presto 理论概念和安装部署总结
presto 理论概念和安装部署总结
presto 理论概念
presto 定义与概念
MPP(大规模并行处理)引擎MPP就是将任务并行地分散到多个服务器与节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果,Presto就是MPP引擎,Presto对于task中的splits可以做到并行处理。
presto 由facebook开源,用于在apache hadoop 之上的数据仓库上运行交互式查询。presto 是开源的用于大数据高性能的分布式的sql查询引擎,通过presto 可以让使数据的存储与分析分离开来,presto 作用于底层存储之上,presto 支持多种数据源 hive ,MySQL等并在之上进行数据处理。
OLAP 和OLTP:
OLAP: 联机分析处理:数据仓库的主要应用,支持复杂的分析操作,侧重决策支持,提供直观易懂得查询结果。侧重于数据分析,强调sql执行时长和效率,强调磁盘I/O和分区。
OLTP: 联机事务处理:传统关系型数据库的主要应用,主要是基本的、日常的事务处理。侧重于事务支持,强调事务的并发操作。
presto 是一个基于内存的OLAP类型的分布式sql查询引擎。初衷是为了解决hive 基于 mapreduce 磁盘调度运行模型计算效率慢的问题。适合于PB级别的海量级数据分析,交互式sql特点,支持跨数据源查询。不适合与多个大表的join连接操作,内存空间有限无法存放大量数据。
presto特性
- sql on everything 支持多种数据源(mysql,oracle)
- 数据存储与计算分离 (只负责数据的分析与计算,不涉及数据的存储,数据的存储有数据源保证)
- 海量数据计算能力(支持大数据的分析与处理)
- 低时间延迟 (基于内存操作,效率高,经过facebook计算是hive效率的10倍,spark sql的三倍)
- 完全基于内存
- 支持sql (完全支持ANSL SQL,提供SQL shell)
- 可扩展 (支持集群化部署,分布式计算,可以动态扩容work节点,可以自定义connector)
- 混合计算(可以混合多个catelog 进行join查询和计算)
- 流水线(基于pipeline设计的,在进行大量设计处理过程中,终端不需要等待所有的数据计算完毕之后才能看到结果,计算一部分就可以看部分结果)
- 动态编译(对于少数Operator会被动态编译为Byte Code ,而后由JIT编译为native代码,降低代码展开开销。)
- 本地化计算(优先选择与数据源靠近的工作节点计算)
- 高效内存拷贝(使用slice进行内存操作,slince 可以实现内存的高效拷贝)
presto 不足
- 容错性:不支持单个query内部执行容错(query 中包含多个 Task,如果某个Task 失败了,会导致整个Query 失败,而不会进行把 task 在移动到其他工作节点处理重试)
- 不是数据库,不进行数据存储,不支持在线事务
- 内存限制 :presto 是基于内存计算,当内存空间不足时,不会将一部分结果保存到磁盘上,直接就查询失败,不适合大表的join操作。
- 并行限制:多个task 并行在worker节点进行计算,当其中一台worker计算缓慢,会让整个query流程效率变慢
- 并发限制:presto 基于全内存进行计算,加上数据也在内存中保存,能同时并发处理量受内存限制。
presto基本架构和组件
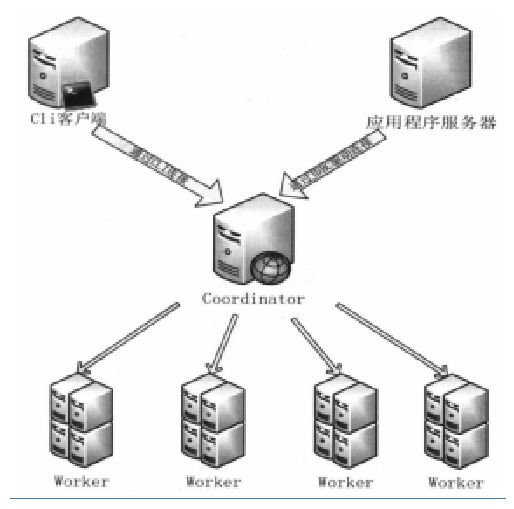
在物理架构方面 presto 采用了主从架构(master-slave)的方式,主节点coordinator负责接收来自客户的请求,让后分发到worker工作的从节点进行数据处理,然后在接收worker节点处理结果在由主节点cooedinator返回结果。
presto cli : 客户端负责发起请求
coordinator:
presto 集群的主节点,负责管理集群与客户端链接,并接收客户端查询请求。进行sql语法解析,生产和优化查询任务,并且调度和跟踪任务的执行。集群管理节点。
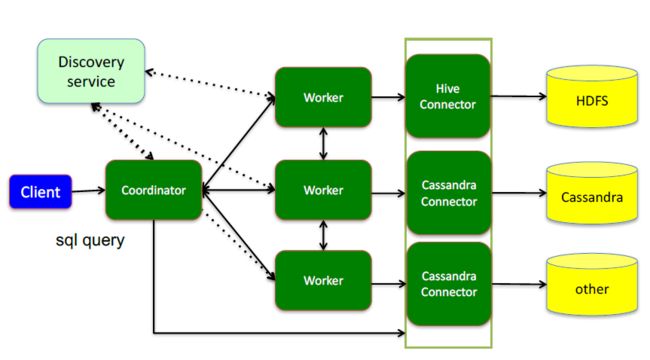
同时承担了服务注册中心的角色,内置了discovery server 可以实现服务的注册与发现,跟踪work节点的状态。独立部署,使用restful 接口与client 和 worker 进行通信。
worker:执行被分解后的任务,进行数据的处理,一个集群中部署多个worker,使用restful 接口与coordinator 以及其他 worker通信。 worker 节点是真正进行数据的处理的节点,它接收来自 coordinator 分发的的task进行数据的获取和计算。
三者交互关系:
服务进程交互关系:
状态管理:
worker 定时向coordinator 发送心跳,表明自己的存活,主要影响discoverserver,服务的注册与发现,通过心跳机制来保证存活,指定时间间隔进行通信。
任务管理:
coordinator 接收 client 请求
coordinator 从存活的 worker 中选取合适(靠近数据源的节点)的 worker 派发任务
数据处理:
worker 通过 connector 连接器拉取数据
worker 与其它 workers 进行中间数据的交互处理
coordinator 从 worker 拉取数据处理结果
coordinator 将结果返回给client
presto 与 hive 的区别:
相同点:都是数据仓库工具,进行数据的在线处理
不同点:presto 基于内存计算,效率更高,支持多数据源
hive 的操作会被翻译成mapreduce 程序,执行效率慢,只支持在hdfs数据源之上操作。
presto 工作模型
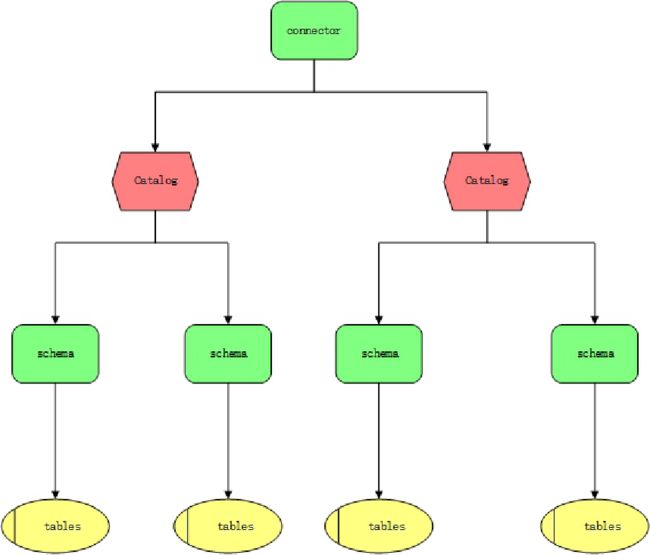
connector:(适配器的设计模式:适应不同类型的数据源)
相当于数据库访问的驱动
presto 通过不同的connector 可以访问多种不同的数据源
connector 通过 presto 提供的spi 接口实现数据源的接入
catalog:
相对于数据库的一个实例机器
schemas:
相当于数据库的名称
Table:
相当与数据库表名
presto 查询模型
statement (语句):指用户输入的sql语句,根据statement语句,presto 会创建一个query查询以及一个查询计划,然后进行调度分析,交给worker节点处理,这一系列的操作是在coordinator节点实现的。
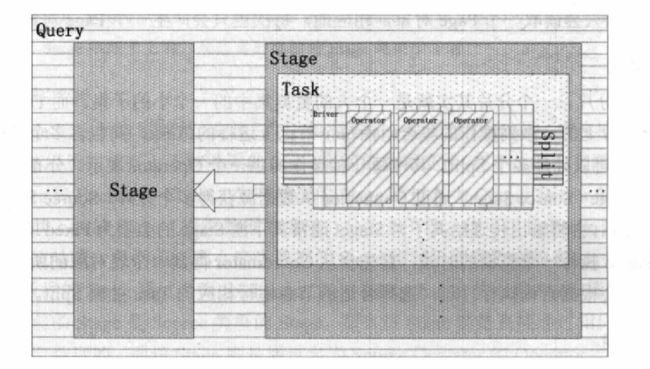
query(查询):根据statement生成的查询执行计划,即查询句,代表着可以在集群中运行的查询操作,以下所有结构通过各种内部关系构成一个查询。
stage(阶段) : 查询的执行阶段,一个query 会被拆分成具有层级关系的多个 stage,一个 stage代表查询执行计划的一部分stage 不会在集群中实际执行,它只是coordinator用于对查询执行计划进行管理和建模的逻辑概念。
Stage之间是树状结构。
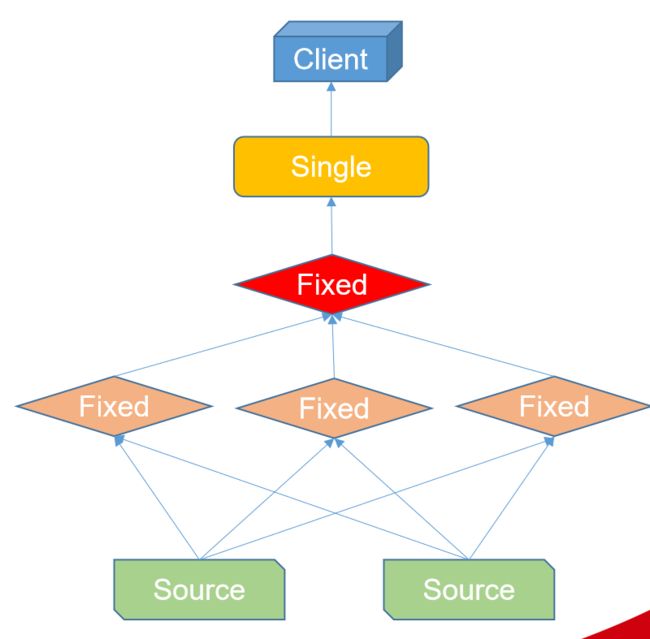
Coordinator_only
执行ddl(建表,修改表结构,创建视图),dml(insert update delete)相关的表操作。
Single
聚合子Stage结果,并将最终数据返回给客户端程序。
Fixed
用于接收子Stage数据,并在集群中对这些数据进行聚合和分组操作。
Source
接收数据源数据,进行数据过滤,谓词下推。exchange(交换):
用于连接不同的stage,用来完成有上下游关系的stage之间的数据交换
exchangeclient: 获取上游stage 产生的数据,提供给当前的stage 消费
outputbuffer: 缓存当前stage生成的数据,供下游消费
task(任务):
每个stage 由多个 task 组成,task 实际运行在 worker节点上,称之为一个任务
每个task 有对应的输入输出
多个task 并行执行一个 stage ,处理一个或多个 split(数据集的基本单元)
driver(驱动)
每个Task 包含多个Driver,每个Driver 是对一个 Split(数据集) 的Operator (算子)操作集合;
一个Driver 处理一个 Split,拥有一个输入和输出。
是Presto 最底层的并行处理单元。operator(算子):
代表对一个split 的一种操作,例如过滤,关联,聚集等;以page 为最小处理 单位进行数据的读取和输出
split(分片)
一个大数据集中的一个小的子集;
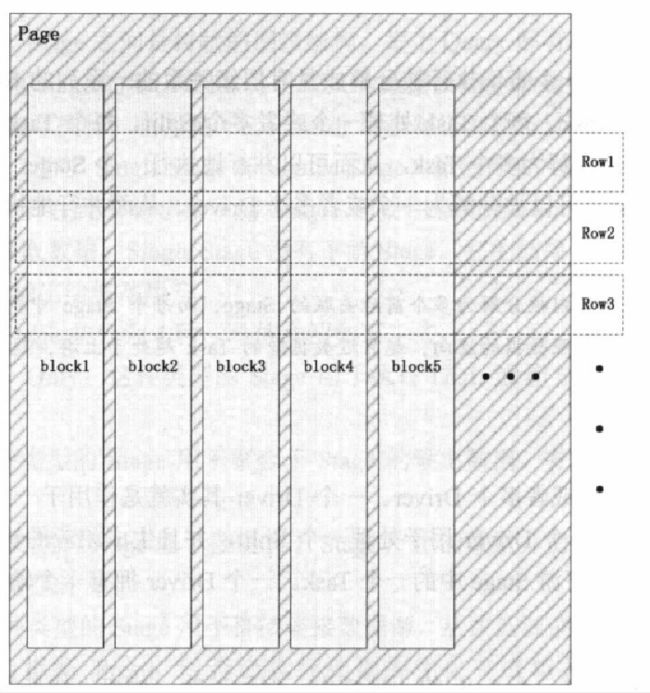
通过 Coordinator 获取表所对应的 split信息,然后指定查询计划,选择合适的worker处理对应的 Split;split 是worker处理的基本数据集。page(页)
是数据处理的最小单元;
一个Page 对象包含多个 Block 对象,一个Block 对象是一个字段的多行数据;
一个 Page 最大为 1M,最多 16*1024行;
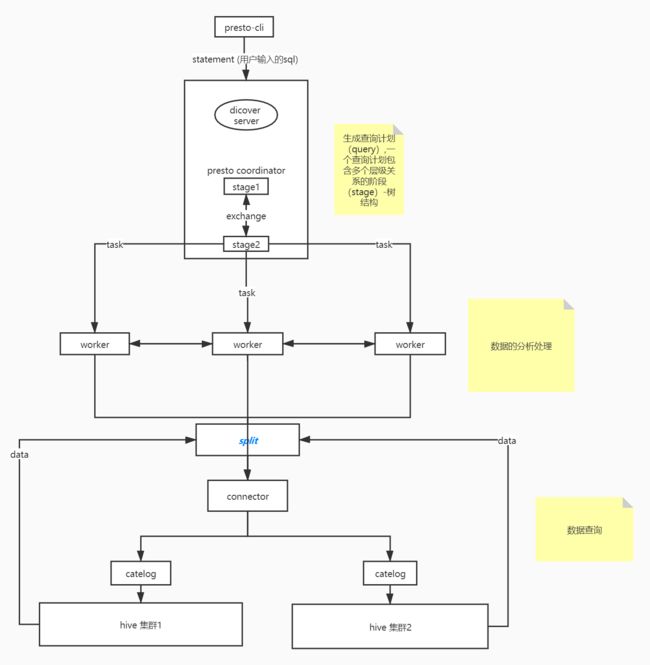
presto sql 执行流程
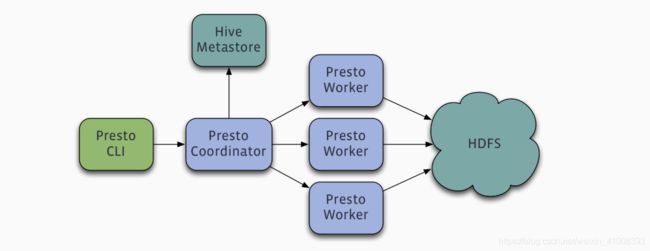
- presto cli 通过接口向presto coordinator 发送一个query请求
- presto coordinator接收到query请求,负责获取其中的sql语句,并进行sql语句的语法解析,生成一个query查询,然后对查询进行分析生成一系列的stage阶段,最后生成具体的task任务,然后通过自身的discover服务,选择合适的worker节点去执行task;
- presto worker 节点接收到task任务后,然后通过connector 连接器插件读取数据,拿到一个基本数据集splint,然后装换成page数据结构,进行处理
- presto worker 执行完成任务,将结果返回到presto coordinator 调度处理的主节点
- presto coortinator 进行数据的汇总,响应返回给presto cli端。
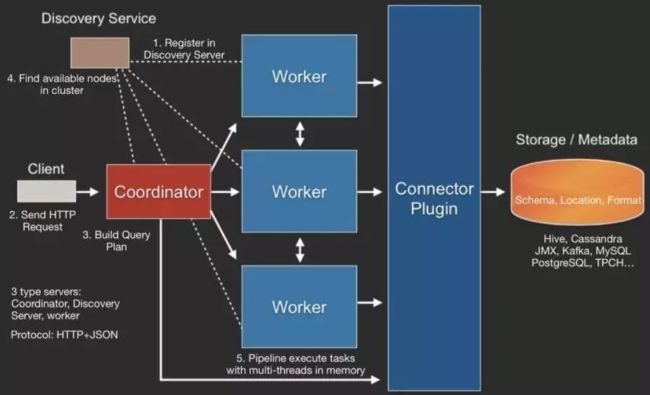
具体的执行流程:
1.当我们执行一条sql查询, coordinator 会先通过 SQL Praser 对SQL 语法进行解析,解析成为抽象的语法书AST,在解析的过程中如果sql 的语法有问题,会直接暴露出来,返回给客户端错误信息。
- sql 语法解析完成为AST后,会通过 Logical Planner 逻辑查询计划的组件进行AST抽象语法树的分析,这一步会通过 connector的方式获取数据源中的元数据信息(表名,类型…)进行一个sql 语法的检查,检查是否包含不存在字段,字段类型不匹配,表是否存在。如果检查出错直接返回给客户端错误。
- 通过 Logincal Planner 的分析,会生成一个Logical query plan 逻辑查询计划,对于Logincal query Planner 逻辑查询计划会经过DistriButed planner 进行分布式计划即系,生成一系列的Distributed Query plan,也就是基本的task
- 在每一个task里面,他会把对应的位置信息全部给提取出来,交给执行的plan,由plan把对应的task发给对应的worker去执行,这就是整个的一个过程然后task 会被分配到具体工作的worker节点执行。
presto 不足分析
单点故障: 在主从架构中coordinator采用单节点部署,会造成单点故障的问题,因为coordinator 节点负责整个集群的调度和与外部交互,同时也承担了服务注册中心的角色,当coordinator节点崩溃,会导致整个集群不可用。
容错性: query 查询会被生成多个 task ,task 会被分配到多个worker执行,如果一个worker节点出错,会导致整个query执行出错,而不会切换到其他节点重新执行task。
presto 内存管理
presto 是一个全内存的计算框架,对于内存的管理和利用要求高,它内置了一个细粒度资源管理系统。这使得一个集群可以同时执行数百个查询,并最大程度上利用 CPU 内存 IO 资源。
presto 把自己管理的内存分为两大类:user memory 和 system memory :
user memory 是跟用户数据相关的,比如读取用户oss数据会占据相应的内存,这种内存的占用量跟用户底层数据量大小是强相关的;system memory则是为了执行查询所需要执行的operator本身分配的一些内存,跟用户的数据本身不强相关的内存。
Presto中还有内存池的概念,分为两种: general和reserved。
在一般情况下,一个查询执行所需要的内存都是从general pool中分配的,reserved pool在一般情况下是空闲不用的。
当集群中某个worker的general pool消耗殆尽之后,coordinator会选择集群中内存占用最多的查询,把这个查询分配到reserved pool,这样这个大查询自己可以继续执行,而腾出来的内存也使得其它的查询可以继续执行,从而使得整个系统可以向前进。
自我保护的机制
当general pool内存用完的时候,一些operator会被置为blocked状态,让operator暂停一下,从而避免整个系统垮掉。
reserved pool在普通情况下是浪费内存的 ,coordinator每秒钟做一次判断,指定某个query在所有的机器上都能使用reserved 内存
presto 安装部署(单机和分布式)
基本环境前提
1.三台主机,相互之间可以ping通,能够ssh无密码登录
2.jdk1.8
3.hadoop 分布式部署
4.mysql 安装部署
5.hive 安装
准备文件
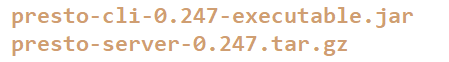
prosto-cli 是 presto的客户端工具
presto-server 是presto 服务端,也就是具体节点
presto 单机安装(presto 节点即是 coordinator 主节点也是 worker节点)
1.解压presto-server,并修改权限
sudo tar -zxvf presto-server-0.247.tar.gz -C /opt/module/prosto-server # 解压
sudo chown hadoop:hadoop presto-server # 修改权限用户组
2.创建data目录存放presto 元数据信息和日志信息
mkdir /opt/module/prosto-server/data # 创建存放与数据信息目录

3.创建配置文件存放配置信息(在presto 的安装目录下进行创建)
mkdir etc # 创建配置目录
cd etc
# 创建配置文件
touch config.properties # 存放prosto 基本的配置属性
touch jvm.config # 配置 presto 运行的虚拟机参数
touch log.properties # 配置 presto 日志级别
touch node.properties # 配置 presto 节点信息

**config.properties **
coordinator=true # 允许此Presto实例充当协调器(接受来自客户端的查询并管理查询执行)
node-scheduler.include-coordinator=true # 允许在协调器上安排工作。对于较大的集群,协调器上的处理工作可能会影响查询性能,因为计算机的资源不可用于调度,管理和监视查询执行的关键任务。-- 承担 worker角色
http-server.http.port=8081
query.max-memory=5GB # 查询使用最大的分布式内存量
query.max-memory-per-node=1GB # 查询可在任何一台计算机上使用的最大用户内存量。
query.max-total-memory-per-node=2GB # 查询可在任何一台计算机上使用的最大用户和系统内存量,其中系统内存是读取器,写入程序和网络缓冲区等执行期间使用的内存。
discovery-server.enabled=true # 承担服务注册中心的概念
discovery.uri=http://192.168.11.131:8081 # 注册中心地址
jvm.config
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
log.properties
com.facebook.presto = INFO # 输出日志级别
node.properties
node.environment=production # presto 集群名称
node.id=presto1 # presto 集群节点名称
node.data-dir=/opt/module/presto-server/data # 存放数据的目录
4.创建catalog 配置presto 连接数据源的信息
mkdir catalog # 在 presto 安装目录的etc 目录下创建 catalog 是服务端获取链接和客户端将要链接哪个数据库必须的
touch hive.properties # 创建hive 连接配置
touch mysql.properties # 创建 mysql 连接配置信息 -- 使用 mysql作为数据源时需要注意 mysql 的用户权限,可以保证在其他主机上访问到数据库
hive.properties
connector.name=hive-hadoop2 # 连接器类型名称
hive.metastore.uri=thrift://192.168.11.131:9083 # hive 元数据获取地址
hive.config.resources=/opt/module/hadoop/conf/core-site.xml,/opt/module/hadoop/conf/hdfs-site.xml # hive 配置资源路径
mysql.properties
connector.name=mysql # 连接器类型名称
connection-url=jdbc:mysql://192.168.11.131:3306 # mysql 地址
connection-user=presto # mysql 用户名
connection-password=presto # mysql 密码 注意:用户权限要支持在外部登录查看数据
5.启动基础服务
1.启动hadoop start-dfs.sh start-yarn.sh
2.后台启动hive服务 hive --service hiveserver -p 9083
3.启动mysql service mysql start
6.启动单节点的presto,并进行测试
./presto/bin/laucher run # 控制台启动
./presto/bin/lauucher start # 后台启动
mv presto-cli-0.208-executable.jar presto-cli # 重命名
chmod 777 presto-cli # 赋予权限
./presto-cli --server localhost:8081 --catalog hive --schema db_name; # 启动客户端 --schema 可以省略 -- server 代表的是 coordinatl 的端口号 -- catalog 代表端口
presto 分布式安装
1.在单节点的情况下通过 scp 分发到其他主机,并修改权限
scp -r folder 用户名@远程主机ip:远程主机文件夹 #主机之间文件互传 前提做好ssh相关服务
2.修改config.properties和node.properties
config.properties
coordinator=false # 允许此Presto实例充当协调器(接受来自客户端的查询并管理查询执行) 改变
node-scheduler.include-coordinator=true # 允许在协调器上安排工作。对于较大的集群,协调器上的处理工作可能会影响查询性能,因为计算机的资源不可用于调度,管理和监视查询执行的关键任务。-- 承担 worker角色
http-server.http.port=8081
query.max-memory=5GB # 查询使用最大的分布式内存量
query.max-memory-per-node=1GB # 查询可在任何一台计算机上使用的最大用户内存量。
query.max-total-memory-per-node=2GB # 查询可在任何一台计算机上使用的最大用户和系统内存量,其中系统内存是读取器,写入程序和网络缓冲区等执行期间使用的内存。
discovery-server.enabled=false # 承担服务注册中心的概念 改变
discovery.uri=http://192.168.11.131:8081 # 注册中心地址
node.config
node.environment=production # presto 集群名称 保证相同
node.id=presto2 # presto 集群节点名称 保证唯一
node.data-dir=/opt/module/presto-server/data # 存放数据的目录
3.启动presto集群,并进行测试
./presto/laucher start # 启动单个节点,注意先启动coordinator 节点,在启动其他的worker节点 (可以编写脚本启动,需要先配置presto的环境变量)