利用python批量生成Word合同
利用python批量生成Word合同
首先安装openpyxl和python-docx模块
安装方法: pip install openpyxl ; pip install python-docx
安装好模块后,导入相关的模块,用于读取Excel工作薄和Word文档
相应代码如下:
from openpyxl import load_workbook
from docx import Document
使用python-docx模块读取Word文档内容
doc=Document("C:\\Users\\Dell\\PycharmProjects\\untitled1\\合同模板.docx")
for para in doc.paragraphs: #遍历Word文档中的所有段落,其中paragraphs对象代表文档中所有段落的集合
for run in para.rus: #run对象代表具有相同样式的一断连续文本
print(run.text)
若Word文档中含有表格,则无法通过paragraphs对象直接读取,要通过tables对象读取
演示代码如下:
doc=Document("C:\\Users\\Dell\\PycharmProjects\\untitled1\\合同模板.docx")
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
print(cell.text)
为了后续方便调用,可编写一个自定义函数,代码如下:
def info_update(doc,old_info,new_info):
for para in doc.paragraphs: #遍历Word文档中的所有段落,其中paragraphs对象代表文档中所有段落的集合
for run in para.rus:
run.text=run.text.replace(old_info,new_info)
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
cell.text=cell.text.replace(old_info,new_info)
使用循环套用模板生成合同
info_update()函数在Word模板文档中进行查找和替换的内容来自与"合同信息.xlsx"
因此,需要使用openpyxl模块读取工作簿
wb=load_workbook("C:\\Users\\Dell\\PycharmProjects\\untitled1\\合同信息.xlsx")
ws=wb.active #使用active属性激活工作簿中的工作表
接着遍历工作表中的每一行每一列数据,传递给info_update()函数用于查找和替换
for row in range(2,ws.max_row+1): #从第二行遍历到最后一行,第一行是列标题,所以从第二行开始,range()函数是左闭右开的特性,如不加1,就遍历不到最后一行
doc=Document("C:\\Users\\Dell\\PycharmProjects\\untitled1\\合同模板.docx")#打开模板文档
for col in range(1,ws.max_column+1):#按列遍历
old_info=str(ws.cell(row=1,column=col).value)#读取当前列的第一行,即列标题
new_info=str(ws.cell(row=row,column=col).value)
info_update(doc,old_info,new_info)
com_name=str(ws.cell(row=row,column=2).value) #读取第二列的采购方名字
doc.save(f"C:\\Users\\Dell\\PycharmProjects\\untitled1\\{com_name}合同.docx")
综上所述,批量生成Word合同的代码如下:
from openpyxl import load_workbook
from docx import Document
def info_update(doc,old_info,new_info):
for para in doc.paragraphs: #遍历Word文档中的所有段落,其中paragraphs对象代表文档中所有段落的集合
for run in para.rus:
run.text=run.text.replace(old_info,new_info)
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
cell.text=cell.text.replace(old_info,new_info)
wb=load_workbook("C:\\Users\\Dell\\PycharmProjects\\untitled1\\合同信息.xlsx")
ws=wb.active #使用active属性激活工作簿中的工作表
for row in range(2,ws.max_row+1): #从第二行遍历到最后一行,第一行是列标题,所以从第二行开始,range()函数是左闭右开的特性,如不加1,就遍历不到最后一行
doc=Document("C:\\Users\\Dell\\PycharmProjects\\untitled1\\合同模板.docx")#打开模板文档
for col in range(1,ws.max_column+1):#按列遍历
old_info=str(ws.cell(row=1,column=col).value)#读取当前列的第一行,即列标题
new_info=str(ws.cell(row=row,column=col).value)
info_update(doc,old_info,new_info)
com_name=str(ws.cell(row=row,column=2).value) #读取第二列的采购方名字
doc.save(f"C:\\Users\\Dell\\PycharmProjects\\untitled1\\{com_name}合同.docx")
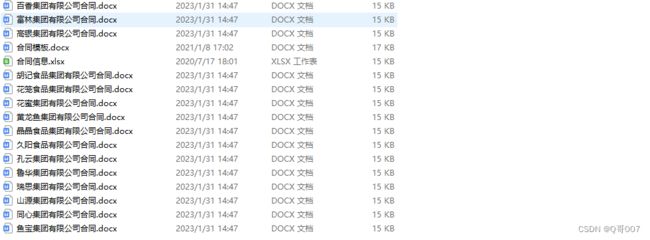
上面代码运行完成后,生成如下图的docx文件: