Go内存管理及性能观测工具
内存管理
TCMalloc
Golang内存分配算法主要源自Google的TCMalloc算法,TCMalloc将内存分成三层最外层Thread Cache、中间层Central Cache、最里层Page Heap。Thread Cache和Central Cache里放着不同size的空闲内存块,相同size的空闲内存块会以链表的形式排布。申请内存分为两种,<=256KB的对象都被认为是小对象,>256KB的被认为是大对象,直接通过Page Heap来获取。大对象分配内存都是以Page为单位,即大对象内存以Page对齐。如果你看懂了下面的逻辑图,那么你已经理解了RCMalloc算法。
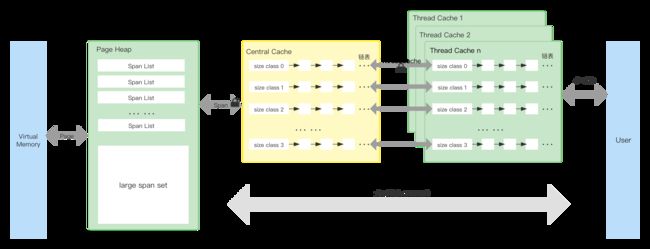
- Page:操作系统的分页,1Page=8KB;
- Span:一个Span是由多个Page构成的List;
- Size Class:将每个小对象(1KB~256KB)分成88个可分配的尺寸等级,每个Size Class对应一个编号,从0开始递增;
- Thread Cache:每个Thread Cache里对于每个Class Size都有一个单独的Free List,用来缓存N个未被使用的空闲对象。算法为每个线程都分配了一个Thread Cache,所以从中获取/释放内存是不需要加锁的,速度很快.。释放对象时,只需要将对象插入Thread Cache的Size Class对应的FreeList中,不需要加锁,速度也是非常快的;
- Central Cache:Central Cache中对每个Size Class都维护着Free List。当Thread Cache中没有空闲对象时,会向Central Cache申请对象。Central Cache是所有线程共用的缓存,过程中需要自旋锁。为了平摊自旋锁的开销,Thread Cache会从CentralCache一次性取用或回收多个空闲对象。满足一定条件时,Thread Cache中的空闲对象会放回到Central Cache的Free List中,这个操作是需要加锁的;
- Page Heap:Page Heap的基础单位是Span(Page List),根据Span的大小分为两种缓存形态,小Span(128个Page以内)通过链表来缓存,大Span会存储在一个有序Set。 当Central Cache中没有空闲对象时,会向Page Heap申请。Central Cache会将Span拆分成Size Class的大小使用;
- Virtual Memory:虚拟内存。当Page Heap的空闲对象不足时,会向Virtual Memory申请一个或多个Page。向Virtual Memory申请应用程序所使用的对象时,每次至少尝试申请1MB(
kMinSystemAlloc),申请TCMalloc自身元数据所使用的内存时,每次至少申请8MB(kMetadataAllocChunkSize)。这样既可以减少内存碎片,又均摊了系统调用的开销。
优势
- 多级缓存,提高内存获取速度;
- 为每个线程分配独立内存空间,资源隔离、减少线程之间的锁竞争;
- 将内存分为多个size等级,减少内存碎片,提高内存利用率。使内存的获取和释放简化;
- 从操作系统获取固定大小(page整数倍)的内存,减少内存碎片、便于内存管理。
go内存分配
Go的内存管理思路和TCMalloc一致,内存池+多级对象管理,在Go里内存管理的对象结构主要是:mheap、mspan、arenas、mcentral、mcache。
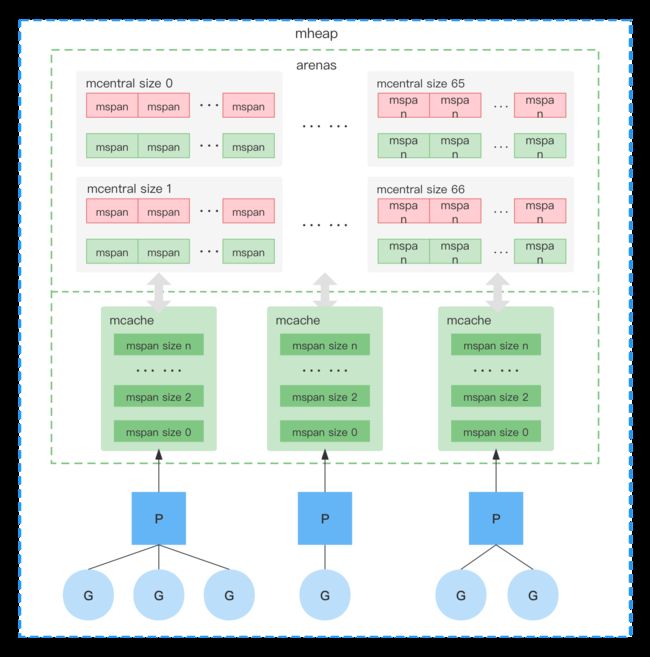
- page:在Go里Page的大小是固定的8KB;
- mspan:内存管理的基本单元;
- mcache:每个P都对应一个mcache,在申请小内存(<=32KB)时直接从mcache获取,不需要加锁;
- mcentral:包含不同size的mspan(绿色-空闲、红色-已占用),当mcache空闲不足时会向mcentral申请内存;
- arenas:堆区,动态分配的内存都在这个区域;
- mheap:代表Go程序持有的所有堆空间。当空间不够时会向系统申请一块64M的内存块,封装成arena来管理。mheap中最多可以管理4194304个arena,每个arena 64MB。
go垃圾回收
垃圾回收(Garbage Collection,GC)就是把程序不用的内存空间视为“垃圾”。这里具体是指程序的堆、栈所占用的内存。GC 要做两件事:标记出需要清理的对象,回收标记的清除对象。标记就是从根节点(栈或者全局变量)扫描,每个根节点扫描到底,扫描所有的根节点。根据三色标记法将对象标记为黑色、灰色、白色;回收标为白色的对象,使其可以被再次利用。
三色标记法

- 所有对象初始状态都是白色;
- 从根节点开始扫描,并将引用对象标成灰色;
- 遍历灰色节点,将新遍历到的白色节点标记为灰色,并把上一步标记的灰色节点标记为黑色;
- 重复上面步骤,直到没有灰色节点;
- 回收所有白色节点。
为了避免在GC过程中对象之间的引用关系发生变化,导致GC出错(比如在GC过程中由于未扫描到新的引用对象导致错误清除),会停止所有正在运行的协程,即STW(Stop the world)。STW虽然保证了准确性但是对性能也有影响,那么GC和程序运行是否可以并发进行?

在图三被标记为黑色的对象新引用了一个白色对象,但是这个黑色对象不会再次被扫描,白色对象一人会被回收,这样会造成很严重的后果。为了解决漏标的问题,需要使用写屏障机制。
写屏障是在内存进行写操作之前执行的,一般需要满足以下两个原理:
- 强三色不变式,强制性的不允许黑色对象引用白色对象;
- 弱三色不变式,黑色对象可以引用的白色对象是,有其他灰色对象对它的直接引用,或者它的链路上游存在灰色对象。

插入写屏障,引入新的白色对象时,就将白色对象标记为灰色,满足强三色不变式。处于性能和实现复杂度的考虑,go对栈空间没有使用写屏障,导致新增的引用对象无法及时发现。为了保证程序正常运行,在执行清除回收前,go会执行STW重新扫描一遍栈空间。

删除写屏障,在GC过程中如果出现在引用删除,所删除的对象依旧会全部保留下来,满足满足弱三色不变式。虽然不用在此STW但是标记删除粒度比较粗,需要被删除的对象只有在下一轮GC中才会被删除。

go的垃圾回收是基于三色标记法,通过合理的使用内存屏障,大大较少了垃圾回收的STW。GC开始就将栈上所有的对象标记为黑色,不需要二次扫描,不需要STW;GC期间任何栈上新建对象均标记为黑色;被删除的对象标记为灰色;新增对象标记为灰色。结合了删除、插入写屏障各自优势。
GC时机
主要有两种:
- 主动触发:
runtime.GC() - 被动触发:定时触发、GC百分比(在下一次垃圾收集必须启动之前可以分配多少新内存的比率,默认为100)
性能观测
名词解释
- mark:标记阶段;
- STW:Stop The World,在垃圾回收的某个阶段需要暂停整个应用程序;
- P:processors,处理器;
- markTermination:标记结束阶段;
- mutator assist:辅助GC;
- dedicated/fractional/idle:在标记阶段会分为三种不同的mark worker模式,分别是dedicated、fractional和idle,它们代表着不同的专注程度,其中dedicated模式最专注,是完整的GC回收行为,fractional只会干部分的GC行为,idle最轻松。(这篇文章你只需要了解它代表不同专注程度的mark worker就行);
- heap_live:span是GO内存页的基本单元,每页大小为8kb,同时会根据对象大小分配span页数,heap_live就是所有span的总大小。
GODEBUG之gctrace
gctrace主要是观察GC各个阶段耗时及GC后的内存情况。gcvis提供了可视化功能,仅支持GO 1.6版本。下面是一段有内存泄漏的问题代码,执行GODEBUG=gctrace=1 go run demo.go,会得到详细的GC参数
// go 1.19
package main
import (
"fmt"
"net/http"
)
// 内存未被释放
var urlList []string
func main() {
go func() {
for {
data := []byte("http://127.0.0.1")
sData := string(data)
urlList = append(urlList, sData)
}
}()
http.ListenAndServe("0.0.0.0:6060", nil)
}
命令执行结果:

下面介绍输出参数的具体含义,以图片的最后一行为例
gc 10 @0.264s 1%: 0.39+5.0+0.034 ms clock, 1.5+3.2/3.9/1.4+0.13 ms cpu, 4->5->2 MB, 5 MB goal, 4 P
- gc 10:第10次gc
- @0.264s:当前程序启动后的第0.264秒
- 1%:程序启动到现在花费在gc上的时间是1%
- 0.39+5.0+0.034 ms clock:
- 0.39:单个P在mark阶段的STW时间
- 5.0:所有P并发标记使用的时间
- 0.034:单个P在markTermination阶段所用时间
- 1.5+3.2/3.9/1.4+0.13 ms cpu:
- 1.5:进程在mark阶段的STW时间
- 3.2/3.9/1.4:3.2表示mutator assist占用的时间,3.9表示dedicated mark workers + fractional mark workers占用的时间,1.4表示idle占用的时间
- 0.13:整个进程在markTermination阶段 STW 时间
- 4->5->2 MB:
- 4:mark阶段前heap_live 大小。
- 5:markTermination阶段前heap_live大小。
- 2:被标记对象的大小
- 5 MB goal:下次触发GC阈值是5MB
- 4 P:这次GC一共涉及4个P
- GC forced: 如果两分钟内没有执行GC,会强制执行一次GC,会换行打印 GC forced
下面贴出官方的解释:
Currently, it is:
gc # @#s #%: #+#+# ms clock, #+#/#/#+# ms cpu, #->#-># MB, # MB goal, # P
where the fields are as follows:
gc # the GC number, incremented at each GC
@#s time in seconds since program start
#% percentage of time spent in GC since program start
#+...+# wall-clock/CPU times for the phases of the GC
#->#-># MB heap size at GC start, at GC end, and live heap
# MB goal goal heap size
# P number of processors used
The phases are stop-the-world (STW) sweep termination, concurrent
mark and scan, and STW mark termination. The CPU times
for mark/scan are broken down in to assist time (GC performed in
line with allocation), background GC time, and idle GC time.
If the line ends with "(forced)", this GC was forced by a
runtime.GC() call and all phases are STW.
pprof
pprof是可视化和分析性能分析数据的工具。下面一段代码
package main
import (
"fmt"
"net/http"
"time"
_ "net/http/pprof"
)
func main() {
var forkNum int
for forkNum < 100 {
forkWorker(forkNum)
forkNum++
}
http.ListenAndServe("0.0.0.0:6060", nil)
}
func forkWorker(i int) {
go func(i int) {
for {
fmt.Println("worker id ", i, "at ", time.Now().Format("2006-01-02"))
}
}(i)
}
上面的代码会一直创建空跑协程。接下来通过pprof工具来分析。
通过web页面
访问http://127.0.0.1:6060/debug/pprof/ 会看到如下页面

点进子页面能查看到更多的信息。
通过终端交互
执行命令 $ go tool pprof http://localhost:6060/debug/pprof/profile?seconds=60

命令执行后需要等待seconds秒(可调整),此时在pprof的命令交互模式,可以详细查看、导出结果。具体命令执行help查看。
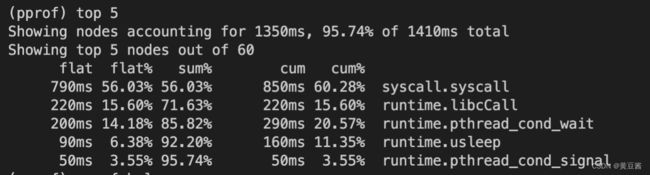
- flat:函数上运行耗时
- flat%:函数CPU运行耗时总比例
- sum%:函数累积使用 CPU总比例
- cum:函数加上它之上的调用运行总耗时
- cum%:函数CPU 运行耗时总比例
$ go tool pprof http://localhost:6060/debug/pprof/heap分析程序常驻内存使用情况
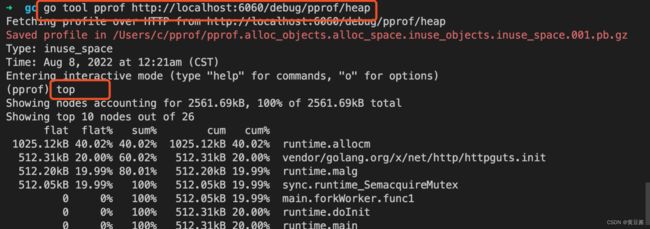
$ go tool pprof http://localhost:6060/debug/pprof/goroutine分析协程数
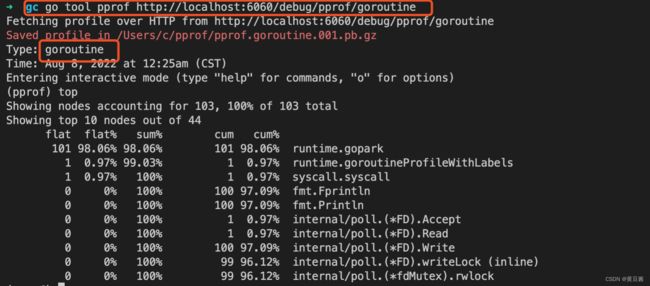
命令$ go tool pprof http://localhost:6060/debug/pprof/***最后的内容可以用web方法页面中的内容替换,会看到不同方向下的内存分配情况。
pprof可视化
安装工具
$ brew install gperftools
$ brew install graphviz
安装graphviz需要很多依赖包,根据报错手动安装对应包。我在安装过程中遇到了gdk-pixbuf安装失败,执行下面命令成功后再次安装graphviz就可以了
$ brew install cairo pango gdk-pixbuf libffi
简单demo
package main
import (
"testing"
)
func TestAdd(t *testing.T) {
s := Add()
if s == "" {
t.Errorf("Test.Add error!")
}
}
func BenchmarkAdd(b *testing.B) {
for i := 0; i < b.N; i++ {
Add()
}
}
var urlList []string
func Add() string {
data := []byte("http://127.0.0.1")
sData := string(data)
urlList = append(urlList, sData)
return sData
}
分别执行下面命令:
$ go test -bench=. -cpuprofile=cpu.prof
$ go tool pprof -http=:8080 cpu.prof
执行后会弹出web页面:
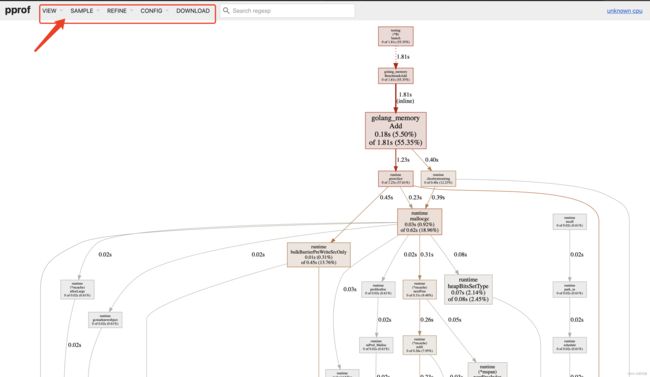
红色框起来的是二级页面,点进去可以查看更详细的信息。有了这个可视化工具,我们可以清晰的看出函数的调用关系、以及每一步的耗时情况。可以快速的帮我们找到程序的问题。
pprof火焰图
在上面web页面中,点击VIEW->Flame Graph就可以看到火焰图了。

在上面提到的一步$ go tool pprof http://localhost:6060/debug/pprof/profile?seconds=10,会产生文件~/pprof/pprof.samples.cpu.003.pb.gz。
执行命令$ go tool pprof -http=:8081 ~/pprof/pprof.samples.cpu.003.pb.gz 也会跳转到pprof的可视化界面。
怎么看火焰图
- 纵轴代表调用栈,调用顺序从上到下
- 横轴代表函数。一个函数在横轴越宽,说明函数执行时间越长。一个函数横向越长,越有可能是性能瓶颈,但是横轴的长度不等于时长;
- 如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的;
- 这里的颜色没有特殊含义,是随机暖色系;