Linux 操作系统 CPU numa架构
支持超线程的numa架构
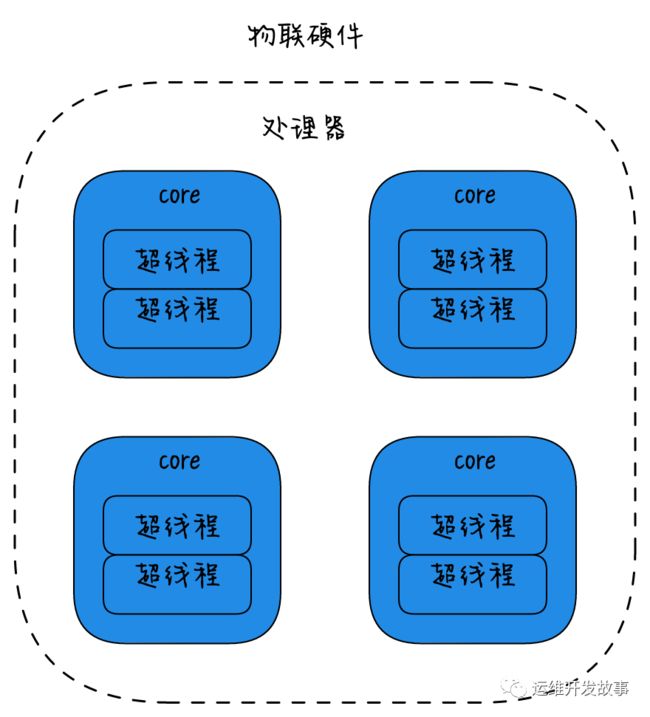
物理硬件视角,
-
将多个CPU封装在一起,这个封装被称为插槽Socket;
-
Core是socket上独立的硬件单元;
-
通过intel的超线程HT技术进一步提升CPU的处理能力,OS看到的逻辑上的核Processor的数量。
每个硬件线程都可以按逻辑cpu寻址,因此这个处理器看上去有八块cpu。
(有多少个socket就有多少个CPU,也即使CPU的数量。每个CPU上面都有核心,然后核心可以开启1个或者多个超线程。 下面这幅图就是一个socket也就是一个CPU的架构,一个CPU上面4个核心,每个核心跑两个超线程,那么操作系统就可以看到8个CPU)
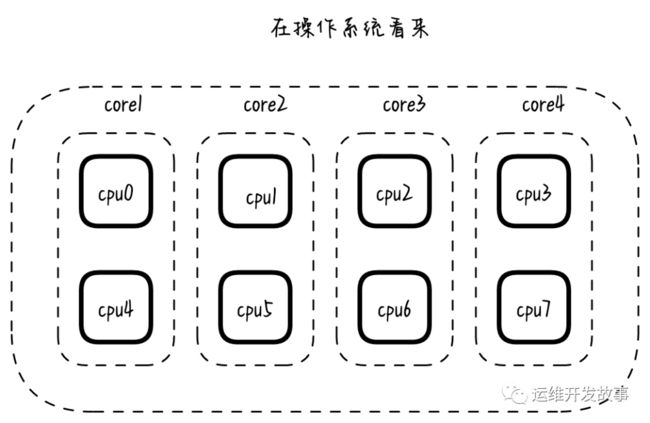
对于操作系统的视角:
CPU(s):8
-
NUMA node0 CPU(s):0,4
-
NUMA node1 CPU(s):1,5
-
NUMA node2 CPU(s):2,6
-
NUMA node3 CPU(s):3,7
L1缓分成两种,一种是指令缓存,一种是数据缓存。L2缓存和L3缓存不分指令和数据。
L1和L2缓存在第一个CPU核中,L3则是所有CPU核心共享的内存。
L1、L2、L3的越离CPU近就越小,速度也越快,越离CPU远,速度也越慢。再往后面就是内存,内存的后面就是硬盘。我们来看一些他们的速度:
-
L1 的存取速度:4 个CPU时钟周期
-
L2 的存取速度:11 个CPU时钟周期
-
L3 的存取速度:39 个CPU时钟周期
-
RAM内存的存取速度 :107 个CPU时钟周期
如果 CPU 所要操作的数据在缓存中,则直接读取,这称为缓存命中。命中缓存会带来很大的性能提升,因此,我们的代码优化目标是提升 CPU 缓存的命中率。

在主流的服务器上,一个 CPU 处理器会有 10 到 20 多个物理核。同时,为了提升服务器的处理能力,服务器上通常还会有多个 CPU 处理器(也称为多 CPU Socket),每个处理器有自己的物理核(包括 L1、L2 缓存),L3 缓存,以及连接的内存,同时,不同处理器间通过总线连接。通过lscpu来看:(4个CPU处理器,每个CPU处理器上面一个核心,每个核心开启一个超线程)
root@ubuntu:~# lscpu
Architecture: x86_64
CPU(s): 32
Thread(s) per core: 1
Core(s) per socket: 8
Socket(s): 4
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 20480K
NUMA node0 CPU(s): 0-7
NUMA node1 CPU(s): 8-15
NUMA node2 CPU(s): 16-23
NUMA node3 CPU(s): 24-31
你可能注意到,三级缓存要比一、二级缓存大许多倍,这是因为当下的 CPU 都是多核心的,每个核心都有自己的一、二级缓存,但三级缓存却是一颗 CPU 上所有核心共享的。
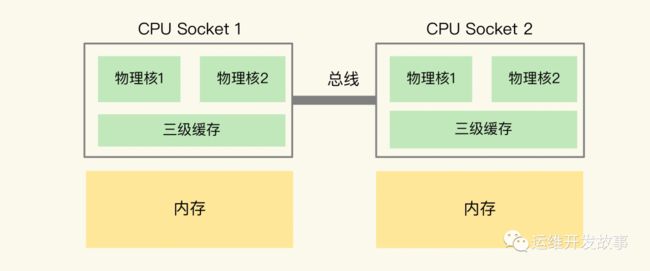
但是,有个地方需要你注意一下:如果应用程序先在一个 Socket 上运行,并且把数据保存到了内存,然后被调度到另一个 Socket 上运行,此时,应用程序再进行内存访问时,就需要访问之前 Socket 上连接的内存,这种访问属于远端内存访问。和访问 Socket 直接连接的内存相比,远端内存访问会增加应用程序的延迟。
cpu调优

应用程序对CPU进行绑核,也就是让应用程序固定使用某些核数,
这个是常见的2路cpu,2路CPU表示一台服务器上面插入了两个CPU,每个CPU在图里面占用了socket,每个socket上面又有很多CPU的核,比如可能有18个物理核数,这里就会有c1-c18 18个核,每个核都有L1 L2的两级缓存,每个socket共享使用L3缓存。
在访问数据的时候是从它,离它最近的L1的缓存去访问的,L1里面没有找到就去L2,L2没有找到就去L3,L3没有找到的话就去查看内存。
这里内存又分两个情况,这里的CPU和内存是一个socket,叫做本地内存。也可能和CPU不是一个socket,比如socket1的CPU访问socket2的CPU内存也是能够访问到的,这个叫做远程内存,这个差异在于访问本地的内存要比访问远程的内存快40ms,这里就出现了差异。
每个CPU核有自己的缓存,如果某个任务使用一个核的话,那么L1,L2的缓存命中率就会很高,每个socket是公用L3的缓存,假设任务在socket之间调度那么L3的缓存命中率也会大幅度下降
这里还有本地内存和远程内存,它们也是不一样的,这里有40ms的延迟
每个CPU核有自己的缓存,如果某个任务使用一个核的话,那么L1,L2的缓存命中率就会很高,每个socket是公用L3的缓存,假设任务在socket之间调度那么L3的缓存命中率也会大幅度下降

查看CPU的信息使用lscpu

Thread(s) per core:
也就是36个CPU的时候,实际上只有18个核,因为就是开了超线程
Cpu是有很多很多的计算模块,在运行的时候不是所有的模块都在工作,假设将一个物理核数虚拟出两个核,这样就可以更大的复用每个CPU的模块,也就是让每个模块的利用率变高,从而提高整体性能,2个虚拟核比2个物理核性能要差,但是要比一个物理核要好。
每个socket包含18个核,表示每个CPU是18个物理核数,但是每个物理核又有两个超线程,那么每个CPU看到的是36个核数,2个CPU就看到的是72个核数。
Sockets是物理概念表示服务器有两个物理的CPU
Numa本意是和Socket的一样,为了隐藏让应用程序只看到一个socket,在bios里面将numa的功能关闭,那么Numa Node就等于1。也就是我有两个socket,但是我让应用程序只看到一个socket,这就是numa的作用。
早期有一匹服务器都会将numa关闭,所以在这里只能看到一个numa,但是新上线的服务器都会开启这个功能,上面是可以看到两个numa node。
#2个socket 但是只能看到一个numa
[root@docker ~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 2
On-line CPU(s) list: 0,1
Thread(s) per core: 1
Core(s) per socket: 1
Socket(s): 2
[root@docker ~]# numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1
node 0 size: 1993 MB //本地内存就是物理内存 2G
node 0 free: 1591 MB
node distances:
node 0
0: 10
[root@docker ~]# free -m
total used free shared buff/cache available
Mem: 1993 132 1590 8 270 1692
Swap: 1023 0 1023不关闭那么应用程序就知道哪些是本地内存,哪些是远程内存,尽量使用本地内存的时候性能就会好一些。
