【NLP】实体识别TENER论文阅读笔记
写在前面
TENER是邱锡鹏老师团队的工作,其核心在于Attention设计时考虑了对实体识别而言可能重要的三个因素:方向、距离(相对位置)以及词间更sharp的注意力。
实际上看过原文之后,TENER和Transformer基本上差不多,简单地说TENER就是针对NER场景进行Transformer的适配改进,用邱锡鹏老师的原话“站在巨人的肩上”。
这篇笔记主要就是针对这几处小改动进行一个相对细致的分析和记录。
论文名称:《TENER: Adapting Transformer Encoder for Named Entity Recognition》
论文链接:https://arxiv.org/abs/1911.04474
代码地址:https://github.com/fastnlp/TENER
一、问题和核心思想
1. 方向和位置
Louis Vuitton founded Louis Vuitton Inc. in 1854这里直接使用论文给出的一个例子。通常,在in之后的词更可能是位置或者时间,比如这里的1854就是一个时间实体;而在Inc之前的词更可能代表组织,比如这里的Louis Vuitton Inc,所以词之间的相对方向是较重要的。
另外,词之间的相对距离也很重要,因为通常实体都是由连续的字或词构成的,比如这里句中的Louis Vuitton就比句首的Louis Vuitton更可能和Inc构成一个实体。
但个人感觉这段motivition没有说清楚太或者说它的说服力不够。因为这几个点都是考虑在attention计算的时候,但attention本质上就是计算词之间的相似度,然后基于这个相似度对词加权求和,重新表征词(简单地说就是词向量的转化或者说映射)。也就是说应该解释的是为什么计算attention时要考虑这几点?这样的attention有什么特别之处?对之后的词表征有什么影响,以至于模型可以正确判断实体类型以及实体边界?
非要套上去理解,只能这么想:(忽略词向量)因为1854、Louis Vuitton Inc和in的相对方向和相对距离的不同,所以in和它们的相似度不同。所以在最终对Louis Vuitton Inc和1854进行表征时,由in贡献的那部分值不同,使得Louis Vuitton Inc和1854具有不同的特性,而这个特性使得它们可以分别被识别为组织机构和时间。
2. 更sharp的注意力
对于每个词而言,可能我们仅需要知道较小部分的上下文就可以判别它的实体类别,而不需要关注所有词。但是经过transformer后的attention较为平滑,这样平滑的权重可能会带来一些噪声,影响我们的判定。极端点,也许我们需要就是内积经过softmax后的结果是非0即1,不要那么“soft”,为了达到这个效果,scale参数可以丢掉。
二、模型细节
1. Transformer概述
快速回顾下Transformer,方便后续TENER的细节分析。这里的Attention指的是self-attention,也就是在序列内部做Attention以寻找序列内部词间关系。
1.1 Self-Attention
设是token向量序列(token指字或词),其中代表序列长度,代表token向量维度。另外,参数矩阵、、的维度均为,用于将输入序列映射到不同的空间,则是scale参数。
有了这些定义后,我们再来看scale的内积attention:
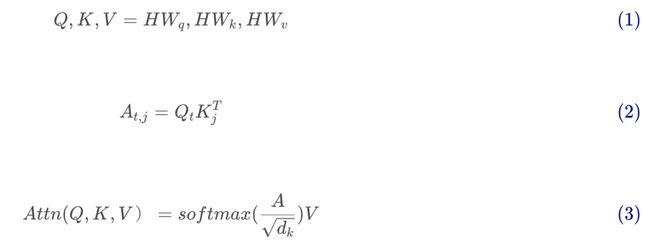
式中为序列中的第个token的表征,而则为第个token的表征,当然这里的表征是指经、映射过后的。
那么表示的是第、个token之间相似度。最终这个相似度矩阵由scale参数的调节后,再经过softmax进行归一化就得到了最终的相似度矩阵。最后再乘上就完成了重新表征过程。
1.2 Position Embedding
Transformer本身不能捕捉序列信息,比如我们交换token的顺序,但是对每个token而言,出来的attention结果还是一样的,那么最终每个token的新表征也还是一样的,只是它们的位置变了而已。
另一方面。我们知道当词的顺序变了以后,很有可能语义已经变了。另外在不同位置的词它本身也可能扮演不同的角色。比如开头我们提到的句首和句中的Louis Vuitton。
所以为了引入位置信息,Transformer设计了位置表征(Position Embedding):

这里,而依旧代表token的向量维度。
2. 方向和距离感知的Attention
由于TENER主要的改动就在Attention 上。那么这部分我们就来看看原始的Attention有什么问题,尤其是位置嵌入有什么问题;然后再来看TENER是怎么去避免那些问题的。
2.1 距离有感但方向无感的位置嵌入
根据式和式,第个token的位置嵌入:

这里。那么第和第个token之间的内积即为:

再根据二角和差公式,最终两个token之间基于位置嵌入的内积仅取决于相对偏移量:

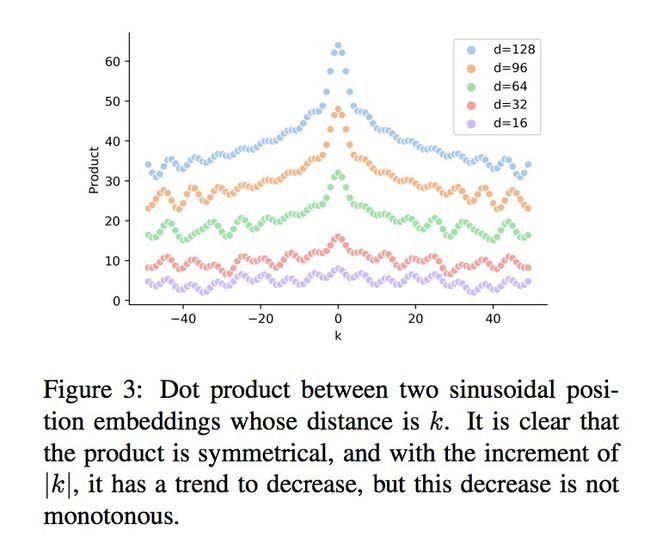
也就是说transformer提出的位置嵌入成功地考虑了相对位置这个点。但是,相对方向它却无法把控,因为,所以这个内积具有对称性:

这点看图更直观:
2.2 距离有感到无感
由式和,两个token的位置嵌入并不是直接内积,而需要先经过一次变换(这里忽略token嵌入部分的计算,仅看两个token位置嵌入部分参与的计算,注意行列向量的区别),所以内积其实是:
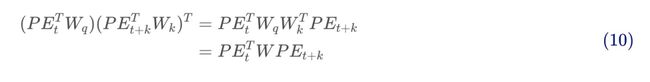
这里。我们看到式和的区别仅在于中间多了一个参数矩阵。下图2展示了两者的区别:
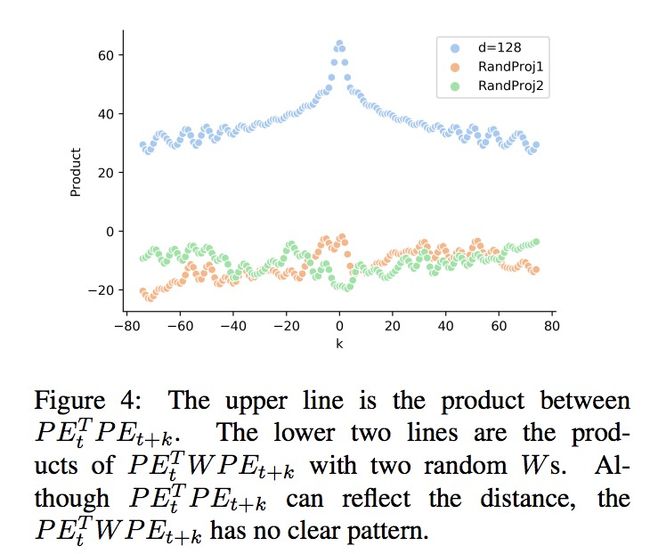
很明显,当经过query和key的参数矩阵映射以后,再去与内积时,就变得距离无感了。
2.3 TENER中的Attention改动
位置嵌入部分的改动
transformer里的内积计算其实是两部分:(1)token向量部分;(2)位置嵌入部分。token向量部分的计算没什么问题,所以保持;而位置嵌入部分的计算可以稍作修改。
由式和可知:
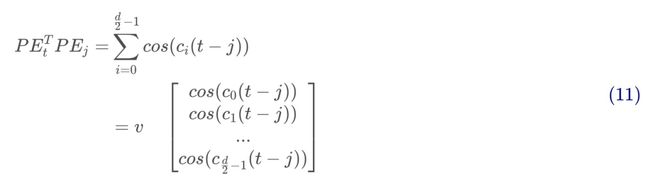
这里。我们知道方向无感主要是因为,我们又知道,所以最简单粗暴的方式就是把cos换成sin,当然论文这里只是换了一半,或者说论文这里是插入了sin项:

再代入,考虑经过转换后的token维度为,最终来自位置嵌入部分的内积贡献为:

其中:
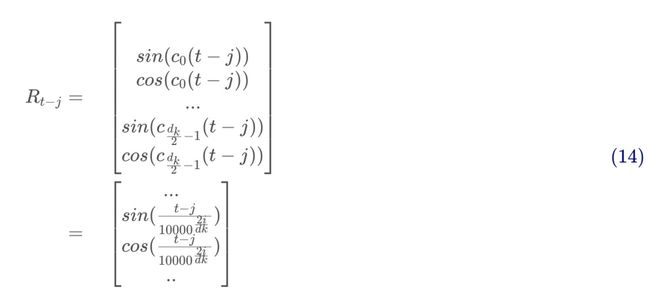
式即为TENER中attention计算的一部分,当然这里的则是一个参数。式跟式不能说是毫无关系,可以说是一模一样了。夸张一下,二者还是有一定的差别,主要就是在刻画的对象。
式是针对某一位置(如)的token的位置嵌入,而式则可以看作是考虑了两个位置(如和)的token的相对距离,所以原文把它称之为相对位置的嵌入(relative positional encoding)。并且式也同时考虑了相对方向:
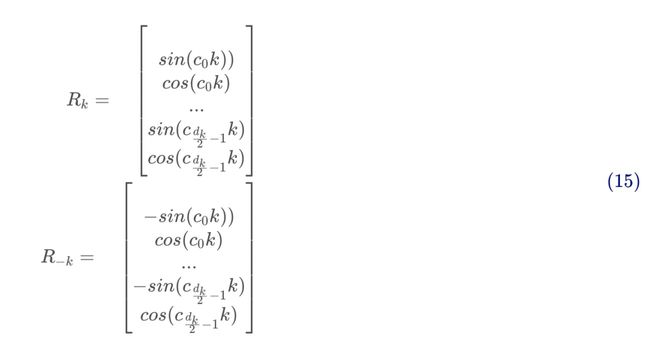
Attention计算整体改动
我们下面来看整体上TENER的Attention的改动(这部分直接贴原文的公式截图,但是注意这里有行列向量问题):

重点在式上,等号右边的第一项和第四项分别是token向量之间的内积以及我们刚刚分析完的位置部分的贡献。那么中间两项、又代表什么呢?原文说的是the tth token’s bias on certain relative distance and the bias on the jth token,我在这里理解为偏置(就是+b的那个)。但是不明白这第二项为什么不跟第三项一样,即为什么不是。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载中国大学慕课《机器学习》(黄海广主讲)机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码: