Flink:任务提交详细流程
文章目录
1.Flink多种提交方式对比
1.1 local模式
1.1.1 纯粹的local模式运行
1.1.2 local使用remote的方式运行
1.1.3 本地提交到remote集群
1.2 standalone模式
1.3 yarn模式
1.3.1 yarn-session
1.3.2 yarn-cluster
2.flink命令参数详解
3.flink on yarn作业提交详细流程
4.总结
5.遇到的问题
5.1 采用yarn-session方式运行过项目后,再以standalone模式运行项目报错
1.Flink多种提交方式对比
常用提交方式分为local,standalone,yarn三种。
local:本地提交项目,可纯粹的在本地单节点运行,也可以将本地代码提交到远端flink集群运行。
standalone:flink集群自己完成资源调度,不依赖于其他资源调度器,需要手动启动flink集群。
yarn:依赖于hadoop yarn资源调度器,由yarn负责资源调度,不需要手动启动flink集群。需要先启动yarn和hdfs。又分为yarn-session和yarn-cluster两种方式。提交Flink任务时,所在机器必须要至少设置环境变量YARN_CONF_DIR、HADOOP_CONF_DIR、HADOOP_CONF_PATH中的一个,才能读取YARN和HDFS的配置信息(会按三者从左到右的顺序读取,只要发现一个就开始读取。如果没有正确设置,会尝试使用HADOOP_HOME/etc/hadoop),否则提交任务会失败。
1.1 local模式
local即本地模式,可以不依赖hadoop,可以不搭建flink集群。一般在开发时调试时使用。
1.1.1 纯粹的local模式运行
就是直接运行项目中的代码的方式,例如直接在idea中运行。创建ExecutionEnvironment的方式如下:
// getExecutionEnvironment()方法可以根据flink运用程序如何提交判断出是那种模式提交
//ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
ExecutionEnvironment env = ExecutionEnvironment.createLocalEnvironment();
1.1.2 local使用remote的方式运行
这种方式可以将本地代码提交给远端flink集群运行,需要指定集群的master地址。在flink集群的web ui会存在Running Job/Compaleted Jobs的记录。
public class TestLocal {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.createRemoteEnvironment("remote_ip", 8090, "D:\\code\\flink-local.jar");
System.out.println(env.getParallelism());
env.readTextFile("hdfs://remote_ip:9000/tmp/test.txt")
.print();
}
}
1.1.3 本地提交到remote集群
例如有如下项目代码:
public class TestLocal {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.readTextFile("hdfs://remote_ip:9000/tmp/test.txt")
.print();
}
}
将项目打成jar包,在本机上使用flink run 指定集群的模式提交(这个机器可以不是flink集群的节点,但需要在local机器上有flink提交命令,)。如:
./flink run -m remote_ip:8090 -p 1 -c com.test.TestLocal /home/hdp/flink-local.jar
# -m flink 集群地址
# -p 配置job的并行度
# -c Job执行的main class
也会在flink web ui界面显示结果。
1.2 standalone模式
上面讲了flink在local机器上进行提交,需要指定flink的master信息。
standalone模式提交也是类似,不过可以不用指定master节点,还有个区别就是,提交是在flink集群的机器节点上。
两个提交命令示例:
# 前台提交
./flink run -p 1 -c com.test.TestLocal /home/hdp/flink-local.jar
# 通过-d后台提交
./flink run -p 1 -c com.test.TestLocal -d /home/hdp/flink-local.jar
1.3 yarn模式
yarn模式必须确保本机配置了HADOOP_HOME环境变量,flink会尝试通过HADOOP_HOME/etc/hadoop目录下的配置文件连接yarn。
flink on yarn 有两种提交方式:
yarn-session:启动一个YARN session(Start a long-running Flink cluster on YARN)
yarn-cluster:直接在YARN上提交运行Flink作业(Run a Flink job on YARN)
两者区别
一种是yarn-session,就是把首先启动一个yarn-session当成了一个flink容器,官方说法是flink服务,然后我们提交到yarn上面的全部flink任务全部都是提交到这个服务,也就是容器里面进行运行的。flink任务之间也是独立的,但是都存在于flink服务即容器里面,yarn上只能监测到一个flink服务即容器,无法监测到flink单个任务,需要进入flink服务即容器内部,才可以看到。
另一种是yarn-cluster,就是每个把flink任务当成了一个application,就是一个job,在yarn上可以管理,flink任务之间互相是独立的。
1.3.1 yarn-session
这种模式下会启动yarn session,并且会启动Flink的两个必要服务:JobManager和TaskManagers,然后你可以向集群提交作业。同一个Session中可以提交多个Flink作业。需要注意的是,这种模式下Hadoop的版本至少是2.2,而且必须安装了HDFS(因为启动YARN session的时候会向HDFS上提交相关的jar文件和配置文件)。
yarn-session模式提交任务的步骤:
1.启动yarn-session,我们可以通过./bin/yarn-session.sh脚本启动,参数如下
Usage:
Required
-n,--container Number of YARN container to allocate (=Number of Task Managers)
Optional
-D use value for given property
-d,--detached If present, runs the job in detached mode
-h,--help Help for the Yarn session CLI.
-id,--applicationId Attach to running YARN session
-j,--jar Path to Flink jar file
-jm,--jobManagerMemory Memory for JobManager Container with optional unit (default: MB)
-m,--jobmanager Address of the JobManager (master) to which to connect. Use this flag to connect to a different JobManager than the one specified in the configuration.
-n,--container Number of YARN container to allocate (=Number of Task Managers)
-nl,--nodeLabel Specify YARN node label for the YARN application
-nm,--name Set a custom name for the application on YARN
-q,--query Display available YARN resources (memory, cores)
-qu,--queue Specify YARN queue.
-s,--slots Number of slots per TaskManager
-sae,--shutdownOnAttachedExit If the job is submitted in attached mode, perform a best-effort cluster shutdown when the CLI is terminated abruptly, e.g., in response to a user interrupt, such
as typing Ctrl + C.
-st,--streaming Start Flink in streaming mode
-t,--ship Ship files in the specified directory (t for transfer)
-tm,--taskManagerMemory Memory per TaskManager Container with optional unit (default: MB)
-yd,--yarndetached If present, runs the job in detached mode (deprecated; use non-YARN specific option instead)
-z,--zookeeperNamespace Namespace to create the Zookeeper sub-paths for high availability mode
例如:
# 方式一:启动一个新的flink集群
./bin/yarn-session.sh -n 4 -tm 8192 -s 8
# 方式二:附着到一个已存在的flink yarn session
附着到一个已存在的flink yarn session
方式一启动了4个TaskManager,每个TaskManager内存为8G且占用了8个核(是每个TaskManager,默认是1个核)。在启动YARN session的时候会加载conf/flink-config.yaml配置文件,我们可以根据自己的需求去修改里面的相关参数。启动后可以在flink web ui查看运行情况。
2.启动了yarn session之后,就可以通过flink run命令提交作业了
例如:
./bin/flink run ./examples/batch/WordCount.jar --input hdfs:///user/zhang/LICENSE
# --input是程序的入参,不是flink内部参数
1.3.2 yarn-cluster
上面的YARN session是在Hadoop YARN环境下启动一个Flink cluster集群,里面的资源是可以共享给其他的Flink作业。我们还可以在YARN上启动一个Flink作业。这里我们还是使用./bin/flink,但是不需要事先启动YARN session:
./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar \
--input hdfs:///user/zhang/LICENSE \
--output hdfs:///user/zhang/result.txt
上面的命令同样会启动一个类似于YARN session启动的页面。其中的-yn是指TaskManager的个数,必须指定。
2.flink命令参数详解
flink run参数:flink run命令执行模板:
flink run [option]
-c,--class : 需要指定的main方法的类
-C,--classpath : 向每个用户代码添加url,他是通过UrlClassLoader加载。url需要指定文件的schema如(file://)
-d,--detached : 在后台运行
-p,--parallelism : job需要指定env的并行度,这个一般都需要设置。
-q,--sysoutLogging : 禁止logging输出作为标准输出。
-s,--fromSavepoint : 基于savepoint保存下来的路径,进行恢复。
-sae,--shutdownOnAttachedExit : 如果是前台的方式提交,当客户端中断,集群执行的job任务也会shutdown。
提交项目时如何指定外部依赖jar包呢?
通过-C命令添加外部jar包的路径,但是有两点需要注意:
a、需要指定文件路径的协议:例如本地文件用file://,多个jar包用*表示,这里不支持hdfs://
b、指定的路径要flink的所有节点都能访问
例如我在做flink与kafka和hbase整合测试时,需要依赖kafka和hbase的jar包,我的做法是,将依赖的jar包传到每个flink节点的flink_home/lib目录下,然后编写如下的启动脚本:

flink run -m yarn-cluster参数
-m,--jobmanager : yarn-cluster集群
-yd,--yarndetached : 后台
-yjm,--yarnjobManager : jobmanager的内存
-ytm,--yarntaskManager : taskmanager的内存
-yn,--yarncontainer : TaskManager的个数
-yid,--yarnapplicationId : job依附的applicationId
-ynm,--yarnname : application的名称
-ys,--yarnslots : 分配的slots个数
flink run -m yarn-cluster -yd -yjm 1024m -ytm 1024m -ynm -ys 1
flink list
flink list:列出flink的job列表。
flink list -r/--runing :列出正在运行的job
flink list -s/--scheduled :列出已调度完成的job
flink cancel
flink cancel [options] : 取消正在运行的job id
flink cancel -s/--withSavepoint : 取消正在运行的job,并保存到相应的保存点
flink stop:仅仅针对Streaming job
flink stop [options]
flink stop :停止对应的job
flink modify
flink modify [options]
flink modify -p/--parallelism p : 修改job的并行度
flink savepoint(重要)
flink savepoint [options]
eg:
# 触发保存点
flink savepoint : 将flink的快照保存到hdfs目录
# 使用yarn触发保存点
flink savepoint -yid
# 使用savepoint取消作业
flink cancel -s
# 从保存点恢复
flink run -s [:runArgs]
# 如果复原的程序,对逻辑做了修改,比如删除了算子可以指定allowNonRestoredState参数复原。
flink run -s -n/--allowNonRestoredState [:runArgs]
3.flink on yarn作业提交详细流程
几个角色的作用:
JobManager :接受application,包含StreamGraph(DAG)、JobGraph(logical dataflow graph,已经进过优化,如task chain)和JAR,将JobGraph转化为ExecutionGraph(physical dataflow graph,并行化),包含可以并发执行的tasks。其他工作类似Spark driver,如向RM申请资源、schedule tasks、保存作业的元数据,如checkpoints。如今JM可分为JobMaster和ResourceManager(和下面的不同),分别负责任务和资源,在Session模式下启动多个job就会有多个JobMaster。
ResourceManager:一般是Yarn,当TM有空闲的slot就会告诉JM,没有足够的slot也会启动新的TM。kill掉长时间空闲的TM。
TaskManager类似Spark的executor,会跑多个线程的task、数据缓存与交换。
Dispatcher(Application Master)提供REST接口来接收client的application提交,它负责启动JM和提交application,同时运行Web UI。
task与slot
task是最基本的调度单位,由一个线程执行,里面包含一个或多个operator。多个operators就成为operation chain,需要上下游并发度一致,且传递模式(之前的Data exchange strategies)是forward。
slot是TM的资源子集,类似于spark的executor-core。如果一个TaskManager有三个slot,那么它会将其管理的内存分为三份(cpu是共享的)。slot的数量表示任务理论上最大的并行度,任务实际的并行度由参数parallelism决定。结合下面Task
Execution的图,一个slot并不代表一个线程,它里面并不一定只放一个task。多个task在一个slot就涉及slot sharing group。
session模式的作业提交流程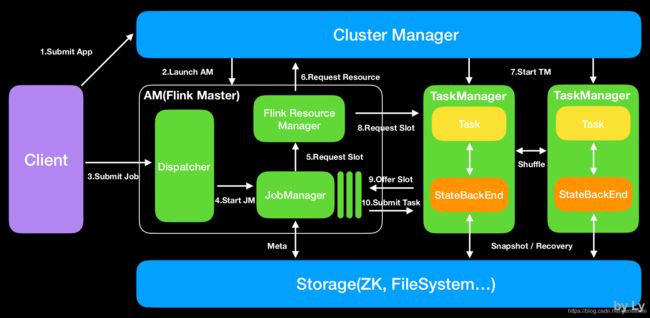
4.总结
所有模式都是通过flink run命令提交任务的(除了在idea中纯本地运行),yarn-sesion模式需要先执行一个脚本(yarn-session.sh)来开启一个session。
local模式和yarn-cluster模式提交任务时需要-m指定master,local模式指定master:-m master_ip:port,yarn-cluster模式指定master:-m yarn-cluster
standalone和yarn-session模式提交任务时不需要-m指定master。
standalone模式需要手动启动flink集群,而flink on yarn不需要启动flink集群,但必须先启动yarn和hdfs。
5.遇到的问题
5.1 采用yarn-session方式运行过项目后,再以standalone模式运行项目报错
问题描述:搭建好一个全新flink集群后,在没有运行过flink on yarn之前,直接采用standalone模式运行项目能够成功。命令如下:
./bin/flink run ./examples/streaming/SocketWindowWordCount.jar --hostname hadoop04 --port 9090
但是在运行过一次yarn-session过后,再次用standalone模式以同样的命令运行项目,就会报错:
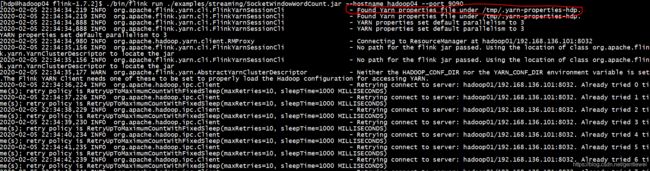
我们知道standalone模式不需要启动yarn,也不会去连接yarn,那么日志显示:发现了yarn的配置文件,flink尝试去连接yarn。由于yarn并没有启动,所以一直在重试。出于好奇,我启动了yarn,再次提交项目,又报了以下错误:
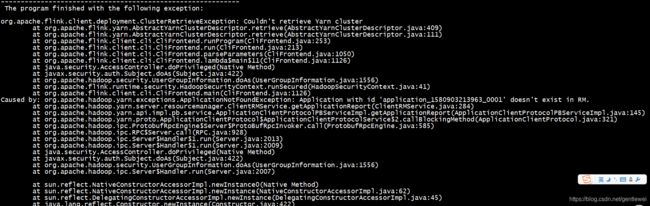
日志显示无法找到application:ApplicationNotFoundException: Application with id 'application_1580903213963_0001' doesn't exist in RM,这里怎么会有application id呢?百思不得其解。根据日志我输出了/tmp/.yarn-properties-hdp文件的内容:
发现日志中打印的application id与文件中记录的id相同。我猜测是由于运行过一次yarn-session过后,会在本地留下一个yarn的配置文件/tmp/.yarn-properties-hdp,再次以standalone模式提交任务时,flink发现了这个配置文件,便会尝试去连接yarn。
那么如果将这个文件删除,是否就可以再以standalone模式提交任务了呢?
将这个文件删除,关闭yarn,再次以同样的命令提交任务,果然成功了!!!