【JAVA秘籍心法篇-Spring】Spring XML解析源码详解
【JAVA秘籍心法篇-Spring】Spring XML解析源码详解
所谓天下武功,无坚不摧,唯快不破。但有又太极拳法以快制慢,以柔克刚。武功外式有拳打脚踢,刀剑棍棒,又有内功易筋经九阳神功。所有外功招式配合内功心法才能大成,使其练成钢筋铁骨,无往不前。
大家好,我是王老狮,一个有思想有内涵的架构狮。在茫茫大千的程序宇宙,JAVA可以说是一个层级的位面,需要在这个位面脱颖而出,各种技术框架只是我们的一些外功招式,要想让自己位于不败之地,更要搭配招式的内功心法,了解底层实现原理。融会贯通,收为己用。成为一套完整的解决方案,才有可能大成。今天和大家老聊一下Spring容器加载的过程
Spring容器加载方式
Spring项目中,一般第一步我们都是加载Spring的配置文件,来读取相关信息,用于初始化Spring容器,那么Spring的配置加载的方式一般也有下面4种:
类路径获取配置文件
这种一般都是我们单元测试的时候用一下
AnnotationConfigApplicationContext appcationContext = new AnnotationConfigApplicationContext("com.spring");

基于XML的方式加载SPring配置文件
这种是我们使用Spring经常使用的一种方式,通过Spring配置文件加载Spring容器。
ApplicationContext applicationContext = new FileSystemXmlApplicationContext("E:\\XXX\\spring.xml");

无配置文件加载容器
这种基本是通过到具体扫描包来进行初始化容器,很少使用
ApplicationContext applicationContext = new AnnotationConfigApplicationContext("com.xx.XX");
springboot 加载容器
这种是SpringBoot启动的时候的使用方式。可以用来初始化tomcat等服务器。
ApplicationContext applicationContext = new EmbeddedWebApplicationContext();
Spring的核心启动方法
从上面的初始化方法可以看出,spring容器最核心的加载方法是:AbstractApplicationContext.refresh() 方法。以上几种启动方式都加载必须执行该方法。接下来,我们重点来看下AbstractApplicationContext.refresh() 方法的实现
Spring启动流程介绍
refresh中主要方法如下图,
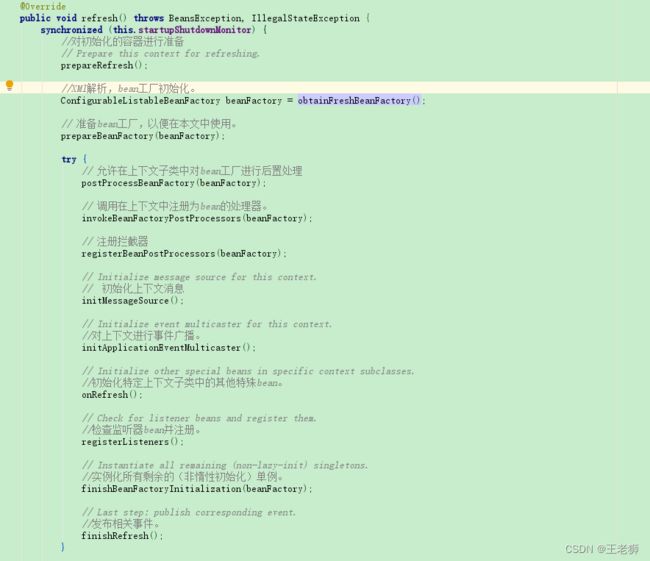
为了防止Spring并发初始化的问题,首先对方法进行了加锁处理。接下来执行prepareRefresh()方法,对容器初始化的环境做准备。这一阶段主要创建了Environment对象,他的主要作用就是为了后期对@Value注入对应的键值。我们重点看下obtainFreshBeanFactory()这个方法。该方法主要主要是对XML进行解析,是创建BeanFactory的核心。
SpringXMl解析源码详解
打开obtainFreshBeanFactory,首先执行refreshBeanFactory方法
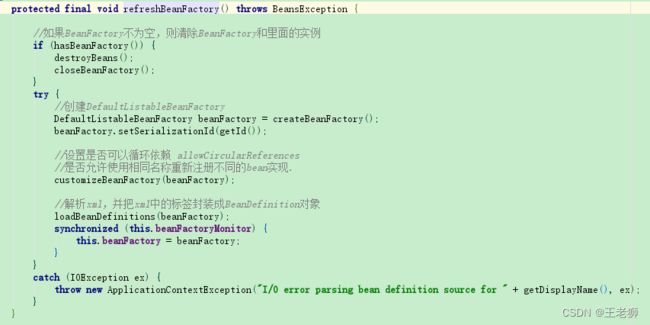
- hasBeanFactory判断BeanFactory是否为空,如果不为则清除BeanFactory和里面的实例用于后面初始化
- createBeanFactory方法创建DefaultListableBeanFactory,该类主要是以list集合的方式操作bean,是整个Spring中的发动机
- customizeBeanFactory方法用于设置对相同bean的处理方式以及是否支持循环依赖,默认相同bean覆盖处理并且支持循环依赖。
- loadBeanDefinitions方法是用来解析XML,并且xml中的标签封装成BeanDefinition对象

loadBeanDefinitions方法首先创建了个XMl的解析器XmlBeanDefinitionReader对象,并且这里使用了代理模式。对于什么是代理模式,大家可以看下我的Mybatis源码分析的专题Mybatis源码分析二-如何优雅的使用主体日志。里面有具体介绍。
之后对解析器进行一些属性设置,之后执行loadBeanDefinitions(beanDefinitionReader);

该方法主要通过 Reader 对象加载配置文件。
配置文件的加载路径一般就是我们传参时的路径。

之后继续执行LoadBeanDefinitions方法,解析XML文件并计数。在目录下可能会有多个配置文件。

之后将路径的文件为了更方便得操作转为Resource对象,之后继续执行loadBeanDefinitions,

之后会获取Resource对象中的文件流对象,然后转为InputSource,并设置编码。InputSource是jdk中的sax中xml文件解析对象。提供的一种输入规范。之后执行doLoadBeanDefinitions进行XML的解析。
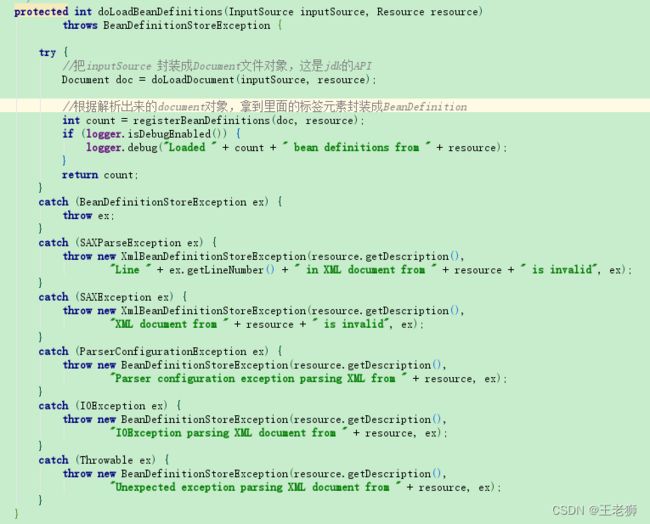
doLoadBeanDefinitions将文件流转为Document对象,之后根据解析出来的对象将里面的元素封装成BeanDefinition对象。其中也对XMl解析存在的一些异常进行了封装和抛出。BeanDefinition 在 spring 中贯穿始终,spring 要根据 BeanDefinition 对象来实例化 bean,只要把解析的标签,扫描的注解类封装成BeanDefinition对象,spring才能实例化bean。

createBeanDefinitionDocumentReader方法创建 BeanDefinitionDocumentReader 对象,DocumentReader 负责对 document 对象 解析

registerBeanDefinitions方法通过接收root节点,开始对bean进行定义以及注册。

对root节点进行一些校验,可以通过preProcessXml方法和postProcessXml对xml解析进行一些前置以及后置处理。

通过parseBeanDefinitions执行对默认标签进行解析还是自定义标签的解析。
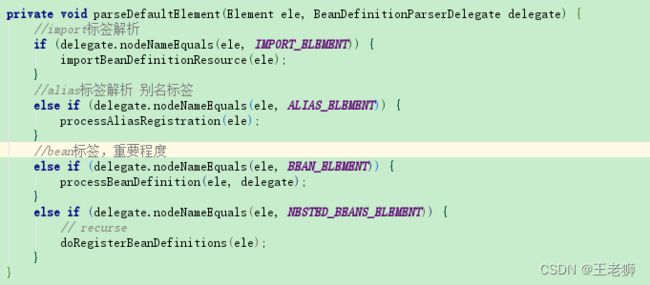
标签的解析过程主要有
- import标签解析
- alias标签解析
- bean标签解析
我们重点看下bean标签解析
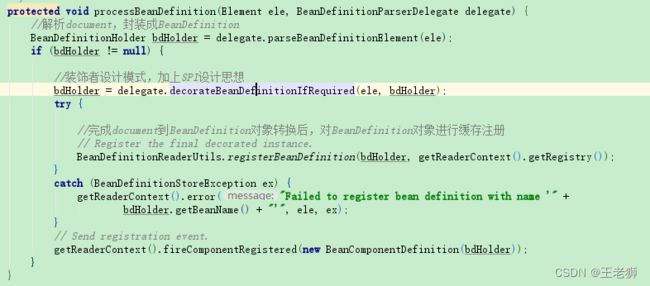
第一步就是解析document,封装成BeanDefinition,解析过程如下:
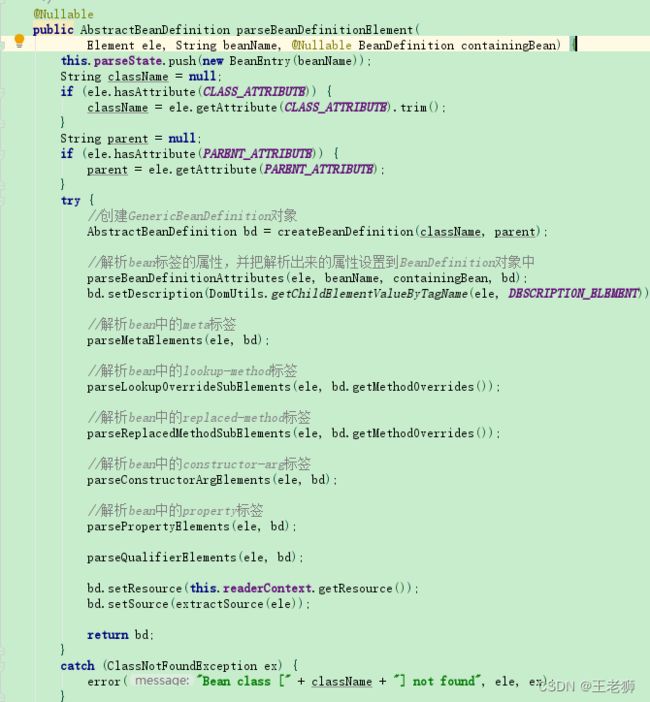
首先创建GenericBeanDefinition对象。然后将解析出来的bean标签的属性都设置到BeanDefinition上。之后返回一个GenericBeanDefinition对象。
PS:从 spring 2.5 开始,Spring提供了一个更好的注册bean definition类,即GenericBeanDefinition ,它支持动态定义父依赖,GenericBeanDefinition 是一站式的标准 bean definition ,除了具有指定类、可选的构造参数值和属性参数这些其它 beandefinition 一样的特性外,它还具有通过 parenetName 属性来灵活设置父类依赖。

得到BeanDefinition对象之后,继续对属性进行补充修饰
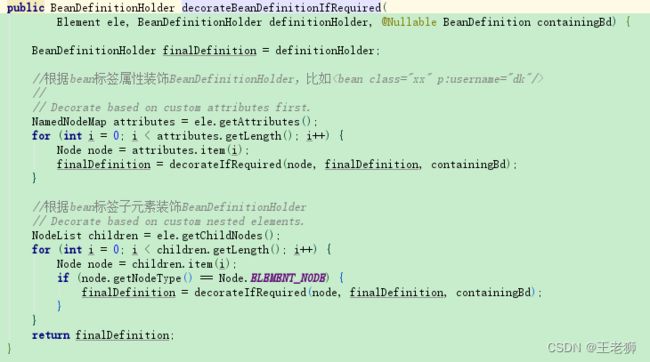
分别对bena标签属性以及bean的子属性进行解析以及对BeanDefinition进行修饰。

根据node获得的命名空间以及,再根据对应的url获取对应的处理类,最终通过namespace的decorate进行装饰,最终返回装饰完的对象。返回完之后执行BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());方法将对象注册到容器中缓存起来。


bean的注册首先判断bean是否被注册了,如果没有那么将beanDefinition缓存到Spring的beanDefinitionMap对象中,并添加到beanDefinitionNames这个list中。最后再将别名和id对应,就可以通过别名获取bean的ID。
整个bean的流程就注册完了。
总结
整个XML解析的主要流程如下:
1、创建XmlBeanDefinitionReader对象
2、通过Reader对象加载配置文件
3、根据加载的配置文件把配置文件封装成document对象
4、创建BeanDefinitionDocumentReader对象,DocumentReader负责对document对象解析
5、parseDefaultElement(ele, delegate);负责常规标签解析
6、delegate.parseCustomElement(ele);负责自定义标签解析
7、最终解析的标签封装成BeanDefinition并缓存到容器中
具体解析流程见下图:
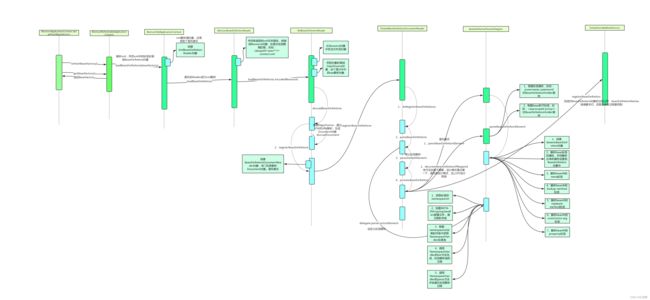
Spring的一个XML解析就使用了代理模式,模板设计、装饰器模式等多种设计模式,因此学习源码对于我们来讲并不是为了学习源码而学习,而是要将源码中涉及到的好的设计思想,融入我们日常开发中,思考下为什么这么设计,这样我们才能更好地掌握系统的设计方法和技巧。