SeaTunnel连接器V1到V2的架构演进与探究
核心概念
整个SeaTunnel设计的核心是利用设计模式中的控制翻转或者叫依赖注入,主要概括为以下两点:
- 上层不依赖底层,两者都依赖抽象
- 流程代码与业务逻辑应该分离
对于整个数据处理过程,大致可以分为以下几个流程:输入 -> 转换 -> 输出,对于更复杂的数据处理,实质上也是这几种行为的组合:

内核原理
SeaTunnel将数据处理的各种行为抽象成Plugin,并使用SPI技术进行动态注册,设计思路保证了框架的灵活扩展,在以上理论基础上,数据的转换与处理还需要做统一的抽象,譬如比较有名异构数据源同步工具DataX,也同样对数据单条记录做了统一抽象。
在SeaTunnel V1架构体系中,由于背靠Spark和Flink两大分布式计算框架,框架已经为我们做好了数据源抽象的工作,Flink的DataStream、Spark的DataFrame已经是对接入数据源的高度抽象,在此基础上我们只需要在插件中处理这些数据抽象即可,同时借助于Flink和Spark提供的SQL接口,还可以将每一次处理完的数据注册成表,方便用SQL进行处理,减少代码的开发量。
实际上SeaTunnel最后的目的是自动生成一个Spark或者一个Flink作业,并提交到集群中运行。
SeaTunnel连接器V1 API解析
架构概览
目前在项目dev分支下,SeaTunnel连接器V1 API所在的模块如图所示:

- seatunnel-api-base:基础API层抽象
- seatunnel-api-flink:Flink引擎API层抽象
- seatunnel-api-spark:Spark引擎API层抽象
seatunnel-api-base
在基础模块中,有以下代码:
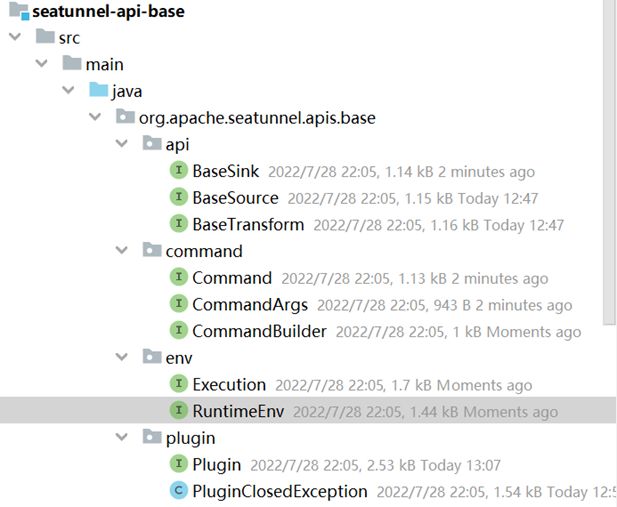
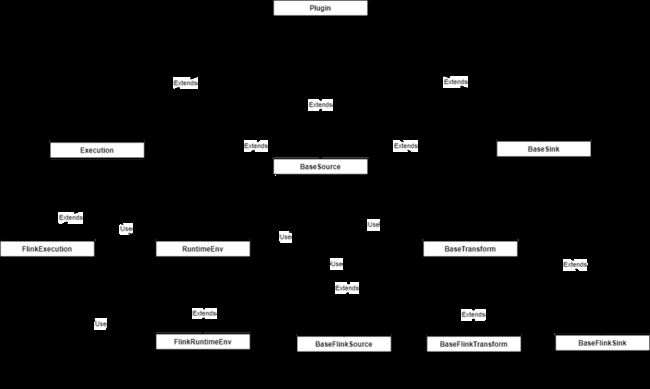
为了更清晰的理解这些类之间的关系,笔者这里制作了一张简单的UML类图:

整个API的组成可以大体分为三部分:
- 插件层:提供Source、Transform、Sink插件定义
- 执行层:提供执行器和运行上下文定义
- 构建层:提供命令行接口定义
构建层接收命令参数构建执行器,执行器初始化上下文,上下文注册插件并启动插件,至此,整个作业开始运行。
seatunnel-api-spark
在Spark引擎API层有以下代码:
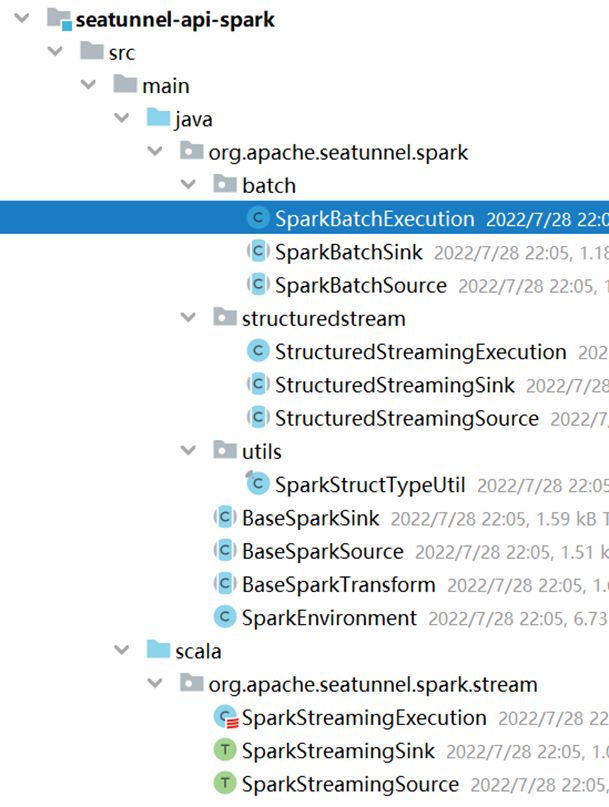
同样,笔者也整理了一张UML类图来表示它们之间的关系:
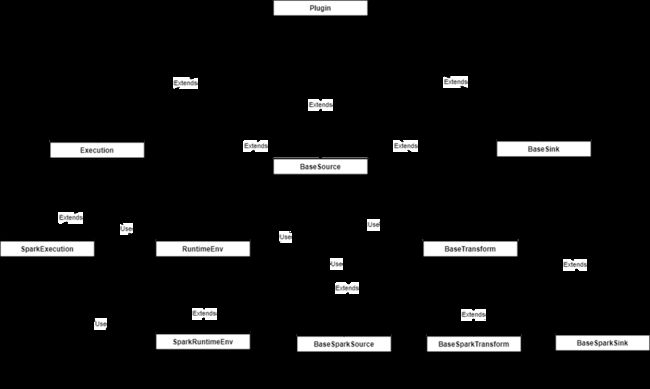
整个流程与Base模块一致,在这里笔者不过多赘述,有兴趣的读者可以自行观看源码。
seatunnel-api-flink
在Flink引擎API层有以下代码:
同样,笔者也整理了一张UML类图来表示它们之间的关系:
整个流程与Base模块一致,在这里笔者不过多赘述,有兴趣的读者可以自行观看源码。
SeaTunnel连接器V1运行原理
启动器模块概览
整个项目的最外层的启动类都放在以下模块中:
跟连接器V1有关的模块如下:
- seatunnel-core-base:V1基础启动模块
- seatunnel-core-flink:V1flink引擎启动模块
- seatunnel-core-flink-sql:V1flink-sql引擎启动模块
- seatunnel-core-spark:V1spark引擎启动模块
执行流程
为了更好的理解SeaTunnel V1的启动流程,笔者在这里制作了一张简单的时序图:

程序最外层的启动由start-seatunnel-${engine}.sh开始,用户根据将配置文件从脚本传入,脚本调用org.apache.seatunnel.core.spark.SparkStarter或者org.apache.seatunnel.core.flink.FlinkStarter,实际上这个类只做一个工作:将所有参数拼接成spark-submit或者flink命令,而后脚本接收到spark-submit或者flink命令并提交到集群中;提交到集群中真正执行job的类实际上是org.apache.seatunnel.spark.SeatunnelSpark或是org.apache.seatunnel.flink.SeatunnelFlink,读者如果想直接深入了解作业启动核心流程的话推荐阅读这两个类的源码。
执行原理
Spark
- SparkSource插件将异构数据源接入为DataFrame
- SparkTransform插件将SparkSource接入的DataFrame进行转换处理
- SparkSink插件将SparkTransform处理好的DataFrame写入到目标数据源
Flink
- FlinkSource插件将异构数据源接入为DataStream
- FlinkTransform插件将FlinkSource接入的DataStream进行转换处理
- SparkSink插件将FlinkTransform处理好的DataStream写入目标数据源
SeaTunnel连接器V2 API解析
架构概览
目前在项目dev分支下,SeaTunnel连接器V2 API所在的模块如图所示:
- seatunnel-api:连接器V2所有的API定义
数据抽象
SeaTunnel连接器V2 API在数据层面做了抽象,定义了自己的数据类型,这是与连接器V1最大的不同点,连接器V1使用的是引擎数据抽象的能力,但是连接器V2自己提供的这个异构数据源统一的能力:

在所有的Source连接器和Sink连接器中,处理的都是SeaTunnelRow类型数据,同时SeaTunnel也对内设置了数据类型规范,所有通过Source接入进来的数据会被对应的连接器转化为SeaTunnelRow送到下游。
API Common
在API common包下有以下接口的定义:
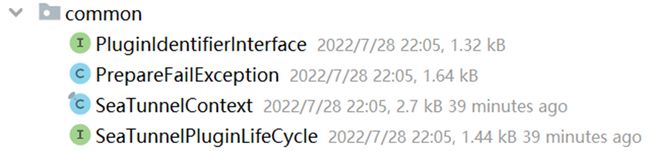
在这里由于篇幅关系只介绍比较核心的几个接口:
- PluginIdentifierInterface:插件唯一标识
- SeaTunnelContext:SeaTunnel应用上下文,每个SeaTunnel Job包含的上下文对象,保存了当前源表的元数据
- SeaTunnelPluginLifeCycle:插件声明周期
具体接口中有哪些方法读者可以自行阅读对应类的源码,在这里笔者将不过多赘述。
API Source
在API source包下有以下接口的定义:

在这里由于篇幅关系只介绍比较核心的几个接口:
- Boundedness:标识数据有界无界,连接器V2设计理念基于批流一体,此接口用于区分流式作业还是批式作业
- Collector:数据收集器,用于收集Source连接器产生的数据并推往下游
- SeaTunnelSource:Source插件基类,所有的Source连接器主类均继承于这个接口
- SourceReader:Source插件真正处理数据接入的接口
- SourceSplit:数据分片接口,连接器V2支持数据并行读入,提升数据接入效率
- SourceSplitEnumerator:数据分片器,此接口用于分发数据分片至对应的SourceReader中
API Sink
在API sink包下有以下接口的定义:
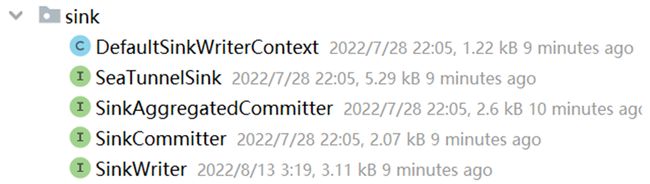
在这里由于篇幅关系只介绍比较核心的几个接口:
- SeaTunnelSink:Sink插件基类,所有的Sink连接器均继承于这个接口
- SinkWriter:Sink插件真正实现数据输出的接口
- SinkCommitter:用于处理
SinkWriter#prepareCommit返回的数据信息,包含需要提交的事务信息,连接器V2在Sink设计上提供二阶段提交的接口,从而使连接器有了实现Exactly-Once的可能性 - SinkAggregatedCommitter:用于处理
SinkWriter#prepareCommit返回的数据信息,包含需要提交的事务信息等,用于在单节点多任务一起提交事务信息,这样可以避免提交阶段二部分失败导致状态不一致的问题(注:在实现连接器时优先实现这个接口,这样会兼容性更强)
小结

连接器V2在架构分层上与计算引擎进行解耦,定义了自己的元数据定义以及数据类型定义,在API层和计算引擎层增加了翻译层,将SeaTunnel自定义的数据源通过翻译层接入到引擎中,从而真正实现接口和引擎分离的目的。
SeaTunnel连接器V2运行原理
启动器模块概览
整个项目的最外层的启动类都放在以下模块中:
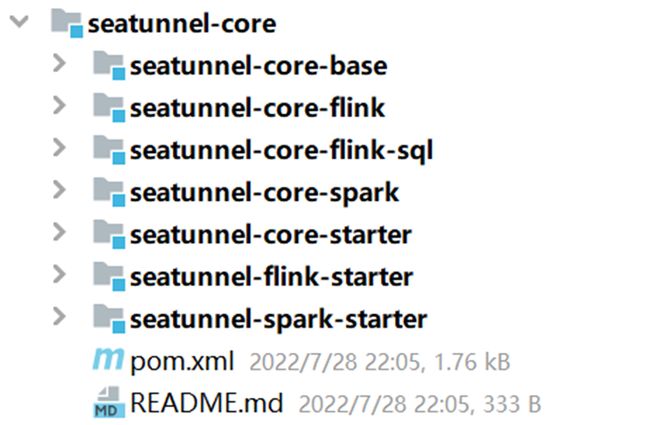
跟连接器V2有关的模块如下:
- seatunnel-core-starter:V2基础启动模块
- seatunnel-flink-starter:V2flink引擎启动模块
- seatunnel-spark-starter:V2spark引擎启动模块
执行流程
为了更好的理解SeaTunnel V2的启动流程,笔者在这里制作了一张简单的时序图:
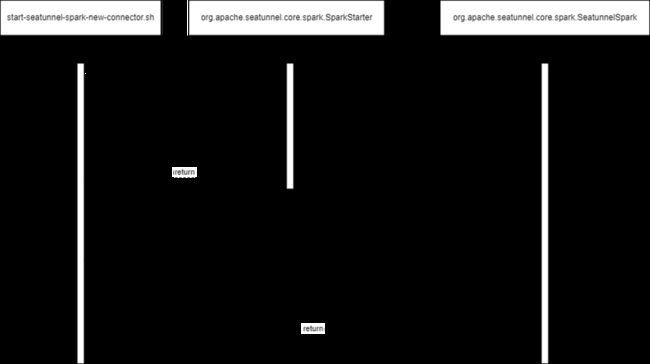
程序最外层的启动由start-seatunnel-${engine}-new-connector.sh开始,用户根据将配置文件从脚本传入,脚本调用org.apache.seatunnel.core.spark.SparkStarter或者org.apache.seatunnel.core.flink.FlinkStarter,实际上这个类只做一个工作:将所有参数拼接成spark-submit或者flink命令,而后脚本接收到spark-submit或者flink命令并提交到集群中;提交到集群中真正执行job的类实际上是org.apache.seatunnel.spark.SeatunnelSpark或是org.apache.seatunnel.flink.SeatunnelFlink,读者如果想直接深入了解作业启动核心流程的话推荐阅读这两个类的源码,连接器V2和连接器V1的启动流程基本一致。
SeaTunnel V2 on Spark

SeaTunnel Source连接器V2将异构数据源接入,生成以SeaTunnelRow为基本单位的数据源,在翻译层实现了Spark DataSource API V2,翻译层使得Spark可以接入以SeaTunnelRow为基本单位的数据源,从而实现无缝接入Spark的目的。
关于Spark DataSource API V2的详细信息,读者可以参考:https://www.databricks.com/session/apache-spark-data-source-v2,由于这篇文章的主题并不是介绍Spark的特性,所以笔者在这里不过多赘述。
SeaTunnel V2 on Flink

SeaTunnel Source连接器V2将异构数据源接入,生成以SeaTunnelRow为基本单位的数据源,同时在翻译层实现了Flink source function和Flink sink function,翻译层使得Flink可以接入以SeaTunnelRow为基本单位的数据源,从而实现无缝接入Flink的目的。
关于Flink source Function和Flink sink function的详细信息,读者可以参考:https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/datastream/sources/#the-data-source-api,由于这篇文章的主题并不是介绍Flink的特性,所以笔者在这里不过多赘述。
执行原理
Source连接器接入数据源为SeaTunnelRow,Translation层转换SeaTunnelRow数据源为各种计算引擎内部的数据源,Sink 连接器接收计算引擎内部转换好的SeaTunnelRow数据源并写入到目标数据源中。
V1 API vs V2 API
| 特征 | 连接器V1 | 连接器V2 |
|---|---|---|
| 引擎依赖 | 强依赖Spark、Flink | 无依赖 |
| 连接器实现 | 针对不同引擎要实现多次 | 只实现一遍 |
| 引擎版本升级难易程度 | 较难,连接器与引擎高度耦合 | 较易,针对不同版本开发不同翻译层即可 |
| 连接器参数是否统一 | 针对不同引擎可能会有不同参数 | 参数统一 |
| 自定义分片逻辑 | 依赖Spark、Flink已经实现好的数据Connector,分片逻辑不可控 | 分片逻辑可自定义 |
未来展望
目前社区正在做的事情:
- 连接器接入,社区计划在年底接入80+种数据源
- Web服务化,社区目前在做Web服务化相关工作,用户可根据Web界面进行作业的管理、日志查看、上下线操作
- 计算引擎开发,社区目前在开发自己的计算引擎,更专注于数据同步,提升性能
未来目标:
- 性能优化,多维度指标监控,精确流速控制,可视化大屏监控
- 可视化拖拉拽快速生成数据集成任务
- 更多调度平台无缝接入
最终目标:成功从Apache孵化器毕业,成为世界一流的诞生于中国的数据集成平台工具
贡献者招募
目前社区正在蓬勃向前发展,大量feature需要去开发实现,毕业之路道阻且艰,期待更多的有志之士参与到社区共建,欢迎热爱开源的小伙伴加入SeaTunnel社区,有意者可发邮件至[email protected]或微信tyrantlucifer联系我咨询相关事宜,让我们一起用开源点燃璀璨的程序人生。