CortexM系列的Hardfault 问题跟踪方法
一、Cortex内部寄存器的作用:
程序状态寄存器xPSR
在arm7时代的程序状态寄存器是这样的。将整个寄存器划分为4个域,[31-24]是标志域,用于判断计算是否溢出进位为0等。[23-16]是状态域没有使用,[15-8]是扩展域没有使用,[7-0]是控制域用于控制中断的模式。
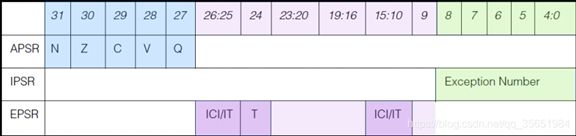
31 30 29 28 27 26-25 24 23 16 15-8 7 6 5 4-0
N Z C V Q unused J unused unused I F T MODE
cortex的程序状态寄存器xpsr,将整个寄存器分为三个子状态寄存器(部分位没有使用):
应用程序 PSR(APSR)—对应cpsr标志域[31-27],(由8位减到5位)
执行 PSR(EPSR)—对应cpsr没有使用的状态域和扩展域
中断号 PSR(IPSR)—对应cpsr的控制域[8-0](增加了1位)
31 30 29 28 27 26-25 24 23 -16 15-10 9 8-0
N Z C V Q ICI/IT T unused ICI/IT 中断号
APSR
N:表示两个有符号整数运算时,N==1表示运算结果为负数,N=0表示运算结果为正数或者零。
Z:Z=1表示运算结果为0,Z=0表示运算结果不为0
C:无符号加法运算产生进位,则C=1,无符号减法运算产生溢出,则C=0;
V:有符号加减运算产生溢出,则V=1;
Q:饱和条件码标志位
IPSR
在arm7中,是通过一个特定的数来表示某个模式,而cortex中,只有两个模式,所以当IPSR等于0时候,处于线程模式时,在手柄模式下,为当前异常的异常号。
EPSR
用来说明是arm指令还是thumb指令,其实也就是控制域的[5]位
T:Thumb状态, T=1,ARM状态,T=0;
通用状态寄存器
由R0到R12寄存器构成,其中R0到R7是低组寄存器。所有指令都能访问它们,复位后的初始值是不可预料的。R8-R12 被称为高组寄存器。这是因为只有很少的 16 位 Thumb 指令能访问它们, thumb-2 指令则不受限制。复位后的初始值也是不可预料的。
中间结果保存寄存器R12
R12一般用在子程序连接代码中使用,作为子程序的中间结果寄存器
堆栈指针寄存器R13(sp)
在 CM3 中有两个堆栈指针,当引用 R13(时,引用到的是当前正在使用的那一个,另一个必须用特殊的指令来访问( MRS,MSR指令)。
主堆栈指针(MSP),或写作 SP_main。这是缺省的堆栈指针,它由 OS 内核、异常服务例程以及所有需要特权访问的应用程序代码来使用。
进程堆栈指针(PSP),或写作 SP_process。用于常规的应用程序代码(不处于异常服用例程中时)。
连接寄存器R14(LR)
当通过BL跳转到子程序时,R14就被设置成子程序的返回地址,在子程序中把LR的值赋值给pc就可以实现子程序的返回。如 MOV PC,LR 或者 BX LR;
程序计数器R15(PC)
CM3 内部使用了指令流水线,读 PC 时返回的值是当前指令的地址+4。
二、中断发生时的动作
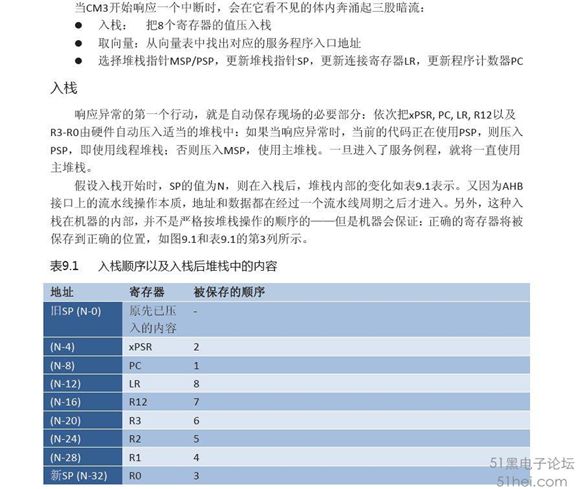
栈里面的值依次为R0~R3、R12、PC(Return address)、xPSR(CPSR或SPSR)、LR。
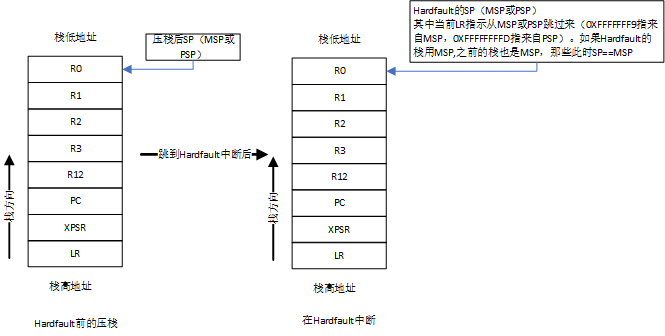
前面说过,连接寄存器R14(LR):当通过BL跳转到子程序时,R14就被设置成子程序的返回地址,在子程序中把LR的值赋值给pc就可以实现子程序的返回。但是当要跳到中断之前,LR赋给的是用来表示使用的栈为MSP还是PSP,意义如下:
因此,跟踪Hardfault的第一个步骤就是要找到发生问题时的栈首地址。
三、触发Hardfault中断时需要用到的信息
出现硬件错误可能有以下原因:
(1)数组越界操作;
(2)内存溢出,访问越界;
(3)堆栈溢出,程序跑飞;
(4)中断处理错误;
知道发生问题时栈的首地址,那么在栈里找到发生问题时的代码地址就能大概跟踪到问题所在位置。一般是找到PC与XSPR,PC是调用函数的地方,XSPR为发生问题时的代码行。例如:

PC指针
XPSR
在PC以前都是通用寄存器,所以通常查到的第一个地址就是PC的地址,也就是进入异常前要执行的命令。如果详细计算的话堆栈地址加上20也就是0x14就是PC的地址。要注意的是地址在寄存器中的顺序。
四、获取硬件错误信息的方法
知道了原理,遇到问题的终极解决办法:
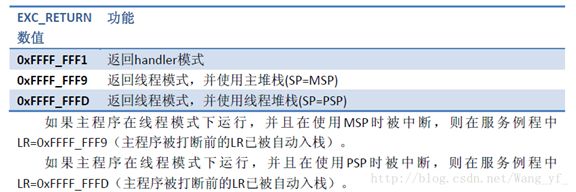
- 在Registers里面找到R14(LR)的值,例如:0xFFFFFFF9 (0xFFFFFFF9对应的是要看MSP寄存器,0xFFFFFFFD对应的是要看PSP寄存器 ),需要SP查找的内存地址是MSP的值:0x20008828
- 通过SP地址(0x20008828)找到PC(0x20008828+20)与XSPR(0x20008828+24)
- 再在map表或仿真下找到PC与XSPR这两个地址的代码位置,仔细研究附近代码的出错原因。
可以通过以下3种方式来定位到出错代码段。
1.仿真调试
keil MDK hardfault调试步骤_Wang_yf_的博客-CSDN博客_hardfault_handler keil
STM32进入HardFault_Handler处理办法_Moon~的博客-CSDN博客
https://www.cnblogs.com/zhangshenghui/p/5944881.html
2.通过接入JLINK-COMMAND对死在Hardfault中的产品进行定位:
JLink Commander调试方法_物联网布道者的博客-CSDN博客_jlink调试
打开JLINK-COMMAND后输入:
connect :选择相应的芯片,连接上目标板
h :停止设备,并能看到当前的SP MSP PSP LR等内容,根据LR决定选MSP还是PSP,例如选中MSP并为地址0x20008828
mem 0x20008828 20:读取栈的内存的32个字节,通过小端模式找到PC及XSPR
然后通过DEBUG或MAP表找到PC与XSPR相应地址的代码进行研究。
3.通过在Hardfault插入调试代码,触发故障时把PC与XPSR通过协议发出来。