Python写入字典_干货|python基础知识总结
点击上方“AI遇见机器学习”,选择“星标”公众号
重磅干货,第一时间送达
![]()
Python是一种面向对象的解释型计算机程序设计语言。它有着代码简洁、可读性强的特点。代码简洁是因为它把许多的复杂的操作封装起来,将C语言中麻烦的指针和内存管理对开发者隐藏起来,使得在开发过程中,无须在意这部分的细节。另外Python这们语言强制用户用缩进进行排版,若不好好排版,则代码编译无法通过,或者运行过程会出现错误。
Python程序的执行过程和C语言不一样,使用Python写的程序在运行过程中 Python解释器会把源代码转换为字节码,再由Python虚拟机来执行这些字节码。而C程序则是计算机直接执行由C源代码编译的机器指令。
在使用Python的时候需要留意你所使用的Python版本,因为Python2.X和Python3.X有较大的改动。最主要的是Python3默认编码为utf-8,并且Python2中的print语句变成了print函数。其他变动在此不一一说明。
有关Python的特点只需了解就好,这些在代码实战会体会到。
一、基础数据类型
Python是一门弱类型语言,变量使用前无需声明,变量名可以看作一种引用。Python的基本数据类型分为数字、字符串、列表、元组、集合、字典。
其中数字包括整型、浮点型、布尔型、以及复数。Python的整型数可以有无限精度,浮点数默认为double类型保留16位小数,如果你需要更高的精度,则可以使用decimal模块。在python中,布尔型为数字的一种,True 和 1等价,False和0等价,(你会发现True == 1这语句为真,且True+True的值等于2),复数的实部和虚部均为浮点数。
列表、元组、字典、集合、字符串是Python中经常会使用到的数据结构,这些数据结构的方法都要能熟练使用。
列表、元组、字符串是非常相似的,他们都是顺序存储结构,元素之间有固定的顺序,并且它们都可以用 + 和相同类型的数据类型拼接起来。他们的差别是:列表内的元素可以修改,元组和字符串是不可变数据类型,即元祖和字符串的元素不能修改(如果把每一个字符当成字符串的元素的话)。
其中元组和字符串的不可改变也不一样,如果对想修改字符串,等价新建新的字符串(字符串的是完全不能修改)。
而元组是不能修改元组内对元素的引用。当你的元组里嵌套了一个列表时,你发现列表内的元素可以修改,但是你不能把列表这个元素换成其他元素。因为元祖该位置保存着该列表的引用,该引用不能修改。修改列表内的元素并不会改变元组对该列表的引用。
除此以为,列表、元组、字符串都能用索引访问元素,可以使用切片操作,可以用for in 循环按顺序迭代元素。其中元祖的性能比列表的性能稍微高一点点,这在数据量大的时候才比较明显,但在机器学习中通常都是使用numpy的数组。
字符串的使用自不用说,列表往往使用来处理数据时使用(处理完直接append到列表里),元祖就比较少用到。有关字符串、列表的操作一定要熟练掌握。
字典记录了键值的映射关系,可以迭代,可以修改,但是字典没办法保证安装你添加顺序进行迭代。此外使用字典会比列表更占用内存,但字典的访问更快。
在使用字典的时候还有许多技巧,当你想判断某个键是否在字典里的时候,在数据量巨大的时候,用in操作会很慢,而如果你直接访问用键来访问,并将此语句放在try/except内,速度会明显提高(in操作相当于遍历查找,如果字典无此键,这需要遍历整个字典;但如果直接访问,就能利用哈希表的优点,迅速查找,如果找不到也会因为抛出异常而进入except语句块)。
集合也是一种无序无重复元素的数据结构,所以我们可以把列表转化为集合达到数据去重的效果,这是制作词袋经常使用的技巧。同时也要注意集合内存放的都是不可变对象。
有些时候我们还需要对数据进行拷贝操作,这时我们要注意是否需要深拷贝的情况。当列表、字典存在嵌套的时候,如果用浅拷贝或者切片。则会导致嵌套里面的列表或字典仍为同一个对象,一处修改导致同时修改的情况。这是应该使用copy模块的deepcopy方法来进行拷贝。
机器学习的操作对象是数据,所以以上的数据类型必须要能够熟练的运用。
二、循环
Python的循环简单易上手,while循环和C语言一样,但for in 循环就很像java的foreach循环(java foreach循环不能修改迭代元素,而Python的for in可以)。for in 循环在迭代列表、元组等可迭代类型非常方便。例:
>>>abc = ['a', 'b', 'c']>>> for item in abc: print(item)也可以用range用索引迭代:
>>> for index in range(len(abc)): print abc([index])三、文件IO
在处理数据的时候,我们往往需要从文件中读取数据。所以文件IO操作必不可少的。
Python的文件操作很简单,只需用open打开文件
file = open(path,pattern)
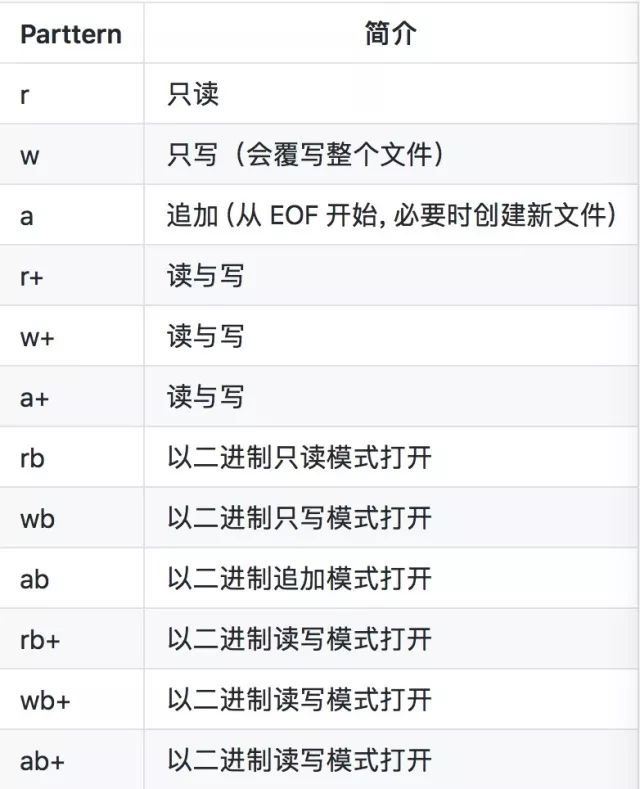
由上可知,上面文件IO的模式和C的差不多,除此之外,有些时候还要设置编码等等。
read是一次性读完文件,但是当读取内容大于内存大小不能使用read。
readline和readlines都是逐行读取,但是readlines是一次性读取之后,每一行转为列表的一个元素。readlines比readline要快。
当使用write写入时,若写入的内容大于缓冲区,则会直接写入文件(一般会先写入缓存区)。writeline则是可以把列表当做参数写入。一般写入操作之后都应调用flush方法,把缓存区的内容写到文件去。
在完成文件IO之后要关闭文件,否则就会占用系统资源,可以用try/finally确保文件关闭,用with语句可以更方便些(with语句结束自动关闭文件)。
四、函数
Python中用def关键字来定义函数,格式为
def 函数名(参数):
函数参数:
接下来将详细将函数的参数类型,函数的参数有4种分别是:必选参数、默认参数、可变参数和关键字参数
必选参数:必选参数需要按照函数声明的顺序传入,和C语言的函数参数一样
默认参数:如果该参数没有传入,则传入默认取值

可变关键字:可变关键字就是传入的参数个数是可变的。

也可以传入一个列表或元组,在参数前加上*

关键字参数:关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个字典

也可以传入一个dict,在参数前加上**

在Python中定义函数,可以用必选参数、默认参数、可变参数和关键字参数,这4种参数都可以一起使用,或者只用其中某些,但是请注意,参数定义的顺序必须是:必选参数、默认参数、可变参数和关键字参数。
返回值:
函数可以有0个或多个返回值,直接return没有返回值实际上是返回了None,返回多个值时,上还是返回一个元组,元组可以对多个变量对应赋值。(其实就是序列解包)
推荐阅读
一起走进自然语言处理的世界
干货|全面理解N-Gram语言模型
你还记得吗?那些最基础的机器学习知识。
干货|学术论文怎么写
欢迎关注我们,看通俗干货!
