雪花算法-java
前言:
作者简介:我是笑霸final,一名热爱技术的在校学生。
个人主页:个人主页1 || 笑霸final的主页2
系列专栏:计算机基础专栏
如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步
如果感觉博主的文章还不错的话,点赞 + 关注 + 收藏

目录
- 一、初识雪花算法
- 二、为什么需要分布式id
- 三、手写雪花算法
-
- 3.1实现时间戳
- 3.2 代码分析
- 3.3整体代码
一、初识雪花算法
雪花(snowflake):大自然中找不到几乎完全一样的雪花。
Snowflake,雪花算法是由Twitter开源的分布式ID生成算法,以划分命名空间的方式将 64-bit位分割成多个部分,每个部分代表不同的含义。
组成部分
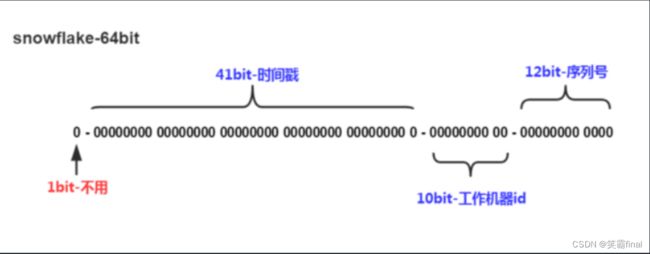
- 第1位占用1-bit,是符号位通常不使用。
- 第2位开始的41-bit是时间戳。可表示2^41个数,每个数代表毫秒 可表示69年。
- 中间的10-bit位可表示机器数,即2^10 = 1024台机器。
- 最后12-bit位是自增序列,可表示2^12 = 4096个数。
二、为什么需要分布式id
在分布式服务架构模式下分库分表的设计,使得
多个库或多个表存储相同的业务数据。这种情况根据数据库的自增ID就会产生相同ID的情况,不能保证主键的唯一性。
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。如在美团点评的金融、支付、餐饮、酒店、猫眼电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求;特别一点的如订单、骑手、优惠券也都需要有唯一ID做标识。此时一个能够生成全局唯一ID的系统是非常必要的。
三、手写雪花算法
实现雪花算法主要要实现3个数字
- now 生成id的时间戳
- workId 机器编号id 一般分为 工作ID + 数据中心ID
- n 序列号(同一时间内生成的第几个id从0开始)
步骤
- 先获取当前毫秒时间戳
- 比较当前时间戳和前一个时间戳
- 如果时间戳相同 则序列号+1 如果不同 则序列号sequence=0 【注意范围】
- 最后一次生成的时间戳更新为当前的时间戳。
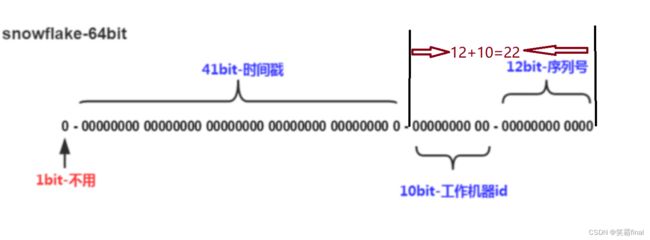
- 将当前时间戳左翼22位, 机器编码id左移12位 ,序列号用或运算拼接起来【左移 右边补0】
3.1实现时间戳
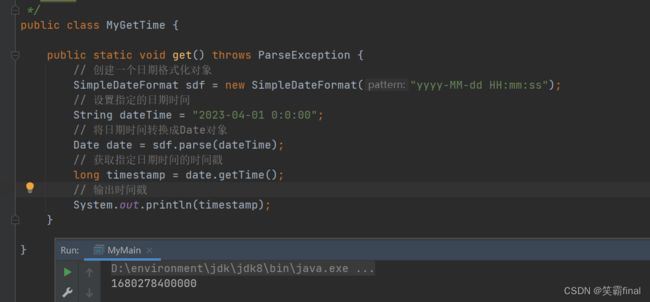
获取指定时间的时间戳
public class MyGetTime {
public static void get() throws ParseException {
// 创建一个日期格式化对象
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// 设置指定的日期时间
String dateTime = "2023-04-01 0:0:00";
// 将日期时间转换成Date对象
Date date = sdf.parse(dateTime);
// 获取指定日期时间的时间戳
long timestamp = date.getTime();
// 输出时间戳
System.out.println(timestamp);
}
}
获取当前时间的时间戳
public static void getNow(){
long timeMillis = System.currentTimeMillis();
// 输出时间戳
System.out.println(timeMillis);
}

3.2 代码分析
定义一些属性
- 工作ID + 数据中心ID = 10bit的工作机器id
- 毫秒内序列(0~4095)
- 上次生成ID的时间截
/**
* 设置开始时间戳(13位)
* 时间是 2023-04-01 0:0:00
*/
private final long twepoch = 1680278400000L;
// 41-bit是时间戳 10-bit位可表示机器数 12-bit位是自增序列
/**
* 序列在id中占的位数
*/
private final long sequenceBits = 12L;
// 机器数10位 一般= 机器id所占的位数+数据标识id所占的位数 一共10 bit
/**
* 机器id所占的位数
*/
private final long workerIdBits = 5L;
/**
* 数据标识id所占的位数
*/
private final long datacenterIdBits = 5L;
/**
* 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数)
*/
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/**
* 支持的最大数据标识id,结果是31
*/
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/**
* 机器ID向左移12位
*/
private final long workerIdShift = sequenceBits;
/**
* 数据标识id向左移17位(12+5)
*/
private final long datacenterIdShift = sequenceBits + workerIdBits;
/**
* 时间截向左移22位(5+5+12)
*/
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/**
* 生成序列的掩码,这里为 4095 (0b111111111111=0xfff=4095)
* 为了比较生成的序列号是否超出范围
*/
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/**
* 工作机器ID(0~31)
*/
private long workerId;
/**
* 数据中心ID(0~31)
*/
private long datacenterId;
/**
* 毫秒内序列(0~4095)
*/
private long sequence = 0L;
/**
* 上次生成ID的时间截
*/
private long lastTimestamp = -1L;
构造函数
/**
* 构造函数
*
* @param workerId 工作ID (0~31)
* @param datacenterId 数据中心ID (0~31)
* 工作ID + 数据中心ID = 10bit的工作机器id
*/
public SnowflakeDistributeId(long workerId, long datacenterId) {
//maxWorkerId 是机器最大id 31
if (workerId > maxWorkerId || workerId < 0) {
//工作ID超过或最大值 或小于o 就抛出异常
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
//maxDatacenterId 数据标识id 最大值是 31
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
获得下一个ID (该方法是线程安全的)

/**
* 获得下一个ID (该方法是线程安全的)
*
* @return SnowflakeId
*/
public synchronized long nextId() throws InterruptedException {
//获取当前时间戳
long timestamp = System.currentTimeMillis();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
Thread.sleep(1);
timestamp = System.currentTimeMillis();
}
}
//时间戳改变,毫秒内序列重置
else {
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
}
3.3整体代码
public class demo {
// ==============================Fields===========================================
/**
* 开始时间截 (2015-01-01)
*/
private final long twepoch = 1420041600000L;
/**
* 机器id所占的位数
*/
private final long workerIdBits = 5L;
/**
* 数据标识id所占的位数
*/
private final long datacenterIdBits = 5L;
/**
* 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数)
*/
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/**
* 支持的最大数据标识id,结果是31
*/
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/**
* 序列在id中占的位数
*/
private final long sequenceBits = 12L;
/**
* 机器ID向左移12位
*/
private final long workerIdShift = sequenceBits;
/**
* 数据标识id向左移17位(12+5)
*/
private final long datacenterIdShift = sequenceBits + workerIdBits;
/**
* 时间截向左移22位(5+5+12)
*/
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/**
* 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095)
*/
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/**
* 工作机器ID(0~31)
*/
private long workerId;
/**
* 数据中心ID(0~31)
*/
private long datacenterId;
/**
* 毫秒内序列(0~4095)
*/
private long sequence = 0L;
/**
* 上次生成ID的时间截
*/
private long lastTimestamp = -1L;
//==============================Constructors=====================================
/**
* 构造函数
*
* @param workerId 工作ID (0~31)
* @param datacenterId 数据中心ID (0~31)
*/
public demo( long datacenterId,long workerId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
// ==============================Methods==========================================
/**
* 获得下一个ID (该方法是线程安全的)
*
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
}
//时间戳改变,毫秒内序列重置
else {
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
}
/**
* 阻塞到下一个毫秒,直到获得新的时间戳
*
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 返回以毫秒为单位的当前时间
*
* @return 当前时间(毫秒)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
}
//阻塞到下一个毫秒,获得新的时间戳新增加了
tilNextMillis()、timeGen()方法
结果
SnowflakeDistributeId snowflakeDistributeId = new SnowflakeDistributeId(0, 1);
for (int i = 0; i < 10; i++) {
long id = snowflakeDistributeId.nextId();
System.out.println(id+"对应的二进制"+Long.toBinaryString(id));
}
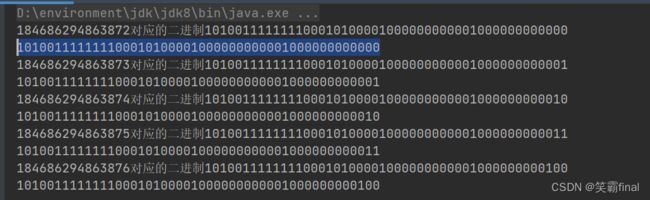
分析:
101001111111100010100001000000000001000000000000可能想这也没有64位啊 这里 后12位是序列号 然后就是10位的工作机器的id 剩下的其实是当前时间戳与指定的开始时间戳的差值。
前面补0就行了。
