2021-12-24 迈向程序猿的第五十四步
目录
一、Presto的概述
1.1 Presto的简介
1.2 Presto支持的数据源
1.3 Presto和Hive的比较
1.4 Presto与Impala的比较
二、Presto的体系架构
2.1 简介与图解
2.2 Presto中SQL运行过程
2.3 MapReduce vs Presto
三、Presto的安装
3.1 Presto Server的安装
3.2 Presto server的运行
3.3 Presto Client安装
3.3.1 第一种客户端:presto-cli-0.266-executable.jar
3.3.2 第二种客户端:yanagishima-20.0.zip
一、Presto的概述
1.1 Presto的简介
官网:Presto | Distributed SQL Query Engine for Big Data
Presto是facebook的一个开源,并完全基于内存的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。presto的架构由关系型数据库的架构演化而来。presto之所以能在各个内存计算型数据库中脱颖而出,在于以下几点:
1.具有良好的清晰的体系架构,是一个能够独立运行的系统,不依赖于任何其他外部系统。
2.例如调度,presto自身提供了对集群的监控,可以根据监控信息完成调度。
3.简单的数据结构,列式存储,逻辑行。
4.大部分数据都可以轻易的转化成presto所需要的这种数据结构。
5.丰富的插件接口,完美对接外部存储系统,或者添加自定义的函数。
1.2 Presto支持的数据源
参考官网:https://prestodb.io/docs/current/connector.html#
1)hive源,支持的文件类型如下:
- ORC
- Parquet
- Avro
- RCFile
- SequenceFile
- JSON
- Text2)开源数据存储系统
MySQL & PostgreSQL,Cassandra,Kafka,Redis3)其他数据源
MongoDB,ElasticSearch,HBase1.3 Presto和Hive的比较
hive是一个数据仓库管理工具,是一个交互式比较弱一点的查询引擎,而且只能访问hdfs的数据,底层编译成mr、spark或者tez程序
presto是一个交互式查询引擎,可以在很短的时间内返回查询结果,秒级,分钟级,能访问很多数据源,也不能用于在线事务处理(OLTP)
注意:presto是取代不了hive的,因为presto全部的数据都是在内存中,限制了在内存中的数据集大小,比如多个大表的join,这些大表是不能完全放进内存的1.4 Presto与Impala的比较
首先你要知道Presto,Impala都属于开源OLAP引擎.
Presto是一个分布式SQL查询引擎,FaceBook于2013年11月份对其进行了开源, 它被设计为用来专门进行高速、实时的数据分析。它支持标准的ANSI SQL,包括复杂查询、聚合(aggregation)、连接(join)和窗口函数(window functions)。Presto 本身并不存储数据,但是可以接入多种数据源,并且支持跨数据源的级联查询。Presto是一个OLAP的工具,擅长对海量数据进行复杂的分析;但是对于OLTP场景,并不是Presto所擅长,所以不要把Presto当做数据库来使用。
Impala是实时交互SQL大数据查询工具,是Google Dremel的开源实现(Apache Drill类似),Cloudera推出的Impala系统,它拥有和Hadoop一样的可扩展性、它提供了类SQL(类Hsql)语法,在多用户场景下也能拥有较高的响应速度和吞吐量。Impala还能够共享Hive Metastore,甚至可以直接使用Hive的JDBC jar和beeline等直接进行查询,并且支持丰富的数据存储格式(Parquet、Avro等)。此外,Impala 通过使用分布式查询引擎(由 Query Planner、Query Coordinator 和 Query Exec Engine 三部分组成),可以直接从 HDFS 或 HBase 中用 SELECT、JOIN 和统计函数查询数据,从而大大降低了延迟。1. Presto支持标准的ANSI SQL规范,复杂查询、聚合(aggregation)、连接(join)和窗口函数
Impala的sql和Hive基本一致
2. Presto可连接的数据源更加丰富
Impala可连接的数据源不多,hive,hdfs,hbase
3. Presto的支持的文件存储格式比较多
Impala的较少
4. 速度上的比较
Impala快,但是使用的内存更多,比hive快10多倍
presto相对较慢,但是使用的内存比Impala少。 比hive快 5~10倍 所以从整体性能对比看,两者差不多,但是Presto更优.
大数据开源引擎presto和impala,哪个好? - 知乎
二、Presto的体系架构
2.1 简介与图解
Presto查询引擎是一个master/slaves的主从架构,由一个Coordinator节点和一个Discovery Server节点,多个Worker节点组成,Discovery Server通常内嵌于Coordinator节点中。Coordinator负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行。Worker节点负责实际执行查询任务。Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。如果配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息,Worker节点与HDFS交互读取数据。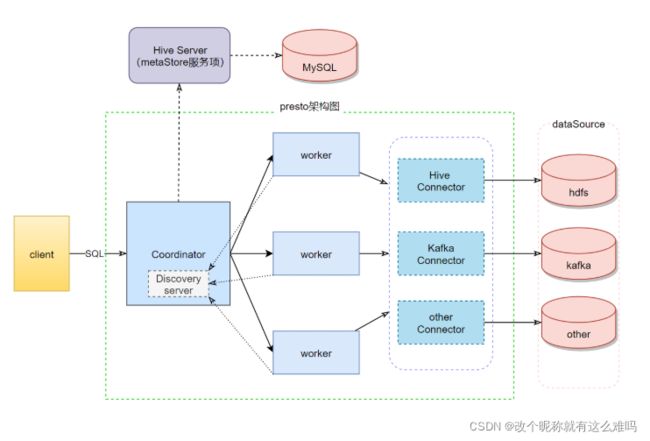
Coordinator服务
是一个中心的查询角色,它主要的一个作用是接受查询请求,将他们转换成各种各样的任务,将任务拆解后分发到多个worker去执行各种任务的节点
1、解析SQL语句
2、⽣成执⾏计划
3、分发执⾏任务给Worker节点执⾏
Worker服务
是一个真正的计算的节点,执行任务的节点,它接收到task后,就会到对应的数据源里面,去把数据提取出来,提取方式是通过各种各样的connector:
1、负责实际执⾏查询任务Discovery service服务
是将coordinator和woker结合到一起的服务:
1、Worker节点启动后向Discovery Server服务注册
2、Coordinator从Discovery Server获得Worker节点coordinator和woker之间的关系是怎么维护的呢?是通过Discovery Server,所有的worker都把自己注册到Discovery Server上,Discovery Server是一个发现服务的service,Discovery Server发现服务之后,coordinator便知道在我的集群中有多少个worker能够给我工作,然后我分配工作到worker时便有了根据
最后,presto是通过connector plugin获取数据和元信息的,它不是⼀个数据存储引擎,不需要有数据,presto为其他数据存储系统提供了SQL能⼒,客户端协议是HTTP+JSON
参考美团技术文章:Presto实现原理和美团的使用实践 - 美团技术团队
2.2 Presto中SQL运行过程
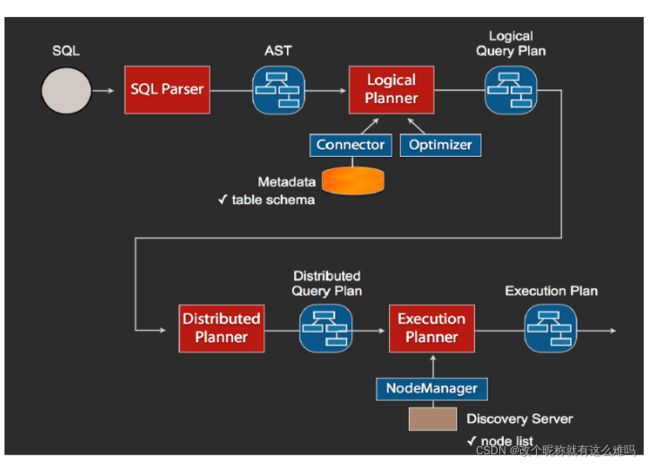
1、当我们执行一条sql查询,coordinator接收到这条sql语句以后,它会有一个sql的语法解析器去把sql语法解析变成一个抽象的语法树AST,这抽象的语法书它里面只是进行一些语法解析,如果你的sql语句里面,比如说关键字你用的是int而不是Integer,就会在语法解析这里给暴露出来
2、如果语法是符合sql语法规范,之后会经过一个逻辑查询计划器的组件,他的主要作用是,比如说你sql里面出现的表,他会通过connector的方式去meta里面把表的schema,列名,列的类型等,全部给找出来,将这些信息,跟语法树给对应起来,之后会生成一个物理的语法树节点,这个语法树节点里面,不仅拥有了它的查询关系,还拥有类型的关系,如果在这一步,数据库表里某一列的类型,跟你sql的类型不一致,就会在这里报错
3、如果通过,就会得到一个逻辑的查询计划,然后这个逻辑查询计划,会被送到一个分布式的逻辑查询计划器里面,进行一个分布式的解析,分布式解析里面,他就会去把对应的每一个查询计划转化为task
4、在每一个task里面,他会把对应的位置信息全部给提取出来,交给执行的plan,由plan把对应的task发给对应的worker去执行,这就是整个的一个过程
这是一个通用的sql解析流程,像hive也是遵循类似这样的流程,不一样的地方是distribution planner和executor pan,这里是各个引擎不一样的地方,前面基本上都一致的2.3 MapReduce vs Presto
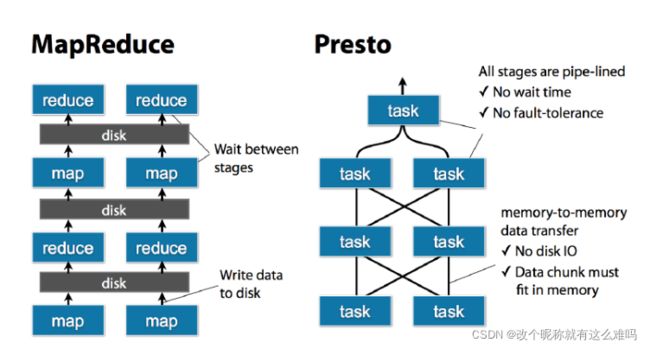
Presto的task是放在每个worker上该执行的,每个task执行完之后,数据是存放在内存里了,而不像mr要写磁盘,然后当多个task之间要进行数据交换,比如shuffle的时候,直接从内存里处理
小贴士:
presto适合PB级的海量数据查询分析,并不是说把pb的数据放进内存。比如对一张PB级别的表进行count,avg这种类型的查询,虽然数据很多,但是最终的查询结果很小,这种就不会把数据都放到内存里面,只是在运算的过程中,拿出一些数据放内存,然后计算,保存结果,清理内存,在拿,这种的内存占用量是很小的。
但是join这种,在运算的中间过程会产生大量的数据,或者说那种查询的数据不大,但是生成的数据量很大,这种也是不合适用presto的,但不是说不能做,只是会占用大量内存,消耗很长的时间,这种hive合适点
presto算是hive的一个补充,需要尽快得出结果的用presto,否则用hive三、Presto的安装
3.1 Presto Server的安装
参考官网:Deploying Presto — Presto 0.266.1 Documentation
步骤1)上传presto-server-0.266.tar.gz、解压,更名、配置环境变量
[root@xxx01 ~]# tar -zxvf presto-server-0.266.tar.gz -C /usr/local/
[root@xxx01 ~]# cd /usr/local
[root@xxx01 local]# mv presto-server-0.266/ presto
[root@xxx01 local]# vim /etc/profile
[root@xxx01 local]# source /etc/profile步骤2)维护目录结构
data/
etc/
├── catalog
│ └── hive.properties # Configures the TPCH connector to generate data
├── config.properties # Presto instance configuration properties
├── jvm.config # JVM configuration for the process
├── log.properties # Logging configuration
└── node.properties # Node-specific configuration properties
[root@xxx01 presto]# mkdir $PRESTO_HOME/data
[root@xxx01 presto]# mkdir $PRESTO_HOME/etc
[root@xxx01 presto]# touch $PRESTO_HOME/etc/{config.properties,jvm.config,log.properties,node.properties}
[root@xxx01 presto]# mkdir $PRESTO_HOME/etc/catalog && touch $PRESTO_HOME/etc/catalog/hive.properties步骤3)配置note.properties
[root@xxx01 presto]# vim $PRESTO_HOME/etc/node.properties
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-fffffffffff1
node.data-dir=/usr/local/presto/data注意:别忘记修改其他节点的id的值
步骤4)配置jvm.config
[root@xxx01 presto]# vim $PRESTO_HOME/etc/jvm.config
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError步骤5)配置config.properties
[root@xxx01 presto]# vim $PRESTO_HOME/etc/config.properties
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8090
query.max-memory=50GB
discovery-server.enabled=true
discovery.uri=http://xxx01:8090
coordinator: 表示是否开启coordinator服务项
node-scheduler.include-coordinator: 是否在coodinator节点上开启一个worker
http-server.http.port: coordinator的通信端口
discovery-server.enabled: 是否内置一个discovery server
discovery.uri: discovery server的通信地址,必须和coordinator公用一个端口号步骤6:配置log.properties(可选)
[root@xxx01 presto]# vim $PRESTO_HOME/etc/log.properties
com.facebook.presto=INFO步骤7)配置catalog里的hive.properties
[root@xxx01 presto]# vim $PRESTO_HOME/etc/catalog/hive.properties
connector.name=hive-hadoop2
hive.metastore.uri=thrift://xxx01:9083最后,scp指令同步到其他两台机器上 注意修改 node.properties . config.properties
xxx02的node.properties
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-fffffffffff2
node.data-dir=/usr/local/presto/dataxxx03的node.properties
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-fffffffffff3
node.data-dir=/usr/local/presto/dataxxx02和xxx03的config.properties的内容如下:
coordinator=false
http-server.http.port=8090
query.max-memory=50GB
discovery.uri=http://xxx01:80903.2 Presto server的运行
1)首先、要启动 hdfs和Hive的metastore服务项
start-dfs.sh
nohup hive --service metastore 2>&1 >/dev/null &2)然后、启动presto服务
前台运行
bin/launcher run后台启动
[root@xxx01 ~]# bin/launcher start
[root@xxx02 ~]# bin/launcher start
[root@xxx03 ~]# bin/launcher start3)小贴士:启动后,您可以在var/log以下位置找到日志文件:
launcher.log: 这个日志是由启动器创建的,并连接到服务器的 stdout 和 stderr 流。它将包含一些在初始化服务器日志记录时发生的日志消息以及 JVM 产生的任何错误或诊断信息。
server.log:这是 Presto 使用的主要日志文件。如果服务器在初始化期间出现故障,它通常会包含相关信息。它会自动旋转和压缩。
http-request.log:这是包含服务器收到的每个 HTTP 请求的 HTTP 请求日志。它会自动旋转和压缩。3.3 Presto Client安装
3.3.1 第一种客户端:presto-cli-0.266-executable.jar
1)说明
是一个可执行文件,只需要上传到presto的bin目录下,更名即可2)上传、更名、修改权限
mv presto-cli-0.266-executable.jar presto-cli
chmod a+x presto-cli3) 运行客户端
presto-cli --server xxx01:8090 --catalog hive --schema sz21033.3.2 第二种客户端:yanagishima-20.0.zip
0) 说明
yanagishima是一个presto的webui客户端。 在github上可以下载源码,进行编译
20.0版本是最后一个支持jdk1.8的版本。
yanagishima-20.0.zip:是已经编译好的1)上传、解压、更名
unzip yanagishima-20.0.zip -d /usr/local
mv yanagishima-20.0 yanagishima2)修改配置文件
[root@xxx01 ~]# vim /usr/local/yanagishima/conf/yanagishima.properties
找到以下属性进行修改:
jetty.port: webui的端口号 ,比如设置成8899
presto.datasources: 数据源的名称,自定义即可,注意,下面的都要替换成这个名字
presto.coordinator.server.nickname=
catalog.nickname=hive
schema.nickname=default
sql.query.engines=presto3)启动服务项
./bin/yanagishima-start.sh4)访问webui
http://xxx01:8899(>-<,presto的搭建挺简单,主要是看客户端的选择啊,这里第一个是官网自带的纯命令行模式,第二个客户端则是由个人开发的可视化操作界面,挺不错的.)