FlinkSQL快速入门
一.FlinkSQL和TableAPI简介
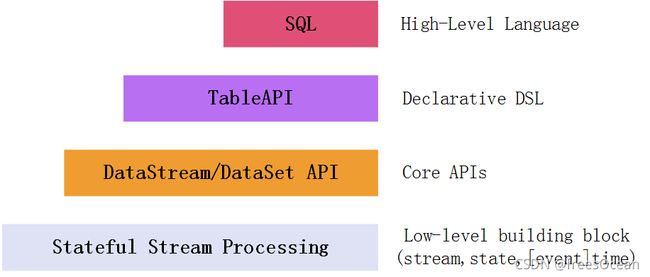
Flink针对流处理和批处理,为我们提供了多种操作API。从图中可知,越上层的API抽象程度越高,门槛越低(大家都熟悉SQL),但也丧失了灵活性。
Table API 是一系列集成在Java或Scala语言中的查询API,它允许通过一些关系运算符操作进行很直观的操作。
FlinkSQL 则是基于Apache Calcite实现了标准的SQL,可以通过编写SQL的方式进行Flink数据处理。
需要引入的依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-scala_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-csvartifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
除了Flink本身的依赖之外,首先要引入flink-table-planner,planner(计划器),用于执行TableAPI和SQL时的运行时环境,会基于运行环境解析流式处理程序,生成表的执行计划,这个类似查询数据库时一般有的操作。
其次还需要一个table-api转换器flink-table-api-java-bridge,它有java和scala两种版本,主要作用就是提供table API和底层API的转换,因为TableAPI本质还是会转为底层DataStreamAPI执行。
实际上,只需要引入一个planner即可,其中已经包含了对应的转换器依赖。

二.TableAPI示例
package com.zx.flink.table.review
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.flink.table.api.scala._
import org.apache.flink.table.api.{EnvironmentSettings, Table}
object TableApiTest0908 {
def main(args: Array[String]): Unit = {
//1.Flink执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//2.表执行环境:Flink1.12后默认使用BlinkPlanner,本示例Flink版本1.10.1,需要显式声明
val settings: EnvironmentSettings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.useBlinkPlanner()
.build()
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env, settings)
//3.连接外部系统,注册表空间
val props = new Properties
props.setProperty("bootstrap.servers", "192.168.111.101:9092")
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
//消费者组
props.put("group.id", "zm-group")
//设置自动提交offset:提交offset后,该消费者组的offset向前推移。
props.put("enable.auto.commit", "true")
//设置自动提交offset时间间隔
props.put("auto.commit.interval.ms", "1000")
//从外部数据源获取数据
val inputStream = env.addSource(new FlinkKafkaConsumer[String]("flink_sql_test", new SimpleStringSchema(), props))
//可以先用dataStreamAPI做一些转换处理
val dataStream: DataStream[UserBehavior] = inputStream
.map(data => {
val arr = data.split(",")
UserBehavior(arr(0).toLong, arr(1).toLong, arr(2).toInt, arr(3), arr(4).toLong)
})
.filter(d => {
d.behavior == "pv"
})
.assignAscendingTimestamps(_.timestamp * 1000)
//4.处理数据
//4.1.通过TableAPI处理数据示例
val sensorTable: Table = tableEnv.fromDataStream(dataStream,'userId,'itemId,'behavior,'timestamp,'pt.proctime)
val resultTable: Table = sensorTable
.select("itemId,behavior")
.filter("userId = 10086 ")
//5.输出:注意要引入隐式转换
resultTable.toAppendStream[(String, Double)].print("resultTable")
//6.执行job
env.execute("Table API Test")
}
}
/**
* 用户行为样例类
* 输入数据格式:543462,1715,1464116,pv,1511658000
*/
case class UserBehavior(userId: Long, itemId: Long, categoryId: Int, behavior: String, timestamp: Long)
这里首先要获取StreamTableEnvironment,然后,通过tableEnv.fromDataStream获取Table对象,之后就可以调用TableAPI进行数据处理。
TableEnvironment的创建
为了获取TableAPI执行环境,需要根据Flink执行环境创建。TableEnvironment 是TableAPI和FlinkSQL执行的关键。针对流处理,批处理,以及是否使用BlinkPlanner,可以根据EnvironmentSettings进行设置。最新Flink,默认是使用流处理,BlinkPlanner.
创建不同执行环境代码示例:
//先获取Flink执行环境
val env= StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1.基于老版本的流处理
val DefaultSettings:EnvironmentSettings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.useOldPlanner()
.build()
val tableEnv01 = StreamTableEnvironment.create(env,DefaultSettings)
//1.2.基于老版本的批处理:老版本还没有流批统一,所以需要批处理的环境
val batchEnv = ExecutionEnvironment.getExecutionEnvironment
val tableEnv02 = BatchTableEnvironment.create(batchEnv)
//1.3.基于新版本的流处理
val blinkSettings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.useBlinkPlanner()
.build()
val tableEnv03 = StreamTableEnvironment.create(env,blinkSettings)
//1.4.基于新版本的批处理
val blinkBatchSettings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()
.inBatchMode()
.build()
val blinkBatchTableEnv = TableEnvironment.create(blinkBatchSettings)
三.FlinkSQL使用示例
def main(args: Array[String]): Unit = {
//1.Flink执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//2.表执行环境:Flink1.12后默认使用BlinkPlanner,本示例Flink版本1.10.1,需要显式声明
val settings: EnvironmentSettings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.useBlinkPlanner()
.build()
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env, settings)
//3从外部数据源获取数据
val inputStream = env.socketTextStream("192.168.111.12", 8888)
//可以先用dataStreamAPI做一些转换处理
val dataStream: DataStream[UserBehavior] = inputStream
.map(data => {
val arr = data.split(",")
UserBehavior(arr(0).toLong, arr(1).toLong, arr(2).toInt, arr(3), arr(4).toLong)
})
.filter(d => {
d.behavior == "pv"
})
.assignAscendingTimestamps(_.timestamp * 1000)
//4.处理数据
//4.1.通过Flink SQL处理数据示例
tableEnv.createTemporaryView("dataTable",dataStream,'userId,'itemId,'behavior,'temperature,'pt.proctime)
val reTableSQL = tableEnv.sqlQuery(
"""
|select userId,behavior
|from dataTable
|where userId = 10086
""".stripMargin)
//5.输出:注意要引入隐式转换
reTableSQL.toAppendStream[(String, Double)].print("resultTable")
//6.执行job
env.execute("Flink SQL Test")
}
基本的使用流程
FlinkSQL则支持执行对应的SQL语句,完成对流数据的处理。要做到像传统数据库那样,通过执行SQL语句操作流数据,中间需要一些转换。
- 注册Catalog : 因为要模拟数据库的表,这里Catalog就类似传统数据库的表空间,可以理解为一组保存所有数据库,表,等相关元数据的集合,基于此,才能在上边模拟表,然后才能解析sql生成对应的查询计划,进行操作
- 在Catalog中注册表:因为流数据是动态数据,所以注册的这张表是一张“动态表”
- 执行SQL查询:基于注册的动态表,用sql进行处理
其中注册Catalog和注册表(视图),在代码中就是一句代码:
tableEnv.createTemporaryView("dataTable",dataStream,'userId,'itemId,'behavior,'temperature,'pt.proctime)
这里是通过dataStream构建,另外还有以下方式可以去注册表:
通过Table对象注册一张表
val table: Table = tableEnv.fromDataStream(dataStream)
tableEnv.createTemporaryView("dataTable",table)
直接连接外部数据源,注册表:
tableEnv.connect(new FileSystem().path(filePath))
.withFormat(new Csv())
.withSchema(new Schema()
.field("id", DataTypes.STRING())
.field("timestamp", DataTypes.BIGINT())
.field("temperature", DataTypes.DOUBLE())
)
.createTemporaryTable("dataTable")
有了名为dataTable,后续就可以通过SQL操作这张表
四.TableAPI和FlinkSQL对比
两者查询的底层逻辑
不管是Table API还是FlinkSQL,其底层最终都是要转换为DataStream等底层的API执行。
而且两者都是基于一张 “动态表"进行操作,操作的结果依然放在一张动态表中,因为是流式处理,所以会持续查询,结果会持续更新。
流式表查询的处理过程:
1.流被转为动态表
2.对动态表计算持续查询,生成新的动态表(结果表)
3.生成的动态表转回流

从上面也可以看到,动态表和流之间可以相互转换。下面小结一下:

FlinkSQL和TableAPI本质都是操作一张动态表(逻辑概念),动态表和DataStream直接能够相互转换,所以处理完成后,可以转换为流输出。
使用TableAPI的前提是获取Table对象:有两种获取方式:
方式一:通过dataStream获取
方式二:通过注册的某个表名获取
//通过dataStream
val table: Table = tableEnv.fromDataStream(dataStream)
//通过已经注册的某个表名
val table: Table = tableEnv.from("dataTable")
使用FlinkSQL的前提是要在表空间注册表:有两种方式
方式一:通过Table对象
方式二:通过DataStream
方式二(变种):直接connect数据源(这种本质类似通过DataStream)
//通过table对象
tableEnv.createTemporaryView("dataTable",table)
//通过dataStream,同时指定想要的字段,可以不指定
tableEnv.createTemporaryView("dataTable",dataStream,'userId,'itemId,'behavior,'temperature,'pt.proctime)
//connect数据源
tableEnv.connect(new FileSystem().path(filePath))
.withFormat(new Csv())
.withSchema(new Schema()
.field("id", DataTypes.STRING())
.field("timestamp", DataTypes.BIGINT())
.field("temperature", DataTypes.DOUBLE())
)
.createTemporaryTable("dataTable")
所以TableAPI和FlinkSQL两者无外乎是通过DataStream,还是通过对方来获取执行条件,通过DataStream可以理解为先构建动态表,之后进行操作,Table和注册表通过对方获取执行条件,可以理解动态表已经构建好,只需要获取引用,然后执行操作。当然,这种理解,只是我个人为了区分,不当之处,欢迎指正。
DataStream和Table的相互转换
上面提到操作后的结果动态表可以转换为流,具体可以转换为三种DataStream
-
仅追加(Append-only)流 :
用于表只会被插入(Insert)操作更改的场景
val resultStream: DataStream[Row] = tableEnv.toAppendStream[Row](resultTable) -
撤回(Retract)流
得到的数据会增加一个 Boolean 类型的标识位(返回的第一个字段),用它来表示到底是 新增的数据(Insert),还是被删除的数据(Delete)
val aggResultStream: DataStream[(Boolean, (String, Long))] = tableEnv .toRetractStream[(String, Long)](aggResultTable)

比如聚合场景,就是对某个状态持续聚合,在插入新结果后,旧结果会删除,以保持结果的更新,这样输出的流就会持续更新
- Upsert(更新插入)流
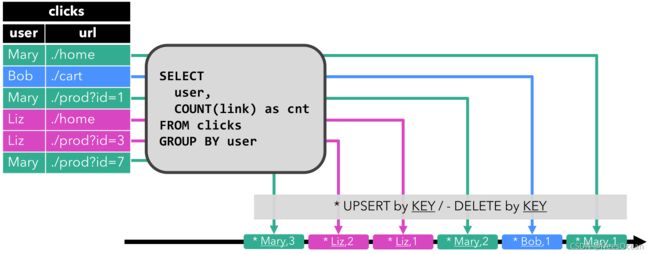
这种场景,要求外部数据源能够支持查询之前的结果,这样查找到之后,进行一次更新操作,比如ES,但如果外部数据源不支持,就无法实现。
如何确定使用场景
不管是Table API还是FlinkSQL,其底层最终都是要转换为DataStream等底层的API执行。除此之外,还有更底层的DataStreamAPI,这么多层次的API,什么场景下使用哪些API,依据是什么?
首先:SQL和Table API能实现的功能,底层API都可以实现,但是大多数情况下往往比较复杂,所以SQL和TableAPI的出现是为了简化使用Flink门槛,在大多数情况下,你只需要调用Flink SQL或者TableAPI即可,有些复杂实现要利用更底层的API. 这里说大多数情况 ,意味着,某些时候可能用底层API更加直观方便,这个要看具体业务场景。
其次:FlinkSQL和TableAPI并非相互替代的作用,两者的某些操作实现的功能类似,但是在某些场景下,两者可能各有优缺点,比如一些转换操作,可能直接通过TableAPI掉用几个算子就能实现,而像TopN计算可能用SQL实现更方便,因为有一些内置函数。
目前FlinkSQL和TableAPI还处于快速迭代发展中,很多功能不完备,所以我们需要保持开放,持续关注。