Refactoring a Go Code into SOLID Code(将 Go 代码重构为 SOLID 代码)
Refactoring a Go Code into SOLID Code(将 Go 代码重构为 SOLID 代码)

一个大项目需要一个SOLID原则的基本原则。
这个原则是可以处理错综复杂并在不可预测的情况下灵活处理。
在Elasticsearch Getting Started with Go中,我们成功地使用 Go 和 Elasticsearch 构建了我们的主要 CRUD 服务器。
但是,此代码需要重构才能成为 SOLID。我们将在下一节详细讨论如何做到这一点。
为什么选择 SOLID

如今的形势经常迫使开发人员更改他们的代码以克服即将到来的浪潮。
为了生存现在,我们需要与这些运动相关;这是不可避免的。
我们的代码必须具有可扩展性和适应性,才能应对这一挑战。
这就是为什么使用 SOLID 原因。
SOLID 是 Bob 大叔设计的一种编码原则,用于构建我们可扩展和可维护的代码。它代表以下思想:
- The Single-responsibility principle(单一职责原则)
- The Open–closed principle(开闭原则)
- The Liskov substitution principle(里氏替换原则)
- The Interface segregation principle(接口隔离原则)
- The Dependency inversion principle(依赖倒置原则)
在本文中,我们不讨论里氏替换原则。因此,我们的代码示例不使用类继承。
项目设计结构
在我们进行重构之前,我们需要设计我们的项目结构。我们使用Go 项目布局作为我们的基本参考,因为它很流行并且符合 SOLID 原则。
从该布局中,我们采用了几个文件夹,将我们的示例代码转换为新形式,如下所示:
solid-go
├── cmd
│ └── app-search
│ ├── main
│ └── main.go
├── configs
│ └── configs.go
├── deployments
│ ├── docker-compose.yaml
│ └── Dockerfile
├── go.mod
├── go.sum
├── internal
│ └── search
│ ├── handler
│ │ └── rest.go
│ ├── model
│ │ └── employee.go
│ ├── repository
│ │ ├── repository.go
│ │ └── types.go
│ └── service
│ └── service.go
├── Makefile
└── README.md
让我们更详细地讨论单个文件夹的目标:
cmd 文件夹
cmd 是一个包含我们主要 Go 包的索引。
它是保存我们源代码中所有可执行二进制文件的地方。
每个二进制文件代表一个特定的业务逻辑。
因此,这些二进制文件通常由子文件夹分隔。
文件的结构具有以下格式:
cmd/
├── {{app-name-1}}
└── {{app-name-2}}
在这个项目中,我们只使用一个用例。因此,使用一个按以下层次排列的子文件夹就足够了:
cmd/
└── app-search
├── main
└── main.go
configs 文件夹
configs 文件夹是我们应用环境的模型。
通常它是从 “.env” 文件或我们操作系统中的全局导出变量中读取的。
对于这个项目,我们使用 struct 类型将配置表示为对象。
此外,层次结构直接具有以下结构,如下所示:
configs/
└── configs.go
internal 文件夹
internal 文件夹是包含我们私有代码的文件夹。
换句话说,这个文件夹中的所有代码都是不可公开访问的;只有具有相同包的邻居或孩子才能导入/访问它。
我们通常把业务逻辑安排在这个文件夹上;它是我们源代码的核心。
对于每个业务范围,我们将其拆分为具有以下格式的子文件夹下的用例:
internal/
├── {{use-case-1}}
└── {{use-case-2}}
在我们的例子中,我们只将我们的业务逻辑设计到子文件夹搜索下的一个基本范围:
internal/
└── search
├── handler
│ └── rest.go
├── model
│ └── model.go
├── repository
│ └── repository.go
└── service
└── service.go
如您所见,以下是模型(model)、服务(service)、存储库(repository)和处理程序(handler)。我们将在下一节详细讨论这一点。
deployments 文件夹
最后,部署文件夹是部署文件或模板(Dockerfile、docker-compose 等)的地方。
因此,我们有 Dockerfile 和 docker-compose.yaml;无论如何,我们只是把它放在这里:
deployments/
├── docker-compose.yaml
└── Dockerfile
单一职责原则
让我们讨论单一职责的第一个原则。该原则规定:
A module should be responsible to one, and only one, actor.
作为开发人员,我们有几个优势:
- 测试——我们可以专注于基于每一层创建测试
- 低耦合——因为每一层都有特殊的责任,所以依赖性更小。
- 组织——明显的层次结构使我们很容易分离我们的关注点。
我们可以将这里的模块类比为 Go 中的包。通常,从我们的布局来看,我们分为几个文件夹层次结构。每个那个文件夹都属于一个有特定职责的 Go 包,所以我们已经实现了这个原则。
预先,我们有一个**/internal文件夹,我们将其拆分为四个子文件夹(模型、服务、存储库和处理程序**)。
这种设计模式遵循著名的三层架构,将业务逻辑分为三个独立的层。这些层由表示层、业务层和数据层组成。
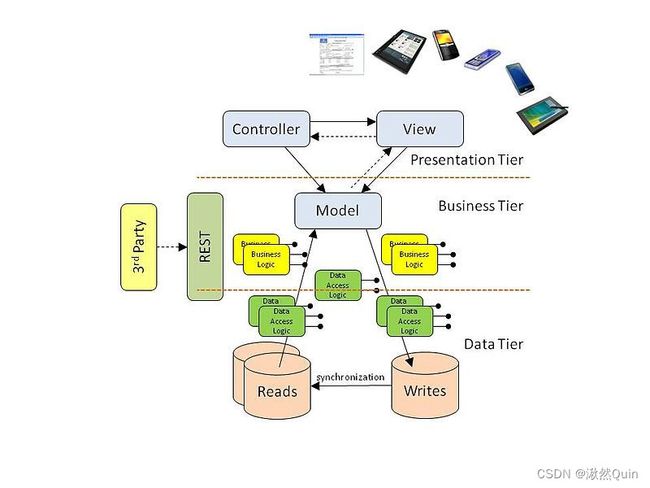
三层架构图取自https://en.wikiversity.org/wiki/Three-Tier_Architecture
我们可以用我们的**/internal**文件夹分别表示每一层,如下所示:
- 模型(model)(业务层) 负责表示我们的业务对象
- 服务(service)(业务层) 负责持有我们的核心业务逻辑
- 存储库(repository)(数据层) 负责与我们的数据库进行通信
- 处理程序(handler)(表示层) 负责成为我们的表示层
开闭原则
一旦我们完成了项目布局的设计,我们就可以开始编写一些代码了。
然而,为了直截了当,我们只关注包含我们业务逻辑的最关键的包 – /internal。
我们的第一个目标是组织可靠的代码,因此开放式代码变得非常重要:
Software entities (classes, modules, functions, etc.) should be open for extension but closed for modification.
从这个语句中,我们可以确保我们的代码不会看起来很脆弱。
因为每个新的更改都不会影响我们现有的代码。
这个原则在我们的存储库层非常适合;让我们重写我们的client.go到存储库中:
package repository
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"log"
"net/http"
"strconv"
"strings"
"github.com/sog01/solid-go/internal/search/model"
)
type Repository interface {
CheckHealth() error
CreateIndex() error
InsertData(e *model.Employee) error
SeedingData(idStart, n int) error
UpdateData(e *model.Employee) error
DeleteData(id int) error
SearchData(keyword string) ([]*model.Employee, error)
}
type ElasticSearch struct {
baseURL string
}
func NewElasticSearch(baseURL string) *ElasticSearch {
return &ElasticSearch{baseURL}
}
func (c *ElasticSearch) CheckHealth() error {
response, err := http.Get(c.baseURL)
if err != nil {
return err
}
defer response.Body.Close()
responseBody, err := ioutil.ReadAll(response.Body)
if err != nil {
return fmt.Errorf("failed check Elasticsearch health: %v", err)
}
log.Println("debug health check response: ", string(responseBody))
return nil
}
func (c *ElasticSearch) CreateIndex() error {
body := `
{
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "text"
},
"address": {
"type": "text"
},
"salary": {
"type": "float"
}
}
}
}
`
req, err := http.NewRequest("PUT", c.baseURL+"/employee", strings.NewReader(body))
if err != nil {
return fmt.Errorf("failed to make a create index request: %v", err)
}
httpClient := http.Client{}
req.Header.Add("Content-type", "application/json")
response, err := httpClient.Do(req)
if err != nil {
return fmt.Errorf("failed to make a http call to create an index: %v", err)
}
defer response.Body.Close()
responseBody, err := ioutil.ReadAll(response.Body)
if err != nil {
return fmt.Errorf("failed read create index response: %v", err)
}
log.Println("debug create index response: ", string(responseBody))
return nil
}
func (c *ElasticSearch) InsertData(e *model.Employee) error {
body, _ := json.Marshal(e)
id := strconv.Itoa(e.Id)
req, err := http.NewRequest("PUT", c.baseURL+"/employee/_doc/"+id, bytes.NewBuffer(body))
if err != nil {
return fmt.Errorf("failed to make a insert data request: %v", err)
}
httpClient := http.Client{}
req.Header.Add("Content-type", "application/json")
response, err := httpClient.Do(req)
if err != nil {
return fmt.Errorf("failed to make a http call to insert data: %v", err)
}
defer response.Body.Close()
responseBody, err := ioutil.ReadAll(response.Body)
if err != nil {
return fmt.Errorf("failed read insert data response: %v", err)
}
log.Println("debug insert data response: ", string(responseBody))
return nil
}
func (c *ElasticSearch) SeedingData(idStart, n int) error {
for i := idStart; i < n; i++ {
if err := c.InsertData(&model.Employee{
Id: i,
Name: "person" + strconv.Itoa(i),
Address: "address" + strconv.Itoa(i),
Salary: float64(i * 100),
}); err != nil {
return fmt.Errorf("failed seeding data with id %d: %v", i, err)
}
}
return nil
}
func (c *ElasticSearch) UpdateData(e *model.Employee) error {
body, _ := json.Marshal(map[string]*model.Employee{
"doc": e,
})
id := strconv.Itoa(e.Id)
req, err := http.NewRequest("POST", c.baseURL+"/employee/_update/"+id, bytes.NewBuffer(body))
if err != nil {
return fmt.Errorf("failed to make a update data request: %v", err)
}
httpClient := http.Client{}
req.Header.Add("Content-type", "application/json")
response, err := httpClient.Do(req)
if err != nil {
return fmt.Errorf("failed to make a http call to update data: %v", err)
}
defer response.Body.Close()
responseBody, err := ioutil.ReadAll(response.Body)
if err != nil {
return fmt.Errorf("failed read update data response: %v", err)
}
log.Println("debug update data response: ", string(responseBody))
return nil
}
func (c *ElasticSearch) DeleteData(id int) error {
req, err := http.NewRequest("DELETE", c.baseURL+"/employee/_doc/"+strconv.Itoa(id), nil)
if err != nil {
return fmt.Errorf("failed to make a delete data request: %v", err)
}
httpClient := http.Client{}
req.Header.Add("Content-type", "application/json")
response, err := httpClient.Do(req)
if err != nil {
return fmt.Errorf("failed to make a http call to delete data: %v", err)
}
defer response.Body.Close()
responseBody, err := ioutil.ReadAll(response.Body)
if err != nil {
return fmt.Errorf("failed read delete data response: %v", err)
}
log.Println("debug delete data response: ", string(responseBody))
return nil
}
func (c *ElasticSearch) SearchData(keyword string) ([]*model.Employee, error) {
query := fmt.Sprintf(`
{
"query": {
"match": {
"name": "%s"
}
}
}
`, keyword)
req, err := http.NewRequest("GET", c.baseURL+"/employee/_search", strings.NewReader(query))
if err != nil {
return nil, fmt.Errorf("failed to make a search data request: %v", err)
}
httpClient := http.Client{}
req.Header.Add("Content-type", "application/json")
response, err := httpClient.Do(req)
if err != nil {
return nil, fmt.Errorf("failed to make a http call to search data: %v", err)
}
defer response.Body.Close()
responseBody, err := ioutil.ReadAll(response.Body)
if err != nil {
return nil, fmt.Errorf("failed read insert data response: %v", err)
}
var searchHits SearchHits
if err := json.Unmarshal(responseBody, &searchHits); err != nil {
return nil, fmt.Errorf("failed read unmarshal data response: %v", err)
}
var employees []*model.Employee
for _, hit := range searchHits.Hits.Hits {
employees = append(employees, hit.Source)
}
return employees, nil
}
repository代码由interface Repository和 struct Elasticsearch组成。
interface 约定了数据库操作。
换句话说,当我们想要添加更多的存储库(如 MySQL、Postgres 等)时,我们直接通过添加,实现对应的 interface,而不需要修改任何现有代码。
接口隔离原理
构建存储库后,我们继续编写我们的模型和**服务,**这是必不可少的。
这两个包包含我们的业务实体和业务逻辑。
让我们把注意力集中到employee.go的模型中:
package model
type Employee struct {
Id int `json:"id"`
Name string `json:"name,omitempty"`
Address string `json:"address,omitempty"`
Salary float64 `json:"salary,omitempty"`
}
在我们的模型准备好后,我们将通过从 main.go 拆封业务逻辑来实现 service 开发,代码如下:
package service
import "github.com/sog01/solid-go/internal/search/model"
type Service interface {
SearchEmployees(keyword string) ([]*model.Employee, error)
InsertEmployee(e *model.Employee) error
SeedingEmployees(idStart, n int) error
UpdateEmployee(e **model.Employee) error
DeleteEmployee(id int) error
CheckHealth() error
CreateIndex() error
}
可是等等!看起来我们的服务需要有一个明确的目标。
该组合由几个不同的动作组成。
因此,复杂性的操作总是推给我们的 service;我们必须使其细化。
这样就是接口隔离原则。它指出:
No code should be forced to depend on methods it does not use.
按照这个原则,我们可以根据它的作用将服务拆分成三个接口:
package service
import (
"log"
"github.com/sog01/solid-go/internal/search/model"
"github.com/sog01/solid-go/internal/search/repository"
)
// interface area
type Search interface {
SearchEmployees(keyword string) ([]*model.Employee, error)
}
type Sync interface {
InsertEmployee(e *model.Employee) error
SeedingEmployees(idStart, n int) error
UpdateEmployee(e *model.Employee) error
DeleteEmployee(id int) error
CheckHealth() error
}
type Construct interface {
CreateIndex() error
}
// search service area
type SearchService struct {
repository repository.Repository
}
func NewSearchService(repo repository.Repository) *SearchService {
return &SearchService{repository: repo}
}
func (s *SearchService) SearchEmployees(keyword string) ([]*model.Employee, error) {
employees, err := s.repository.SearchData(keyword)
if err != nil {
log.Println("failed search employees: ", err)
return nil, err
}
return employees, nil
}
// sync service area
type SyncService struct {
repository repository.Repository
}
func NewSyncService(repo repository.Repository) *SyncService {
return &SyncService{repository: repo}
}
func (s *SyncService) InsertEmployee(e *model.Employee) error {
err := s.repository.InsertData(e)
if err != nil {
log.Println("failed insert employee: ", err)
return err
}
return nil
}
func (s *SyncService) SeedingEmployees(idStart, n int) error {
err := s.repository.SeedingData(idStart, n)
if err != nil {
log.Println("failed seeding employees: ", err)
return err
}
return nil
}
func (s *SyncService) UpdateEmployee(e *model.Employee) error {
err := s.repository.UpdateData(e)
if err != nil {
log.Println("failed update employee: ", err)
return err
}
return nil
}
func (s *SyncService) DeleteEmployee(id int) error {
err := s.repository.DeleteData(id)
if err != nil {
log.Println("failed delete employee: ", err)
return err
}
return nil
}
func (s *SyncService) CheckHealth() error {
err := s.repository.CheckHealth()
if err != nil {
log.Println("failed do health check: ", err)
return err
}
return nil
}
// construct service area
type ConstructService struct {
repository repository.Repository
}
func NewConstructService(repo repository.Repository) *ConstructService {
return &ConstructService{repository: repo}
}
func (s *ConstructService) CreateIndex() error {
err := s.repository.CreateIndex()
if err != nil {
log.Println("failed create index: ", err)
return err
}
return nil
}
现在我们的服务好多了。
通过分成三个部分,我们可以对代码进行细粒度的修改,而不用担心我们的代码会变得庞大。
因此,我们将其组织在正确的位置。
让我们也编写我们的处理程序:
package handler
import (
"encoding/json"
"log"
"net/http"
"strconv"
"github.com/sog01/solid-go/internal/search/model"
"github.com/sog01/solid-go/internal/search/service"
)
type Rest struct {
SearchService service.Search
SyncService service.Sync
}
func NewRest(searchService service.Search,
syncService service.Sync) *Rest {
return &Rest{
SearchService: searchService,
SyncService: syncService,
}
}
func (rest *Rest) Router(mux *http.ServeMux) {
mux.HandleFunc("/search", rest.SearchEmployeesHandler)
mux.HandleFunc("/insert", rest.InsertEmployeeHandler)
mux.HandleFunc("/update", rest.UpdateEmployeeHandler)
mux.HandleFunc("/delete", rest.DeleteEmployeeHandler)
mux.HandleFunc("/health", rest.HealthCheckHandler)
}
func (rest *Rest) ListenAndServe() {
mux := &http.ServeMux{}
log.Println("listening server on port 8080")
rest.Router(mux)
http.ListenAndServe(":8080", mux)
}
func (rest *Rest) InsertEmployeeHandler(w http.ResponseWriter, r *http.Request) {
var employee *model.Employee
json.NewDecoder(r.Body).Decode(&employee)
if err := rest.SyncService.InsertEmployee(employee); err != nil {
writeResponseInternalError(w, err)
return
}
writeResponseOK(w, employee)
}
func (rest *Rest) UpdateEmployeeHandler(w http.ResponseWriter, r *http.Request) {
var employee *model.Employee
json.NewDecoder(r.Body).Decode(&employee)
if err := rest.SyncService.UpdateEmployee(employee); err != nil {
writeResponseInternalError(w, err)
return
}
writeResponseOK(w, employee)
}
func (rest *Rest) DeleteEmployeeHandler(w http.ResponseWriter, r *http.Request) {
id, _ := strconv.Atoi(r.FormValue("id"))
if err := rest.SyncService.DeleteEmployee(id); err != nil {
writeResponseInternalError(w, err)
return
}
writeResponseOK(w, model.Employee{Id: id})
}
func (rest *Rest) SearchEmployeesHandler(w http.ResponseWriter, r *http.Request) {
keyword := r.FormValue("keyword")
employees, err := rest.SearchService.SearchEmployees(keyword)
if err != nil {
writeResponseInternalError(w, err)
return
}
writeResponseOK(w, employees)
}
func (rest *Rest) HealthCheckHandler(w http.ResponseWriter, r *http.Request) {
if err := rest.SyncService.CheckHealth(); err != nil {
writeResponseInternalError(w, err)
return
}
writeResponseOK(w, map[string]string{
"status": "OK",
})
}
func writeResponseOK(w http.ResponseWriter, response interface{}) {
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(http.StatusOK)
writeResponse(w, response)
}
func writeResponseInternalError(w http.ResponseWriter, err error) {
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(http.StatusInternalServerError)
writeResponse(w, map[string]interface{}{
"error": err,
})
}
func writeResponse(w http.ResponseWriter, response interface{}) {
json.NewEncoder(w).Encode(response)
}
依赖倒置原则
最后不能不提的是依赖倒置原则,它指出:
High-level modules should not import anything from low-level modules. Both should depend on abstractions.
换句话说,高层必须与低层解耦,反之亦然,这样每一组的任何变化都不会影响另一组。我们可以显示代码的层次结构如下:

handler -> service -> repository 的层次依赖关系
正如您在此处所意识到的,我们将每一层定义为一个接口。
从外层处理程序导入服务开始,直到服务导入存储库。
然而,这个原则是最后的关键步骤,许多开发人员有时需要帮助来验证。
因此,我们将回答这个问题来测试我们的设计是否正确。
假设我们想用 MySQL 数据库替换我们的 Elasticsearch。应该改变哪个级别?
正确的答案是只有存储库应该改变。
存储库中的任何更改都不会破坏service和handler。
由于我们在代码中使用抽象(Go 中的接口)作为依赖项,因此每一层上的通信变得不那么耦合了。
此外,我们可以快速隔离特定层的任何问题并立即进行修复。
接线
最后一步是将我们的 CMD 文件夹中的所有层连接到我们的主包中:
package main
import (
"log"
"github.com/sog01/solid-go/configs"
"github.com/sog01/solid-go/internal/search/handler"
"github.com/sog01/solid-go/internal/search/repository"
"github.com/sog01/solid-go/internal/search/service"
)
func main() {
// read a configs instance
configs := configs.ReadConfigs()
// construct a repository
repository := repository.NewElasticSearch(configs.ElasticSearchConfigs.BaseURL)
// do a health check
// if error abort operation immediately
checkHealth(repository)
// construct services
searchService := service.NewSearchService(repository)
syncService := service.NewSyncService(repository)
constructService := service.NewConstructService(repository)
// initiate an index
constructService.CreateIndex()
// construct a rest handler
rest := handler.NewRest(searchService, syncService)
// listen and serve server
rest.ListenAndServe()
}
func checkHealth(repository repository.Repository) {
if err := repository.CheckHealth(); err != nil {
log.Fatalf("missing elasticsearch connection: %v", err)
}
}
最后的话,非常感谢,不要犹豫放弃一些评论和反馈;我将非常感激。在接下来的帖子中再见,祝您编码愉快!
资料
原文
github