CockroachDB架构-存储层
本文知识点来源于官网地址https://www.cockroachlabs.com/docs/v22.1/architecture/storage-layer.html
概览
每个CRDB节点至少包含一个store,该store在节点启动时指定,这是CRDB进程在磁盘上读写数据的位置。
数据使用存储引擎以键-值对的形式存储在磁盘上,存储引擎主要作为黑盒API处理。
CRDB使用Pebble存储引擎。Pebble的灵感来自RocksDB,但不同之处在于:
- 是用Go编写的,实现了RocksDB大型特性集的一个子集。
- 包含有利于CRDB的优化。
在内部,每个store包含存储引擎的两个实例:
- 1个用于存储临时分布式SQL数据
- 1个用于表示节点上的所有其他数据
此外,一个节点中的所有存储之间还共享一个块缓存(block cache)。这些stores有一个范围副本集合。一个范围的多个副本永远不会被放置在同一个store甚至同一个节点上。
组件
Pebble
CRDB使用Pebble(一种受RocksDB启发的嵌入式键值存储)向磁盘读写数据。
Pebble可以很好地与CRDB集成,原因有很多:
- 它是一个键值存储,使得映射到键值层变得简单
- 它提供原子的写批处理和快照,这为我们提供了事务的子集
- 它是由CRDB实验室的工程师开发的
- 它包含了RocksDB中没有的优化,这些优化的灵感来自于CRDB使用存储引擎的方式。
LSM树
Pebble使用一个Log-structured Merge-tree(以下简称LSM树)来管理数据存储。LSM是一个层次树。在树的每个级别上,磁盘上都有存储该级别引用的数据的文件。这些文件称为排序字符串表文件(以下简称SST或SST文件)。
SSTs
SST是键值对排序列表的磁盘表示。从概念上讲,它们看起来像这样的图表:

SST文件是不可变的;它们从未被修改,即使在compation过程中。
LSM级别
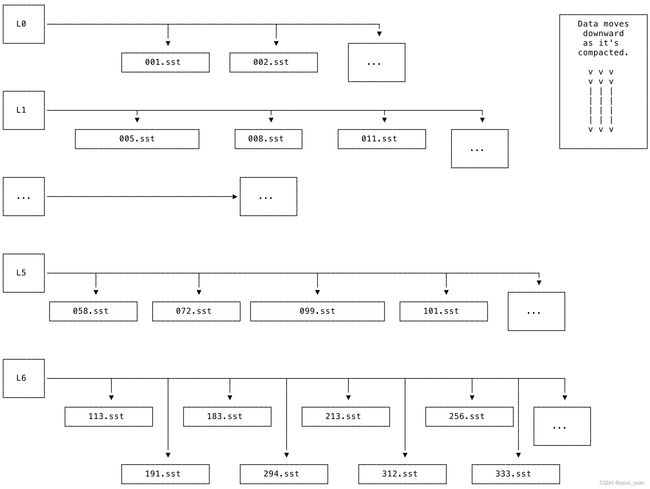
LSM的级别从L0到L6进行组织。L0是最顶层。L6是最底层。新数据被添加到L0(例如,使用INSERT或IMPORT),然后随着时间的推移合并到更低的级别。
下图显示了LSM在高层次上的样子。每个级别都与一组sst相关联。每个SST都是不可变的,并且有一个唯一的、单调递增的数字。
每个级别中的SST都保证不重叠:例如,如果一个SST包含键[A-F)(不包含),那么下一个SST将包含键[F-R),依此类推。L0级别是一种特殊情况:它是树中唯一允许包含具有重叠键的sst的级别。这个规则的例外是必要的,原因如下:
- 允许像Pebble这样基于lsm的存储引擎支持摄取大量数据,例如在使用IMPORT语句时。
- 允许更容易和更有效地刷新memtable。
合并(Compaction)
合并sst并在LSM中从L0向下移动到L6的过程称为合并。存储引擎的工作是尽可能快地合并数据。由于这个过程的结果,较低级别的LSM应该包含较大的SST,其中包含较小最近更新的键,而较高级别的LSM应该包含较小的SST,其中包含较多最近更新的键。
为了使LSM高效工作,合并过程是必要的;从L0到L6,每一层树的数据量应该是下一层树的1/10。例如,L1的数据量应该是L2的1/10,以此类推。理想情况下,尽可能多的数据将存储在LSM较低级别引用的较大SST中。如果合并过程落后,就会导致反向LSM。
SST文件在压缩过程中不会被修改。而是采用写入新的SST,删除旧的SST。这种设计利用了顺序磁盘访问比随机磁盘访问快得多的事实。
合并过程是这样工作的:如果需要合并两个SST文件A和B,则将它们的内容(键-值对)读入内存。从那里,内容被排序并合并到内存中,打开一个新文件C,并使用新的、更大的已排序的键-值对列表将其写入磁盘。这个步骤在概念上类似于归并排序。最后,删除旧文件A和B。
反向LSM树
如果合并过程落后于被添加的数据量,并且在树的较高级别存储的数据比下一级别存储的数据更多,则LSM形状可以颠倒。
反向LSM会降低读性能。
当LSM反向时,读放大很高。在反向LSM状态下,读取需要从更高的级别开始,并通过大量SST“向下查看”以读取键的正确(最新)值。当存储引擎需要从多个SST文件中读取以服务单个逻辑读取时,这种状态称为读放大。
如果一个大的IMPORT使集群过载(由于CPU和/或IOPS不足),并且存储引擎必须在L0中参考许多小SST来确定正在读取的键的最新值(例如,使用SELECT),那么读放大可能会特别糟糕。
在正常的CRDB集群中,会有一定数量的读放大。例如,“存储”仪表板上的“读放大倍数”图中显示的小于10的读放大倍数被认为是正常的。
写放大比读放大更复杂,但可以广泛地定义为:“在紧凑过程中我重写了多少物理文件?”例如,如果存储引擎在L5中进行大量的合并操作,那么它将一遍又一遍地重写L5中的SST文件。这是一种权衡,因为如果引擎不经常执行合并操作,L0的大小就会变得太大,从而导致反向LSM,这也会产生不良影响。
读放大和写放大是LSM性能的关键指标。两者本质上都不是“好”或“坏”,但它们不能过量出现,为了达到最佳性能,它们必须保持平衡。这种平衡涉及到权衡。
反向LSM也有过度的合并工作待完成。在这种状态下,存储引擎有大量的合并积压要执行,以将倒置的LSM返回到正常的非倒置状态。
内存表(memtable)和预写日志(WAL)
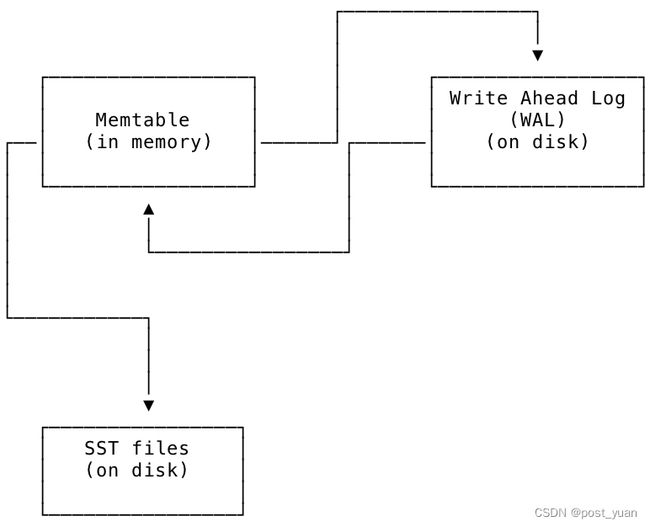
为了方便管理LSM树结构,存储引擎在内存中维护LSM的表示形式,称为memtable;定期将memtable中的数据刷新到磁盘上的SST文件中。
磁盘上的另一个名为预写日志(以下简称WAL)的文件与每个memtable相关联,以确保在电源丢失或其他故障时的持久性。WAL是将复制层发送给存储引擎的最新更新存储在磁盘上的位置。每个WAL与一个memtable有1对1的对应关系;它们保持同步,WAL和memtable的更新会定期写入SST,作为存储引擎正常操作的一部分。
memtable、WAL和SST文件之间的关系如下面的图所示。新值被写入WAL的同时被写入memtable。从memtable中,它们最终被写入磁盘上的SST文件,以便长期存储。
LSM设计权衡
LSM树的设计优化了写性能而不是读性能。通过将排序的键值数据保存在SST中,它避免了写入时的随机磁盘寻道。它试图通过从LSM树中尽可能低的位置(从更少、更大的文件)进行读取来减少读取(随机查找)的成本。这就是存储引擎执行合并的原因。存储引擎还使用块缓存在可能的情况下进一步加快读取速度。
LSM设计中的折衷是为了利用现代磁盘的工作方式,因为尽管由于缓存的存在,它们可以更快地读取磁盘上的随机位置,但在对随机位置的写入方面,它们的性能仍然相对较差。
MVCC
CRDB严重依赖于多版本并发控制(MVCC)来处理并发请求并保证一致性。大部分工作是通过使用混合逻辑时钟(HLC)时间戳来区分数据版本、跟踪提交时间戳和确定值的垃圾回收过期时间来完成的。所有这些MVCC数据都存储在Pebble中。
尽管在存储层中实现了MVCC值,但是MVCC值被广泛用于强制事务层中的一致性。例如,CRDB维护一个时间戳缓存,它存储最后一次读取键值的时间戳。如果写操作发生的时间戳低于读时间戳缓存中的最大值,则表示存在潜在的异常,必须在稍后的时间戳重新启动事务。
指定时间查询
正如SQL:2011标准中所描述的,CRDB支持指定时间查询(由MVCC启用)。
为此,所有模式信息背后都有一个类似mvcc的模型。这允许您执行SELECT…AS OF SYSTEM TIME,并且CRDB使用该时间的模式信息来制定查询。
使用这些工具,您可以从数据库中获得与垃圾收集时期一致的数据。
垃圾回收
CRDB定期垃圾收集MVCC值,以减少存储在磁盘上的数据大小。为此,当有一个较新的MVCC值,其时间戳比垃圾收集周期更早时,我们压缩旧的MVCC值。通过配置gc.ttlseconds,可以在集群、数据库或表级别设置垃圾收集周期。
受保护时间戳
垃圾收集只能在未被保护时间戳覆盖的MVCC值上运行。受保护的时间戳子系统的存在是为了确保依赖历史数据的操作的安全性,例如:
- 导入,包括IMPORT INTO
- 备份
- CDC
- 在线模式变化
受保护的时间戳确保了历史数据的安全性,同时还支持更短的GC ttl。更短的GC TTL意味着更少的以前的MVCC值被保留。对于每天频繁更新行的工作负载,这有助于降低查询执行成本,因为SQL层必须扫描以前的MVCC值来查找一行的当前值。
受保护时间戳如何工作
受保护时间戳的工作原理是创建保护记录,这些记录存储在一个内部系统表中。当一个长时间运行的作业(如备份)希望保护某个时间戳上的数据不被垃圾收集时,它会创建一个与该数据和时间戳相关联的保护记录。
成功创建保护记录后,指定数据在时间戳小于或等于受保护时间戳时的MVCC值将不会被垃圾收集。当创建保护记录的作业完成它的工作时,它将删除该记录,允许垃圾收集器在以前受保护的值上运行。