Java中的多线程安全问题
目录
一、什么是线程安全?
二、线程不安全的原因
2.1 从底层剖析count++的操作
2.2 线程不安全的原因总结
2.3 JVM内存模型(JMM)
三、synchronized 关键字-监视器锁monitor lock
3.1 如何加锁(Synchronized用法和特性)
3.1.1. 独占性
3.1.2 可重入性
四、Java 标准库中的线程安全类
五、volatile关键字
5.1 volatile可以保证内存可见性
5.2 volatile不可以保证原子性
一、什么是线程安全?
简单的理解:如果多线程环境下代码运行的结果是符合我们预期的,即在单线程环境应该的结果,则说这个程序是线程安全的。
观察一下代码:使用两个线程,每个线程都对这个 Counter进行5w次自增,预计是结果为10w。
/**
* Created with IntelliJ IDEA.
* Description:
* User: 86136
* Date: 2023-01-12
* Time: 20:50
*/
class Counter {
public int count = 0;
public void increase() {
count++;
}
}
public class Demo13 {
static Counter counter = new Counter();
public static void main(String[] args) throws InterruptedException {
//使用两个线程,每个线程都对这个 Counter进行5w次自增
//预计是结果为10w
Thread t1 = new Thread(() -> {
for (int i = 0; i < 5_0000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 5_0000; i++) {
counter.increase();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(counter.count);
}
}
运行结果:

二、线程不安全的原因
上面我们使用了多线程运行了一个程序,想让这个变量从0自增到10w次,但是最终实际结果比我们预期的结果要小,这是线程调度顺序的随机性导致的,造成了线程间自增的指令集交叉,导致本来需要自增两次但值只自增了一次的情况。所以得到的结果偏小。
2.1 从底层剖析count++的操作
count++ 操作,在底层其实是被分为三条指令在CPU上进行执行的
- 把内存的数据读取到CPU的寄存器上(load)
- 把CPU的寄存器中的值,进行+1(add)
- 把寄存器中的值,写回到内存中(save)
这里简单的描述几种情况,初始条件:初始值为1,对其进行两次自增。
情况1 :线程间的指令集,没有交叉,运行结果和预期结果相同,

情况2:线程间指令集存在交叉,运行结果低于预期结果

情况3:线程间的指令集完全交叉,实际结果低于预期。

根据上面我们所举出的情况,可以得出,满足线程安全需要具备原子性(自增操作的三条指令可以拆分,不具备这个特点)。
2.2 线程不安全的原因总结
- 抢占式执行,可以说是线程不安全的万恶之源:多个线程的调度执行过程是“完全随机的‘(这里并非是数学上的完全随机,但是确实是没有规律可言)。
- 多个线程修改同一个变量。
- 修改操作不是原子的,如count++一样,其本质在CPU上其实会被分为load,add,save这三个单位。解决线程安全最常见的手段就是从这里入手,通过一些方法将这些指令打包为一个整体。
- 内存可见性问题,这是JVM的代码优化背景下,在运用到多线程中引入的bug。
- 指令重排序:可以理解为规划最优路线,这是一种编译器优化,举个栗子:洗碗,烧水,和拖地,我们可以在洗碗的时候同时进行烧水的工作。
对于指令重排序的前提是 "保持逻辑不发生变化". 这一点在单线程环境下比较容易判断, 但是在多线程环境下就没那么容易了, 多线程的代码执行复杂程度更高, 编译器很难在编译阶段对代码的执行效果进行预测, 因此激进的重排序很容易导致优化后的逻辑和之前不等价
现在我们对以上的 内存可见性 进行一定的补充:
可见性的定义
:一个线程对共享变量值的修改,能够及时地被其他线程看见。
2.3 JVM内存模型(JMM)
Java虚拟机规范中定义了Java内存模型,目的是屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的并发效果。

- 线程之间的共享变量存在 主内存 中(Main Memory)
- 每一个线程都有自己的“工作内存”(Work Memory)
- 当线程要读取一个共享变量的时候,会先把变量从主内存拷贝到工作内存中,再从工作内存读取数据。
- 当线程要修改一个共享变量的时候,也会先把工作内存中的副本,再同步到主内存中。
但是由于每个线程都有自己的工作内存,这些工作内存中的内容相当于同一个共享变量的副本,此时如果修改线程1的工作内存的值,线程2的工作内存不一定会及时变化。
犹如下面情况:
初始情况 :当两个线程的工作内存相同时候。

后续:一旦线程1修改了a的值,那么主内存不一定能够及时同步,对应的线程2的工作内存的a值也不一定能及时同步。

这时的代码可能就会出现问题。
思考:为什么需要那么多内存?为什么要这么麻烦的拷贝来拷贝去?
1):实际并没有那么多的内存,这只是Java规范中的一个术语,是属于抽象的叫法,因为我们需要更好的通用性/跨平台性,Java语言的初衷其实就是让程序员们感受不到硬件上的差异。(比如工作内存就和硬件无关,因为CPU内部的结构是不一样的,有的CPU是只带寄存器,有的带寄存器和缓存,有的CPU缓存还有多级缓存(L1,L2,L3)).这时不同CPU存储方式就不一样了,此时使用工作内存就代指上面一套(寄存器+缓存)。
所谓的 “主内存”,才是真正硬件角度的内存,而所谓的 “工作内存”则是指:CPU的寄存器和高速缓存。
2):因为CPU访问自身寄存器的速度以及高速缓存的速度,远超于访问内存的速度(快了3-4个数量级)。
比如某个代码要连续10次读取某个变量的值,如果10次都从内存读,速度是很慢的,但是如果只是第一次从内存读,读到的结果缓存到CPU的某个寄存器中,那么后9次读数据就不必访问内存了,效率大大提高。
那么问题来了,既然访问寄存器的速度这么快,那么全部都用寄存器不就好了,为什么还需要内存呢?
:因为CPU中的寄存器价格昂贵,内存次之,硬盘最便宜。所以导致了需要内存配合寄存器使用。
值得一提的是,快和慢是相对的,CPU访问寄存器的速度远远高于访问内存的速度,但是内存的访问速度又远远快于硬盘。
这里用一段代码再次演示以便加深印象:

我们已经知道,访问寄存器的速度是远远高于内存的,在下面这段代码中,while循环内会频繁的进行读内存(LOAD)和比较的操作(CMP,比较寄存器中的值是否为0).
由于load消耗的时间比CMP的时间慢了3~4个数量级,于是编译器就会对这一现象进行优化:
编译器认为因为要频繁的执行load,而且load得到的结果是一样的(编译器这么认为的,实际不一定,比如下面我们举的例子)。于是就只执行一次load,后续在进行CMP的时候就不会再读内存了,而是读JMM中的工作内存(寄存器的值或者缓存)。
但是如果在这期间,有人修改了这个值,代码就会因为编译器的优化而出现bug:
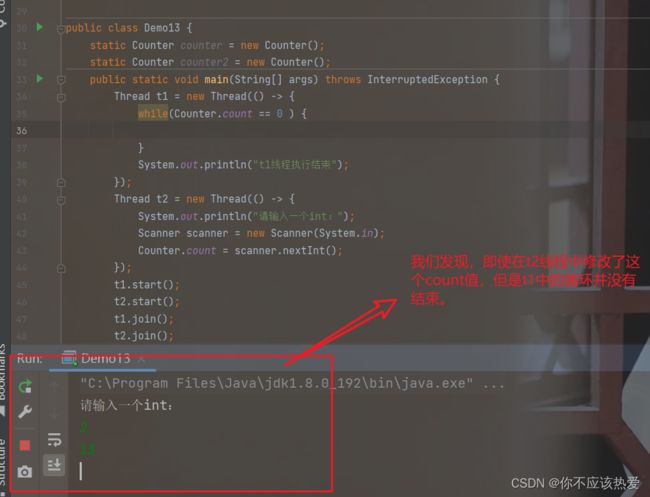
结论:编译器优化会在多线程的情况下可能会出现误判。
既然编译如果在自己判断不准确的话,把不该优化的地方优化了,那么就可以让程序员们显示的提醒编译器,该地方无需优化。这也正是volatile的作用。
三、synchronized 关键字-监视器锁monitor lock
那么以上的问题如何解决呢?那就需要引入Java中的”锁”
再回顾刚刚的代码,我们只需要将increase方法用synchronized修饰即可。
class Counter {
public int count = 0;
public synchronized void increase() {
count++;
}
}整段代码:
class Counter {
public int count = 0;
public synchronized void increase() {
count++;
}
}
public class Demo13 {
static Counter counter = new Counter();
public static void main(String[] args) throws InterruptedException {
//使用两个线程,每个线程都对这个 Counter进行5w次自增
//预计是结果为10w
Thread t1 = new Thread(() -> {
for (int i = 0; i < 5_0000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 5_0000; i++) {
counter.increase();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(counter.count);
}
}
运行结果:

3.1 如何加锁(Synchronized用法和特性)
3.1.1. 独占性
利用synchronized的独占性,也称互斥性,通俗一点来说就是如果当前锁没有被上锁,那么这个加锁操作就会成功,如果当前锁已经被人加上,加锁操作就会阻塞等待。
- 进入 synchronized 修饰的代码块,相当于加锁
- 退出 synchronized 修饰的代码块,相当于解锁

加锁之后,原先可以交叉执行的指令就无法交叉,变成了一个整体。

如果仍无法理解线程1在参与其他工作时候,线程2无法进入CPU执行,可以看一下这个栗子:
类似于图书馆占座,小A同学占座之后不一定每时每刻都在图书馆位子上,可能中途上厕所,饭点去吃饭之类的,而这期间小B同学想使用小A的这个位置是不被允许的。

如果把for也写到加锁代码里,这时候就跟完全串行一样了。
总结:加锁要考虑好锁哪段代码,锁的代码范围不一样,对代码执行效果会有很大影响,锁的代码越多,就叫做”锁的粒度越大/越粗“,锁的代码越少,就叫做”锁的粒度越小/越细“。
有的同学可能会问,如果一个线程加锁,一个线程不加锁,这时线程安全能否保证?
首先我们要明白一点,线程安全,不是因为加了锁就一定安全,而是通过加锁,让并发修改同一个变量变成串行修改同一个变量才安全。结论就是不正确的加锁方式,不一定能解决线程安全问题。
举例:这时只给一个线程加锁,这个是没啥用的,一个线程加锁,不涉及到”锁竞争“,也就不会阻塞等待,相应,也就不会并发执行变成串行执行。
class Counter {
public int count = 0;
public synchronized void increase() {
count++;
}
public void increase2() {
count++;
}
}
public class Demo13 {
static Counter counter = new Counter();
public static void main(String[] args) throws InterruptedException {
//使用两个线程,每个线程都对这个 Counter进行5w次自增
//预计是结果为10w
Thread t1 = new Thread(() -> {
for (int i = 0; i < 5_0000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 5_0000; i++) {
counter.increase2();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(counter.count);
}
}
运行结果仍比期望的10w小:

在日常开发的过程中,可能会碰到需要加锁的代码不完全都在一个方法中,这时该怎么处理?
其实我们的synchronized除了能修饰方法外,还可以修饰代码块。因此,我们就可以把要进行加锁的逻辑放到synchronized修饰的代码块中,也能起到加锁的效果。

写法1:
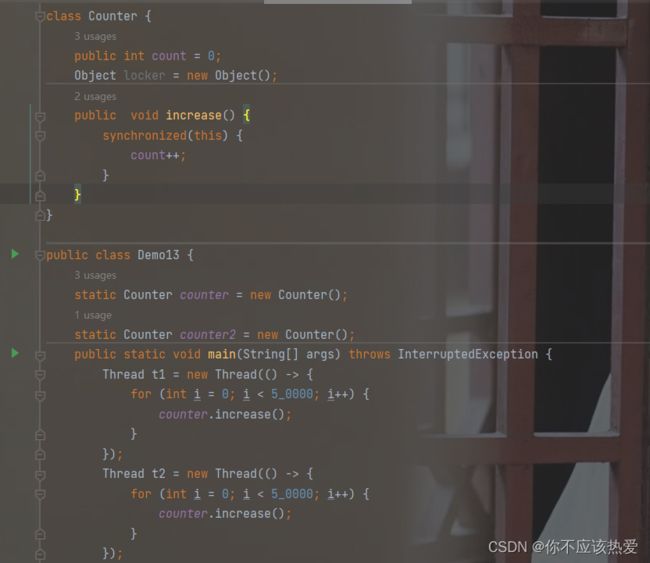
需要注意的是:synchronized里面锁的对象个数只能为一,虽然在Java中任何对象都可以被当作锁对象,但是我们并不关心对象是谁,而是关系是否锁的是同一个对象,因为只有多个线程锁同一个对象的时候,这时才能进行锁竞争。
就如下图一样,因为是针对两个不同对象进行加锁,所以不涉及到锁竞争。

写法2:针对locker对象进行加锁,locker是Counter的一个普通成员(非静态成员),每一个Counter实例中,都有自己的locker实例。

分析:这个代码中都针对counter对象进行加锁,counter对象中的locker是同一个对象,因此仍然可以导致锁竞争的产生。
延申1;如果这里调用count1,count2的increase,因为locker不是同一个locker,结论
:同样无法产生锁竞争。

延申2:将locker变为静态的。结论;会产生锁竞争。

延申3:一个锁locker,一个锁当前对象(this),结论:不会产生锁竞争
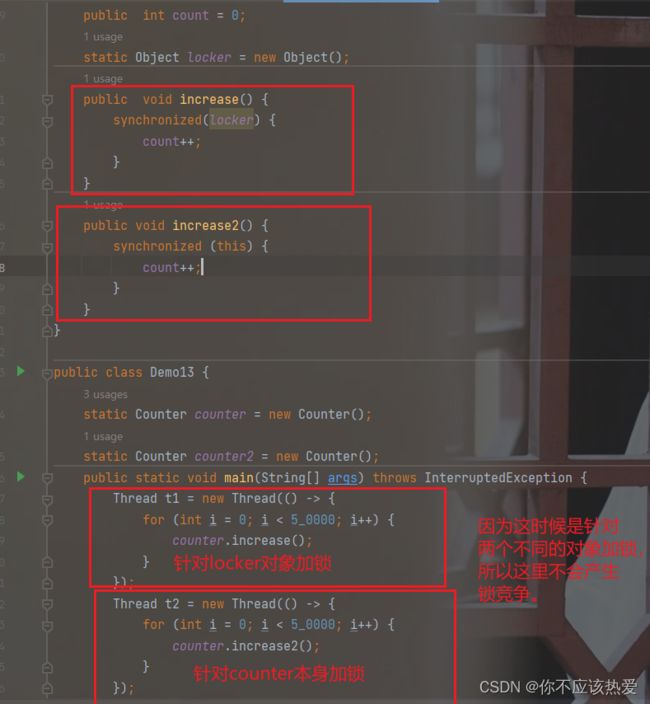
延申4:锁对象为一个类对象 Counter.class(在JVM中只有一个,存储的是Counter中的详细信息,比如属性数量,名称,类型等),结论:会产生锁竞争。

延申5:synchronized修饰静态方法,结论:会产生锁竞争。
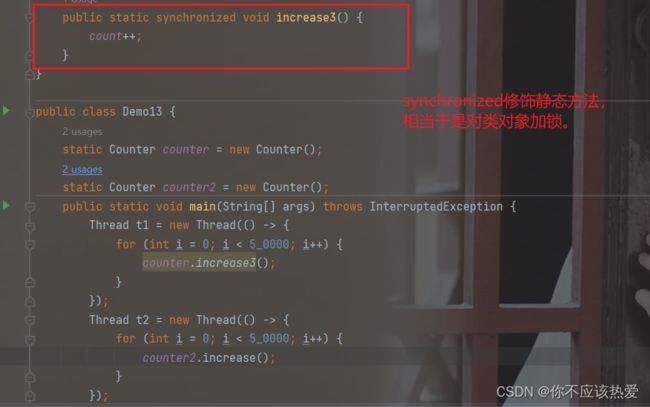
synchronized用法总结:
1.修饰普通方法,锁对象相当于this。
2.修饰代码块,锁对象需要在 ()内指定。
3.修饰静态方法,锁对象相当于 类对象(注意这里并不是锁整个类)。
3.1.2 可重入性
synchronized 是可以对同一条线程是可重入的,不会出现自己把自己锁死的情况。
何为死锁?
简单来说;就是一个线程针对一把锁加锁两次。
第一次加锁可以成功,第二次加锁就会失败
分析:因为第二次加锁的时候,锁已经被占用,要想加锁成功,必须等待第一把锁解锁,但是第一把锁要想执行完成,必须执行完第二把加锁的代码块。这造成死循环。

针对上述情况,不会产生死锁的情况,就叫做”可重入锁“, 会产生死锁的情况,就叫做”不可重入锁“。
当然 我们这里所讲到的 synchronized是可重入锁。
可重入锁的底层实现
其实道理是很简单的。原则1 就是 让这个锁记录好是哪个线程持有这把锁即可。
比如:线程t尝试对针对this进行加锁,this这个锁就记录t持有了它自己,当第二次t进行加锁的时候,锁一看还是t线程,于是就直接放行通过。这是不需要阻塞等待的。
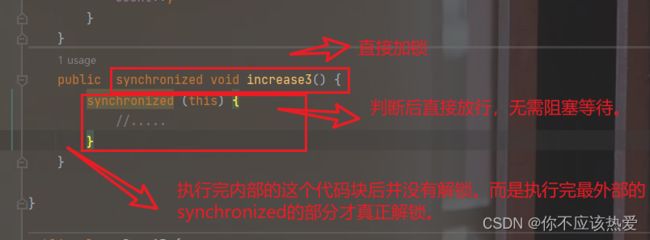
原则2:就是内部维护一个计数器,用来衡量什么时候是真加锁,什么时候需要解锁,什么时候需要直接放行。(这些synchronized会帮我们维护好,不需要我们关心)。
ps:加锁代码中出现了一次,是不会出现死锁的情况的,无论如何代码都能执行到。这也是synchronized被设计为关键字的一个原因。
四、Java 标准库中的线程安全类
Java标准库中很多都是线程不安全的,这些类可能会设计到多线程修改共享数据,但是没有任何自带的加锁措施:
- ArrayList
- LinkedList
- HashMap
- TreeMap
- HashSet
- TreeSet
- StringBuilder
但是还有一些是线程安全的. 使用了一些锁机制来控制.
- Vector (不推荐使用)
- HashTable (不推荐使用)
- ConcurrentHashMap
- StringBuffer
StringBuffer 的核心方法都带有 synchronized .

还有的虽然没有加锁, 但是不涉及 "修改", 仍然是线程安全的
- String
五、volatile关键字
5.1 volatile可以保证内存可见性
我们上面提到了volatile所修饰的变量能够保证”内存可见性“。
再次引用上面我们在JMM中提到的例子:
import java.util.Scanner;
class Counter {
public static volatile int count = 0;
static Object locker = new Object();
public void increase() {
synchronized(Counter.class) {
count++;
}
}
public void increase2() {
synchronized (this) {
count++;
}
}
public synchronized void increase3() {
synchronized (this) {
//.....
}
}
}
public class Demo13 {
static Counter counter = new Counter();
static Counter counter2 = new Counter();
public static void main(String[] args) throws InterruptedException {
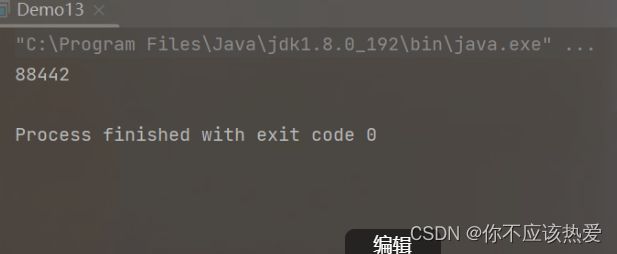
Thread t1 = new Thread(() -> {
while(Counter.count == 0 ) {
}
System.out.println("t1线程执行结束");
});
Thread t2 = new Thread(() -> {
System.out.println("请输入一个int:");
Scanner scanner = new Scanner(System.in);
Counter.count = scanner.nextInt();
});
t1.start();
t2.start();
t1.join();
t2.join();
// System.out.println(counter.count);
// System.out.println(counter2.count);
}
}
运行结果:

分析:这里给count变量加上了volatile,强制读取了内存(禁止了编译器的优化,避免了直接读取CPU寄存器中缓存的数据,而是每次都重新读取内存),速度是变慢了,但是准确度提高了。
5.2 volatile不可以保证原子性
volatile和synchronized有着本质的区别,synchronized能够保证原子性,volatile保证的是内存可见性。
这里我们把上面count++的例子(利用两个线程,将count从0自增到10w次):
static class Counter {
volatile public int count = 0;
void increase() {
count++;
}
}
public static void main(String[] args) throws InterruptedException {
final Counter counter = new Counter();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(counter.count);
}结论: 可以看出由于volatile无法保证原子性,所以再涉及到count++这类操作(在底层会把自增操作拆分为三个指令)时,无法保证线程安全。