Procfs (一) /proc/* 文件解析
1.1 Procfs概述
Procfs 是进程文件系统的缩写,包含一个伪文件系统(启动时动态生成的文件系统),用于通过内核访问进程信息。这个文件系统通常被挂载到 /proc 目录。
由于 /proc 不是一个真正的文件系统(概念参考本文2.1.12节),它也就不占用存储空间,只是占用有限的内存。/proc中的文件可以被修改,但一般不可以被删除。
1.2 Procfs文件用途
Procfs的文件都在/proc目录下,可以直接cd到对应目录进行查看。因为不同内核版本,不同发行版本的/proc目录存在一定差异(内核版本相关知识可参考本文2.1.38节),所以并没有所谓的/proc文件夹文件大全,只有相对比较齐全的版本。以下为笔者整理的/proc下各文件/文件夹的用途,来自kernel.org和笔者的云主机centos7。
2. Procfs具体文件
2.1 /proc/* 具体文件解析
本文以笔者的云主机中(centos7,内核版本3.10.0-1160.15.2.el7.x86_64 )的/proc目录为例进行说明,共分41个小结进行讲解,包含共42个文件的解析。因篇幅限制,本文仅针对/proc下的文件,暂不包含对应的二级目录/proc/acpi, /proc/fs, /proc/irq, /proc/sys, /proc/net等中的文件,/proc/sys, /proc/net中的文件会单独在后续的文章中进行解析。
注:本文在读取文件时均使用了cat -n,这导致第一列多出一列序号,仅用于讲解方便,请忽略首列。
2.1.1 /proc/buddyinfo
/proc/buddyinfo是linuxbuddy系统管理物理内存的debug信息。在linux中使用buddy算法解决物理内存的外碎片问题,buddy算法会把所有空闲的内存,以2的幂次方的形式,分成11个页块链表,分别对应为1、2、4、8、16、32、64、128、256、512、1024个页块,buddy算法的原理按笔者的理解可以汇总成下图。

另外,Linux还支持NUMA(Non-uniform memory access )技术,与之相对的是UMA技术,两者的区别在于NUMA支持多节点,UMA只支持单节点。NUMA系统的节点通常由CPU和其对应的本地内存(NUMA将内存划成本地/远程,CPU访问不同位置的内存,代价是不一样的),在/proc/buddyinfo中,使用"Node 0"这样的ID来标识NUMA系统的某个节点。而对于每一个节点,它的本地内存又可以根据具体用途划分为多个内存区域(zone),因此在下面的输出中,对于Node 0的本地内存,又会划分为DMA、DMA32、Normal等区域。具体的区域可以参照此链接或者本文2.1.41(zoneinfo)节,NUMA相关可以参考此链接。
[root@hecs-197747 proc]# cat -n buddyinfo
1 Node 0, zone DMA 4 2 1 4 2 2 2 2 3 1 2
2 Node 0, zone DMA32 15801 1203 626 414 402 29 6 4 2 1 0
3 Node 0, zone Normal 1806 901 431 164 37 0 0 0 0 0 0
#列分别为:Node, Zone 1Pg 2Pgs 4Pgs 8Pgs 16Pgs 32Pgs 64Pgs 128Pgs 256Pgs 512Pgs 1024Pgs
复制代码2.1.2 /proc/cgroups
/proc/cgroups里为cgroups相关状态。cgroups(Control Groups) 是 linux 内核提供的一种机制,这种机制可以根据需求把一系列系统任务及其子任务整合(或分隔)到按资源划分等级的不同组内,从而为系统资源管理提供一个统一的框架。简单说,cgroups 可以限制、记录任务组所使用的物理资源。本质上来说,cgroups 是内核附加在程序上的一系列钩子(hook),通过程序运行时对资源的调度触发相应的钩子以达到资源追踪和限制的目的,cgroups的相关知识可以参照此链接。
[root@hecs-197747 proc]# cat -n cgroups
1 #subsys_name hierarchy num_cgroups enabled
2 cpuset 9 1 1
3 cpu 3 1 1
4 cpuacct 3 1 1
5 memory 2 1 1
6 devices 8 52 1
7 freezer 11 1 1
8 net_cls 6 1 1
9 blkio 7 1 1
10 perf_event 5 1 1
11 hugetlb 10 1 1
12 pids 4 1 1
#列分别为 cgroups支持的子系统名 层级 控制组数量 控制组是否启用
复制代码2.1.3 /proc/cmdline
/proc/cmdline里为linux内核的启动参数。在linux中,可以使用boot管理器比如lilo或者grub进行linux内核的启动,也可以直接传递参数给linux内核来启动。如果需要查看boot时传递给内核的参数,可以cat/proc/cmdlinecat /proc/cmdlinecat/proc/cmdline或者使用dmesg∣grep"Commandline"dmesg | grep "Command line"dmesg∣grep"Commandline",详细可参照此链接。
[root@hecs-197747 proc]# cat -n cmdline
1 BOOT_IMAGE=/boot/vmlinuz-3.10.0-1160.15.2.el7.x86_64 root=UUID=b64c5c5d-9f6b-4754-9e1e-eaef91437f7a ro net.ifnames=0 consoleblank=600 console=tty0 console=ttyS0,115200n8 spectre_v2=off nopti crashkernel=auto LANG=en_US.UTF-8
#BOOT_IMAGE为启动时用的镜像,root为根设备(硬盘)的名称,ro为readonly,net.ifnames和后面的都是一些其他启动参数的名称
复制代码2.1.4 /proc/cpuinfo
/proc/cpuinfo里为linux的cpu信息。在linux系统中,如果想了解系统中CPU的提供商和相关配置信息,则可以查看/proc/cpuinfo。详细字段名如下表。
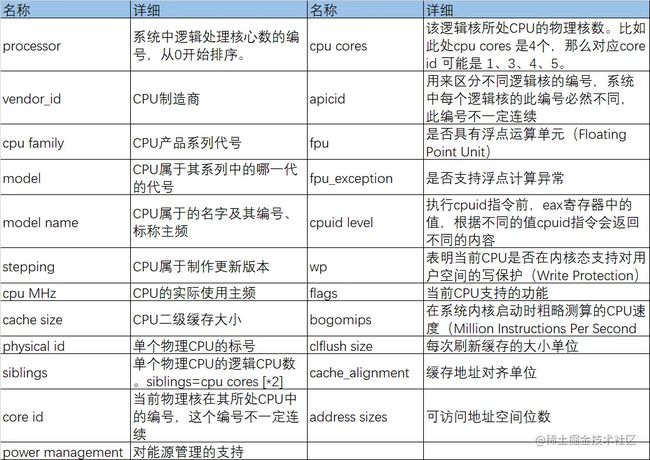
[root@hecs-197747 proc]# cat -n cpuinfo
1 processor : 0
2 vendor_id : GenuineIntel
3 cpu family : 6
4 model : 85
5 model name : Intel(R) Xeon(R) Gold 6161 CPU @ 2.20GHz
6 stepping : 4
7 microcode : 0x1
8 cpu MHz : 2200.000
9 cache size : 30976 KB
10 physical id : 0
11 siblings : 2
12 core id : 0
13 cpu cores : 1
14 apicid : 0
15 initial apicid : 0
16 fpu : yes
17 fpu_exception : yes
18 cpuid level : 13
19 wp : yes
20 flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 arat md_clear spec_ctrl intel_stibp flush_l1d
21 bogomips : 4400.00
22 clflush size : 64
23 cache_alignment : 64
24 address sizes : 42 bits physical, 48 bits virtual
25 power management:
复制代码2.1.5 /proc/console
/proc/console为最近用于/dev/console的字符串设备信息。
[root@hecs-197747 proc]# cat -n consoles
1 ttyS0 -W- (EC p a) 4:64
2 tty0 -WU (E p ) 4:1
#R = can do read operations
#W = can do write operations
#U = can do unblank
#E = it is enabled
#C = it is preferred console
#B = it is primary boot console
#p = it is used for printk buffer
#b = it is not a TTY but a Braille device
#a = it is safe to use when cpu is offline
复制代码2.1.6 /proc/crypto
/proc/crypto为所有被linux内核使用到的密码学加密组件的列表。
[root@hecs-197747 proc]# cat -n crypto
1 name : crc32
2 driver : crc32-pclmul
3 module : crc32_pclmul
4 priority : 200
5 refcnt : 1
6 selftest : passed
7 type : shash
8 blocksize : 1
9 digestsize : 4
... (此处省略后面的输出内容)
复制代码2.1.7 /proc/devices
/proc/devices为linux系统已经配置的字符串设备和块设备的列表。字符串设备提供连续的数据流,应用程序可以顺序读取,通常不支持随机存取,通常为键盘、串口;块设备可以被应用程序随机访问设备数据,通常为硬盘、软盘、闪存。字符串设备和块设备的区别可以概括为:一,字符串设备不需要buffering(buffer的定义参考下图)。二,字符串设备发送数据前不需要预先配置size。

[root@hecs-197747 proc]# cat -n devices
1 Character devices:
2 1 mem
3 4 /dev/vc/0
4 4 tty
5 4 ttyS
6 5 /dev/tty
7 5 /dev/console
8 5 /dev/ptmx
9 7 vcs
10 10 misc
11 13 input
12 29 fb
13 99 ppdev
14 128 ptm
15 136 pts
16 162 raw
17 180 usb
18 188 ttyUSB
19 189 usb_device
20 202 cpu/msr
21 203 cpu/cpuid
22 226 drm
23 242 dimmctl
24 243 ndctl
25 244 virtio-portsdev
26 245 aux
27 246 hidraw
28 247 usbmon
29 248 bsg
30 249 hmm_device
31 250 watchdog
32 251 iio
33 252 rtc
34 253 dax
35 254 tpm
36
37 Block devices:
38 2 fd
39 259 blkext
40 9 md
41 253 virtblk
42 254 mdp
复制代码2.1.8 /proc/diskstats
/proc/diskstats展示了块设备(硬盘)的I/O统计数据。使用iostats使用的便是里面的信息。
[root@hecs-197747 proc]# cat -n diskstats
1 253 0 vda 448190 4127 29774818 2822415 24653963 10316559 804508256 24820119 0 20308011 27642534
2 253 1 vda1 448161 4127 29772730 2822396 24080652 10316559 804508256 24784881 0 20293918 27607277
#除去第一列的行标号,列分别为:
#设备号(253)、次设备号(0)、设备名称(vda)
#成功完成读的总次数、合并读总次数、读扇区的次数、读花的总时间
#成功完成写的总次数、合并写总次数、写扇区的次数、写花的总时间
#I/O当前进度(一般为0)、输入输出花的总是加、输入输入花费的加权毫秒数
复制代码2.1.9 /proc/dma
/proc/dma是当前支持(或使用)的dma传输。直接内存访问(Direct Memory Access,DMA)是计算机科学中的一种内存访问技术。它允许某些电脑内部的硬件子系统(电脑外设),可以独立地直接读写系统内存,而不需中央处理器(CPU)介入处理 。在同等程度的处理器负担下,DMA是一种快速的数据传送方式。很多硬件的系统会使用DMA,包含硬盘控制器、绘图显卡、网卡和声卡。
DMA的工作过程如下图所示,设备需要DMA传输时,首先会向DMA控制器(8237)发送DRQ;DMA控制器收到DRQ后,会通过HRQ向CPU发送HOLD请求;CPU收到HRQ后,会先完成当前工作,然后挂起、让出总线,最后发送HLDA;8237收到HLDA后,会用DACK向设备通知总线已经就位。最终,设备通过总线直接(不经过CPU)向内存传输数据。详情可参考此链接。
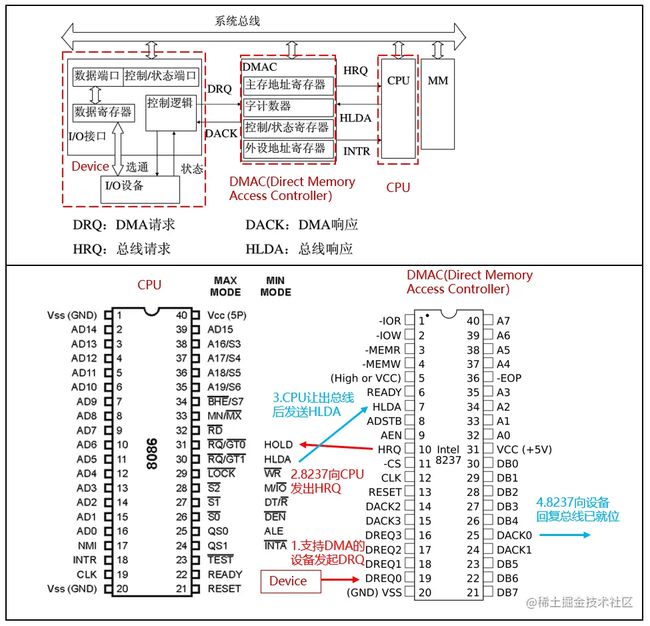
[root@hecs-197747 proc]# cat -n dma
1 2: floppy
2 4: cascade
#在8237中,有4个DRQ引脚,对应支持的便是4个DMA Channel,DRQ0即0号Channel,DRQ1即1号引脚,以此类推。下面是DMA Channel的通用用途。
#DMA Channel Standard Assignment
#0 Available
#1 Available but is the Default for most Sound Cards
#2 Floppy disk controller
#3 ECP parallel port on LPT 1
#4 Cascade for the second device (DMA 0 to 3)
#5 Available but is also the Default for some Sound Cards
#6 Available
#7 Available
复制代码2.1.10 /proc/execdomains
/proc/execdomains是当前Linux内核支持的执行域。在不同操作系统上,如果对同一段代码进行编译链接(可以用c/go的代码测试一下),得到的二进制文件一般是不一样的,这些二进制文件一般也是不能跨平台运行的,比如我在windows编译链接出一个二进制文件,在windows中可以运行,但传到linux里大概率是运行不成功的。在这个背景上,linux引入了execution domain,用这个字段去标识程序所需的操作系统(在哪种操作系统上编译就需要哪种),同时编写了相关的兼容代码,将某操作系统上编译链接的程序映射到linux操作系统上可运行的程序。在运行程序前,可以通过personality()这个系统调用改变程序对应的execution domain,来实现对某些操作系统上编译的程序的兼容运行(但很遗憾,目前好像还是不支持windows上编译的程序运行)。execdomains可以类比为Windows的兼容模式,当win10运行有问题的时候,可以以win7/win vista来兼容运行。不同的persinality字段对应的系统如下
[root@hecs-197747 proc]# cat -n execdomains
1 0-0 Linux [kernel]
#笔者的云服务器上的centos好像只支持一种execution domain也就是原生的linux,所以没办法运行上面列出的系统上编译的程序
复制代码2.1.11 /proc/fb
/proc/fb为framebuffer设备列表。framebuffer是内存中的一段数据,这段数据包含一个位图,它可以驱动视频文件的播放。在linux中,fbdev(framebuffer device)是一种面向视频硬件的图形抽象层,可以将复杂的底层硬件映射成相同的可操作单元。
[root@hecs-197747 proc]# cat -n fb
1 0 cirrusdrmfb
复制代码2.1.12 /proc/filesystems
/proc/filesystems为linux支持的文件系统。文件系统按照我的理解,可以理解为一种转化规则。我们平时看到的文件,虽然可以打开关闭读写执行这些操作,但如果没有显示器也是看不见也摸不着的,它在本质上是物理设备上的高低电荷抽象出来的产物。文件系统就是物理设备电荷和文件之间的一种转化规则,它规定了一个文件需要多少电荷来承载,如何从设备上的电荷读出文件,如何将文件存储为物理设备上的电荷。
在这种意义上,如果存在某种规则可以把一个物理设备(比如usb设备)或物理设备的一部分(比如某一段内存)上的电荷抽象成文件,并且可以将文件转化成物理设备上的电荷,那它就可以是一个文件系统。比如我现在有一台打印机设备,自己又编程了一个打印机文件系统(myprinterfs),可以在连接这台打印机后,将这台打印机的某个部分作为文件来执行新建、删除、读、写等文件操作,那我也可以管myprinterfs叫做文件系统。因此,文件系统的数量和外接设备的种类品牌成正比,另外,同一种外接设备(比如磁盘)也有可能会随着时间更替,出现新的更高效的转化规则也就是新的文件系统(比如从ext2到ext3),所以已有的文件系统会显得五花八门种类繁多。单个物理设备或物理设备的部分(比如windows的C盘D盘,linux的partion)只能有一个文件系统,还存在一些文件系统之上的文件系统,比如docker用到的UFS.下图为从维基百科截下来的文件系统列表。
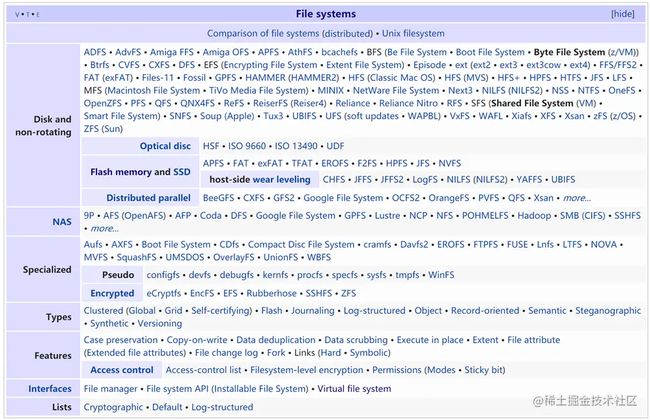
特别的是,上图中Interfaces一栏的virtual file system(VFS),这与种类繁多的其他文件系统如何去管理有关。假如我要将ext3文件系统中的某个文件迁移到ext2的文件系统中,则要从ext3文件系统的物理设备中读出电荷,再按ext2文件系统的规则将电荷写入另一个物理设备中。假如我们把从ext3迁移到ext2调用的函数叫做MOV_EXT3_EXT2,那么从ext2迁移到ext3,又会有另一个函数MOV_EXT2_EXT3。
这只是两种文件系统的情况,假如现在有n种文件系统,则有A(2∣n)A(2|n)A(2∣n)种MOV函数,这对于开发者来说是极不友好的,开发者仅移动一个文件,就需要去确认源目文件夹的文件系统到底是什么,然后调用对应的函数。所以在这个基础上,linux引入了VFS,作为一个虚拟层,横在应用程序和其他文件系统之间,统一提供诸如读、写、复制、迁移等操作的接口,这样用户就可以一视同仁对待所有文件(其实严格意义上是大部分),不管文件是在ext2还是ext3的物理设备中,下面的细节都不需要普通使用者或开发者关心。
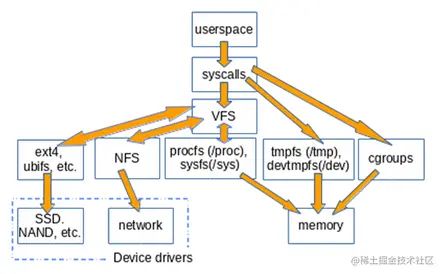
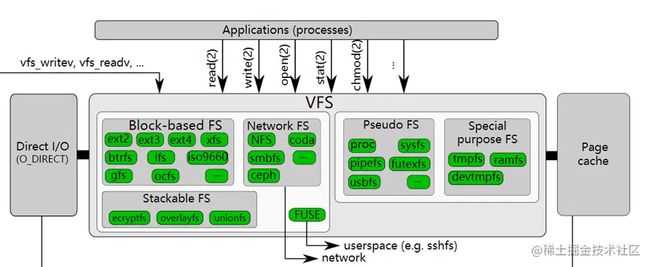
[root@hecs-197747 proc]# cat -n filesystems
1 nodev sysfs
2 nodev rootfs
3 nodev ramfs
4 nodev bdev
5 nodev proc
6 nodev cgroup
7 nodev cpuset
8 nodev tmpfs
9 nodev devtmpfs
10 nodev debugfs
11 nodev securityfs
12 nodev sockfs
13 nodev dax
14 nodev bpf
15 nodev pipefs
16 nodev configfs
17 nodev devptss
18 nodev hugetlbfs
19 nodev autofs
20 nodev pstore
21 nodev mqueue
22 ext3
23 ext2
24 ext4
25 nodev binfmt_misc
复制代码2.1.13 /proc/interrupts
/proc/interrupts记录了各种中断请求的次数。中断可以分为软中断和硬中断,硬中断又可以根据接CPU(如intel 8086)的引脚分为NMI(不可屏蔽硬件中断)和MI(可屏蔽硬件中断)。在早期,可屏蔽硬件中断的数量受限于PIC(Programmable Interrupt Controller,可编程中断控制器)的IR引脚数量,如intel的8259芯片,共有8个IR(InterruptRequest)引脚IR0-IR7,每个引脚都支持独立的置位,所以8个引脚能最多表示2^8=256种硬件中断。可屏蔽中断在CPU上以INTR引脚接入,可以通过清空标志位IF来屏蔽此类中断。
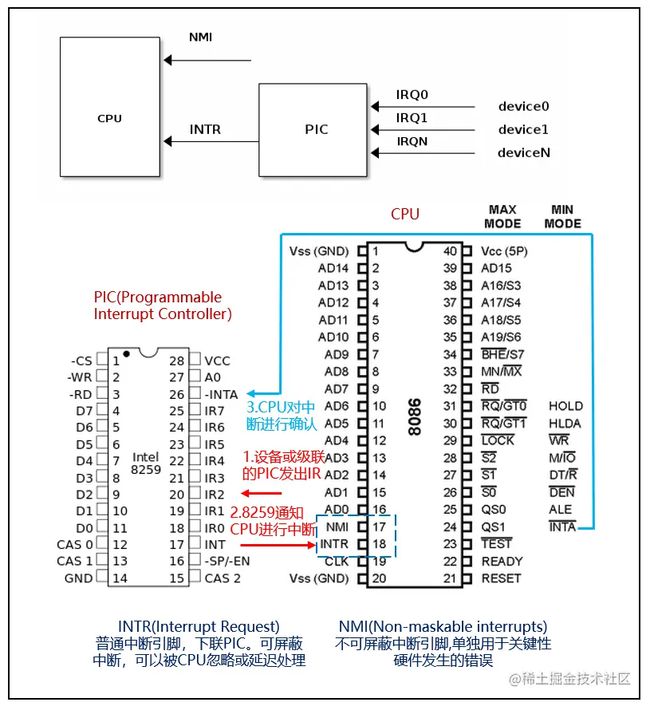
在早期设备不多的时候,中断控制器可以一个IR引脚接一个设备,这样就只能有8个设备发出硬件中断。但随着后面设备数量的增多,PIC的IR引脚直接接设备的情况变少了,一般会使用串联PIC的方式,最多可以将8个设备扩充为256个设备(主PIC上每个IR引脚下挂一个PIC)。中断的相关知识可以参考此链接。
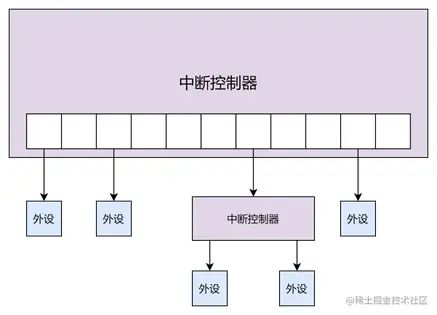
再往后,出现了更高级的中断控制器APIC(Local APIC和I/O APIC两部分构成),还有PIC总线上的MSI(消息信号中断)和MSI-X(支持2048种中断)这样的新中断方式,详细可参考此链接。另外,中断的触发也分为边缘触发和高低电平触发。两种触发方式可以参照此链接。
所有中断类型都会存储在中断/异常向量表中,这个表在内存中最低端1K字节空间中,共可存储256个中断/异常向量。向量(vector)其实就是一个表项,只是intel采取了这种叫法,不必深究其意思,需要关注的是中断/异常向量表除了存储中断,还存储了异常。异常(Exception)在intel文档中分为处理器检测到的异常(Processor-detected exceptions),故障(Faults),陷阱(Traps),中断(Aborts),程序异常(Programmed exceptions)五种,有兴趣的可以自行了解其区别。linux的中断/异常向量表按以下方式组织:
- 0-31为异常(Exception)和不可屏蔽中断(NMI,向量号固定为2)。
- 32-47为可屏蔽中断(MI),即从INTR引脚接入的中断。(IRQ为0的中断对应向量号32,1对应33号,以此类推)
- 48-255为其他中断比如软中断(Softirq)。
以下为linux系统中中断/异常向量表的0-19项(CPU指定,一般固定),供了解NMI和Exception的读者参考。也可以查看此链接查看linux源代码里定义的中断向量。
| 向量号 | 助记符 | 说明 | 类型 | 错误号 | 产生源 |
|---|---|---|---|---|---|
| 0 | #DE | 除出错 | 故障 | 无 | DIV或IDIV指令。 |
| 1 | #DB | 调试 | 故障/陷阱 | 无 | 任何代码或数据引用,或是INT 1指令。 |
| 2 | -- | NMI中断 | 中断 | 无 | 非屏蔽外部中断。 |
| 3 | #BP | 断点 | 陷阱 | 无 | INT 3指令。 |
| 4 | #OF | 溢出 | 陷阱 | 无 | INTO指令。 |
| 5 | #BR | 边界范围超出 | 故障 | 无 | BOUND指令。 |
| 6 | #UD | 无效操作码 | 故障 | 无 | UD2指令或保留的操作码。 |
| 7 | #NM | 设备不存在 | 故障 | 无 | 浮点或WAIT/FWAIT指令。 |
| 8 | #DF | 双重错误 | 异常终止 | 有(0) | 任何可产生异常、NMI或INTR的指令。 |
| 9 | -- | 协处理器段超越(保留) | 故障 | 无 | 浮点指令 |
| 10 | #TS | 无效的任务状态段TSS | 故障 | 有 | 任务交换或访问TSS |
| :- | :--- | :---------- | :--- | :--- | :------------------- |
| 11 | #NP | 段不存在 | 故障 | 有 | 加载段寄存器或访问系统段 |
| 12 | #SS | 堆栈段错误 | 故障 | 有 | 堆栈操作或SS寄存器加载 |
| 13 | #GP | 一般保护错误 | 故障 | 有 | 任何内存引用和其他保护检查 |
| 14 | #PF | 页面错误 | 故障 | 有 | 任何内存引用 |
| 15 | -- | (intel保留) | 无 | ||
| 16 | #MF | x87 FPU浮点错误 | 故障 | 无 | |
| 17 | #AC | 对齐检查 | 故障 | 有(0) | 对内存中任何数据的引用。 |
| 18 | #MC | 机器检查 | 异常终止 | 无 | 错误码(若有)和产生源与CPU类型有关。 |
| 19 | #XF | SIMD浮点异常 | 故障 | 无 |
[root@hecs-197747 proc]# cat -n interrupts
1 CPU0 CPU1
2 0: 80 0 IO-APIC-edge timer
3 1: 140 0 IO-APIC-edge i8042
4 4: 692 0 IO-APIC-edge serial
5 6: 3 0 IO-APIC-edge floppy
6 8: 0 0 IO-APIC-edge rtc0
7 9: 0 0 IO-APIC-fasteoi acpi
8 10: 1865817 0 IO-APIC-fasteoi virtio2
9 11: 29 0 IO-APIC-fasteoi uhci_hcd:usb1
10 12: 15 0 IO-APIC-edge i8042
11 14: 0 0 IO-APIC-edge ata_piix
12 15: 0 0 IO-APIC-edge ata_piix
13 24: 0 0 PCI-MSI-edge virtio3-config
14 25: 35465650 0 PCI-MSI-edge virtio3-req.0
15 26: 0 0 PCI-MSI-edge virtio1-config
16 27: 3 0 PCI-MSI-edge virtio1-virtqueues
17 28: 0 0 PCI-MSI-edge virtio0-config
18 29: 103 24027754 PCI-MSI-edge virtio0-input.0
19 30: 138 352 PCI-MSI-edge virtio0-output.0
20 NMI: 0 0 Non-maskable interrupts
21 LOC: 2130954077 2186717189 Local timer interrupts
22 SPU: 0 0 Spurious interrupts
23 PMI: 0 0 Performance monitoring interrupts
24 IWI: 111622499 120048621 IRQ work interrupts
25 RTR: 0 0 APIC ICR read retries
26 RES: 270338464 271150417 Rescheduling interrupts
27 CAL: 11761309 461 Function call interrupts
28 TLB: 2137131 2506979 TLB shootdowns
29 TRM: 0 0 Thermal event interrupts
30 THR: 0 0 Threshold APIC interrupts
31 DFR: 0 0 Deferred Error APIC interrupts
32 MCE: 0 0 Machine check exceptions
33 MCP: 62200 62200 Machine check polls
34 ERR: 0
35 MIS: 0
36 PIN: 0 0 Posted-interrupt notification event
37 NPI: 0 0 Nested posted-interrupt event
38 PIW: 0 0 Posted-interrupt wakeup event
#2-31行是可屏蔽硬件中断,列分别为 IRQ号 CPU0中断次数 CPU1中断次数 类别 名称
# IRQ号 + 32 = 中断/异常向量表里的向量号
#IO-APIC是APIC的一部分,用于多处理器情况下的中断控制,可以将中断分配到不同的CPU上。
#IO-APIC-edge和IO-APIC-fasteoi的触发方式不同,前者为边缘触发,后者为高低电平触发。
#PCI-MSI-edge为PCI总线上使用MSI边缘触发。
#timer为定时器,i8042为鼠标和键盘控制芯片,serial为串行设备,后面的设备请自行查阅
#20-38行是特定的中断,即不在中断向量表32-47范围(NI)的中断,比如NMI是中断向量表的2号,后面的英文就是对应的中断意思,具体为中断/异常向量表里的哪个向量号可以自行查阅,特别关注需要关注的是:RES
#RES:唤醒空闲的CPU来调度新的任务运行的中断。这是多处理器系统中,调度器用来分散任务到不同CPU的机制,也称为处理期间中断,此中断升高一般是因为过频繁、过多任务的调度问题。
复制代码2.1.14 /proc/iomem
/proc/iomem用于展示当前每段内存地址到物理设备的映射。这个文件与地址空间(address space)这一概念紧密相连。地址空间是一串的离散地址(或数字),可以来标识网络主机、外围设备、磁盘分区、内存单元、或其他逻辑/物理实体。比如IPv4地址的地址空间是0-2147483647(0.0.0.0-255.255.255.0),用来标识网络主机;32位的CPU的地址空间是0-4G(2^32),用来标识内存单元。
地址空间可以分为物理地址空间和虚拟地址空间。物理地址空间直接对应设备上的某个单元,会分配给各种外设使用,这样就可以通过地址访问或操作各种外设,如下所示/proc/iomem便是物理地址空间的分配情况;而知道了物理地址空间分配情况,我们能不能直接用物理地址空间的地址来直接编程?比如我写一段汇编代码,将0x01放入00001000(System RAM)?答案是否定的,物理地址空间的地址并不能被直接使用。因为在linux中建立了一个物理地址到虚拟地址的映射,00001000可能映射到了10111000(仅举例),我们操作的时候要使用后面的虚拟地址10111000,虚拟地址组成的空间便是虚拟地址空间。将物理地址映射到虚拟地址的机制就是大名鼎鼎的页表机制。
[root@hecs-197747 proc]# cat -n iomem
1 00000000-00000fff : reserved
2 00001000-0009fbff : System RAM
3 0009fc00-0009ffff : reserved
4 000a0000-000bffff : PCI Bus 0000:00
5 000c0000-000c95ff : Video ROM
6 000c9800-000ca5ff : Adapter ROM
7 000ca800-000ccbff : Adapter ROM
8 000f0000-000fffff : reserved
9 000f0000-000fffff : System ROM
10 00100000-bff7ffff : System RAM
... (此处省略后面的输出内容)
#列分别为 物理地址段 物理设备名称
复制代码2.1.15 /proc/ioports
/proc/ioports展示了io端口资源的分布情况。首先要明确一点,虽然此处的/proc/ioports输出的内容也是地址段,但和上面的/proc/iomem使用的不是同一个地址空间,下面是另外一套机制的实现。两者的关系类似于现实生活中的地址和邮政编码,通过地址能找到某个区/县,通过邮政编码也能找到某个区/县。所以在x86设备访问I/O外设时,也会有将IO外设映射到内存地址和使用inp、outp这样的IO指令两种方式,前者(称之为I/O Memory)通过00000000-00000fff这样的地址定位I/O设备,后者(称之为I/O ports)通过0000-001f这样的地址定位I/O设备,前者更通用更现代,后者并非所有都支持(比如ARM不支持)。/proc/iomem和/proc/ioports的关系可以参考此链接,Linux如何通过上述两种方式操作存储器可以参考此链接。
[root@hecs-197747 proc]# cat -n ioports
1 0000-0cf7 : PCI Bus 0000:00
2 0000-001f : dma1
3 0020-0021 : pic1
4 0040-0043 : timer0
5 0050-0053 : timer1
6 0060-0060 : keyboard
7 0064-0064 : keyboard
8 0070-0071 : rtc0
9 0080-008f : dma page reg
10 00a0-00a1 : pic2
11 00c0-00df : dma2
12 00f0-00ff : fpu
13 0170-0177 : 0000:00:01.1
14 0170-0177 : ata_piix
... (此处省略后面的输出内容)
#列分别为 物理地址段 物理接口名称
复制代码2.1.16 /proc/kallsyms
/proc/kallsyms展示了内核符号表。为了更好地调试内核,引入了kallsyms。kallsyms抽取了内核用到的所有函数地址(全局的、静态的)和非栈数据变量地址,生成一个数据块,作为只读数据链接进kernel image,相当于内核中存了一个System.map。因为使用编译型语言将代码编译成二进制文件的时候会丢掉变量名,全部用地址进行变量的访问,所以对于代码调试者,很难知道某个地址是什么变量,于是linux开发者编写了两段代码:/scripts/kallsyms.c负责生成System.map,./kernel/kallsyms.c负责生成/proc/kallsyms,前者在内核编译时进行,后者在内核启动后进行,最终形成这个内核符号表,作为一个可供调试时查询的地址和变量名的映射。
[root@hecs-197747 proc]# cat -n kallsyms | head -n 10
1 0000000000000000 A irq_stack_union
2 0000000000000000 A __per_cpu_start
3 0000000000004000 A init_tss
4 0000000000004000 A __per_cpu_user_mapped_start
5 0000000000007000 A exception_stacks
6 000000000000c000 A gdt_page
7 000000000000d000 A kaiser_scratch
8 000000000000d010 A spec_ctrl_pcp
9 000000000000d040 A kaiser_enabled_pcp
10 000000000000d080 A cpu_debug_store
#列分别为 地址(一般为虚拟地址) 静态全局变量名
复制代码2.1.17 /proc/kcore
/proc/kcore代表着本机的所有内存。kcore相当于内存的别名,变相代表着内存,可以当做内存文件执行内存读取,通过不同的命令查看该文件所显示的大小是不一致的。
[root@hecs-197747 proc]# cat kcore
ÂÒÂ룬ÇëÎð³¢ÊÔ
[root@hecs-197747 proc]# du -hs kcore
0 kcore
[root@hecs-197747 proc]# ls -lh kcore
-r-------- 1 root root 128T Jan 12 15:44 kcore
复制代码2.1.18 /proc/keys和/proc/key-users
/proc/keys展示了本地所有的密钥,/proc/key-users展示了本地所有密钥用户。密钥(key)是一组密码学数据、身份验证标记或某些相似的元素,它在内核中由 struct key 表示。密钥、/proc/keys、/proc/key-users的相关知识可以参考此链接。
[root@hecs-197747 proc]# cat -n keys
1 06896f2c I--Q--- 4 perm 3f030000 0 0 keyring _ses: 1
2 0c59d3c4 I--Q--- 1 perm 1f3f0000 0 65534 keyring _uid_ses.0: 1
3 0fcdff9a I------ 1 perm 1f030000 0 0 keyring .system_blacklist_keyring: empty
4 1cfe7180 I------ 1 perm 1f0f0000 0 0 keyring .ima: empty
5 200f778e I--Q--- 10 perm 3f030000 0 0 keyring _ses: 1
6 2436f78b I--Q--- 3 perm 3f030000 0 0 keyring _ses: 1
7 288d5a7e IR-Q--- 3 expd 3f030000 0 0 keyring _ses: empty
8 2b5c4918 I------ 1 perm 1f030000 0 0 asymmetri CentOS Linux kpatch signing key: ea0413152cde1d98ebdca3fe6f0230904c9ef717: X509.RSA 4c9ef717 []
9 30c9626c I------ 1 perm 1f030000 0 0 asymmetri CentOS Linux Driver update signing key: 7f421ee0ab69461574bb358861dbe77762a4201b: X509.RSA 62a4201b []
10 321f60b1 I------ 1 perm 1f030000 0 0 asymmetri CentOS Linux kernel signing key: 02fb1b20b039e3cdc759938ba958538481778031: X509.RSA 81778031 []
11 360895e6 IR-Q--- 13 expd 3f030000 0 0 keyring _ses: empty
12 388f2086 I------ 1 perm 1f0b0000 0 0 keyring .system_keyring: 3
13 39f28f69 I--Q--- 5 perm 1f3f0000 0 65534 keyring _uid.0: empt
[root@hecs-197747 proc]# cat -n key-users
1 0: 16 15/15 7/1000000 59/25000000
#cat keys的列分别为 32位ID(16进制) 标识 使用数量 超时时间 权限 UID GID 类型 描述
#标识共有IRDQUNi七位, I(nstantiated)是否被实例化 (R)evoked是否被调用 (D)ead是否死亡 (Q)uota是否影响用户的某个指标 (N)egatively是否被反实例化 (i)nvalidated是否失效
#使用数量标识有多少线程或打开的文件引用了这个key
#超时时间中的perm为永不超时,expd为已经超时
#权限为key的使用权限,参照0x01:view、0x02:read、0x04:write、0x08:search 、0x10:link、0x20:setattr
#UID和GID为用户ID和用户组ID
#类型为密钥类型。user和keyring为两种标准密钥类型:要添加新的密钥类型,必须由一个内核服务注册它。另外,用户空间程序不允许创建新的密钥类型。
#描述为创建key的时候输入的描述
#cat key-users的列分别为 UID 使用数量 nkeys/nikeys qnkeys/maxkeys qnbytes/maxbytes
#使用数量为内核内部使用数,具体数量如何统计待后续确认
#nkeys/nikeys为用户拥有的密钥总数以及其中已经实例化的密钥数
#qnkeys/maxkeys为用户拥有的密钥数和用户最大可拥有密钥数
#qnkeys/maxkeys为用户拥有的密钥消耗的字节数和用户最大可拥有密钥消耗的字节数
复制代码2.1.19 /proc/kmsg
/proc/kmsg用于暂存内核产生的信息。/proc/kmsg中的内容和dmsg输出的内容类似,但如果使用cat /proc/kmsg读取过一次后,再次读取就会发现之前读取到的不会再显示,显示的是新产生的内核信息;但如果是dmsg则会输出全部的内核信息。
[root@hecs-197747 proc]# cat kmsg
<6>[ 1.116596] acpiphp: Slot [30-9] registered
<6>[ 1.118250] acpiphp: Slot [31-9] registered
<6>[ 1.120204] pci 0000:00:0b.0: PCI bridge to [bus 08]
<7>[ 1.121960] pci 0000:00:0b.0: bridge window [io 0x1000-0x1fff]
<7>[ 1.121984] pci 0000:00:0b.0: bridge window [mem 0xfda00000-0xfdbfffff]
<7>[ 1.122027] pci 0000:00:0b.0: bridge window [mem 0xfc000000-0xfc1fffff 64bit pref]
<6>[ 1.138581] ACPI: PCI Interrupt Link [LNKA] (IRQs 5 *10 11)
... (此处省略后面的输出内容)
复制代码2.1.20 /proc/loadavg
/proc/loadavg为当前平均负载的记录。平均负载是指单位时间内,系统处于可运行状态(Runing)和不可运行状态(Disk sleep)的平均进程数,平均负载和CPU使用率和I/O都有关系。假如主机平均负载上升,可能由以下几种情况引起:1)CPU密集型进程正在运行 2)I/O密集型进程正在运行 3)大量进程同时运行(中断次数较多)。可以使用uptime命令来输出类似的信息。
[root@hecs-197747 proc]# cat -n loadavg
1 0.00 0.01 0.05 1/196 12565
#列分别为 1分钟内平均负载 5分钟内平均负载 15分钟内平均负载 活动实体数/总实体数 最近创建的进程
#实体应该是进程或线程,有待后续确认
复制代码2.1.21 /proc/locks
/proc/locks展示了当前被内核锁住的文件列表。为了解决不同程序同时访问同一个文件时的冲突问题,出现了文件锁机制(关于各种锁的原理介绍后面会有专题)。文件锁针对的对象是文件,主要分为两种类型ADVISORY和MANDATORY:ADVISORY为建议使用,为POSIX标准提供;MANDATORY为强制使用,由System V Release 3引入使用。首先,要明确这里的文件指的是什么,一个东西如果看起来像文件,用起来像文件(可以读、写、执行、复制、删除、移动),那它就可以称为文件(编程中的鸭子类型也是同样的思想)。ADVISORY和MANDATORY两种文件锁,前一种锁全靠自觉,如果一个进程没有检查文件有没有锁,也可以直接访问文件,属于"欲练此功须先自宫,若不自宫也可成功"的类型;后一种会在read(),write()等系统调用里检测进程/线程有没有拿到锁,如果没有拿到锁则不允许执行操作,强制必须先获取锁再操作。ADVISORY和MANDATORY可以通过mount调用来修改,此处不再赘述。另,文件锁会涉及到fcntl(可以锁某个文件的任意块),flock(只能锁一整个文件),lockf(类似fcntl)等系统调用(system call),可以自行了解。
[root@hecs-197747 proc]# cat -n locks
1 1: POSIX ADVISORY WRITE 19093 fd:01:1706453 0 EOF
2 2: POSIX ADVISORY WRITE 19093 fd:01:1706451 0 EOF
3 3: POSIX ADVISORY WRITE 19093 fd:01:1706441 0 EOF
4 4: POSIX ADVISORY WRITE 19093 fd:01:1706322 0 EOF
5 5: POSIX ADVISORY WRITE 19093 fd:01:1849614 0 EOF
... (此处省略后面的输出内容)
#列分别为 序号: 锁类型 建议/强制 读/写 PID 主设备id:次设备id:inode号 开始 结束
#锁类型一般为POSIX(fcntl调用),FLOCK(flock调用),OFDLOCK(fcntl调用)
#PID是进程ID
#开始是这个锁定的开始位置(通过开始和结束两个数字,可以锁定文件中的任意块)
#结束是这个锁定的结束位置,EOF代表文件末尾
#原版释意参考此链接:https://man7.org/linux/man-pages/man5/proc.5.html
复制代码2.1.22 /proc/mdstat
/proc/mdstat显示了一个内核RAID/md状态的快照。RAID(Redundant Array of Independent/Inexpensive Disks)的基本思想是将多个容量较小、相对廉价的磁盘进行有机组合,从而以较低的成本获得与昂贵大容量磁盘相当的容量、性能和可靠性。关于RAID,已有大量文章介绍,此处不再赘述。不同raid等级的介绍可以参考此链接,mstat的表项可以参照此链接。

[root@hecs-197747 proc]# cat -n mdstat
1 Personalities :
2 unused devices:
[root@fromInternet proc]#cat -n /proc/mdstat
1 Personalities : [linear] [raid0] [raid1] [raid5]
2 read_ahead 1024 sectors
3 md2 : active raid1 sde1[1] sdd1[0]
4 17920384 blocks [2/2] [UU]
5
6 md1 : active raid0 sdc1[1] sdb1[0]
7 35840768 blocks 64k chunks
#由于笔者的虚机内核不支持raid,显示结果为空,所以引入了一个互联网上的例子
#Personalities为内核当前支持的RAID级别,可以包括[raid0] [raid1] [raid4] [raid5] [raid6] [linear] [multipath] [faulty]
#第2行表示在顺序读取期间,内核将尝试缓存最多1024个扇区的数据,大约512 K(1024个扇区,每个扇区大约512字节)
#第3行的md2代表/dev/md2, active raid1代表用的是raid1,/dev/sde1是device 1,/dev/sdd1是device 0,第6行同。
#第4行17920384(可用大小) blocks [2/2](2应有/2当前使用) [UU](U为up,_为down)
#第7行35840768(可用大小) blocks 64k chunks(raid块大小为64k)
复制代码 2.1.23 /proc/meminfo
/proc/meminfo展示了大量关于系统RAM使用情况的信息。因为不同Linux内核版本或者发行版采取的参数不一样,所以此文件最终的展示结果可能不相同,下面解释的地方综合了已有的字段,并参考了以下链接:链接1,链接2。
[root@hecs-197747 proc]# cat -n meminfo
1 MemTotal: 3879808 kB
2 MemFree: 155656 kB
3 MemAvailable: 1945488 kB
4 Buffers: 372712 kB
5 Cached: 1703348 kB
6 SwapCached: 0 kB
7 Active: 2334856 kB
8 Inactive: 1027692 kB
9 Active(anon): 1390140 kB
10 Inactive(anon): 85424 kB
11 Active(file): 944716 kB
12 Inactive(file): 942268 kB
13 Unevictable: 0 kB
14 Mlocked: 0 kB
15 SwapTotal: 0 kB
... (此处省略后面的输出内容)
#MemTotal 所有可用RAM大小(即物理内存减去一些预留位和内核的二进制代码大小)(HighTotal+LowTotal),系统从加电开始到引导完成,BIOS等要保留一些内存,内核要保留一些内存,最后剩下可供系统支配的内存就是MemTotal。这个值在系统运行期间一般是固定不变的。
#MemFree LowFree与HighFree的总和,被系统留着未使用的内存,MemFree是说的系统层面
#MemAvailable 应用程序可用内存数。系统中有些内存虽然已被使用但是可以回收的,比如cache/buffer、slab都有一部分可以回收,所以MemFree不能代表全部可用的内存,这部分可回收的内存加上MemFree才是系统可用的内存,即#MemAvailable≈MemFree+Buffers+Cached,它是内核使用特定的算法计算出来的,是一个估计,MemAvailable是说的应用程序层面
#Buffers 用来给文件做缓冲大小
#Cached 被高速缓冲存储器(cache memory)用的内存的大小(等于 diskcache minus SwapCache )
#SwapCached 被高速缓冲存储器(cache memory)用的交换空间的大小,已经被交换出来的内存,但仍然被存放在swapfile中。用来在需要的时候很快的被替换而不需要再次打开I/O端口
#Active 在活跃使用中的缓冲或高速缓冲存储器页面文件的大小,除非非常必要否则不会被移作他用. (Active(anon) + Active(file))
#Inactive 在不经常使用中的缓冲或高速缓冲存储器页面文件的大小,可能被用于其他途径. (Inactive(anon) + Inactive(file))
#Active(anon) 活跃的与文件无关的内存(比如进程的堆栈,用malloc申请的内存)(anonymous pages),anonymous pages在发生换页时,是对交换区进行读/写操作
#Inactive(anon) 非活跃的与文件无关的内存(比如进程的堆栈,用malloc申请的内存)
#Active(file) 活跃的与文件关联的内存(比如程序文件、数据文件所对应的内存页)(file-backed pages) File-backed pages在发生换页(page-in或page-out)时,是从它对应的文件读入或写出
#Inactive(file) 非活跃的与文件关联的内存(比如程序文件、数据文件所对应的内存页)
#Unevictable 由分页代码发现的内存量(以kibitbytes为单位),它是不可收回的,因为它被用户程序锁定在内存中
#Mlocked 以kibitbytes为单位的内存总量,它是不可收回的,因为它被用户程序锁定在内存中
#HighTotal 高位内存总大小(Highmem是指所有内存高于860MB的物理内存,Highmem区域供用户程序使用,或用于页面缓存。该区域不是直接映射到内核空间。内核必须使用不同的手法使用该段内存)
#HighFree 未被使用的高位内存大小
#LowTotal 低位内存总大小,低位可以达到高位内存一样的作用,而且它还能够被内核用来记录一些自己的数据结构
#LowFree 未被使用的低位大小
#SwapTotal 交换空间的总大小
#SwapFree 未被使用交换空间的大小
#Dirty 等待被写回到磁盘的内存大小
#Writeback 正在被写回到磁盘的内存大小
#AnonPages 未映射页的内存大小
#Mapped 设备和文件等映射的大小
#Shmem 共享内存(shmem)和tmpfs使用的内存总量(以kibibytes为单位)
#Slab 内核数据结构缓存的大小,可以减少申请和释放内存带来的消耗
#SReclaimable 可收回Slab的大小
#SUnreclaim 不可收回Slab的大小(SUnreclaim+SReclaimable=Slab)
#KernelStack 常驻内存,每一个用户线程都会分配一个kernel stack(内核栈)
#PageTables 管理内存分页页面的索引表的大小
#NFS_Unstable 不稳定页表的大小
#Bounce 用于块设备“Bounce Buffer”的内存量(以kibibytes为单位)
#WritebackTmp FUSE用于临时回写缓冲区的内存量(以kibibytes为单位)
#CommitLimit 根据超额分配比率('vm.overcommit_ratio'),这是当前在系统上分配可用的内存总量,这个限制只是在模式2('vm.overcommit_memory')时启用。CommitLimit用以下公式计算
#Committed_AS 目前在系统上分配的内存量。是所有进程申请的内存的总和,即时所有申请的内存没有被完全使用,例如一个进程申请了1G内存,仅仅使用了300M,但是这1G内存的申请已经被"committed"给了VM虚拟机,进程可以在任何时间使用。如果限制在模式2('vm.overcommit_memory')时启用,分配超出CommitLimit内存将不被允许
#VmallocTotal 可以vmalloc虚拟内存大小
#VmallocUsed vmalloc已使用的虚拟内存大小
#VmallocChunk 最大的连续未被使用的vmalloc区域
#Percpu 无
#HardwareCorrupted 带有物理内存损坏问题的内存数量(以千字节为单位),由硬件识别,并由内核保留,以便不被使用。
#AnonHugePages 没有文件支持并映射到用户空间页表的巨大页面所使用的内存总量(以kibibytes为单位)。
#CmaTotal 无
#CmaFree 无
#HugePages_Total 系统中HugePages的总数。这个数字是由Hugepagesize除以/proc/sys/vm/hugetlb_pool中指定的为hugepages预留的megabytes 得到的。这个统计数据只出现在x86、Itanium和AMD64架构上。
#HugePages_Free 系统可用的hugepages总数。这个统计数据只出现在x86、Itanium和AMD64架构上。
#HugePages_Rsvd 保留给hugetlbfs的未使用的hugepages的数量。
#HugePages_Surp 剩余hugeoages的数量。
#Hugepagesize 每个hugepages的大小,单位为kibitbytes。默认情况下,对于32位体系结构,该值在单处理器内核上是4096 KB。对于SMP、hugemem内核和AMD64,默认值是2048 KB。对于Itanium架构,默认值是262144 #KB。这个统计数据只出现在x86、Itanium和AMD64架构上
#DirectMap4k 使用4 kB页面映射映射到内核地址空间的内存量(以kibibytes为单位)。
#DirectMap2M 使用2 mB页面映射映射到内核地址空间的内存量(以kibibytes为单位)。
#DirectMap1G 使用1 gB页面映射映射到内核地址空间的内存量(以kibibytes为单位)。
复制代码2.1.24 /proc/misc
/proc/misc可用于查看系统中装载的所有misc设备的驱动程序。misc(miscellaneous devices),中文名一般叫做杂项设备/杂散设备。大部分的设备都有一个明确的分类class,有一些设备进行分类时不太好分,我们不知道一些设备到底应该分到哪一类设备中去,所以最后将这些不知道分到哪类中的设备分到misc设备中,也就是分到了杂散类中,像蜂鸣器还有ADC设备都被分到了misc设备杂散类设备中。misc设备是典型的字符设备,主设备号是10(主设备号和次设备号的列表参考此链接),在/sys/class有一个misc目录,这个misc就是杂散类设备。
#/sys/class/里的misc文件夹
[root@hecs-197747 proc]# ls /sys/class/
ata_device bdi devcoredump drm_dp_aux_dev hmm_device iommu misc pci_bus ppdev scsi_device tpm usbmon watchdog
ata_link block dma gpio hwmon leds msr pcmcia_socket pwm scsi_host tpmrm vc
ata_port bsg dmi graphics i2c-adapter mdio_bus nd powercap raw spi_master tty virtio-ports
backlight cpuid drm hidraw input mem net power_supply rtc thermal typec vtconsole
#使用ls -lt查看/dev目录可以看到主设备号和次设备号
[root@hecs-197747 proc]# ls -lt /dev/
total 0
crw-rw-rw- 1 root tty 5, 2 Jan 16 14:00 ptmx
crw-rw-rw- 1 root tty 5, 0 Dec 23 22:06 tty
crw--w---- 1 root tty 4, 1 Jun 5 2021 tty1
brw-rw---- 1 root disk 253, 1 Jun 5 2021 vda1
crw------- 1 root root 5, 1 Jun 5 2021 console
crw--w---- 1 root tty 4, 64 Jun 5 2021 ttyS0
[root@hecs-197747 proc]# cat -n misc
1 59 network_throughput
2 60 network_latency
3 61 cpu_dma_latency
4 227 mcelog
5 62 crash
6 183 hw_random
7 144 nvram
8 228 hpet
9 235 autofs
10 231 snapshot
11 63 vga_arbiter
#列分别为 次设备号 现在使用的驱动程序名
复制代码2.1.25 /proc/modules
/proc/modules为内核已经载入的模块的列表。Linux模块是一组代码,可以在系统启动后的任何时候动态地链接到内核中。当不再需要它们时,可以将它们从内核中解除链接并删除。大多数Linux内核模块都是设备驱动程序、伪设备驱动程序,比如网络驱动程序或文件系统。我们可以用命令列出内核中载入的模块(lsmod),往内核插入模块(insmod/modprobe),从内核中删除模块(rmmod/modprobe),查看某个模块的信息(modinfo)。
[root@hecs-197747 proc]# cat -n modules
1 binfmt_misc 17468 1 - Live 0xffffffffc04e8000
2 nfit 55639 0 - Live 0xffffffffc0526000
3 libnvdimm 159524 1 nfit, Live 0xffffffffc04ee000
4 iosf_mbi 15582 0 - Live 0xffffffffc04e3000
5 crc32_pclmul 13133 0 - Live 0xffffffffc04de000
... (此处省略后面的输出内容)
#列分别为 模块名(如binfmt_misc) 模块所占的内存大小(bytes,如17468) 此模块有多少个实例(如1) 此模块依赖的其他模块(如-,nfit) 模块的载入状态(live,loading,unloading) 当前内核内存的偏移量(理解为地址即可,直接或间接指明了一个地址)
[root@hecs-197747 sbin]# cd /sbin/ & lsmod
[1] 5541
Module Size Used by
iptable_filter 12810 0
binfmt_misc 17468 1
nfit 55639 0
libnvdimm 159524 1 nfit
iosf_mbi 15582 0
crc32_pclmul 13133 0
复制代码2.1.26 /proc/mtrr
/proc/mtrr展示了系统使用的当前内存类型范围寄存器MMTR(Memory Type Range Registers)的信息。MTTRs是一种确定某段物理内存类型的机制,简单来说就是用寄存器来存储物理地址段和类型,这样CPU在处理内存的时候,可以从MMTR中读出物理地址段对应的内存类型,然后执行对应的优化。一般情況下,內存都是应该被设置为有cache來帮助CPU操作內存的,这样的话整个系统的效率会比较高,但是某些设备使用的内存比较特殊,比如说Frame buffer为uncacheable,那么(一般情況下是BIOS)就需要配置CPU的相关寄存器(MTRR)来申明哪些范围的内存需要进行何种优化(没有被申明的则为默认内存类型)。MTRR与Intel P6系列处理器(Pentium II及更高版本)一起使用,并控制处理器对内存范围的访问。当在PCI或AGP总线上使用显卡时,正确配置的/proc/mtrr文件可以提高超过150%的性能。目前,MTRRs是一种逐渐在过时的机制,正在被PAT(page attribute tables)慢慢取代。MTTR的类型可以参考下表,MTTR的相关知识可以参考此链接。
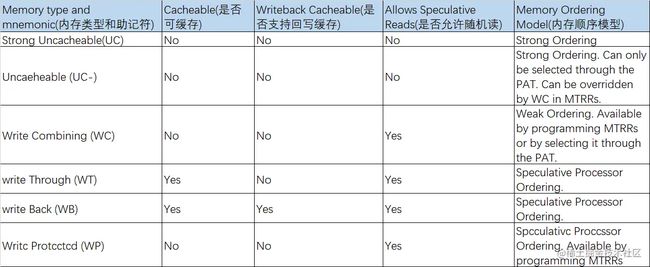
[root@hecs-197747 proc]# cat -n mtrr
1 reg00: base=0x0c0000000 ( 3072MB), size= 1024MB, count=1: uncachable
# reg00(寄存器名): base=0x0c0000000(基址) ( 3072MB 基址人工可读形式), size= 1024MB(大小), count=1(数量): uncachable(内存类型)
# 上面代表 0x0c0000000~(0x0c0000000+1024M)这块内存的类型是uncacheable
复制代码2.1.27 /proc/pagetypeinfo
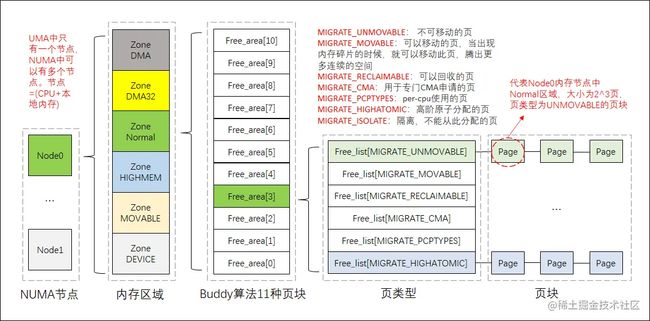
/proc/pagetypeinfo是内存中页的统计信息。和2.1.1的buddyinfo的内容类似,但比/proc/buddyinfo中的内容更详细。在buddyinfo的基础上,pagetypeinfo增加了一个新的分类也就是页的类型,NUMA节点、内存区域、buddy算法、页类型、页块的关系如下图。本节的内容参考了此链接。
[root@hecs-197747 proc]# cat -n pagetypeinfo
1 Page block order: 9
2 Pages per block: 512
3
4 Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10
5 Node 0, zone DMA, type Unmovable 3 1 0 1 0 1 1 0 1 0 0
6 Node 0, zone DMA, type Reclaimable 0 1 1 1 1 1 1 1 1 1 0
7 Node 0, zone DMA, type Movable 0 2 0 2 1 0 0 1 1 0 2
8 Node 0, zone DMA, type Reserve 0 0 0 0 0 0 0 0 0 0 0
9 Node 0, zone DMA, type CMA 0 0 0 0 0 0 0 0 0 0 0
10 Node 0, zone DMA, type Isolate 0 0 0 0 0 0 0 0 0 0 0
11 Node 0, zone DMA32, type Unmovable 69 442 271 120 23 6 5 3 2 1 0
12 Node 0, zone DMA32, type Reclaimable 735 75 220 89 12 0 0 0 0 0 0
13 Node 0, zone DMA32, type Movable 11545 488 134 202 367 23 1 1 0 0 0
14 Node 0, zone DMA32, type Reserve 0 0 0 0 0 0 0 0 0 0 0
15 Node 0, zone DMA32, type CMA 0 0 0 0 0 0 0 0 0 0 0
16 Node 0, zone DMA32, type Isolate 0 0 0 0 0 0 0 0 0 0 0
17 Node 0, zone Normal, type Unmovable 75 109 158 42 6 0 0 0 0 0 0
18 Node 0, zone Normal, type Reclaimable 292 220 245 70 8 0 0 0 0 0 0
19 Node 0, zone Normal, type Movable 103 340 27 53 23 0 0 0 0 0 0
20 Node 0, zone Normal, type Reserve 0 0 0 0 0 0 0 0 0 0 0
21 Node 0, zone Normal, type CMA 0 0 0 0 0 0 0 0 0 0 0
22 Node 0, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0
23
24 Number of blocks type Unmovable Reclaimable Movable Reserve CMA Isolate
25 Node 0, zone DMA 1 2 5 0 0 0
26 Node 0, zone DMA32 29 70 1429 0 0 0
27 Node 0, zone Normal 71 19 422 0 0 0
复制代码2.1.28 /proc/partitions
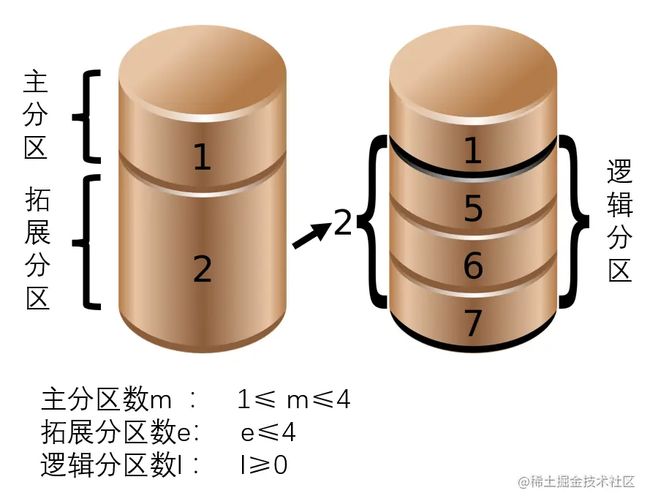
/proc/partitions展示了硬盘分区信息。硬盘分区有三种,主磁盘分区、扩展磁盘分区、逻辑分区。在硬盘中,主磁盘分区的数量mmm满足1≤m≤41≤m≤41≤m≤4,扩展磁盘分区的数量eee满足0≤e≤40≤e≤40≤e≤4,逻辑磁盘分区的数量lll满足l≥0l≥0l≥0;不管m和e取什么值,必须满足m+e≤4m+e≤4m+e≤4。如下图所示。
而为什么主分区大于1个但不超过4个?为什么拓展分区不超过4个?逻辑分区为什么可以一直往下分?这主要跟MBR和EBR上的记录有关。为了将硬盘分区相关的知识串联起来,笔者绘制了下图。
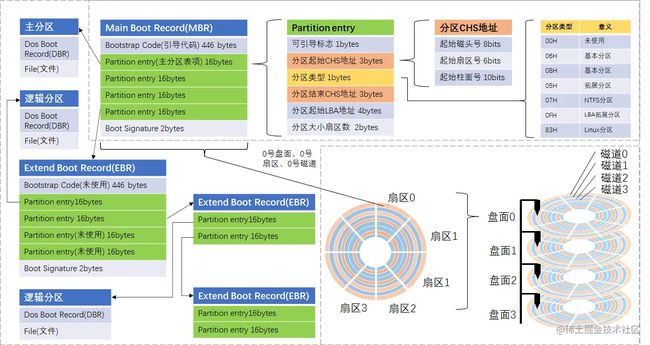
首先,要了解磁盘的构造。如上图所示,一块磁盘会有一个多个盘面,每个盘面上都可以划分出多个扇区和磁道。可以将磁盘的某个盘面想象成一块披萨,一般的披萨都会按着图中的白线切好,每一块切好的披萨就是一个扇区;而整个披萨的最外沿的一圈就是一个磁道,里面一圈是另外一个磁道,再里面又是一个磁道。磁盘就是一堆披萨(盘面)堆在一起。假如我想拿最上层盘面的某个数据,就可以通过盘面(磁头)+扇区+磁道(柱面)的三元组去访问到对应的簇,拿到相应的数据。磁盘的构造可以参考此链接。
然后,要了解MBR的构造。在磁盘的最开始处(开机的时候也是从这开始读),也就是0号盘面+0号扇区+0号磁道处,存放了MBR(主引导记录)。这个记录包含446字节的引导代码、64字节的DPT(Disk Partition Table,磁盘分区表)、2字节的BootSignature(值为55AA)。64字节的DPT中可以存放4条Partition entry,也就是4条分区记录,这4条分区记录可以指向4个分区(主分区/拓展分区),这意味着一个磁盘最多支持4个主磁盘分区或拓展分区,这4个主磁盘分区的位置也是通过磁头号+扇区号+柱面号去确定的。那么拓展磁盘分区和逻辑磁盘分区又是从何而来呢?答案是EBR,拓展引导记录。
最后,要了解EBR实际上是嵌套使用的MBR,或者说是一个链表。EBR的结构与MBR的结构基本一致,MBR可以将Partition entry的某一项指向一个EBR,从而获得更多分区(是不是有点像2.1.13中的PIC的级联?)。一个EBR会带来一个逻辑分区,这个分区由EBR的第一个Partition entry指定。EBR也可以指向另外的EBR,如果需要增加新的逻辑分区,可以增加额外的EBR,然后将当前EBR的第二个Partition entry指向额外的EBR,如此可以像一根链条一样地接下去,直到够用为止,逻辑分区也可以这样一直分下去。
磁盘相关的知识补充还可以查看此链接。
[root@hecs-197747 proc]# cat -n partitions
1 major minor #blocks name
2
3 253 0 41943040 vda
4 253 1 41942016 vda1
#列分别为 主设备号 次设备号 块大小 分区/设备名称
复制代码2.1.29 /proc/sched_debug
/proc/sched_debug为调度器的debug信息。一般我们所说的资源为内存和物理设备,但是CPU也可以认为是一个资源,调度器可以临时分配一个任务在上面执行(单位是时间片)。调度器使得我们同时执行多个程序成为可能,因此可以与具有各种需求的用户共享CPU。调度器可以有效地分配 CPU 时间片,同时提供更好的用户体验。调度器还需要面对一些互相冲突的目标,例如既要为关键实时任务最小化响应时间, 又要最大限度地提高 CPU 的总体利用率。调度器在实现的时候,一般都是使用各种优先级对进程或进程组进行调度。调度器相关的知识可以参考此链接。
[root@hecs-197747 proc]# cat -n /proc/sched_debug
1 Sched Debug Version: v0.11, 3.10.0-1160.15.2.el7.x86_64 #1
2 ktime : 19609904259.099201
3 sched_clk : 19609660653.970728
4 cpu_clk : 19609660653.970759
5 jiffies : 23904571555
6 sched_clock_stable() : 1
7
8 sysctl_sched
9 .sysctl_sched_latency : 12.000000
10 .sysctl_sched_min_granularity : 10.000000
11 .sysctl_sched_wakeup_granularity : 15.000000
12 .sysctl_sched_child_runs_first : 0
13 .sysctl_sched_features : 40571
14 .sysctl_sched_tunable_scaling : 1 (logaritmic)
15
16 cpu#0, 2200.000 MHz
17 .nr_running : 1
18 .load : 1024
19 .nr_switches : 3029800355
20 .nr_load_updates : 2271756583
21 .nr_uninterruptible : -1417619
22 .next_balance : 23904.571683
23 .curr->pid : 30561
24 .clock : 19609660653.883224
25 .cpu_load[0] : 1024
26 .cpu_load[1] : 512
27 .cpu_load[2] : 256
28 .cpu_load[3] : 128
29 .cpu_load[4] : 64
30 .avg_idle : 1000000
31 .max_idle_balance_cost : 500000
32
33 cfs_rq[0]:/
34 .exec_clock : 0.000000
35 .MIN_vruntime : 0.000001
36 .min_vruntime : 598862112.813510
37 .max_vruntime : 0.000001
38 .spread : 0.000000
39 .spread0 : 0.000000
40 .nr_spread_over : 0
41 .nr_running : 1
42 .load : 1024
43 .runnable_load_avg : 1023
44 .blocked_load_avg : 0
45 .tg_load_avg : 0
46 .tg_load_contrib : 0
47 .tg_runnable_contrib : 0
48 .tg->runnable_avg : 0
49 .tg->cfs_bandwidth.timer_active: 0
50 .throttled : 0
51 .throttle_count : 0
52 .avg->runnable_avg_sum : 952
53 .avg->runnable_avg_period : 47558
54
55 rt_rq[0]:/
56 .rt_nr_running : 0
57 .rt_throttled : 0
58 .rt_time : 0.015837
59 .rt_runtime : 950.000000
60
61 runnable tasks:
... (此处省略后面的输出内容)
#此处的具体释意待后续补全
复制代码2.1.30 /proc/schedstat
/proc/schedstat为调度器的统计信息。
[root@hecs-197747 proc]# cat -n schedstat
1 version 15
2 timestamp 22961784572
3 cpu0 0 0 0 0 0 0 627835987486085 24017715134212 1512011609
4 domain0 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
5 cpu1 0 0 0 0 0 0 649571543748105 21557684480339 1519989078
6 domain0 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
#第3/5行:列1为sched_yield()被调用次数 列2为O(1)调度器中使用的遗留数组过期计数字段 列3为schedule()被调用次数 列4为schedule()让控制器闲置次数
# 列5为try_to_wake_up()被调用次数 列6为try_to_wake_up()唤醒cpu次数
# 列7为在这个处理器上运行任务所花费的所有时间的总和 列8为等待该处理器上的任务运行所花费的所有时间的总和 列9为在这个CPU上运行时间片数
#第4/6行: 一共有36个值,跟load_balance(),pull_task()在不同情况下的调用以及对应的状态有关。此处列出https://www.kernel.org/doc/html/latest/scheduler/sched-stats.html上的原文(太多了偷个懒笔者不想翻译了)
# 1 of times in this domain load_balance() was called when the cpu was idle
# 2 of times in this domain load_balance() checked but found the load did not require balancing when the cpu was idle
# 3 of times in this domain load_balance() tried to move one or more tasks and failed, when the cpu was idle
# 4 sum of imbalances discovered (if any) with each call to load_balance() in this domain when the cpu was idle
# 5 of times in this domain pull_task() was called when the cpu was idle
# 6 of times in this domain pull_task() was called even though the target task was cache-hot when idle
# 7 of times in this domain load_balance() was called but did not find a busier queue while the cpu was idle
# 8 of times in this domain a busier queue was found while the cpu was idle but no busier group was found
# 9 of times in this domain load_balance() was called when the cpu was busy
# 10 of times in this domain load_balance() checked but found the load did not require balancing when busy
# 11 of times in this domain load_balance() tried to move one or more tasks and failed, when the cpu was busy
# 12 sum of imbalances discovered (if any) with each call to load_balance() in this domain when the cpu was busy
# 13 of times in this domain pull_task() was called when busy
# 14 of times in this domain pull_task() was called even though the target task was cache-hot when busy
# 15 of times in this domain load_balance() was called but did not find a busier queue while the cpu was busy
# 16 of times in this domain a busier queue was found while the cpu was busy but no busier group was found
# 17 of times in this domain load_balance() was called when the cpu was just becoming idle
# 18 of times in this domain load_balance() checked but found the load did not require balancing when the cpu was just becoming idle
# 19 of times in this domain load_balance() tried to move one or more tasks and failed, when the cpu was just becoming idle
# 20 sum of imbalances discovered (if any) with each call to load_balance() in this domain when the cpu was just becoming idle
# 21 of times in this domain pull_task() was called when newly idle
# 22 of times in this domain pull_task() was called even though the target task was cache-hot when just becoming idle
# 23 of times in this domain load_balance() was called but did not find a busier queue while the cpu was just becoming idle
# 24 of times in this domain a busier queue was found while the cpu was just becoming idle but no busier group was found
# 25 of times active_load_balance() was called
# 26 of times active_load_balance() tried to move a task and failed
# 27 of times active_load_balance() successfully moved a task
# 28 sbe_cnt is not used
# 29 sbe_balanced is not used
# 30 sbe_pushed is not used
# 31 sbf_cnt is not used
# 32 sbf_balanced is not used
# 33 sbf_pushed is not used
# 34 of times in this domain try_to_wake_up() awoke a task that last ran on a different cpu in this domain
# 35 of times in this domain try_to_wake_up() moved a task to the waking cpu because it was cache-cold on its own cpu anyway
# 36 of times in this domain try_to_wake_up() started passive balancing
复制代码2.1.31 /proc/slabinfo
/proc/slabinfo为slab分配器的分配信息。在linux中,分配大块连续内存,使用的是buddy算法。而对于小内存区的申请,比如说几十或几百个字节,使用的便是slab机制,slab机制会从buddy算法取出的连续页的基础上进行二次分配。除了分配小内存区之外,slab分配器另一个主要功能是作为一个高速缓存,它用来存储内核中那些经常分配并释放的对象。slab的相关知识可以参考此链接。
[root@hecs-197747 proc]# cat -n slabinfo
1 slabinfo - version: 2.1
2 # name : tunables : slabdata
3 ext4_groupinfo_4k 330 330 136 30 1 : tunables 0 0 0 : slabdata 11 11 0
4 ext4_inode_cache 110375 116896 1024 16 4 : tunables 0 0 0 : slabdata 7306 7306 0
5 ext4_xattr 92 92 88 46 1 : tunables 0 0 0 : slabdata 2 2 0
6 ext4_free_data 1280 1280 64 64 1 : tunables 0 0 0 : slabdata 20 20 0
7 ext4_allocation_context 64 64 128 32 1 : tunables 0 0 0 : slabdata 2 2 0
8 ext4_io_end 672 672 72 56 1 : tunables 0 0 0 : slabdata 12 12 0
9 ext4_extent_status 33808 82212 40 102 1 : tunables 0 0 0 : slabdata 806 806 0
10 jbd2_journal_handle 170 170 48 85 1 : tunables 0 0 0 : slabdata 2 2 0
... (此处省略后面的输出内容)
复制代码 2.1.32 /proc/softirqs
/proc/softirqs记录了软中断的统计信息。软中断的理解,有一个例子我认为是最通用的最好的,这里引用一下。
首先是只使用硬件中断的情况。“假如订了2份外卖,一份主食和一份饮料,并且是由2个不同的配送员来配送,两份外卖都约定了电话取外卖(硬件中断)的方式。第一份外卖送到时,配送员给打了个长长的电话(硬件中断处理程序过长),商量发票的处理方式;与此同时,第二个配送员也到了,也想给你打电话,但是很明显,因为电话占线(后面的硬件中断请求被屏蔽),第二个配送员的电话是打不通的。所以,第二个配送员很可能试几次后就走掉了(也就是丢失了一次中断)”。
然后是使用硬中断和软中断的情况。“同样是2份不同的外卖,由2个不同的配送员来配送。第一份外卖送到时,配送员给打了个短电话(硬件中断),说发票的处理方式贴在外卖上(硬件中断处理程序),可以自己去看(自己去看这个过程属于软件中断);这样第二个配送员也到了,也能打通电话(两次中断都处理了)”。
最后做个总结。linux 2.2为了解决中断处理程序执行过长和中断丢失的问题,将中断过程分成了两个阶段,分别是「上半部(top half)和下半部分(bottom half)」。上半部用来快速处理中断,一般会暂时屏蔽其他中断请求,主要负责处理跟硬件紧密相关或者时间敏感的事情。下半部用来延迟处理上半部未完成的工作,一般以「内核线程」的方式运行。而在linux 2.4中,又引入了software interrupt和tasklet概念,也就是我们说的软中断,来执行bottom half这部分的功能。软中断的理解可以参考此链接。
[root@hecs-197747 proc]# cat -n softirqs
1 CPU0 CPU1
2 HI: 1 0
3 TIMER: 1384403892 1367041089
4 NET_TX: 8 9
5 NET_RX: 171731774 206973780
6 BLOCK: 35276893 0
7 BLOCK_IOPOLL: 0 0
8 TASKLET: 137 1
9 SCHED: 485533022 435236477
10 HRTIMER: 0 0
11 RCU: 457914255 449578710
#笔者的云主机上包含10种软中断,软中断的类型应该随内核版本没什么变化(不确定最新版本是否有新的IRQ)。
#HI和TASKLET跟TASKLET机制有关,这个还有待笔者了解后补充
#NET_TX和 NET_RX分别是网络的发包和收包
#SCHED是调度产生的中断
#TIMER是定时器有关
#软中断的类型释意笔者找到的相关材料不多,此部分内容待后续补充修订。
复制代码2.1.33 /proc/stat
proc/stat节点记录的是系统进程整体的统计信息。
[root@hecs-197747 proc]# cat -n stat
1 cpu 110262748 1972 13442950 3602657079 1156045 0 410509 0 0 0
2 cpu0 53337012 821 7385425 1802384332 592606 0 204314 0 0 0
3 cpu1 56925735 1151 6057525 1800272746 563439 0 206195 0 0 0
4 intr 5170857898 80 140 0 0 692 0 3 0 0 0 1866559 29 15 0 0 0 0 0 0 0 0 0 0 0 0 35505029 0 3 0 24077952 491 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
5 ctxt 5791708091
6 btime 1622868118
7 processes 16988154
8 procs_running 1
9 procs_blocked 0
10 softirq 4993694193 1 2751446988 17 378705939 35276926 0 138 920770312 0 907493872
#第1行为总cpu运行统计 分别为 user,nice, system, idle, iowait, irq, softirq,steal,guest
# user 用户态时间
# nice 用户态时间(低优先级,nice>0)
# system 内核态时间
# idle 空闲时间
# iowait I/O等待时间
# irq 硬中断
# softirq 软中断
# steal 运行在虚拟环境的操作系统偷的时间
# guest 在内核控制下运行虚拟CPU或guest OS所花费的时间
#第2行为cpu 0的运行统计
#第3行为cpu 1的运行统计
#intr:系统启动以来的所有interrupts的次数情况
#ctxt: 系统上下文切换次数
#btime:启动时长(单位:秒),从Epoch(即1970零时)开始到系统启动所经过的时长,每次启动会改变。
#processes:系统启动后所创建过的进程数量。当短时间该值特别大,系统可能出现异常
#procs_running:处于Runnable状态的进程个数
#procs_blocked:处于等待I/O完成的进程个数
#softirq:系统启动以来的所有软中断请求次数情况
复制代码2.1.34 /proc/swaps
/proc/swaps存放了交换分区的信息。为了提高读写效率与速度,linux内核会将文件在内存中进行缓存,这部分内存就是cache(见本文2.1.7图)。即使你的程序运行结束后,cache也不会自动释放。这就会导致你在Linux系统中程序频繁读写文件后,你会发现可用物理内存变少。当系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前运行的程序使用。那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间被临时保存到Swap空间中,等到那些程序要运行时,再从Swap分区中恢复保存的数据到内存中。这样,系统总是在物理内存不够时,才进行Swap交换。
[root@hecs-197747 proc]# cat -n swaps
1 Filename Type Size Used Priority
ûÓÐswap
#笔者的云主机上并没有设置swap,所以无输出
复制代码2.1.35 /proc/timer_list
/proc/timer_list是linux内核定时器列表。
[root@hecs-197747 proc]# cat -n timer_list
1 Timer List Version: v0.8
2 HRTIMER_MAX_CLOCK_BASES: 4
3 now at 18667276322721266 nsecs
4
5 cpu: 0
6 clock 0:
7 .base: ffff8bc23fc159e0
8 .index: 0
9 .resolution: 1 nsecs
10 .get_time: ktime_get
11 .offset: 0 nsecs
12 active timers:
13 #0: , tick_sched_timer, S:01, tick_nohz_restart, swapper/0/0
14 # expires at 18667276323000000-18667276323000000 nsecs [in 278734 to 278734 nsecs]
... (此处省略后面的输出内容)
# 写到这儿字数超出1w9了,删掉了部分可能有意义的输出,可以自行去查看
# #10【定时器序号】: 【所在内核地址】, hrtimer_wakeup【定时器到期调用函数】, S:01【定时器状态,0不活跃的、1已入队列、2回调、4追加中、8迁移】, schedule_hrtimeout_range_clock【创建定时器的函数】, python3/30157【创建定时器的进程名/pid】
# # expires at 18667276764882951-18667276769872950 nsecs【绝对到期时间】 [in 442161685 to 447151684 nsecs]【相对到期时间】
复制代码 2.1.36 /proc/timer_stats
/proc/timer_stats可以查看请求Linux内核计时器的routine的信息。可参考此链接。
[root@hecs-197747 proc]# cat -n timer_stats
1 Timer Stats Version: v0.2
2 Sample period: 0.000 s
3 0 total events
复制代码2.1.37 /proc/uptime
/proc/uptime存放了系统的运行时间。
[root@hecs-197747 proc]# cat -n uptime
1 18667345.10 36083267.15
#列1 列2分别为系统启动到现在的时间,系统空闲的时间(以秒为单位)
#空闲时间比运行时间长,是因为计算空闲时间的时候会将多核都计算上(乘以core数)
复制代码2.1.38 /proc/version
/proc/version存放了当前的内核版本信息。当前kernal.org上的文档已经更新到了5.16.0,能找到最旧版本的文档已经是4.10版本,而笔者的云主机的内核版本仍然为3.10.0版本(如下),这是否代表笔者的云主机内核版本非常落后?笔者认为不是的,基于下面两个原因:一,生产版本不是最新的,但一定是最稳定的,企业环境稳定第一,稳定并不代表落后。二,实际上centos7相当于是从3.10.0这个内核版本fork出来的分支,在这个3.10.0的基础上做了大量自己的提交修改,虽然写的是3.10.0,但只代表它以3.10.0这个版本为基础进行开发,所以有时候会发现里面甚至会拥有一些5.x版本的特性。
[root@hecs-197747 proc]# cat -n version
1 Linux version 3.10.0-1160.15.2.el7.x86_64 ([email protected]) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC) ) #1 SMP Wed Feb 3 15:06:38 UTC 202
#3.10.0(内核版本号)-1160(提交代码次数).15.2.el7.x86_64
#gcc version 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC) (使用的编译器版本)
复制代码2.1.39 /proc/vmallocinfo
/proc/vmallocinfo提供了vmalloc()分配的内存以及vmap映射区域的相关信息。vmalloc()分配非连续的物理页,并将它们映射到连续的虚拟地址区域。这些vmalloc虚拟地址被限制在内核空间的vmalloc区域内。
[root@hecs-197747 proc]# cat -n vmallocinfo
1 0xffffab8fc0000000-0xffffab8fc0401000 4198400 alloc_large_system_hash+0x188/0x25c pages=1024 vmalloc vpages N0=1024
2 0xffffab8fc0401000-0xffffab8fc0404000 12288 alloc_large_system_hash+0x188/0x25c pages=2 vmalloc N0=2
3 0xffffab8fc0404000-0xffffab8fc0605000 2101248 alloc_large_system_hash+0x188/0x25c pages=512 vmalloc N0=512
4 0xffffab8fc0605000-0xffffab8fc0616000 69632 alloc_large_system_hash+0x188/0x25c pages=16 vmalloc N0=16
5 0xffffab8fc0616000-0xffffab8fc0627000 69632 alloc_large_system_hash+0x188/0x25c pages=16 vmalloc N0=16
... (此处省略后面的输出内容)
# 0xffffab8fc0616000-0xffffab8fc0627000【虚拟地址段】 69632【bytes】 alloc_large_system_hash+0x188/0x25c【caller信息】 pages=16(页数) vmalloc N0=16
复制代码2.1.40 /proc/vmstat
/proc/vmstat展示了从内核导出的虚拟内存的统计信息。
[root@hecs-197747 proc]# cat -n vmstat
1 nr_free_pages 38162
2 nr_alloc_batch 2420
3 nr_inactive_anon 21356
4 nr_active_anon 348290
5 nr_inactive_file 235572
6 nr_active_file 236223
7 nr_unevictable 0
8 nr_mlock 0
9 nr_anon_pages 182601
10 nr_mapped 13212
11 nr_file_pages 519064
12 nr_dirty 13
13 nr_writeback 0
14 nr_slab_reclaimable 48000
15 nr_slab_unreclaimable 6292
16 nr_page_table_pages 3174
17 nr_kernel_stack 196
18 nr_unstable 0
19 nr_bounce 0
20 nr_vmscan_write 7883
21 nr_vmscan_immediate_reclaim 659
22 nr_writeback_temp 0
23 nr_isolated_anon 0
24 nr_isolated_file 0
25 nr_shmem 47269
26 nr_dirtied 78913176
27 nr_written 79141427
28 numa_hit 326120260
29 numa_miss 0
30 numa_foreign 0
31 numa_interleave 13741
32 numa_local 326120260
33 numa_other 0
34 workingset_refault 3462631
35 workingset_activate 1148147
36 workingset_nodereclaim 0
37 nr_anon_transparent_hugepages 273
38 nr_free_cma 0
39 nr_dirty_threshold 138903
40 nr_dirty_background_threshold 46301
41 pgpgin 14893309
42 pgpgout 402831240
43 pswpin 0
44 pswpout 0
45 pgalloc_dma 2141
46 pgalloc_dma32 269319977
47 pgalloc_normal 114269160
48 pgalloc_movable 0
49 pgfree 383660922
50 pgactivate 4988217
51 pgdeactivate 5538104
52 pgfault 623124560
53 pgmajfault 11120
54 pglazyfreed 0
55 pgrefill_dma 236
56 pgrefill_dma32 4138224
57 pgrefill_normal 1531511
58 pgrefill_movable 0
59 pgsteal_kswapd_dma 162
60 pgsteal_kswapd_dma32 5380028
61 pgsteal_kswapd_normal 2041075
62 pgsteal_kswapd_movable 0
63 pgsteal_direct_dma 0
64 pgsteal_direct_dma32 524
65 pgsteal_direct_normal 10435
66 pgsteal_direct_movable 0
67 pgscan_kswapd_dma 164
68 pgscan_kswapd_dma32 5424385
69 pgscan_kswapd_normal 2090553
70 pgscan_kswapd_movable 0
71 pgscan_direct_dma 0
72 pgscan_direct_dma32 524
73 pgscan_direct_normal 10665
74 pgscan_direct_movable 0
75 pgscan_direct_throttle 0
76 zone_reclaim_failed 0
77 pginodesteal 3138
78 slabs_scanned 3480448
79 kswapd_inodesteal 618839
80 kswapd_low_wmark_hit_quickly 27
81 kswapd_high_wmark_hit_quickly 683
82 pageoutrun 1338
83 allocstall 10
84 pgrotated 219591
85 drop_pagecache 0
86 drop_slab 0
87 numa_pte_updates 0
88 numa_huge_pte_updates 0
89 numa_hint_faults 0
90 numa_hint_faults_local 0
91 numa_pages_migrated 0
92 pgmigrate_success 29621
93 pgmigrate_fail 23
94 compact_migrate_scanned 61213
95 compact_free_scanned 2350297
96 compact_isolated 61141
97 compact_stall 35
98 compact_fail 13
99 compact_success 22
100 htlb_buddy_alloc_success 0
101 htlb_buddy_alloc_fail 0
102 unevictable_pgs_culled 0
103 unevictable_pgs_scanned 0
104 unevictable_pgs_rescued 0
105 unevictable_pgs_mlocked 0
106 unevictable_pgs_munlocked 0
107 unevictable_pgs_cleared 0
108 unevictable_pgs_stranded 0
109 thp_fault_alloc 3191
110 thp_fault_fallback 78418
111 thp_collapse_alloc 976
112 thp_collapse_alloc_failed 368038
113 thp_split 340
114 thp_zero_page_alloc 25
115 thp_zero_page_alloc_failed 5
116 balloon_inflate 0
117 balloon_deflate 0
118 balloon_migrate 0
119 swap_ra 0
120 swap_ra_hit 0
#关于vmstat全部数据的文档比较少,以下内容截取自源码,部分项附上了笔者的注释,待后续逐渐补全。
#源码地址为:https://github.com/torvalds/linux/blob/master/mm/vmstat.c
const char * const vmstat_text[] = {
/* enum zone_stat_item counters */
"nr_free_pages", //空闲的页,(nr = pages = number of pages)
"nr_zone_inactive_anon", //非活动内存关联页
"nr_zone_active_anon", //活动内存关联页
"nr_zone_inactive_file", //非活动文件关联页
"nr_zone_active_file", //活动文件关联页
"nr_zone_unevictable", //不可回收页
"nr_zone_write_pending", //写追加页
"nr_mlock", //被用户程序锁定的页
"nr_bounce", //用于Bounce buffer的页
#if IS_ENABLED(CONFIG_ZSMALLOC)
"nr_zspages",
#endif
"nr_free_cma", //空闲cma的页
/* enum numa_stat_item counters */
#ifdef CONFIG_NUMA
"numa_hit", //numa命中
"numa_miss", //numa未命中
"numa_foreign", //numa远端访问
"numa_interleave",
"numa_local", //numa本地访问
"numa_other",
#endif
/* enum node_stat_item counters */
"nr_inactive_anon", //暂同上面的"nr_zone_inactive_anon",字面意思上,上面是针对zone,下面是针对node,但统计方式还有待考证
"nr_active_anon",
"nr_inactive_file",
"nr_active_file",
"nr_unevictable",
"nr_slab_reclaimable", //slab重申明
"nr_slab_unreclaimable", //slab未重申明
"nr_isolated_anon", //隔离内存页
"nr_isolated_file", //隔离内存文件关联的页
"workingset_nodes",
"workingset_refault_anon",
"workingset_refault_file",
"workingset_activate_anon",
"workingset_activate_file",
"workingset_restore_anon",
"workingset_restore_file",
"workingset_nodereclaim",
"nr_anon_pages",
"nr_mapped",
"nr_file_pages",
"nr_dirty",
"nr_writeback",
"nr_writeback_temp",
"nr_shmem",
"nr_shmem_hugepages",
"nr_shmem_pmdmapped",
"nr_file_hugepages",
"nr_file_pmdmapped",
"nr_anon_transparent_hugepages",
"nr_vmscan_write",
"nr_vmscan_immediate_reclaim",
"nr_dirtied",
"nr_written",
"nr_throttled_written",
"nr_kernel_misc_reclaimable",
"nr_foll_pin_acquired",
"nr_foll_pin_released",
"nr_kernel_stack",
#if IS_ENABLED(CONFIG_SHADOW_CALL_STACK)
"nr_shadow_call_stack",
#endif
"nr_page_table_pages",
#ifdef CONFIG_SWAP
"nr_swapcached",
#endif
/* enum writeback_stat_item counters */
"nr_dirty_threshold",
"nr_dirty_background_threshold",
#if defined(CONFIG_VM_EVENT_COUNTERS) || defined(CONFIG_MEMCG)
/* enum vm_event_item counters */
"pgpgin",
"pgpgout",
"pswpin",
"pswpout",
TEXTS_FOR_ZONES("pgalloc")
TEXTS_FOR_ZONES("allocstall")
TEXTS_FOR_ZONES("pgskip")
"pgfree", //空闲页
"pgactivate", //活动页
"pgdeactivate", //非活动页
"pglazyfree", //惰页,自己翻译的
"pgfault", //缺页
"pgmajfault", //主缺页
"pglazyfreed", //次缺页
"pgrefill",
"pgreuse",
"pgsteal_kswapd",
"pgsteal_direct",
"pgdemote_kswapd",
"pgdemote_direct",
"pgscan_kswapd",
"pgscan_direct",
"pgscan_direct_throttle",
"pgscan_anon",
"pgscan_file",
"pgsteal_anon",
"pgsteal_file",
#ifdef CONFIG_NUMA
"zone_reclaim_failed",
#endif
"pginodesteal",
"slabs_scanned",
"kswapd_inodesteal",
"kswapd_low_wmark_hit_quickly",
"kswapd_high_wmark_hit_quickly",
"pageoutrun",
"pgrotated",
"drop_pagecache",
"drop_slab",
"oom_kill",
#ifdef CONFIG_NUMA_BALANCING
"numa_pte_updates",
"numa_huge_pte_updates",
"numa_hint_faults",
"numa_hint_faults_local",
"numa_pages_migrated",
#endif
#ifdef CONFIG_MIGRATION
"pgmigrate_success",
"pgmigrate_fail",
"thp_migration_success",
"thp_migration_fail",
"thp_migration_split",
#endif
#ifdef CONFIG_COMPACTION
"compact_migrate_scanned",
"compact_free_scanned",
"compact_isolated",
"compact_stall",
"compact_fail",
"compact_success",
"compact_daemon_wake",
"compact_daemon_migrate_scanned",
"compact_daemon_free_scanned",
#endif
#ifdef CONFIG_HUGETLB_PAGE
"htlb_buddy_alloc_success",
"htlb_buddy_alloc_fail",
#endif
#ifdef CONFIG_CMA
"cma_alloc_success",
"cma_alloc_fail",
#endif
"unevictable_pgs_culled",
"unevictable_pgs_scanned",
"unevictable_pgs_rescued",
"unevictable_pgs_mlocked",
"unevictable_pgs_munlocked",
"unevictable_pgs_cleared",
"unevictable_pgs_stranded",
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
"thp_fault_alloc",
"thp_fault_fallback",
"thp_fault_fallback_charge",
"thp_collapse_alloc",
"thp_collapse_alloc_failed",
"thp_file_alloc",
"thp_file_fallback",
"thp_file_fallback_charge",
"thp_file_mapped",
"thp_split_page",
"thp_split_page_failed",
"thp_deferred_split_page",
"thp_split_pmd",
"thp_scan_exceed_none_pte",
"thp_scan_exceed_swap_pte",
"thp_scan_exceed_share_pte",
#ifdef CONFIG_HAVE_ARCH_TRANSPARENT_HUGEPAGE_PUD
"thp_split_pud",
#endif
"thp_zero_page_alloc",
"thp_zero_page_alloc_failed",
"thp_swpout",
"thp_swpout_fallback",
#endif
#ifdef CONFIG_MEMORY_BALLOON
"balloon_inflate",
"balloon_deflate",
#ifdef CONFIG_BALLOON_COMPACTION
"balloon_migrate",
#endif
#endif /* CONFIG_MEMORY_BALLOON */
#ifdef CONFIG_DEBUG_TLBFLUSH
"nr_tlb_remote_flush",
"nr_tlb_remote_flush_received",
"nr_tlb_local_flush_all",
"nr_tlb_local_flush_one",
#endif /* CONFIG_DEBUG_TLBFLUSH */
#ifdef CONFIG_DEBUG_VM_VMACACHE
"vmacache_find_calls",
"vmacache_find_hits",
#endif
#ifdef CONFIG_SWAP
"swap_ra",
"swap_ra_hit",
#endif
#ifdef CONFIG_X86
"direct_map_level2_splits",
"direct_map_level3_splits",
#endif
#endif /* CONFIG_VM_EVENT_COUNTERS || CONFIG_MEMCG */
};
复制代码2.1.41 /proc/zoneinfo
/proc/zoneinfo展示了各个内存区域的统计数据。统计数据和2.1.40中的项类似,待后续逐项补充意义,下面为各种内存区域的用途。
| 区域 | 用途 |
|---|---|
| ZONE_DMA | 这个区域为一些不能在所有内存地址初始化DMA的设备保留,大小和体系结构有关 , 一些ISA需要它 |
| ZONE_DMA32 | 这个区域仅存在与X86_64体系中,支持32位设备放到到小于4G的内存 |
| ZONE_NORMAL | 可以直接映射的区域, 如果DMA设备支持所有可寻址内存,则可以将所有可寻址内存视为正常区域, DMA操作可以在这些页面上启动 |
| ZONE_HIGHMEM | 对于32bit系统内核空间和用户空间比例是1:3模式下(3G用户空间,1G 内核空间), 该区域包含的页面只能由内核通过显式映射到其地址空间来访问,内核段以外的所有物理内存页都可以通过映射到该区域 |
| ZONE_MOVABLE | 从最高内存区域划出一片的内存, 处理内存碎片,X86-32bit大于ZONE_HIGH的区域, X86-64bit 大于ZONE_DMA32的区域,启动是根据内核有参数kernelcore用于设置不可移动的内存大小。 如果指定了“mirror”选项,则mirror内存用于非移动分配,其余内存用于移动页面。 |
| ZONE_DEVICE | 与SPARSEMEM这种新的物理内存模型有关, 这种模型支持内存热插拔这类内存通过devm_memremap_pages,映射到内存的这个区域 |
[root@hecs-197747 proc]# cat -n zoneinfo
1 Node 0, zone DMA
2 pages free 3855
3 min 69
4 low 86
5 high 103
6 scanned 0
7 spanned 4095
8 present 3998
9 managed 3977
10 nr_free_pages 3855
11 nr_alloc_batch 17
12 nr_inactive_anon 0
13 nr_active_anon 9
14 nr_inactive_file 38
15 nr_active_file 45
16 nr_unevictable 0
17 nr_mlock 0
18 nr_anon_pages 9
19 nr_mapped 20
20 nr_file_pages 83
21 nr_dirty 0
22 nr_writeback 0
23 nr_slab_reclaimable 2
24 nr_slab_unreclaimable 2
25 nr_page_table_pages 2
26 nr_kernel_stack 0
27 nr_unstable 0
28 nr_bounce 0
29 nr_vmscan_write 0
30 nr_vmscan_immediate_reclaim 0
31 nr_writeback_temp 0
32 nr_isolated_anon 0
33 nr_isolated_file 0
34 nr_shmem 0
35 nr_dirtied 305
36 nr_written 336
37 numa_hit 2111
38 numa_miss 0
39 numa_foreign 0
40 numa_interleave 0
41 numa_local 2111
42 numa_other 0
43 workingset_refault 123
44 workingset_activate 59
45 workingset_nodereclaim 0
46 nr_anon_transparent_hugepages 0
47 nr_free_cma 0
48 protection: (0, 2830, 3770, 3770)
49 pagesets
50 cpu: 0
51 count: 0
52 high: 0
53 batch: 1
54 vm stats threshold: 4
55 cpu: 1
56 count: 0
57 high: 0
58 batch: 1
59 vm stats threshold: 4
60 all_unreclaimable: 0
61 start_pfn: 1
62 inactive_ratio: 1
... (此处省略后面的输出内容)
复制代码3. 小结
linux的/proc目录下的文件,种类繁多,涉及面较广。如果要真正理解,需要各种操作系统方面的知识,甚至是要去阅读相应的内核源代码。本文列出了42个文件的内容以及对应的解释
作者:晴日飞鸢
链接:https://juejin.cn/post/7055321925463048228
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。