腾讯云基于 Apache Pulsar 跨地域复制功能实现租户跨集群迁移
导语
本文整理自 Pulsar Summit Asia 2022 技术峰会上腾讯云中间件高级研发工程师韩明泽的分享《基于跨地域复制实现租户跨集群迁移》。本文主要介绍基于跨地域数据复制和订阅进度同步的实现及优化,以及腾讯云在跨集群迁移过程中遇到的问题及租户跨集群迁移解决方案。
作者简介
韩明泽
毕业于武汉大学,腾讯云中间件高级研发工程师,拥有多年消息中间件开发与运维经验,RoP (RocketMQ-on-Pulsar) Maintainer,Apache Pulsar 贡献者。
订阅进度同步的实现及优化
跨地域复制简介
跨地域复制是 Apache Pulsar 提供的跨机房数据复制能力。其典型的使用场景有:
- 多机房数据复制,即数据容灾备份
- 异地读写
下图为典型的异地读写案例,假定在北京生产与写入,而在上海消费,在对从生产到消费整体链路耗时要求不高的情况下,即可采用跨地域复制的能力。同地域写入的时间成本相对较低,而比较耗时的消费可以在内部通过跨地域复制屏蔽。

跨地域复制集群复制功能实现原理
如果 Apache Pulsar 不提供跨集群复制功能,如何在运维 RocketMQ 或者 Kafka 等情况下实现跨地域数据复制、容灾者备份和集群间数据迁移的工作?
通常情况下,服务中有生产者和消费者两个角色,消费者连接上游集群,生产者连接下游集群。上游集群的消费数据通过生产者发送到下游目标集群。Apache Pulsar 在跨地域复制的设计中采用了类似思路,跨地域复制实现的流程如下图所示。
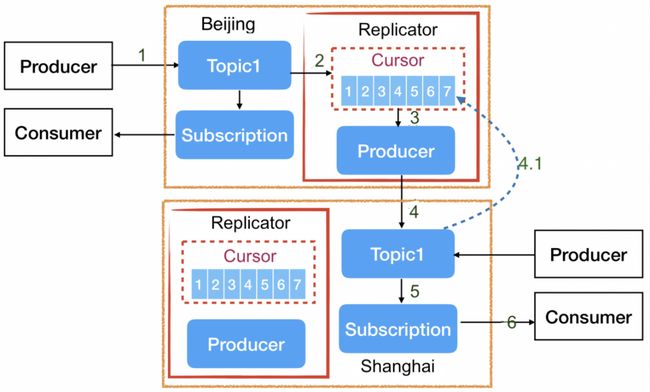
在每个主题内部设置了 Replication 模块。如果开启数据复制,此模块则会发起内部订阅(或游标进度)。在任一主题内消费消息时,生产者向对端集群投递消息来实现跨集群数据的复制功能,不影响本集群的生产消费。在上述的过程中,消息的读取与发送完全异步处理。
订阅进度同步的实现原理
数据复制与同步的实现比较简单,但在一些场景中,除了同步消息,还需要同步订阅的消费进度。
以异地容灾为例,假设原本业务的生产消费均在北京,当北京集群业务出现故障时,业务端想快速将集群切换到上海集群,以继续从北京集群已经消费到的位置开始做生产和消费。
如果没有订阅进度同步的能力,那么用户很难确定在北京集群里哪些消息已经消费过;如果从最新的位置开始消费,可能会导致消息丢失;如果从最早的位置开始消费,会造成大量的重复消费。在实际操作中,稍微折中的方法是通过时间回溯退回到较近的时间点。然而,这种方法无法从根本上解决消息丢失或者重复消费的问题。
而 Apache Pulsar 所提供的订阅进度同步的功能,则可以让用户平滑地完成异地容灾的切换,不用担心消息的丢失或者重复。Pulsar 同时支持数据同步和订阅进度同步,如下图所示。
消费进度
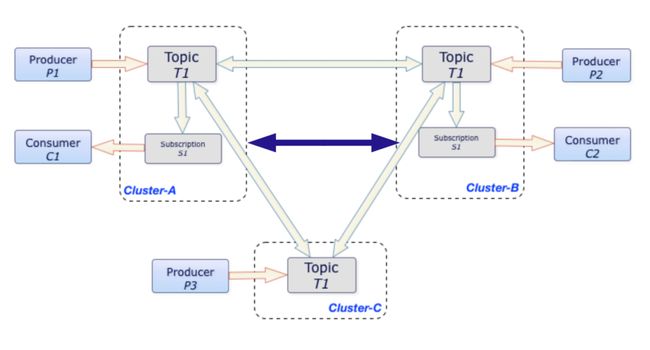
消费进度由 markDeletePosition 和 individuallyDeletedMessages 两部分组成。在 RocketMQ 和 Kafka 中,消费进度在分区上通过 Offset 标识。Offset 对应 Pulsar 中的概念可以理解为 markDeletePosition。
Pulsar 同时支持多种消费模式,它的消息确认机制/签收机制支持单条确认。因此,在 Pulsar 中除了需要记录 markDeletePosition,还需要 Individual Acks 记录单条被确认的消息。

如上图,在共享消费模式下有很多消费者实例。由于每个消费者的消费速度不一样,消息的推送顺序和消息 Ack 顺序并不完全相同。假定我们需要把标号为 0 到 9 的消息同时推送给不同的消费者实例,消息 0、1、2、3、4、6、9 已经确认,但是 5、7、8 并没有确认。markDeletePosition 的游标位置,即 Offset 标识的消费进度只能标识到 4 的位置,表示 4(包括 4)之前的消息都已经被消费。消息 5、7、8 已经被消费,需要单独确认。Pulsar 通过 individuallyDeletedMessages 数组对象范围去标识哪些消息已经被确认过。我们可以将上述消息的确认理解为几个开闭区间,从中可以明显得出 5、7、8 没有被消费。
Message ID 对应关系
在 Pulsar 中,订阅进度同步的复杂性在于同一条消息在不同集群中的 Message ID 不一致,这也是 Pulsar 相较于 Kafka 和 Rocket MQ 而言比较复杂的地方。在 Kafka 分区里只有 Offset 一个概念,而在 Pulsar 中,Message ID 由 Entry ID 和 Ledger ID 组成。同一条消息在不同集群里存储的 Entry ID 和 Ledger ID 无法保持一致。
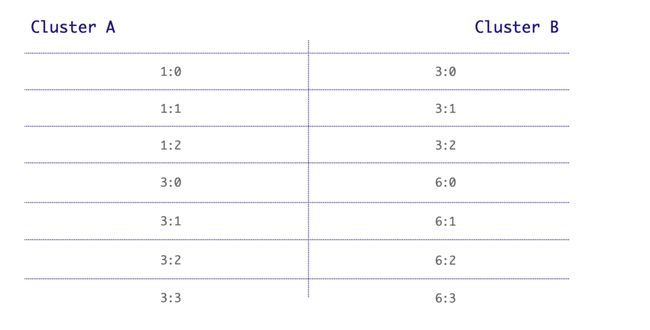
如上图所示,在 A 和 B 两个集群中,消息 1 在集群 A 中的 ID 是 1:0,而在集群 B 中的 ID 是 3:0;消息 2 在集群 A 中的 ID 是 1:1,在集群 B 中的 ID 是 3:1。如果同一条消息在两个集群中的 ID 完全一致,同步消费进度非常容易,比如 ID 为 1:2 的消息在集群 A 中被消费,集群 B 同步确认消息 1:2 即可。但是由于 Message ID 不一致,或者在不知道 Message ID 间对应关系的情况下,没有办法直接将不同集群间的消息对应起来。
所以关键问题就在于,如何知道 Message ID 间的对应关系?其实这也是最为复杂的地方,我们只有清楚集群间同一 Message ID 的对应关系,才能在集群 A 确认消息 1:2 之后,同步在集群 B 确认消息 3:2,或者更新其 markDeletePosition。
构建 Cursor Snapshot
在原生 Pulsar 里通过定期构造 Cursor Snapshot 的机制来实现 Message ID 间的彼此对应。
"ReplicatedSubscriptionSnapshotRequest":{
"snapshot_id":"444D3632-F96C-48D7-83DB-041C32164EC1",
"source_cluster":"a"
}
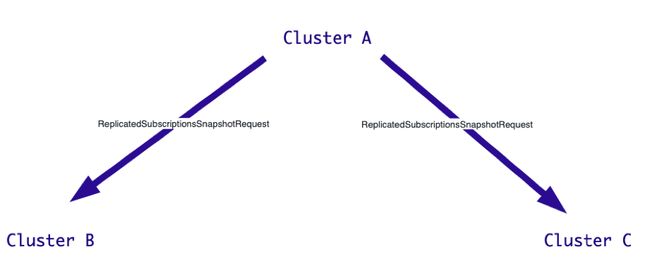
以上图为例,集群 A 确认消息 1:2 时通过快速构建 Snapshot 向集群 B 和 C 发送请求,请求其告知集群 A 此消息在其集群中的位置信息。
集群 A 会定期向其他集群发送 Replicate Subscription Snapshot Request。集群 B 在收到集群 A 的请求之后会回发响应,将当前复制到的最新消息位置发送给集群 A。
"ReplicatedSubscriptionSnapshotResponse":{
"snapshotid":"444D3632-F96C-48D7-83DB-041C32164EC1",
"cluster":{
"cluster":"b",
"message_id":{
"ledger_id":1234,
"entry_id":45678
}
}
}
集群 A 收到对端集群 B 和 C 返回的当前消息的位置后,就会构造起 Message ID 间对应关系。如下图所示,集群 A 中 Message ID 为 192.123123 的消息,在集群 B 中对应 ID 为 1234.45678,在集群 C 中对应 ID 为 7655.13421。
代码如下:
{
"snapshot_id":"44403632-F96C-48D7-83DB-041C32164EC1",
"local_message_id":{
"ledger_id":192,
"endtry_id":123123
},
"clusters":[
{
"cluster":"b",
"message_id":{
"ledger_id":1234,
"endtry_id":45678
}
},
{
"cluster":"c",
"message _id";{
"ledger_id":7655,
"endtry_id":13421
}
}
],
}
Message ID 间对应关系的构建并不复杂,但是实现逻辑会相对复杂。Cursor Snapshot 构造完成之后会形成一种对应关系作为 Cursor Snapshot Maker 写入到原主题。

如上图,阿拉伯数字表示业务主题里的业务消息,字母 S 表示不同集群间构造出来的 Cursor Snapshot 数据。当消费到 Snapshot Marker 时会把对应的 Snapshot Marker 加载到内存里。比如,我们在集群 A 中 Mark Delete 到消息 3 的位置时,可以根据 S 里面记录的集群 B 中的消息位置来更新集群 B 的 markDeletePosition。
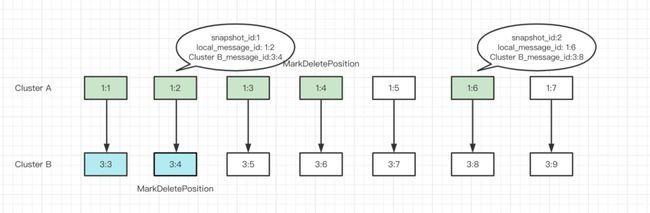
以上图为例,在集群 A 中消息 1:2 和消息 1:6 的位置分别有一个 Snapshot,消息 1:1、1:3、1:4、1:5 和 1:7 是普通消息。当集群 A 中 markDeletePosition 更新到 1:4 时,消息 1:2 在 1:4 之前并且有 Snapshot,就可以快速到集群 B 去确认消息 3:4,并更新该位置的 markDeletePosition。
订阅进度同步
订阅进度同步过程中存在的问题
订阅进度同步过程中存在的问题也是租户跨集群迁移过程中卡点的问题:
- 只同步 markDeletePosition,不同步 individuallyDeletedMessages。
这会导致在单条消息确认时存在很多消息确认空洞,对存在定时消息的场景也会产生较大的影响。假定一个主题里有定时消息和普通消息,定时消息的时间是在一天后,也就意味着定时消息的确认时间需要延迟一天。由于 markDeletePosition 只能记录此时已经被全部确认过的消息的位置,因此在定时消息被确认时,markDeletePosition 还是一天前的位置。如果用户此时切换集群,就会造成消息重复消费,至少一天的消息会被重复消费。
- 消息堆积会导致无法同步消费进度。这与 Cursor Snapshot 的创建机制有关。
如前文提到的,通过集群 A 构建与集群 B 和 C 之间的 Snapshot 时的请求并不是通过 RPC 接口发出的,而是借由我们此前提到的 “S” 带入。在订阅进度或者消息同步的过程中,消息堆积不可避免,导致请求也被写入到本地主题。由于对端消息堆积,且主题内部都会设置超时机制,如果在规定时间内收不到构建 Snapshot 的请求,Snapshot 就无法构建成功,进而无法同步订阅进度,markDeletePosition 也无法同步。
- 定期 Cursor Snapshot 机制。
沿用前面我们在讲同步消费进度时所提到的案例,在集群 A 和集群 B 中,集群 A 中消息 1:2 与消息 1:6 与集群 B 之间有 Snapshot,普通消息间没有 Snapshot。如果此时集群 A 的 markDeletePosition 更新到 1:4,由于此位置上两个集群之间并不存在 Snapshot,所以集群 A 无法确认该条消息在集群 B 中对应消息位置,这也是当前机制中存在的问题。
综上所述,订阅进度同步过程中存在的问题主要在于只同步 markDeletePosition 而不同步 individuallyDeletedMessages,有时虽然同步了 markDeletePosition,但由于本身机制的问题会影响准确性或者出现消息堆积的情况。
订阅进度同步优化
上述问题在租户迁移过程中会造成大量的重复消费,常见且难解。在一些真实用户在线业务场景中,少量、短暂且可控范围内的重复消费可以接受,大量的重复消费不允许存在。
为了解决上面的问题,我们优化了订阅进度同步的逻辑,在集群迁移之前需要同步 markDeletePosition 和 individuallyDeletedMessages。在同步过程中,最大的问题仍然是同一消息在不同集群中 Message ID 的对应。即使集群 A 的 markDeletePosition 和 individuallyDeletedMessages 全部都同步到集群 B,但是集群 B 仍然无法确定 individuallyDeletedMessages 对应的本集群的 Message ID。
为了解决这个问题,我们在原始集群(集群 A)发送消息到集群 B 时,在消息的 Metadata 里加入了集群 A 里的 Entry Position(Message ID)和 originalClusterPosition 的属性来携带消息写入的位置。

这样,当我们在集群 B 进行消费时,可以快捷地从 originalClusterPosition 属性中获取到集群 A 的 Message ID,将其与集群 A 同步到集群 B 的 individuallyDeletedMessages 进行比较。如果消息已经被确认过就直接跳过此条消息,不再发送给消费者。通过这样的方法实现对已确认消息的过滤。
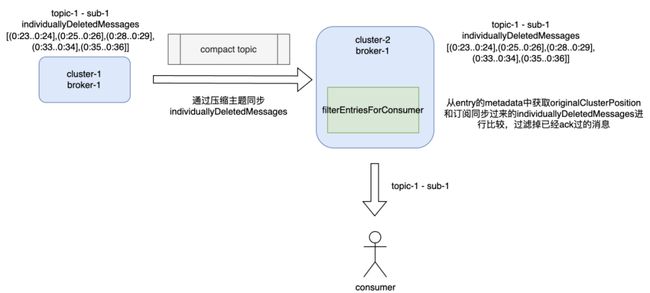
具体实现逻辑如上图。在迁移集群迁移之前,需要先将集群 1 中 individuallyDeletedMessages 的订阅同步到集群 2。在将消息推送给消费者之前,消息会先经过 Filter Entries For Consumer 过滤掉集群 1 中已经消费过的消息,将未消费的消息推送给集群 2 中的消费者。
上述实现逻辑只是一种思路的转换。因为在 Pulsar 中,进度同步实现在集群 1 上,集群 2 中的消息不断同步到集群 1,通过不断构建 Snapshot 记录集群 1 和集群 2 位置对应关系,这样在集群 1 确认消息时,可以同步确认集群 2 对应位置。我们的优化方法是把集群 1 中消息的位置信息放在消息里,通过同步 individuallyDeletedMessages 和 markDeletePosition 将进度同步到集群 2,在集群 2 实际消费时过滤。通过这种方式将重复消费控制在用户可接受范围内。
租户跨集群迁移的实现
早期腾讯云内部的集群是共享集群,不同业务场景的用户使用同一套物理集群。有大规模消息队列运维经验的同学知道,不同用户混用同一集群会使用户之间互相影响。用户对服务的要求不同,需要为对服务质量要求比较高的用户搭建独占集群,物理资源隔离来减少对其他用户的影响。这时需要有平滑的迁移方案实现集群的顺利迁移。
租户迁移整体架构

上图为腾讯云内部实现租户跨集群迁移的架构图,其中最核心的模块 Lookup Service 是腾讯云内部代理客户端 Lookup 请求的服务模块,保存每个租户到物理集群的映射关系。我们根据租户将用户客户端 Lookup 请求转发到对应的物理集群,进而获取用户客户端收发消息时所需要连接的 Broker 节点。需要注意的是,Lookup Service 不仅仅代理 Lookup 请求,还代理 getPartitionState、getPartitionMydata 和 getSchema 等请求,但不代理包含数据流的请求。数据流请求通过 CLB 或 VIP 直接连到集群来收发消息,并不经过 Lookup Service。
其实 Lookup Service 不是为了跨集群迁移而诞生,它的主要目的是在多种网络接入访问场景下,为云上集群提供集中处理不同网络服务路由的能力。在公有云上不只存在通过简单的 Broker IP 就能连接的内网用户,还需要通过公网 CLB、VPC 或 VIP 服务进行转发,Lookup Service 主要应用于这方面。我们跨集群迁移时利用了 Lookup Service 能力来保证集群切换简单顺利地实现,同时借助于跨地域复制的同步功能把数据从原有集群迁移到目标集群上。迁移完成后,通过 Lookup Service 的切入能力最终实现租户跨集群迁移。
租户跨集群迁移的主要流程
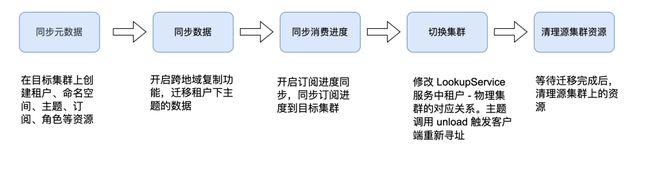
接下来介绍跨集群迁移的具体流程。
-
同步元数据。在目标集群上按照原集群的租户、命名空间、主题和订阅角色等资源,完成元数据同步。
-
开启跨地域复制功能,迁移租户下的主题数据。
-
在集群切换前开启订阅进度同步功能,把每个订阅的 individuallyDeletedMessages 和 Mark Delete Messages 同步到目标集群上。
-
修改 Lookup Service 中租户与物理集群的对应关系,主动调用 Unload 触发客户端重新寻址。Lookup Service 根据新租户到物理集群的对应关系返回新物理集群的地址。
-
在迁移完成后,清理原集群上的资源。
总结
实现租户跨集群迁移的方式有很多,本文只分享一种在公有云上实现改造成本较低、复杂程度较小并且可靠性较高的方案。这种方案不需要对现有 Pulsar 客户端和服务端协议做任何改动就可以实现平滑迁移。