【SeaTunnel】从一个数据集成组件演化成企业级的服务
点亮 ⭐️ Star · 照亮开源之路
GitHub:https://github.com/apache/incubator-seatunnel
在 7 月 24 日 Apache SeaTunnel(Incubating)&Apache Doris 联合 Meetup 上,一个普通的社区贡献者狄杰,给大家带来的演讲主题是SeaTunnel的服务化之路,主要是和大家聊一下,SeaTunnel如何从一个数据集成组件演化成企业级的服务。
今天的分享主要分为四个部分:
-
服务化的初衷与价值
-
服务的整体架构
-
社区的当前进展
-
Roadmap
为什么要做服务化?
从2019年开始,社区对于Web服务的呼声很高,当时就有人在issue里面提及Web服务的事情,一直到今年的5月份周会都还有人在讨论,也有人说在社区贡献,但可能因为种种原因没有了下文。
在之前的Meetup分享,也有同学分享基于SeaTunnel实现了可视化的数据集成服务。我一直从事数据中台的相关工作,觉得服务化对SeaTunnel来说是必不可少的部分,而且对开源也比较感兴趣,所以就结合了社区的意愿,决定着手做这件事。
核心目标是什么?
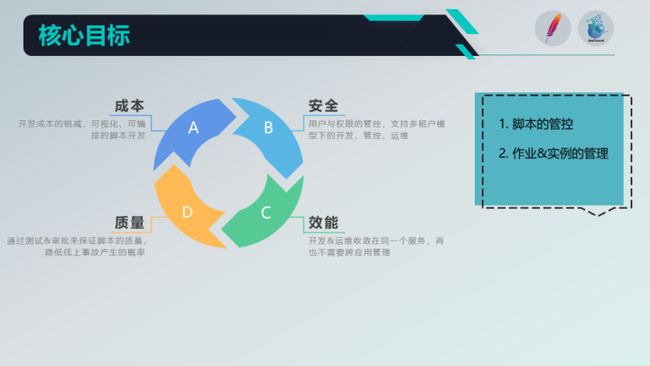
脚本的管控
让用户通过WebUI,以参数的形式配置任务信息,比如:输入/输出数据源、各种transform的配置、env参数等等;总而言之,就是尽可能的让用户通过配置而非脚本的方式来表达自己的业务需求。
之前的公司没有数据平台,使用的是Datax+Azkaban分别作为数据采集的组件和调度执行的组件,使用Git作为代码管理;一个熟手配置一个数据集成任务大约通过7步:**编辑,Commit,Push,打包,上传,页面操作,数据校验;**一个任务的开发最起码需要30~60分钟,还必须保证这中间不能被打扰,没有出现异常情况。后来我们做了自己的数据平台之后,配置一个数据交换任务只需要分钟级别。
作业及实例的管理
这里讲一个基本概念,一个SeaTunnel的任务,在开发时,一般称呼它为脚本,经过测试并发布后,我们才会称其为作业。而作业通过触发后,具体的执行则被称为执行实例。
作业的管控:手动触发(包含补数据和单次触发)、暂停调度、查看上下游依赖、查看作业内容等等。
实例的管控:重跑、KILL、查看日志等等。
通常来说,这部分能力是由整个大数据生态体系中的调度系统来承担,比如说DolphinScheduler、Azkaban等。那么,为什么我们要在SeaTunnel里做这些事情?先暂时留个悬念,等到整体架构时会跟大家讲解我的想法。

当我们完成了这两项的能力建设后,SeaTunnel可以算上是个完整的数据集成解决方案,任意一个人、或者企业,当完成下载和简单配置后,即可快速的完成数据采集任务的定义,通过将任务发布到调度系统或者内置的调度引擎中,即可完成任务的周期性调度,快速、准确、定时将业务数据、应用日志等数据同步到大数据存储平台或者OLAP引擎中,快速进行数据分析,加速数据价值的产生;所以说,这两点是我们最核心的目标
上述可以看成给用户的价值
那么服务化能给SeaTunnel自身带来什么呢?
在没有SeaTunnel或者说没有waterdrop的时候(ST的曾用名),waterdrop的开发同学一开始使用Spark进行数据集成,发现可以通过对常用的操作用代码沉淀,对一些操作进行封装,久而久之就形成了早期的waterdrop,这便是从基础的数据开发组件Spark组件演化成数据集成工具的过程。
后来,SeaTunnel开始做自己的运维管控平台,将SeaTunnel的脚本、开发工具、开发流程整合在一起,统一管理,形成体系化的运维开发管控一体化的平台。 而平台化带来了管控、开发、运维等能力,能够更好的吸引用户来使用SeaTunnel,同样也会吸引一些同学加入SeaTunnel的社区,这对我们社区的发展无疑是极大的利好。
服务的整体架构

整体上来说,目前暂时分为三个大部分
-
**管控:**对数据源、用户、权限、脚本、作业、实例的管控,任何在WebUi上看到的内容都会被管控;
-
**调度:**根据配置的不同,负责将任务丢至不同的调度系统中进行调度与执行;上层的作业和实例的管控也依赖于具体的调度系统;
-
**执行:**任务具体执行时的一些事项,大家能够看到我在这做了task-wrapper,作用下面跟大家详细讲;
管控简述
管理能力

针对于数据源的增删改查以及连接性测试,后续会支持数据源的映射、数据探查等的能力。
除增删改查之外,无非是注册、登录、退出等;但是如果要将SeaTunnel做到顶级的、自成体系、多租户环境下的数据集成服务,那么用户的管理会更加复杂
页面上每个能看见的页面、菜单、按钮、数据等,都应该纳入管控,除此之外,肯定还有更多东西可以纳入管理模块,比如资源管理、自定义connector、trasnform管理、项目空间等等,不过这些都不在我们的主流程范围内,并且也确实没有用户提出这方面的需求,所以我们之后再看。
开发能力
基本上就是针对的脚本的增删改查,最突出最主要的也就是脚本的编辑时的能力:保存、执行、停止、测试、发布、基本参数展示、调度参数配置、告警参数调整、脚本内容、数据源、transform、并发等;这里面其实有很多内容要讲,比如测试,通常来说是替换输出源,通过控制台输出,人工来判断脚本配置是否正确,而如果要做的更智能化一点,完全可以做成单元测试一样,每个脚本必须通过单元测试之后才能够发布上线,而单元测试就像平常我们写JAVA的单元测试一样,Mock数据,验证过程。
再说到发布,这是从脚本演变成作业必不可少的一步,**只有发布成功的脚本才会真正的同步到调度系统中,**而发布中我们可以做很多事情,比如必须经过测试的脚本才能够发布成功,而在提交了发布申请后,会形成OA审批流或者工作流,只有通过审批后才能真正的发布等等;
当然,因为SeaTunnel本身的定位是一个弱T的数据集成组件,我们不会有太多的ETL逻辑,而且我们只会有SeaTunnel一种类型的任务,所以我们不会做类似于文件夹管理、目录树那样的能力,那种能力我觉得还是更适合有单独的组件,比如开源的WEB IDE来做这些事情。
运维能力
作业运维与实例运维 就像我之前说的那样,作业的运维一般是:**手动触发(包含补数据和单次触发)、暂停调度、查看作业内容等,**而实例的运维一般是:**重跑、KILL、查看日志等,**不过值得注意的是,我们的作业有实时和离线之分,所以在作业和实例的运维上有不同的体现:实时任务不存在调度周期、不存在任务依赖,所以实时任务的运维会有不同的体现。
调度简述
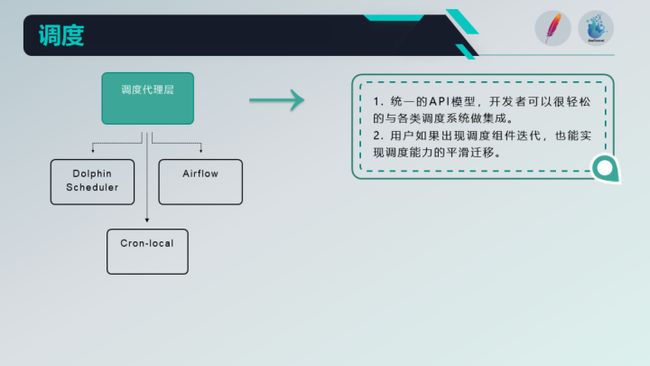
调度是很关键的一环,分成两个部分:
调度代理
大家肯定很疑惑,为什么要在SeaTunnel里面做一些调度相关的事情,比如上面说的作业运维与实例运维,为什么没有在脚本推送到调度系统后,直接在调度系统实现管控、运维的能力?
首先,我们想SeaTunne自成体系,而不是依赖于别的组件才能完成一些能力。其次,调度系统有很多且每个API和能力的表现是不一致的,我们必需为每一种调度系统实现一次集成,如果没有抽象的API层,那么整个代码会显得非常混乱并且难以管理 。
最后,如果我们只针对一种调度系统做实践,那么难度自然会低很多,但是我们就必然会失去使用其它调度的用户;当然,他们也可以像过去一样,通过Shell脚本的方式来进行任务调度,那样服务化的意义也就失去了很多。
crontabl-local 存在的意义是什么?
对小微型用户来说,他们可能都没有大数据平台或者数仓方面的专业人士,他们过去是通过MYSQL或者PYTHON脚本进行数据分析,而随着数据量的增多,用MYSQL和PYTHON跑分析型任务已经又慢又费资源,所以可能选择了使用一些OLAP引擎;而他们想对业务库的数据进行分析的时候,自然而然的需要用SeaTunnel去将数据同步到OLAP引擎中;
小微型用户没有数据类的专业人士,所以大数据平台必然是没有的,更别提调度系统了。而这时crontabl-local就体现了他存在的意义:我们的SeaTunnel自成体系,我们自身就提供了简单的定时调度能力,用户只需要简单的修改一下配置,即可快速上手,完成定时数据集成任务的配置与发布。
执行态task-wrapper

我们通过 IDE 打开,会看到如图所示的目录结构:
它提供了pre-task和post-task的能力,之所以设计这么个能力,是考虑到仅靠SeaTunnel原生的能力是不够的。
比如schema-evolution、分库分表下的同步预处理、动态分区、数据质量等。当然,用户自己也可以通过调度的依赖来实现相应的能力,不过很多时候POST-TASK需要和SEATUNNEL的执行脚本合并在一起,保证事务的一致性,如果拆成两个任务就无法保证。 我们提供了pre-task和post-task的能力,与SeaTunnel的执行引擎进行组装,变成真正的执行内容;同时我们也支持用户自己实现这两种task类型,来实现他们的业务流程。
除了pre-task和post-task,另外一块比较关键的是真正的执行脚本,它需要将我们向导模式和画布模式翻译成真正的执行脚本,再与pre-task和post-task进行打包,一起传递给真正的调度系统;
社区当前的进度
开发进度追踪

大家可以通过Github上的1947issue号进行进度追踪,大家可以看到在下图贴的3个链接,第一个是总体的设计以及整体的进度追踪。第二个是有关于脚本管理&用户管理相关的PR,已经MERGE。第三个是有关于调度代理层的设计以及DolphinScheduler的集成,相关内容已经开发完毕,预计月内能够把PR给MERGE.
脚本编辑模式

目前只支持脚本模式,我们可以在这个页面进行脚本的编辑开发,右侧这个预览方便于用户更好的定位自己的代码;不过目前这里缺少了基本信息、参数配置、调度配置的入口,已经和社区产品的同学在沟通,后续这边也会加上去.
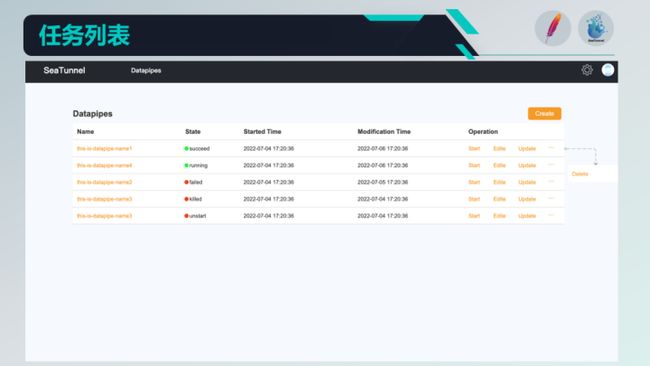
在保存完脚本后,会来到上图,这里也是创建脚本的入口,start/edit是启动和编辑;这里的update后续会改为publish,也就是发布;一个脚本被发布了之后才能进行启动、停止等操作;再看看状态,这里的状态其实是取的这个任务最近一次执行的状态,如果没有执行记录就是unstart,其它的比较好理解,就不再赘述了。
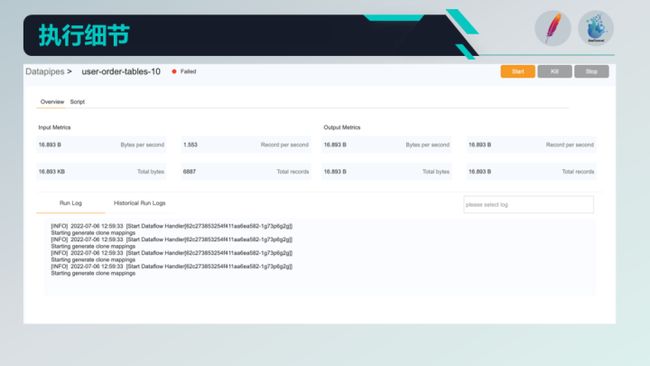
点击任何一个任务名称后,会进到这个页面;这里能看到任务执行的指标信息、输入输出数据条数、数据大小、耗费时间等;另外还有本次的运行日志等;这里能够看到历史的执行记录
更多的产品原型图可以参考issue-2100的内容,我们产品的同学里面有更多的图片展示
什么时候能用上SeaTunnel-Server?
罗马不是一天可以建成的,我们会做出一个稳定可用的最小MVP版本,MVP版本都包含哪些内容?
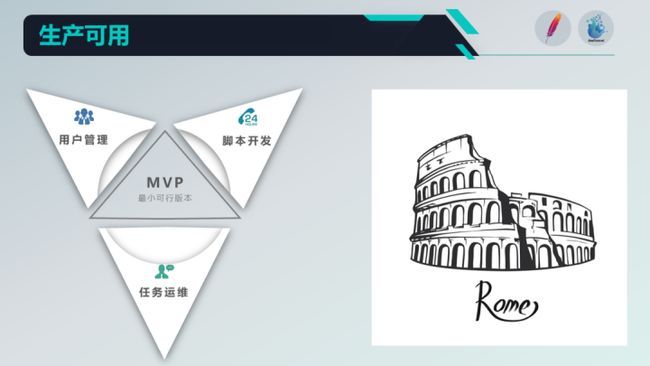
1、用户管理:包含对用户的增删改查以及登录、退出能力;
2、脚本开发:包含对脚本的增删改查,其中脚本开发只支持脚本模式,我之前在issue里面也有说过,分别有三种模式:向导模式也就是配置化的方式——先选输入源,再输入输出源,再配置字段映射等等;脚本模式就是直接将SeaTunnel的脚本贴进来;画布模式就是俗称的拖拉拽;
3、**任务运维:**针对于发布后的脚本进行执行、停止、查看记录、查看日志相关操作;
ROADMAP
我们现在最关键的是完成MVP版本的设计与开发,包括用户、脚本、任务运维,相当于是1.0版本之后我们大概是2个月完成一次迭代,预计到年底能够完成2个小版本的迭代。
**【1.1 版本】**将数据源管理纳入,让用户更加专注于业务代码开发;
**【1.2 版本】实时任务的开发、管控、运维,**为什么要先将实时和离线分开来做呢?主要是因为实时任务通常时7*24的模式,它的运行状态和在调度系统上表现的实例状态其实是不一致的;
**【1.3 版本】用户权限的管控,**这里的顺序和工作内容都是我暂时拍的,如果有更多的人加入进来,我想版本的内容可以更丰富,可以更快的迭代;

而大家关心的向导模式,会在明年的时候才进行设计&开发;因为这个对前端&后端都有比较多的依赖;整个2.0版本我们主要做好这几件事:
-
向导模式的从零到有到完善
-
任务运维的全覆盖:也就是完善对运维这个模块的能力;并且可能会有更多的调度系统接入,比如Airflow、Azkaban等等;
-
通过pre-task和post-task的能力来实现业务能力

并且,随着我们SeaTunnel自身引擎的发展,我相信会对我们的开发、运维带来更多的能力和便利性;
比如脚本可以配置脏数据收集、流控等参数;运维侧我们可以看到SeaTunnel更加专业、更加明确的数据集成指标,到时候可以直接将指标的展示集成在我们的SeaTunnel webui上;
我们预计用6~10个月的事情来做完善这些事情,并且需要与引擎侧的社区贡献者们配合.
至于3.0版本就是很久远的事情了,应该是会有画布模式、资源管理、流批一体能力的全方面覆盖,最后,也欢迎大家来做相关贡献,加入我们 Apache SeaTunnel 大家庭!谢谢大家
Apache SeaTunnel
// 保持联络 //
微信号 : Seatunnel
来,和社区一同成长!
Apache SeaTunnel(Incubating) 是一个分布式、高性能、易扩展、用于海量数据(离线&实时)同步和转化的数据集成平台。
仓库地址: https://github.com/apache/incubator-seatunnel
**网址:**https://seatunnel.apache.org/
**Proposal:**https://cwiki.apache.org/confluence/display/INCUBATOR/SeaTunnelProposal
**Apache SeaTunnel(Incubating) 2.1.0 下载地址:**https://seatunnel.apache.org/download
衷心欢迎更多人加入!
能够进入 Apache 孵化器,SeaTunnel(原 Waterdrop) 新的路程才刚刚开始,但社区的发展壮大需要更多人的加入。我们相信,在**「Community Over Code」(社区大于代码)、「Open and Cooperation」(开放协作)、「Meritocracy」**(精英管理)、以及「**多样性与共识决策」**等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步!
我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源!
**提交问题和建议:**https://github.com/apache/incubator-seatunnel/issues
**贡献代码:**https://github.com/apache/incubator-seatunnel/pulls
订阅社区开发邮件列表 : [email protected]
**开发邮件列表:**[email protected]
**加入 Slack:**https://join.slack.com/t/apacheseatunnel/shared_invite/zt-1cmonqu2q-ljomD6bY1PQ~oOzfbxxXWQ
关注 Twitter: https://twitter.com/ASFSeaTunne