CAP定理(CAP theorem)又被称作布鲁尔定理(Brewer's theorem),是回加州大学伯克得分校的计算机科学家埃里克·布鲁尔(Eric Brewer)在2000年的ACM PODC上提出的一个猜想。2002 年,麻省理工学院的赛斯·吉尔伯特(Seth Gilbert)和南希·林奇(Nancy Lynch)发表了布鲁尔猜想的证明,使之成为分布式计算领域公认的一个定理。
CAP理论
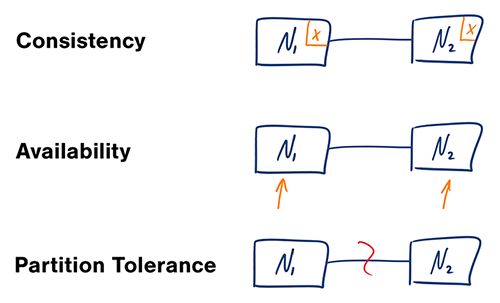
在一个分布式系统(指互相连接并共享数据节点的集合)中,当涉及读写操作时,只能保证一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三者中的两个,另外一个必须被牺牲。
The CAP Theorem states that, in a distributed system (a collection of interconnected nodes that share data.), you can only have two out of the following three guarantees across a write/read pair: Consistency, Availability, and Partition Tolerance - one of them must be sacrificed. However, as you will see below, you don’t have as many options here as you might think.
CAP原则
一致性(Consistency) - 对某个指定的客户端来说,读操作保证能够返回最新的写操作结果。
A read is guaranteed to return the most recent write for a given client.
可用性(Availability) - 非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。
A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout).
分区容错性(Partition Tolerance) - 当出现网络分区后,系统能够继续履行职责。
The system will continue to function when network partitions occur.
CAP应用
虽然CAP理论定义是三个要素中只能取两个,但放到分布式环境下来思考的话,我们会发出必须选择P(分区容错)要素,因为网络本身无法做到100%可靠,有可能出故障,所以分区是一个必然的现象。
如果我们选择了CA而放弃了P,那么当发生分区现象时,为了保证C,系统需要禁止写入,当有写入请求时,系统返回error,这双和A冲突了,因为A要求返回no error 和no timeout。因此,分布式系统理论上不可能选择CA架构,只能选择CP或者AP架构。
CP - Consistency/Partition Tolerance
如图1-1所示,为了保证一致性,当发生分区现象后,N1节点上的数据已经更新到y,但由于N1和N2之间的复制通道中断,数据y无法同步到N2,N2节点上的数据还是x。
这时客户端C访问N2时,N2需要返回Error,提示客户端面C:“系统现在发生错误”,这种处理方式违背了可用性(Availability)的要求,因此CAP三者只能满足CP。

图1-1:CP模式
AP - Availability/Partition Tolerance
如图1-2所示,为了保证可用性,当发生分区现象后,N1节点上的数据已经更新到y,但由于N1和N2之间的复制通道中断,数据y无法同步到N2,N2节点上的数据还是x。
这时客户C访问N2时,N2将当前自己拥有的数据x返回给客户端C了,而实际上当前最新的数据已经是y了,这就不满足一致性(Consistency)的要求了,因此CAP三者只能满足AP。
注意:这里N2节点返回的x,虽然不是一个“正确”的结果,但是一个“合理”的结果,因为x是旧的数据,并不是一个错乱的值,只是不是最新的数据而已。
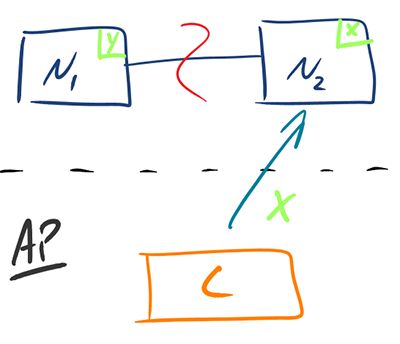
图1-2:AP模式
CAP扩展
理论的优点在于清晰简洁、易于理解,但是缺点就是高度抽象化、省略了很多的细节,导致在将理论应用到实践时,由于各种复杂情况,可能出现误解和偏差,CAP理论也不例外。
如果我们没有意识到这些关键的细节点,那么在实践中应用CAP理论时,就可能发出方案很难落地。
而在我们谈到数据一致性时,CAP、ACID、BASE这些就是我们拿来讨论的对象,原因是这三者都是和数据一致性相关的理论,如果不仔细理解三者之间的差别,则可能会陷入一头雾水的状态,不知道该用哪个才好。
这里,我们来说说CAP的具体细节,简单对比一下ACID、BASE几个概念的关键区别点。
CAP关键细节点
CAP关注的粒度是数据,而不是整个系统。
C与A之间的取舍可以在同一系统内以非常细小的粒度反复发生,而每一次的决策可能因为具体的操作,乃至因为牵涉到特定的数据或用户有所不同。
以一个用户管理系统为例,用户管理系统包含用户账号数据(用户ID、密码)、用户信息数据(昵称、兴趣、性别等)。通常情况下,用户账号数据会选择CP,而用户信息数据会选择AP,如果限定整个系统为CP,则不符合用户信息的应用场景;如果限定整个系统为AP,则又不符合用户账号数据的应用场景。
所以在CAP理论落地实践时,我们需要将系统内的数据按照不同的应用场景和要求进行分类,每类数据选择不同的策略(CP或AP),而不是直接限定整个系统所有数据都是同一策略。
CAP是忽略网络延迟的。
这是一个非常隐含的假设,布鲁尔在定义一致性时,并没有将延迟考虑进去。即当事务提交时,数据能够瞬间复制到所有节点。但实际情况下,从节点A复制数据到节点B,总是需要花费一定时间的。如果在相同机房可能是几毫秒,如果跨机房,可能是几十毫秒。这也就是说,CAP理论中的C在实践中是不可能完美实现的,在数据复制的过程中,节点A和节点B的数据并不一致。
正常运行情况下,不存在CP和AP的选择,可以同时满足CA。
CAP理论告诉我们分布式系统只能选择CP或者AP,但其实这里的前提是系统发生了“分区”现象。如果系统没有发生分区现象,也就是说P不存在的时候(节点的网络连接一切正常),我们就没有必要放弃C或者A,应该C和A都可以保证,这就要求架构设计的时候即要考虑分区发生时选择CP还是AP,也要考虑分区没有发生时如何保证CA。
这里我们还以用户管理系统为例,即使是实现CA,不同的数据实现方式也可能不一样:用户账号数据可以采用“消息队列”的方式来实现CA,因为消息队列可以比较好地控制实时性,但实现起来就复杂一些;而用户信息数据可以采用“数据库同步”的方式来实现CA,因为数据库的方式虽然在某些场景下可能延迟较高,但使用起来简单。
放弃并不等于什么都不做,需要为分区恢复后做准备。
CAP理论告诉我们三者只能取两个,需要“牺牲”(sacrificed)另外一个,这里的“牺牲”是有一定误导作用的,因为“牺牲”让很多人理解成什么也不做。实际上,CAP理论的“牺牲”只是说在分区过程中我们无法保证C或者A,但并不意味着什么都不做。分区期间放弃C或者A,并不意味着永远放弃C和A,我们可以在分区期间进行一些操作,从而让分区故障解决后,系统能够重新达到CA的状态。
最典型的就是在分区期间记录一些日志,当分区故障解决后,系统根据日志进行数据恢复,使得重新达到CA状态。
ACID
ACID 是数据库管理系统为了保证事务的正确性而提出来的一个理论,ACID 包含四个约束:
Atomicity(原子性)
一个事务中的所有操作,要么全部完成,要么全部不完成,不会在中间某个环节结束。事务在执行过程中发生错误,会被回滚到事务开始前的状态,就像这个事务从来没有执行过一样。
Consistency(一致性)
在事务开始之前和事务结束以后,数据库的完整性没有被破坏。
Isolation(隔离性)
数据库允许多个并发事务同时对数据进行读写和修改的能力。隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
Durability(持久性)
事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
划重点: 我们可以看到,ACID中的A(Atomicity)和CAP中的A(Availability)意义完全不同,而ACID中的C和CAP中的C名称虽然都是一致性,但含义也完全不一样。ACID 中的 C 是指数据库的数据完整性,而 CAP 中的 C 是指分布式节点中的数据一致性。再结合 ACID 的应用场景是数据库事务,CAP 关注的是分布式系统数据读写这个差异点来看,其实 CAP 和 ACID 的对比就类似关公战秦琼,虽然关公和秦琼都是武将,但其实没有太多可比性。
BASE
BASE 是指基本可用(Basically Available)、软状态( Soft State)、最终一致性( Eventual Consistency),核心思想是即使无法做到强一致性(CAP 的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性。
基本可用(Basically Available)
分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
这里的关键词部分和核心,具体选择哪些作为可以损失的业务,哪些是必须保证的业务,是一项有挑战的工作。例如,对于一个用户管理系统来说,“登录”是核心功能,而“注册”可以算作非核心功能。因为未注册的用户本来就还没有使用系统的业务,注册不了最多就是流失一部分用户,而且这部分用户数量较少。如果用户已经注册但无法登录,那就意味用户无法使用系统。例如,充了钱的游戏不能玩了、云存储不能用了……这些会对用户造成较大损失,而且登录用户数量远远大于新注册用户,影响范围更大。
软状态( Soft State)
允许系统存在中间状态,而该中间状态不会影响系统整体可用性。这里的中间状态就是 CAP 理论中的数据不一致。
最终一致性( Eventual Consistency)
系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
这里的关键词是一定时间 和 最终,一定时间和数据的特性是强关联的,不同的数据能够容忍的不一致时间是不同的。举一个微博系统的例子,用户账号数据最好能在 1 分钟内就达到一致状态,因为用户在 A 节点注册或者登录后,1 分钟内不太可能立刻切换到另外一个节点,但 10 分钟后可能就重新登录到另外一个节点了;而用户发布的最新微博,可以容忍 30 分钟内达到一致状态,因为对于用户来说,看不到某个明星发布的最新微博,用户是无感知的,会认为明星没有发布微博。“最终”的含义就是不管多长时间,最终还是要达到一致性的状态。
划重点: BASE 理论本质上是对 CAP 的延伸和补充,更具体地说,是对 CAP 中 AP 方案的一个补充。前面在剖析 CAP 理论时,提到了其实和 BASE 相关的两点:
CAP 理论是忽略延时的,而实际应用中延时是无法避免的。
AP 方案中牺牲一致性只是指分区期间,而不是永远放弃一致性。
总结
综合上面的分析,ACID 是数据库事务完整性的理论,CAP 是分布式系统设计理论,BASE 是 CAP 理论中 AP 方案的延伸。