SpringCloud(7)— ElasticSearch基础
SpringCloud(7)— Elasticsearch基础
一 初识Elasticsearch
elasticserach是一个强大的开源搜索引擎,可以从海量数据中迅速找到想要的内容。
elasticsearch结合了 Kibana, Logstach, Beats,也就是 elastic stack。主要应用于日志数据分析,实时监控等领域。

- Elasticsearch是Elastic Stack 的核心,负责数据存储,搜索,分析等
- Kibana负责数据可视化,可以自主实现
- Logstach、Beats负责抓取数据,可以自主实现
Elasticsearch底层是基于Lucene实现,Lucene是一个基于Java实现的搜索引擎类库,是Apache公司的项目
官方站点:Apache Lucene - Welcome to Apache Lucene
Lucene的优势:
- 易扩展性,基于java开发
- 高性能,基于倒排索引
相比Lucene, elasticserach的优点:
- 支持分布式,可水平扩展
- 提供Restful接口,可被任何语言调用
二 倒排索引
1.正向索引和倒排索引
传统数据库采用正向索引,例如给下表中的Id创建索引
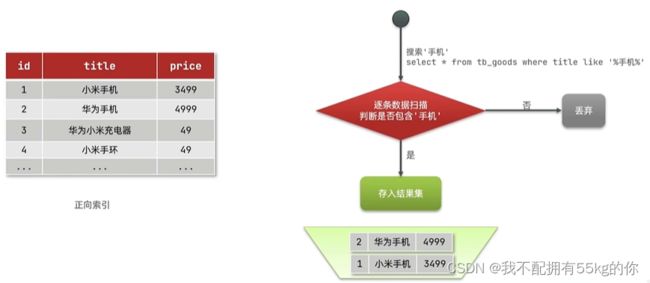
正向索引在做局部内容检索时效果较差
2.倒排索引
elasticsearch 使用倒排索引,加入了文档和词条的概念
- 文档(document):每一条数据就是一个文档
- 词条(term):文档按照语义分成的词语

核心理念:词条不重复,如果遇到相同的词条,则追加文档 id
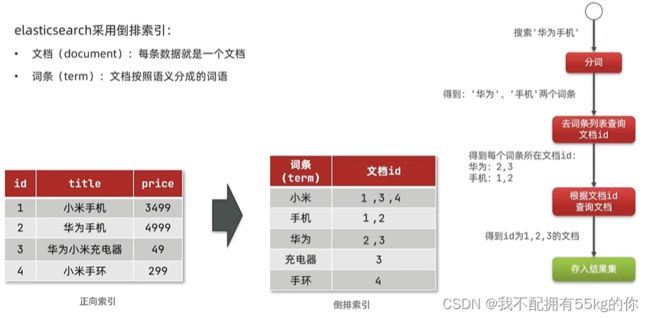
倒排索引更加适合用于内容的检索
3.Elasticsearch文档
Elasticsearch是面向文档存储的,可以是数据库中的一条数据,例如一个商品,一笔订单。
文档数据会被序列化为 Json 格式后存储在 elasticsearch 中
4.Elasticsearch索引
- 索引(index)是指相同类型的文档的集合
- 映射(mapping)索引中文档的字段约束信息,类似表的结构约束

5.Elastic与Mysql概念对比
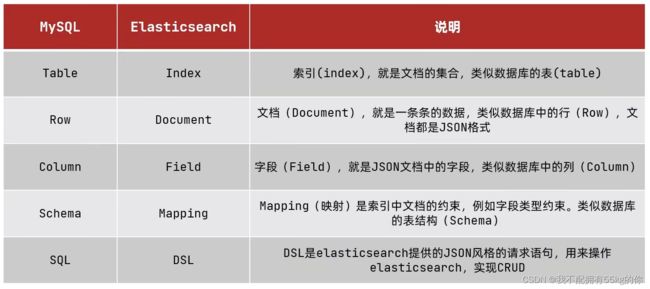
Mysql:擅长事务类型的操作,可以确保数据的安全性和一致性
ElasticSearch:擅长海量数据的搜索,分析和计算
简单小结:
- 文档:一条数据就是一个文档,es中时json格式,相当于MySQL数据库中的一条数据
- 字段:Json文档中的字段
- 索引:同类型文档的集合,相当于MySQL数据库中的数据表
- 映射:索引中文档的约束,比如字段名,类型等
三 ElasticSearch的安装
ElasticSearch,简称ES
1.部署单节点ES
1.创建网络
因为需要部署 kibana 容器,因此需要让 es 和 kibana 容器互联,这里先创建一个网络
# 创建一个网络
docker network create [netname]
# 示例:创建一个名为 es-net 的网络
docker network create es-net
# 对于 docker 中网络的命令,通过 docker network --help 查询了解
docker network --help
2.获取ES和kibana
# 1.拉取 elasticsearch 镜像,这里使用 7.12.1 版本
docker pull elasticsearch:7.12.1
# 2.拉取 kibana 镜像,这里使用 7.12.1 版本
docker pull kibana:7.12.1
3.运行ES和kibana
1.运行 es
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsarch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
- -e:设置环境变量
- -v:设置挂载目录
- -p:对外暴露的端口映射
- ES_JAVA_OPTS:设置 JVM 的堆内存大小
- discovery.type:设置单节点运行
- -v es-data:/usr/share/elasticsarch/data:挂载数据卷
- -v es-plugins:/usr/share/elasticsearch/plugins:挂载插件目录卷,后期扩展时使用
- –network:运行 es 容器加入到指定的网络中,es-net 为前边创建的网络名称
- 9200:对外暴露的 http 协议端口,供用户使用
- 9300:ES容器各节点之间互联的端口
运行容器成功后,在浏览器访问9200端口,如果出现返回一下Json数据,说明es容器运行成功
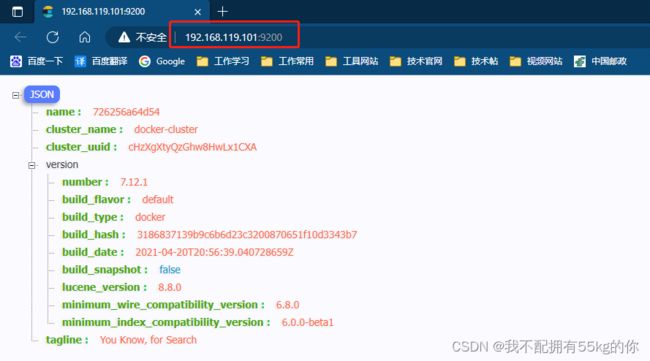
踩坑点:什么都没有修改但是却无法访问时,请运行其他需要容器(例如 mysql,rabbitmq)。
如果抛出 “WARNING: IPv4 forwarding is disabled. Networking will not work”这个异常时,请参考一下文档解决
解决报错 : IPv4 forwarding is disabled. Networking will not work
(这个情况出现在虚拟机上,大概率和虚拟机的网络有关,未深究)
2.运行 kibana
kibana可以给我们提供一个 elasticsearch 的可视化界面,便于学习和使用
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
-
需要将es和kibana加入到同一个网络当中,因为它们已经在同一个网络中,所以可以使用容器名称相互访问
-
-e ELASTICSEARCH_HOSTS:设置es的地址
运行容器成功后,便可以在浏览器中访问kibana的地址,看到kibana的界面了
注意:Kibana启动较慢,容器运行成功不代表就可以打开Kibana,需要稍微等待一会儿,或者可以通过容器日志来监控Kibana的运行状态
四 分词器IK
es在创建倒排索引时需要对文档分词;在搜索时,需要对用户输入内容进行分词。 但是默认分词规则对中文支持较差
对于中文分词,一般使用 IK分词器,IK分词器是ES的一个插件,对中文支持更加友好
GitHub地址:GitHub - medcl/elasticsearch-analysis-ik
1.安装IK分词器
在线安装IK分词器
# 1.进入容器内部
docker exec -it es bash
# 2.下载指定版本的插件到指定位置,推荐和ES版本保持一致
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
# 3.安装完成后退出容器,并且重启容器
exit
docker restart es
安装速度太慢时,建议使用离线安装
下载离线安装包,将安装包解压到指定文件夹,然后连同文件夹一起放到 es-plugins 这个数据卷的目录下
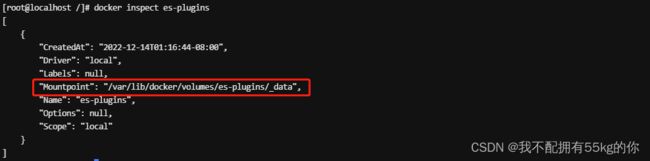
# 1.下载离线安装包,将安装包直接放到 es-plugins 这个数据卷的目录下
# 2.查看 es-plugins 数据卷所在的目录
docker inspect es-plugins
# 3.使用ftp工具直接将 ik 分词器的离线安装包解压后放到指定目录下
最后重启 es 的容器
2.测试IK分词器
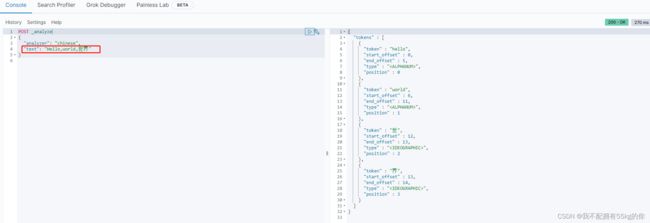
IK分词器有两种模式
- ik_smart:最少切分,词切分的比较粗(粒度粗)
- ik_max_word:最细切分,词切分的比较细(粒度细)
在 kibana 的 devtools 中进行测试,得到了预期的结果

3.拓展和停用词典
所有的分词器均基于字典进行分词,所以需要进行方便的拓展才能更好的被人们所使用
要拓展IK分词器,只需要修改一个IK分词器目录中的 config 目录中的IKAnalyzer.cfg.xml 文件
下面示例中的 ext_dict 和 ext_stopwords 分别是拓展词和停用词,且 dict.dic 和 stopwords.dic 均为存储对应词典的文件名
DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置comment>
<entry key="ext_dict">dict.dicentry>
<entry key="ext_stopwords">stopword.dicentry>
properties>
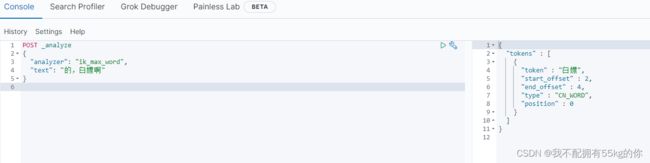
创建 dict.dic 和 stopwords.dic 两个文件,并且填入想要拓展或停用的词,每个词语占据一行。
dict.dic 中填入自定义的特殊词
shaopengjie
奥力给
白嫖
stopwords.dic 中填入无意义的词,例如语气词
的
啊
配置完成之后,重启 es 容器。再次进行测试,发现自定义的特殊词语已经可以进行准确的切分了,且完美的过滤了无意义的语气词。
五 DSL 操作索引库
1.Mapping映射属性
mapping 是对索引库中文档的约束,常见的 mapping 属性包括:
1.type
type 表示字段的数据类型,常见的简单类型有
- 字符串:text(可分词的文本),keyword(精确值)
- 数值类型:long,integer,short,byte,double,flaot
- 布尔:boolean
- 日期:date
- 对象:object
- 数组:ES 中没有数组的概念,但是允许某一个字段有多个值。以上的常用类型均可作为数组来使用
注意:按照数组的方式来存储数据时,重点在于数组中的元素的类型
2.Index
index 表示是否创建倒排索引,默认为 true。根据实际业务需求进行判断,如果一个字段需要被搜索,则 indx 应当 true,反之亦然。
3.analyzer
analyzer 表示使用哪种分词器。分词器主要是用来对内容进行分词
4.properties
properties 表示该字段的子字段
2.创建索引库
ES 中通过 Restful 请求创建索引库,文档。请求内容使用 DSL 语句表示。
注意,一下操作均在 kibana 中的 dev tools 上操作
创建索引库的简单语法说明:
PUT /索引库名称
{
"mappings":{
"properties":{
"字段名":{
"type":"text",
"analyzer":"ik_smart"
},
"字段名2":{
"type":"keyword",
"index":"false"
},
"字段名3":{
"properties":{
"子字段名":{
"type":"keyword",
}
}
}
}
}
}
简单示例:创建一个名为 shawn 的索引库
PUT /shawn
{
"mappings": {
"properties": {
"id":{
"type": "long",
"index": false
},
"name":{
"properties": {
"firstName":{
"type":"text"
},
"lastName":{
"type":"text"
}
}
},
"describe":{
"type": "text"
}
}
}
}
3.查看/修改/删除 索引库
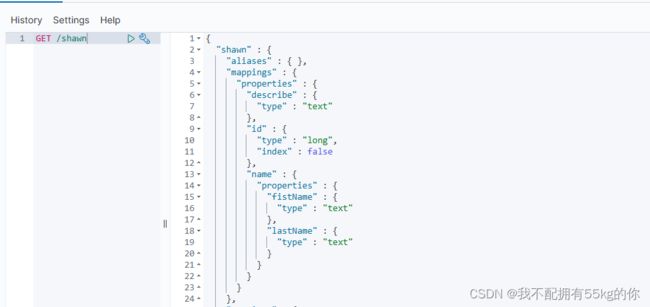
1.查询索引库,将请求方式修改为 GET 即可
# 1.查看指定名称的索引库
GET /【indexName】
# 2.示例
GET /shawn
2.修改索引库
ES 当中,索引库和 mapping 一旦创建好就不允许进行修改。但是可以允许添加新的字段到已有的索引库中
注意:已经存在的 mapping 无法再次添加
语法如下:
PUT /【indexName】/_mapping
{
"properties":{
"新字段名":{
"type":"integer"
}
}
}
示例:添加一个 新的字段到前边创建的 shawn 索引库
PUT /shawn/_mapping
{
"properties": {
"address":{
"type": "text"
}
}
}
3.删除索引库,将请求方式更改为 DELETE 即可
# 1.删除指定名称的索引库
DELETE /【indexName】
# 2.示例
DELETE /shawn
六 DSL 操作文档
对于文档的操作,增删改都会导致文档版本号的增加
1.新增文档
新增文档的语法如下:
POST /【indexName】/_doc/【文档ID】
{
"字段1":"字段1值",
"字段2":"字段2值",
"字段3":{
"子属性1":"子属性1值",
"子属性2":"子属性2值"
}
}
示例代码:
POST /shawn/_doc/1
{
"address":"陕西省西安市高新区",
"describe":"程序猿一枚",
"id":1,
"name":{
"firstName":"马",
"lastName":"小云"
}
}
2.查询文档
根据 Restful 风格,使用 GET 请求方式来查询文档
# 1.查询文档
GET /【indexName】/_doc/【文档ID】
# 2.示例
GET /shawn/_doc/1
3.删除文档
根据 Restful 风格,使用 DELETE 请求方式来查询文档
# 1.删除文档
DELETE /【indexName】/_doc/【文档ID】
# 2.示例
DELETE /shawn/_doc/1
4.修改文档
修改文档有两种方式:
1.全量修改:全量会改会先根据 文档ID 在索引库中找到数据并且删除,然后重新添加一次
全量修改与新增文档的语法一致,只是将请求方式从 POST 修改成了 PUT
PUT /【indexName】/_doc/【文档Id】
{
"字段1":"值1",
"字段2":"值2"
//....
}
需要注意:当【文档Id】在索引库中不存在时,虽然无法进行删除操作,但仍然可以进行天添加操作
所以一般情况认为,PUT 方式既可以做修改操作,也可以做新增操作
2.局部修改:局部修改为增量修改,只会修改指定的字段值
POST /【indexName】/_update/【文档Id】
{
"doc":{
"字段1":"字段1值",
"字段2":"字段2值",
}
}
局部修改示例:
POST /shawn/_update/1
{
"doc":{
"address":"齐齐哈尔",
"name":{
"lastName":"小军"
}
}
}
七 DSL搜索
elasticsearch最主要的功能是实现搜索
1.DSL 查询分类
DSL Query官方文档:Query DSL | Elasticsearch Guide 8.5 Elastic
Elasticsearch提供了基于 JSON 的 DSL(Domain Specific Language)来定义查询,常见的查询类型包括:
- 查询所有:查询所有数据,一般用于测试。例如 match_all
- 全文检索(full text):利用分词器对用户输入的内容进行分词,然后去倒排索引库中匹配,例如 match查询 multi_match查询
- 精确查询:根据精确磁条值查找数据,一般查找 keyword 类型,数值,日期等类型字段,例如:ids range term
- 地理查询:根据经纬度查询,例如:geo_distance geo_bounding_box
- 复合查询:复合查询是将以上的各种查询组合在一起,合并查询条件,例如:bool function_score
2.DSL Query 语法
DSL 查询语法如下:
GET /【indexName】/_search
{
"query":{
"查询条件":"条件值"
}
}
3.查询所有【match_all】示例
GET /hotel/_search
{
"query": {
"match_all": {}
}
}
4.全文检索查询
全文检索查询,会对用户输入的内容进行分词,常用于搜索框
1.match
match 查询语法:
GET /【indexName】/_search
{
"query": {
"match": {
"字段名":"字段值"
}
}
}
需要进行分词查询的是在创建索引库时 mapping 类型为 text 的字段,由于有多个 text 类型的字段,并且这些都已经通过 copy_to 复制到了 all 字段上,所以这里使用 all 作为字段名去查询,就可以查到所有满足条件的数据了。
match查询 示例:
GET /hotel/_search
{
"query": {
"match": {
"all":"高新"
}
}
}
2.multi_match
multi_match 与 match 类似,只不过允许同时查询多个字段,且只要满足其中一个就符合查询条件
multi_match查询 语法示例:
GET /【indexName】/_search
{
"query": {
"multi_match": {
"query":"字段值"
"fields":["字段1","字段2"...]
}
}
}
multi_match查询 示例:
GET /hotel/_search
{
"query": {
"multi_match": {
"query":"高新",
"fields":["name","brand"]
}
}
}
参与查询条件越多,速度就会越慢,建议利用 copy_to 将多个字段复制到同一个字段中,然后使用 match 去查询
5.精确查询
精确查询一般是指查询 keyword,日志,数值,boolean等字段,这些值得特点是不可分割,所以精确查询不会对查询条件进行分词处理
1.term
term 是根据词条精确查询,可以是 keyword,日期,数值等
语法示例:
GET /【indexName】/_search
{
"query": {
"term": {
"字段名":"字段值"
}
}
}
使用示例:
GET /hotel/_search
{
"query": {
"term": {
"brand":"如家"
}
}
}
2.range
range 是根据范围查询,可以是日期范围,数值范围等
语法示例:
GET /【indexName】/_search
{
"query":{
"range":{
"字段名":{
"gte":"范围最小值",
"lte":"范围最大值"
}
}
}
}
使用示例:
GET /hotel/_search
{
"query":{
"range":{
"price":{
"gte":230,
"lte":300
}
}
}
}
6.地理位置查询
1.geo_bounding_box
查询 geo_point 值 落在某个矩形范围内的全部文档
语法示例:
GET /【indexName】/_search
{
"query":{
"geo_bounding_box":{
"字段名":{
"top_left":{
"lat":"经度",
"lon":"纬度"
},
"bottom_right":{
"lat":"经度",
"lon":"纬度"
}
}
}
}
}
或者:
GET /【indexName】/_search
{
"query":{
"geo_bounding_box":{
"字段名":{
"top_left":"纬度,经度",
"bottom_right":"纬度,经度"
}
}
}
}
使用示例:
GET /hotel/_search
{
"query":{
"geo_bounding_box":{
"location":{
"top_left":"31.351433,121.47522",
"bottom_right":"31.251433,122.47522"
}
}
}
}
2.geo_distance
geo_distance 用于查询指定中心 小于 某个距离值的所有文档
GET /【indexName】/_search
{
"query":{
"geo_distance":{
"distance":"距离",
"字段名":"纬度,经度"
}
}
}
示例
GET /hotel/_search
{
"query":{
"geo_distance":{
"distance":"2km",
"location":"31.251433,121.47522"
}
}
}
7.复合查询
复合查询可以将其他简单查询组合起来,实现更加复杂的搜索逻辑。
1.function score
算分函数查询,可以控制文档相关信息算分,控制文档排名
相关性算法:当我们利用 match 查询时,文档结果会根据与搜索词条的关联度打分( _score ),返回结果时按照分值降序排列


使用 function score query ,可以修改文档的相关性算分(query score),根据新得到的算分排序
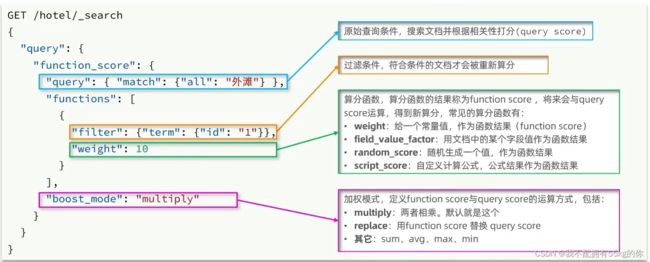
示例代码:
GET /hotel/_search
{
"query":{
"function_score": {
"query": {
"geo_distance":{
"distance":"2km",
"location":"31.251433,121.47522"
}
},
"functions": [
{
"filter": {"terms": {
"brand": [
"如家"
]
}},
"weight": 10
}
],
"boost_mode": "multiply"
}
}
}

2.boolean query
布尔查询是一个或多个查询子句的组合,子查询的组合方式有:
- must:必须匹配每个子查询,类似 “与”
- should:选择性匹配子查询,类似 “或”
- must_not:必须不匹配,不参与算分,类似 “非”
- filter:必须匹配,不参与算分
布尔查询示例:
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"terms": {
"brand": ["如家","速8"]
}
}
],
"filter": [
{
"terms": {
"business": [
"四川北路商业区"
]
}
}
]
}
}
}
8.排序
Elasticsearch 支持对搜索结果排序,默认是根据 **相关度算分(_score)**来排序。可以排序字段类型有 keyword类型,数值类型,地理坐标类型,日期类型等
自定义排序方法后,es 会放弃默认的 相关度算分 和 相关度算分排序。
1.一般字段排序
GET /【indexName】/_search
{
"query":{
"match_all":{}
},
"sort":[
{
"字段1":"desc" // 排序字段和排序方式 asc desc
},
{
"字段2":"asc" // 排序字段和排序方式 asc desc
}
]
}
带排序的示例:
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"terms": {
"brand": ["如家","速8"]
}
},
{
"geo_distance":{
"distance":"4km",
"location":"31.251433,121.47522"
}
}
]
}
},
"sort": [
{
"price": "asc"
}
]
}
2.地理位置排序
按照地理坐标排序,是按照指定的位置中心点,由远到近或由近到远进行排序
GET /hotel/_search
{
"query": {
"match_all":{}
},
"sort": [
{
"_geo_distance":{
"字段名":"纬度,经度",
"order": "升序或降序,asc|desc",
"unit": " 距离单位 默认为km "
}
}
]
}
地理坐标排序示例:
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"terms": {
"brand": ["如家","速8"]
}
},
{
"geo_distance":{
"distance":"4km",
"location":"31.251433,121.47522"
}
}
]
}
},
"sort": [
{
"_geo_distance":{
"location": {
"lat": 31.251433,
"lon": 121.47522
},
"order": "asc",
"unit": "km"
}
}
]
}
3.排序示例-1
按照 评分降序 和 价格升序 排序
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"score": "desc"
},
{
"price": "asc"
}
]
}
4.排序示例-2
按照 距离指定 位置最近进行排序
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance":{
"location": "31.251433,121.47522",
"order": "asc",
"unit": "km"
}
}
]
}
9.分页
1.简单分页
elasticsearch 默认情况下只返回 top10 的数据,而如果要查询更多数据就需要修改分页参数
elasticsearch 中通过修改 from,size 参数来控制要返回的分页结果
- from:分页开始的位置,默认为0
- size:期望获得的文档数量,默认为10
分页基本语法如下:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from":分页开始的位置,默认为0,
"size":期望获得的文档数量,默认为10,
"sort": [
{
"_geo_distance":{
"location": "31.251433,121.47522",
"order": "asc",
"unit": "km"
}
}
]
}
DSL 代码演示如下:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from":10,
"size":3,
"sort": [
{
"_geo_distance":{
"location": "31.251433,121.47522",
"order": "asc",
"unit": "km"
}
}
]
}
2.深度分页问题
ES 是分布式的,所以会面临深度分页问题,例如直接按照某个值进行排序,获取指定 from,size 的数据,在数据库切片的情况下可能无法得到正确的数据信息
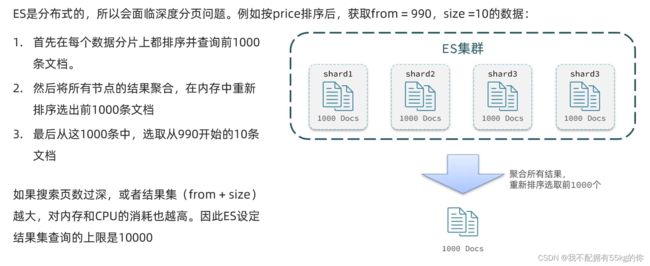
ES 设定的结果集查询上线为10000,即 from + size 之和不得超过 10000
针对深度分页问题,ES 提供了两种结局方案
- search after:分页时需要排序,原理上是从上一次的排序值开始,查询下一页数据。(官方推荐)
- scroll:将排序的数据形成快照,保存在内存。(已经不推荐)
search after 仅支持向后分页查询,不支持向前查询
scroll 当数据过多时占据的内存也太多,而且由于快照缘故,当数据更新时 scroll 这种方式无法支持更新
10.高亮显示
高亮显示就是在搜索结果中把搜索关键字突出显示
实现原理:服务端提前给结果中的关键字添加标记或标签,然后由前端编写样式,从而实现关键字的高亮显示
- 高亮显示不支持 match_all 查询,因为高亮显示仅对所查询的关键字进行高亮
- 默认情况下,高亮字段需要与搜索字段保持一致才可以高亮显示
基础语法:
GET /hotel/_search
{
"query": {
"match": {
"all":"如家"
}
},
"highlight": {
"fields": {
"字段1": {
"pre_tags": "样式前缀,默认为",
"post_tags": "样式后缀,默认为",
"require_field_match": "是否需要与字段值匹配,默认为true"
},
"字段2": {
"pre_tags": "样式前缀",
"post_tags": "样式后缀"
}
}
}
}
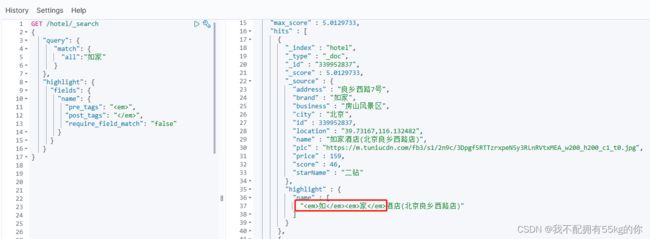
高亮示例:
GET /hotel/_search
{
"query": {
"match": {
"all":"如家"
}
},
"highlight": {
"fields": {
"name": {
"pre_tags": "",
"post_tags": "",
"require_field_match": "false"
}
}
}
}
注意:高亮并不会修改原始值,高亮的值在 json 结构中的 highlight 区域
下一小结,探讨 ElasticSearchs 在Java 项目中的实际使用。
2022-12-20 增加第七小结 “ DSL搜索 ”
本结知识点完毕,完结撒花。