第06篇 并行流和fork-join框架
为了让我们的程序运行的更加高效,CPU的使用效率更高,我们可以通过让程序并行执行的方式让所有的CPU都忙碌起来,从而提供程序执行的效率。
有两种方式来实现并行:java8的fork-join框架、java8中的并行流(底层依然是fork-join框架)。
这里我们以计算n以内数字的和为例进行改进,也让我们能够很好的看到效果。
首先,我们定义要求和的最大数为:Long max = 1000000000L;
一、并行流
(一)经典for循环
首先我们使用经典的for循环,串行进行遍历求和:
@Test
public void serial() {
long sum = 0;
long start = System.currentTimeMillis();
for (long i = 0; i <= max; i++) {
sum += i;
}
long end = System.currentTimeMillis();
System.out.println(String.format("for循环串行计算,sum:%d,总共耗时为:%d", sum, (end - start)));
}
效果如下:
for循环串行计算,sum:500000000500000000,总共耗时为:363
(二)Stream求和
接下来,我们使用stream来遍历求和,代码如下:
@Test
public void java8Stream() {
long start = System.currentTimeMillis();
Long sum = Stream.iterate(1L, i -> i + 1)
.limit(max)
.reduce(0L, Long::sum);
long end = System.currentTimeMillis();
System.out.println(String.format("java8流式计算,sum:%d,总共耗时为:%d", sum, (end - start)));
}
效果如下:
java8流式计算,sum:500000000500000000,总共耗时为:11660
我们会发现,这种方式比for循环慢了很多,产生的原因主要如下:
- Stream本身也是串行的;
- 在进行计算的时候,我们使用的Stream流会使用包装类,在计算的时候要进行拆箱和装箱过程,会消耗大量的时间。
(三)Stream并行求和
我们可以通过把流转换成并行流来进行计算
@Test
public void java8Parallel() {
long start = System.currentTimeMillis();
long sum = Stream.iterate(1L, i -> i + 1)
.limit(max)
.parallel() //获取并行流
.reduce(0L, Long::sum);
long end = System.currentTimeMillis();
System.out.println(String.format("Java8并行流计算,sum:%d,总共耗时为:%d", sum, (end - start)));
}
效果:
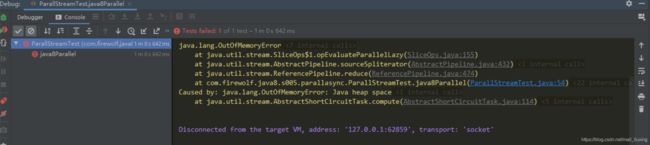
可以看到,直接发生了内存溢出,产生原因如下:
- 和上面一样,包装类会对相率产生极大的影响;
- fork-join框架底层需要使用Spliterator(后续讲解)对迭代器进行切割,进一步出现了问题;
(四)去掉拆装箱的Stream并行
在使用的时候,我们应当尽量避免包装类的转换,所以,我们可以使用LongStream 来获取数据,这样的话,就避免了不必要的拆箱和装箱。其他的场景下,我们也需要注意这一点。
@Test
public void java8ParallelWtihoutPackage() {
long start = System.currentTimeMillis();
long sum = LongStream.rangeClosed(0, max)
.parallel() //获取并行流
.sum();
long end = System.currentTimeMillis();
System.out.println(String.format("Java8并行流计算,去掉装箱拆箱,sum:%d,总共耗时为:%d", sum, (end - start)));
}
效果如下:
Java8并行流计算,去掉装箱拆箱,sum:500000000500000000,总共耗时为:252
并行流的获取
上面演示了串行到并行流的演进过程,接下来,我们给出常用的并行流获取方式:
- 获取流的使用,调用parallelStream()方法代替之前的stream()方法。如:Collection.parallelStream、Arrays.parallelStream 等待;
- 可以把普通的Stream转换成并行流,这朱啊哟是通过
parallel()方法实现; - 相反的,我们也可以把并行流转换成普通的流,方法为:
sequential
配置并行流使用的线程池
- 并行流内部使用了默认的ForkJoinPool它默认的 线程数量就是你的处理器数量,这个值是由Runtime.getRuntime().available- Processors()得到的。
- 可 以 通 过 系 统 属 性 java.util.concurrent.ForkJoinPool.common. parallelism来改变线程池大小,如下所示:
System.setProperty(“java.util.concurrent.ForkJoinPool.common.parallelism”,“12”); - 这是一个全局设置,因此它将影响代码中所有的并行流。反过来说,目前还无法专为某个 并行流指定这个值。一般而言,让ForkJoinPool的大小等于处理器数量是个不错的默认值, 除非你有很好的理由,否则我们强烈建议你不要修改它。
并行流原理
并行流的Stream在内部分成了几块。因此可以对不同的块独立并行进行归纳操作。最后,同一个归纳操作会将各个子流的部分归纳结果合并起来,得到整个原始流的归纳结果

并行流使用原则
- 如果有疑问,测量。把顺序流转成并行流轻而易举,但却不一定是好事,所以一定要进行测量。
- 留意装箱。自动装箱和拆箱操作会大大降低性能。Java 8中有原始类型流(IntStream、 LongStream、DoubleStream)来避免这种操作,但凡有可能都应该用这些流。
- 有些操作本身在并行流上的性能就比顺序流差。特别是limit和findFirst等依赖于元素顺序的操作,它们在并行流上执行的代价非常大。例如,findAny会比findFirst性能好,因为它不一定要按顺序来执行。你总是可以调用unordered方法来把有序流变成无序流。那么,如果你需要流中的n个元素而不是专门要前n个的话,对无序并行流调用 limit可能会比单个有序流(比如数据源是一个List)更高效。
- 还要考虑流的操作流水线的总计算成本。设N是要处理的元素的总数,Q是一个元素通过 流水线的大致处理成本,则N*Q就是这个对成本的一个粗略的定性估计。Q值较高就意味 着使用并行流时性能好的可能性比较大
- 对于较小的数据量,选择并行流几乎从来都不是一个好的决定。并行处理少数几个元素 的好处还抵不上并行化造成的额外开销。
- 要考虑流背后的数据结构是否易于分解。例如,ArrayList的拆分效率比LinkedList 高得多,因为前者用不着遍历就可以平均拆分,而后者则必须遍历。另外,用range工厂方法创建的原始类型流也可以快速分解。
- 流自身的特点,以及流水线中的中间操作修改流的方式,都可能会改变分解过程的性能。例如,一个SIZED流可以分成大小相等的两部分,这样每个部分都可以比较高效地并行处理,但筛选操作可能丢弃的元素个数却无法预测,导致流本身的大小未知。
- 还要考虑终端操作中合并步骤的代价是大是小(例如Collector中的combiner方法)。
流的数据源和可分解性

需要注意的是:并行流的底层,依然采用的是fork-join框架。
二、fork-join框架
分支/合并框架的目的是以递归方式将可以并行的任务拆分成更小的任务,然后将每个子任 务的结果合并起来生成整体结果。它是ExecutorService接口的一个实现,它把子任务分配给 线程池(称为ForkJoinPool)中的工作线程。
使用fork-join框架来实现并行的步骤如下:
(一)RecursiveTask
要把任务提交到这个池,必须创建RecursiveTask的一个子类,其中R是并行化任务(以 及所有子任务)产生的结果类型,或者如果任务不返回结果,则是RecursiveAction类型(当 然它可能会更新其他非局部机构)。要定义RecursiveTask,只需实现它唯一的抽象方法 compute: protected abstract R compute();
这个方法同时定义了将任务拆分成子任务的逻辑,以及无法再拆分或不方便再拆分时,生成 单个子任务结果的逻辑。正由于此,这个方法的实现类似于下面的伪代码:
if (任务足够小或不可分) { 顺序计算该任务
} else {
将任务分成两个子任务
递归调用本方法,拆分每个子任务,等待所有子任务完成
合并每个子任务的结果
}
(二)fork-join过程
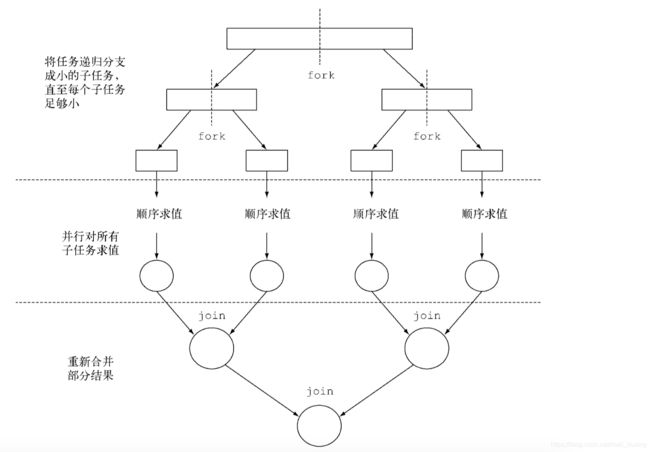
(三)使用示例
- 定义自己的RecursiveTask
package com.firewolf.java8.s005.parallasync;
import java.util.concurrent.RecursiveTask;
/**
* Java7中的并行计算
* 定义一个用于拆分和合并的计算类
* 这个类需要继承RecursiveAction(没有返回值)或者是RecursiveTask(有返回值)
*
* @author liuxing
*/
public class ForkCalculater extends RecursiveTask {
private static final long serialVersionUID = -6790744108691400188L;
private long start;
private long end;
private long boundary = 10000;
public ForkCalculater(long start, long end) {
super();
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long length = end - start;
if (length >= boundary) { //进行任务划分
long middle = (start + end) / 2;
ForkCalculater left = new ForkCalculater(start, middle);
left.fork(); //利用另一个ForkJoinPool线程异步执行新创建的子任务
ForkCalculater right = new ForkCalculater(middle + 1, end);
Long rightResult = right.compute(); //同步执行右边的,这样可以减少提交到线程池中的任务,当然,调用join也是可以的
Long leftResult = left.join(); // 同步等在左边的结果
return leftResult + rightResult;
} else {// 不能再划分的时候,进行计算
long sum = 0;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
}
}
}
- 使用
@Test
public void fork_join() {
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask t = new ForkCalculater(0, max);
long start = System.currentTimeMillis();
Long sum = pool.invoke(t);
long end = System.currentTimeMillis();
System.out.println(String.format("fork-join计算框架,sum:%d,总共耗时为:%d", sum, (end - start)));
}
效果:
fork-join计算框架,sum:500000000500000000,总共耗时为:279
我们可以看到,效率也是非常的高
而问题在于,代码写起来太过麻烦,主要是RecursiveTask的编写,比较痛苦
(四)工作原理
fork-join采用了一种“工作窃取”的技术来提供计算的效率,具体如下:
理想情况下,划分并行任务时, 应该让每个任务都用完全相同的时间完成,让所有的CPU内核都同样繁忙。不幸的是,实际中,每 个子任务所花的时间可能天差地别,要么是因为划分策略效率低,要么是有不可预知的原因,比如 磁盘访问慢,或是需要和外部服务协调执行。
分支/合并框架工程用一种称为工作窃取(work stealing)的技术来解决这个问题。在实际应 用中,这意味着这些任务差不多被平均分配到ForkJoinPool中的所有线程上。每个线程都为分 配给它的任务保存一个双向链式队列,每完成一个任务,就会从队列头上取出下一个任务开始执 行。基于前面所述的原因,某个线程可能早早完成了分配给它的所有任务,也就是它的队列已经 空了,而其他的线程还很忙。这时,这个线程并没有闲下来,而是随机选了一个别的线程,从队 列的尾巴上“偷走”一个任务。这个过程一直继续下去,直到所有的任务都执行完毕,所有的队 列都清空。这就是为什么要划成许多小任务而不是少数几个大任务,这有助于更好地在工作线程 之间平衡负载。
(五)fork-join使用建议
- 对一个任务调用join方法会阻塞调用方,直到该任务做出结果。因此,有必要在两个子任务的计算都开始之后再调用它。否则,你得到的版本会比原始的顺序算法更慢更复杂,因为每个子任务都必须等待另一个子任务完成才能启动。
- 不应该在RecursiveTask内部使用ForkJoinPool的invoke方法。相反,你应该始终直接调用compute或fork方法,只有顺序代码才应该用invoke来启动并行计算。
- 对子任务调用fork方法可以把它排进ForkJoinPool。同时对左边和右边的子任务调用它似乎很自然,但这样做的效率要比直接对其中一个调用compute低。这样做你可以为其中一个子任务重用同一线程,从而避免在线程池中多分配一个任务造成的开销。
- 和并行流一样,你不应理所当然地认为在多核处理器上使用分支/合并框架就比顺序计算快。
三、Spliterator
Spliterator是Java 8中加入的另一个新接口;这个名字代表“可分迭代器”(splitable iterator)。和Iterator一样,Spliterator也用于遍历数据源中的元素,但它是为了并行执行 而设计的
Stream的并行计算,就是依赖了Spliterator来自动的对流进行了拆分。
通常情况下,我们不需要自己实现,当然如果需要实现的话,我们需要去实现Spliterator接口。
(一)Spliterator接口
这个接口定义的几个方法如下:
boolean tryAdvance(Consumer action);:类似于普通的 Iterator,因为它会按顺序一个一个使用Spliterator中的元素,并且如果还有其他元素要遍 历就返回true
Spliterator:专为Spliterator接口设计的,因为它可以把一些元素划出去分 给第二个Spliterator(由该方法返回),让它们两个并行处理,需要注意的是, 这里仅仅返回划分出来的那一部分。
long estimateSize();:估计还剩下多少元素要遍历,因为即使不那么确切,能快速算出来是一个值 也有助于让拆分均匀一点
int characteristics();:返回这个Spliterator的特性集合,可选值如下:

如果有多个特点,就加起来
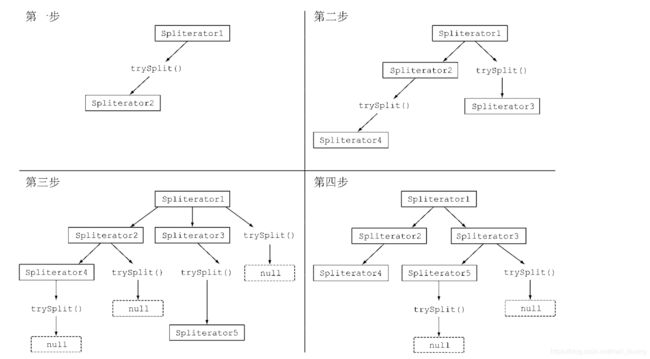
(二)拆分过程
将Stream拆分成多个部分的算法是一个递归过程。第一步是对第一个 Spliterator调用trySplit,生成第二个Spliterator。第二步对这两个Spliterator调用 trysplit,这样总共就有了四个Spliterator。这个框架不断对Spliterator调用trySplit 直到它返回null,表明它处理的数据结构不能再分割,如图所示:
(三)自定义Spliterator示例
这里以统计字符串中单词的数量来示例
字符串内容为:
private final String CONTENTS = "Nel mezzo del cammin di nostra vita i ritrovai in una selva oscura ché la dritta via era smarrita";
为了演示效果,这里没有使用字符串的方法。
1. 普通for循环完成统计
@Test
public void forWordCounter() {
int counter = 0;
boolean lastSpace = true;
for (char c : CONTENTS.toCharArray()) {
if (Character.isWhitespace(c)) {
lastSpace = true;
} else {
if (lastSpace)
counter++;
lastSpace = false;
}
}
System.out.println(counter);
}
结果是19个
2. 使用Stream计算
由于每个字符传入后,需要返回单词的数量已经是否是空格,所以需要顶一个对象来实现
package com.firewolf.java8.s005.parallasync;
/**
* 单词统计器
*/
public class WordCounter {
private int counter; //单词数量
private boolean isWhitespace; //是否是空格
public WordCounter(int counter, boolean isWhitespace) {
this.counter = counter;
this.isWhitespace = isWhitespace;
}
/**
* 累积函数,对每一个字符进行处理
* @param c 要被处理的字符
* @return
*/
public WordCounter accumulate(Character c) {
if (Character.isWhitespace(c)) { // 当前传入的字符为空
return new WordCounter(this.counter, true);
} else { // 当前传入的字符不为空,那么如果上一个字符为空,数量就要+1了,
return isWhitespace ? new WordCounter(this.counter + 1, false) : new WordCounter(this.counter, false);
}
}
/**
* 合并函数,把两个结果合并成一个结果
* @param wc 另外一个结果
* @return 合并后的结果
*/
public WordCounter combiner(WordCounter wc) {
return new WordCounter(wc.counter + this.counter, wc.isWhitespace);
}
/**
* 返回当前统计的单词数量
* @return 单词数量
*/
public int getCounter() {
return this.counter;
}
}
这里面还同时定义了累计函数和合并函数
接下来,进行计算
/**
* 通过流来统计单词个数
*/
@Test
public void streamWordCounter() {
Stream charStream = transStr2CharStream();
countWords(charStream);
}
/**
* 通过流统计单词数量
* @param stream
*/
private void countWords(Stream stream) {
WordCounter reduce = stream.reduce(new WordCounter(0, true), WordCounter::accumulate, WordCounter::combiner);
System.out.println(reduce.getCounter());
}
这个结果也没什么问题。
3. 使用并行流求单词数量
@Test
public void parallStramWordCounter(){
Stream charStream = transStr2CharStream();
countWords(charStream.parallel());
}
/**
* 把字符串转换成流
*
* @return
*/
private Stream transStr2CharStream() {
Stream charStream = IntStream.range(0, CONTENTS.length()).mapToObj(CONTENTS::charAt);
return charStream;
}
得到的结果为30,是错误的,原因是底层进行拆分的时候,把单词给拆开了,为了解决这个问题,我们需要定义自己的Spliterator
4. 自定义Spliterator
自定义Spliterator如下:
package com.firewolf.java8.s005.parallasync;
import java.util.Spliterator;
import java.util.function.Consumer;
public class WCSpliterator implements Spliterator {
private String str; // 要被处理的字符串
private int curentIndex = 0; // 当前处理的字符的下标
public WCSpliterator(String str) {
this.str = str;
}
/**
* 普通的迭代
*
* @param action
* @return
*/
@Override
public boolean tryAdvance(Consumer action) {
action.accept(str.charAt(curentIndex++));
return curentIndex < str.length();
}
/**
* 拆分出来的迭代器
*
* @return
*/
//注意,返回的是拆分出来的这一部分
@Override
public Spliterator trySplit() {
int currentLenght = str.length() - curentIndex;
//长度小于10之后不再拆分,直接顺序处理,所以返回null
if (currentLenght < 10) {
return null;
}
for (int splitPos = currentLenght / 2 + curentIndex; splitPos < str.length(); splitPos++) {
if (Character.isWhitespace(str.charAt(splitPos))) {
Spliterator spliterator = new WCSpliterator(str.substring(curentIndex, splitPos));
curentIndex = splitPos;
return spliterator;
}
}
return null;
}
//估算剩余长度
@Override
public long estimateSize() {
return str.length() - curentIndex;
}
/**
* 返回这个Spliterator的特点
* ORDERED:顺序的(也就是String中各个Character的次序)
* SIZED: estimatedSize方法的返回值是精确的
* SUBSIZED: trySplit方法创建的其他Spliterator也有确切大小
* NONNULL: String中不能有为null的Character
* IMMUTABLE:在解析String时不能再添加Character,因为String本身是一个不可变类
*
* @return
*/
@Override
public int characteristics() {
return ORDERED + SIZED + SUBSIZED + NONNULL + IMMUTABLE;
}
}
计算代码:
@Test
public void parallSteamWCBySelfSpliterater(){
Spliterator spliterator = new WCSpliterator(CONTENTS);
Stream stream = StreamSupport.stream(spliterator, true);
countWords(stream.parallel());
}
这次的计算结果,就正确了