mysql--索引--回表
目录
1 索引
1.1 聚簇索引
1.2 联合索引(复合索引)
1.3 唯一索引
1.4 普通索引
1.5 全文索引
2 回表
1 索引
1.1 聚簇索引
聚簇索引:数据和索引一起的叫做聚簇索引
非聚簇索引(二级索引/辅助索引):数据和索引分开存储的叫做非聚簇索引
myisam中只有非聚簇索引,innodb中既支持聚簇索引也支持非聚簇索引
注意:innodb存储引擎中,数据在进行插入时,数据必须和某一个索引列绑定在一起,如果表中有主键,那么和主键绑定,如果没有主键,那么和唯一键绑定,如果没有唯一键,那么选择一个6字节的rowid进行绑定。
eg:id,name,age,gender四个列,其中id是主键,name是普通索引。此时数据和id绑定一起,name对应的B+树的叶子结点中存储的是id,此时name就叫做辅助索引或者二级索引。
1.2 联合索引(复合索引)
一般情况下我们在设置索引列的时候只会选择一个列作为索引字段,但是在某些特殊情况下,需要将多个列共同组成 一个索引字段,称之为联合索引。
创建联合索引sql:
ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
案例:
表:id,name,age,gender四个列,id为主键,name普通索引
1)回表:select * from table where name = "zhangsan"
当执行这个sql时,会发生回表:从某一个索引的叶子结点中获取聚簇索引的id值,根据id再去聚簇索引中获取全量记录
2)索引覆盖:select id,name from table where name = "zhangsan"
当执行这个sql时,会发生索引覆盖:从索引的叶子结点能获取到全量查询列的过程叫做索引覆盖
表:id,name,age,gender四个列,id为主键,name,age是组合索引
3)最左匹配:
当执行以下sql时,哪个会走组合索引呢?
select * from table where name = "zhangsan" and age = 12
select * from table where name = "zhangsan"
select * from table where age= 12
select * from table where age = 12 and name = "zhangsan"
答案是:第一个,第二个,第四个
第一个按照顺序来肯定是可以的;
第二个虽然只有一个name,但它依然会走索引;
第三个虽然和第二个一样条件只有一个字段,但是第一个索引不是age,不满足最左匹配原则,索引不会走
第四个虽然age和name反着的,但是mysql内部会有一个优化器,会将age和name调整顺序使其走组合索引
思考:当一个表结构为:id,name,age,gender四个列,id为主键,name,age,gender是组合索引时,执行以下sql时会走索引吗?
select * from table where age= 12
答案是会的,可是这样不符合上面说的最左匹配原则啊,其实细心的同学可以发现,这个表结构与上个表结构是有区别的,这个表结构里面所有的字段都有索引,而上个表结构里面gender并不是索引。索引此时总结出一句话:当表中的全部字段都是索引列的时候,无论进行什么样的查询都会用到索引。
4)索引下推:
select * from table where name = "张三" and age = 20(此时name和age是组合索引)
在没有索引下推之前,sql语句执行:
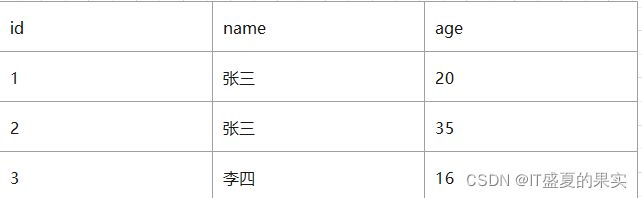
先根据name去查询(此时会忽略age字段),在name和age组合索引的B+树上找到了两个结果(id分别是1和2),然后去id的B+树上进行查找(此时回表查询了两次)
有索引下推之后,sql语句执行:并没有忽略age这个字段,在name和age组合索引的B+树上找到了1个结果(id是1)然后去id的B+树上进行查找(此时回表查询了一次)
1.3 唯一索引
唯一索引:在创建索引时,限制索引的值就是唯一的。通过该类型的索引会更高更快速的查询某条记录
创建唯一索引sql:ALTER TABLE `table_name` ADD UNIQUE (`column`)
1.4 普通索引
普通索引:在创建索引时,不附加任何限制条件(唯一。非空限制)。该类型的索引可以创建任何数据类型的字段上。
创建普通索引sql:
ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
1.5 全文索引
创建全文索引sql:
ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
1.6 覆盖索引
索引包含(也成覆盖)所有需要查询的字段的值,这种索引就叫做覆盖索引。(通过索引值可以直接找到查询字段的值,而不需要通过主键值回表查询,就叫做覆盖索引)
2 回表
上面提到了一个概念,那就是回表。这里详细的说一下回表的过程。
1 . 准备一张表(id为主键索引,adress为普通索引)

注意:有几个索引,就有几个B+树
2. 主键索引的B+树(省略了一些,简化的)

3 普通索引adress的B+树(省略了一些,简化的)
当我们执行如下sql:select * from table where id = 5时,会发生回表吗?
答案是:不会。因为id作为索引时,索引id的这个B+树已经包含了所有的数据,不需要再去查询什么其他的东西了。
当我们执行如下sql:select * from table where address = 安徽时,会发生回表吗?
答案是:会。因为address作为查询条件时。address的这个B+树里面只能查到address,id这两个字段,但我们需要查询的是所有字段,所以它还会根据拿到的id值再次去id的那颗B+树中再查一遍,将所有的值查询出来。增加了IO操作,所以发生回表时,是一个耗时的操作。
3 相关问题
1)mysql一个字段会走索引吗?
场景:一张表A,里面有id,name,gender等等字段,如果给gender建一个普通索引,那么执行(select * from A where gender= '男'),那么这个sql一定会走索引吗?
答案:不会,
因为如果表中有10000条数据,那么有9000条数据的gender都是‘男’,此时mysql就不会再去走索引。此时mysql如果走索引的话速度反而慢。mysql会自行判断是否需要走索引,这也就是为什么经常看到EXPLAIN中明明有索引,但并未使用。
注意:
1)如果一个主键被定义了,那么这个主键就是作为聚集索引(所有的行数据都会被绑定,独此一份)
2)如果没有主键被定义,那么该表的第一个唯一非空索引被作为聚集索引
3)如果没有主键也没有适合的唯一索引,那么innodb内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个6个字节的列,该列的值会随着数据的插入而自增
4)自增主键会将数据自动向后插入,避免了插入过程中的聚集索引排序问题,聚集索引的排序,必然会带来大范围的数据的物理移动,这里带来的磁盘IO性能损耗是非常严重的。而如果聚聚索引上的值可以改动的话,那么也会触发物理磁盘上的移动,于是就可能出现page分裂,表碎片橫生。所以不应该修改聚聚索引。
想要了解更多编程小知识,快来关注公众号:爪哇开发吧!每周会不定时的进行更新。