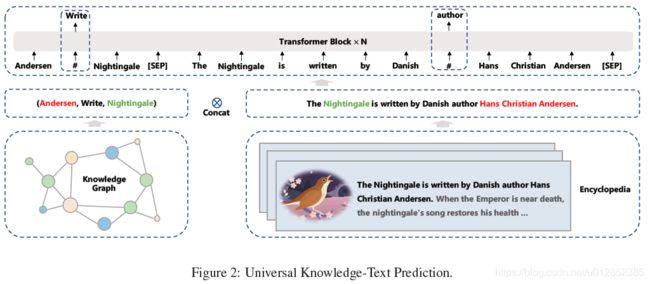
参考
- https://blog.csdn.net/LoseInVain/article/details/118531647
八、MacBERT
论文:Revisiting Pre-Trained Models for Chinese Natural Language Processing
代码:https://github.com/ymcui/MacBERT
作者:哈工大
1、贡献
作者聚焦在中文预训练任务,将BERT任务MLM任务的[MASK]标记替换成了近义词,降低了预训练和finetune阶段的gap,新的预训练模型命名为MacBERT(adopt MLM as correction)。作者证明在下游任务中,MacBERT有更好的效果。
2、实现细节
多种预训练任务对比如下,作者后面消融实验证明N-gram(分词后,词粒度不是字粒度)的mask和近义词替换提升最大(下游finetune任务中n-gram的mask对分类任务更重要,近义词替换对阅读理解更重要)。

mask掉15%的token,其中80%替换成近义词,10%随机替换,10%不变。其中近义词替换中,1-gram到4-gram替换的比例为40%,30%,20%,10%。近义词使用第三方工具提供,基于word2vec的synonyms toolkit,分词工具为哈工大自己的LTP。mask后的示例:

作者也训练了base和large两个版本,base是基于bert-chinese-base初始化的,large版本随机初始化。训练token长度512。作者提出batch-size小于1024时候用AdamW优化器,更大的时候用LAMB优化器。large版本的batch-size=512,base版本的batch-size作者没有提供。